MySQL count语句查询
今天,我们就来聊聊count(*)语句到底是怎样实现的,以及MySQL为什么会这么实现。
count(*)的实现方式
你首先要明确的是,在不同的MySQL引擎中,count(*)有不同的实现方式。
- MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高;
- 而InnoDB引擎就麻烦了,它执行count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
为什么InnoDB不跟MyISAM一样,也把数字存起来呢?
这是因为即使是在同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB表“应该返回多少行”也是不确定的。这里,我用一个算count(*)的例子来为你解释一下。
假设表t中现在有10000条记录,我们设计了三个用户并行的会话。
会话A先启动事务并查询一次表的总行数;
会话B启动事务,插入一行后记录后,查询表的总行数;
会话C先启动一个单独的语句,插入一行记录后,查询表的总行数。
我们假设从上到下是按照时间顺序执行的,同一行语句是在同一时刻执行的。
你会看到,在最后一个时刻,三个会话A、B、C会同时查询表t的总行数,但拿到的结果却不同。
这和InnoDB的事务设计有关系,可重复读是它默认的隔离级别,在代码上就是通过多版本并发控制,也就是MVCC来实现的。每一行记录都要判断自己是否对这个会话可见,因此对于count(*)请求来说,InnoDB只好把数据一行一行地读出依次判断,可见的行才能够用于计算“基于这个查询”的表的总行数。
用缓存系统保存计数
将计数保存在缓存系统中的方式,还不只是丢失更新的问题。即使Redis正常工作,这个值还是逻辑上不精确的。
我们是这么定义不精确的:
一种是,查到的100行结果里面有最新插入记录,而Redis的计数里还没加1;
另一种是,查到的100行结果里没有最新插入的记录,而Redis的计数里已经加了1。
这两种情况,都是逻辑不一致的。
我们一起来看看这个时序图。
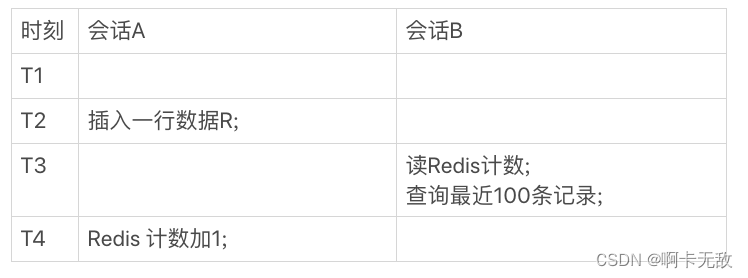
图中,会话A是一个插入交易记录的逻辑,往数据表里插入一行R,然后Redis计数加1;会话B就是查询页面显示时需要的数据。
在图2的这个时序里,在T3时刻会话B来查询的时候,会显示出新插入的R这个记录,但是Redis的计数还没加1。这时候,就会出现我们说的数据不一致。
你一定会说,这是因为我们执行新增记录逻辑时候,是先写数据表,再改Redis计数。而读的时候是先读Redis,再读数据表,这个顺序是相反的。那么,如果保持顺序一样的话,是不是就没问题了?我们现在把会话A的更新顺序换一下,再看看执行结果。
不同的count用法
count(主键id)
nnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。
count(1)
InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
单看这两个用法的差别的话,你能对比出来,count(1)执行得要比count(主键id)快。因为从引擎返回id会涉及到解析数据行,以及拷贝字段值的操作。
count(字段)
-
如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;
-
如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
也就是前面的第一条原则,server层要什么字段,InnoDB就返回什么字段。
但是count(*)是例外
并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。
结论是:按照效率排序的话,count(字段)
所以我建议你,尽量使用count(*)。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!