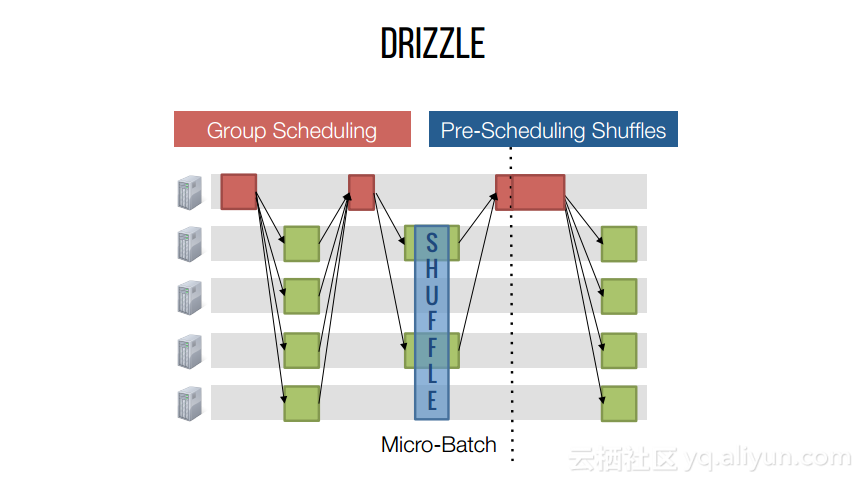
【Spark Summit East 2017】Drizzle——Spark的低延迟执行
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
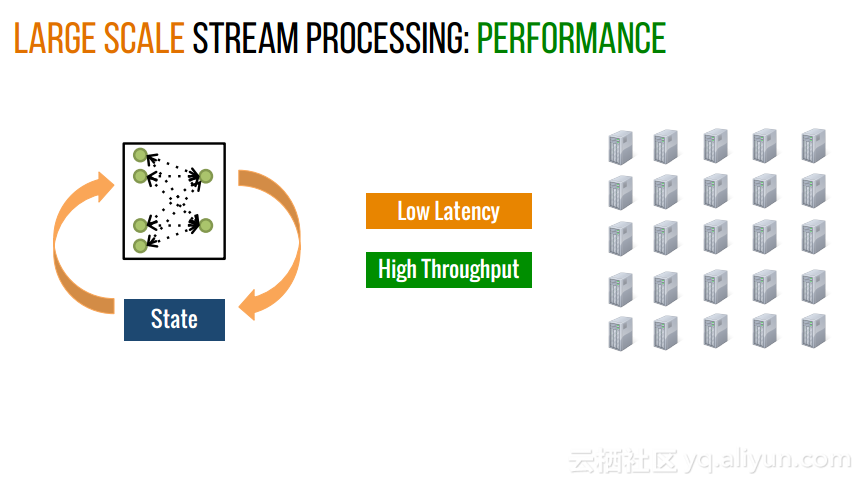
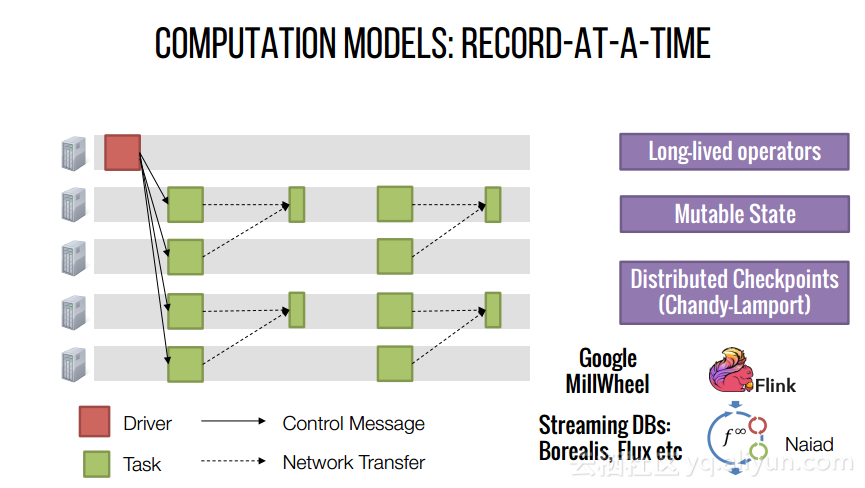
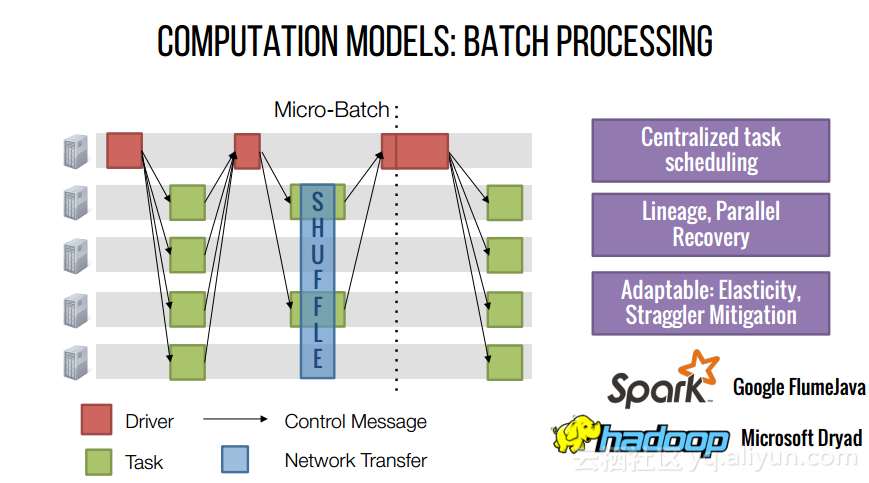
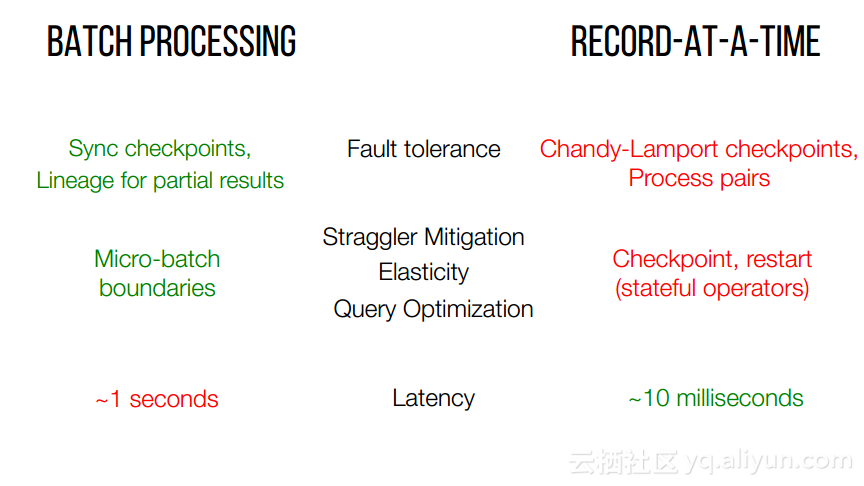
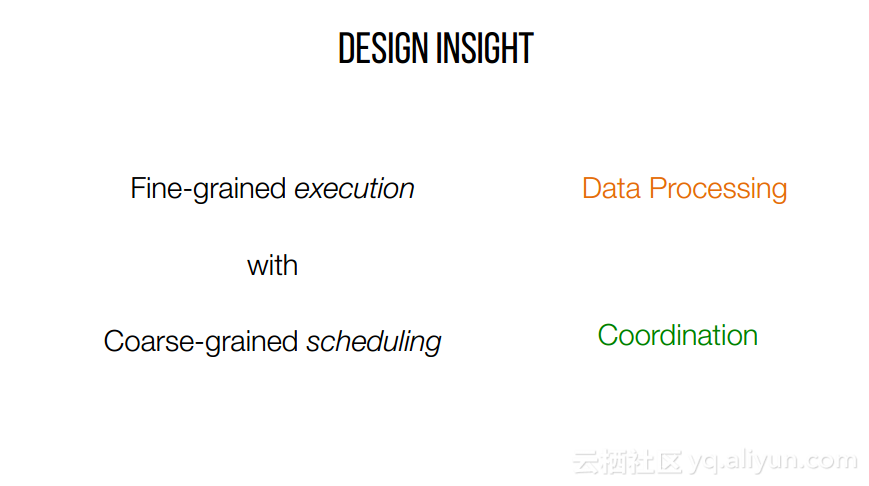
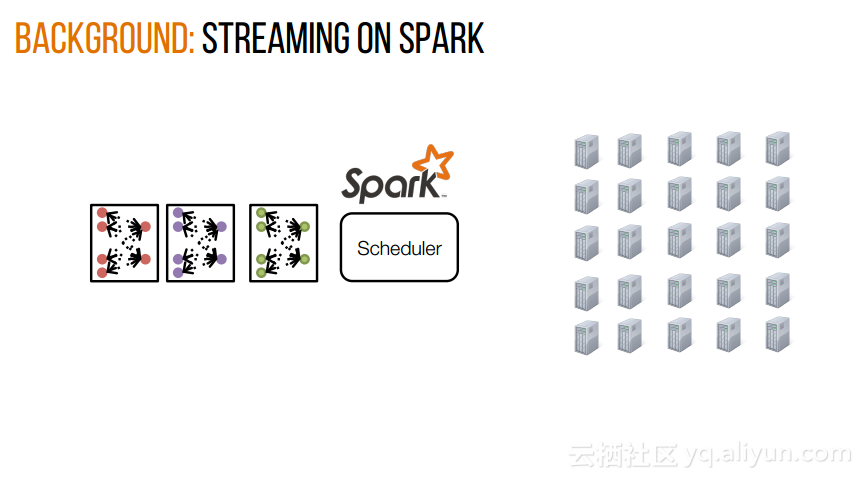
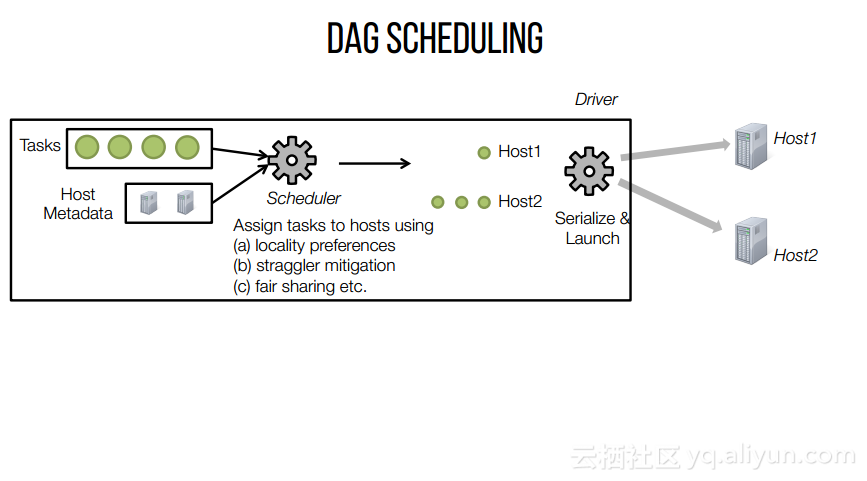
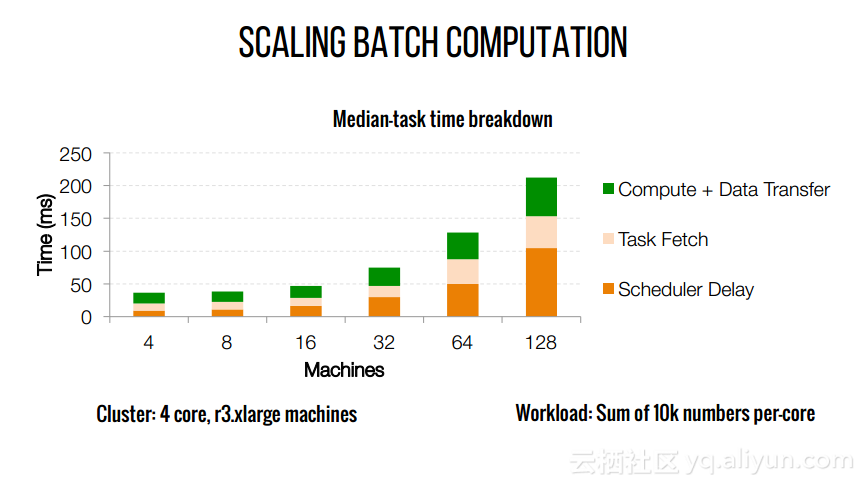
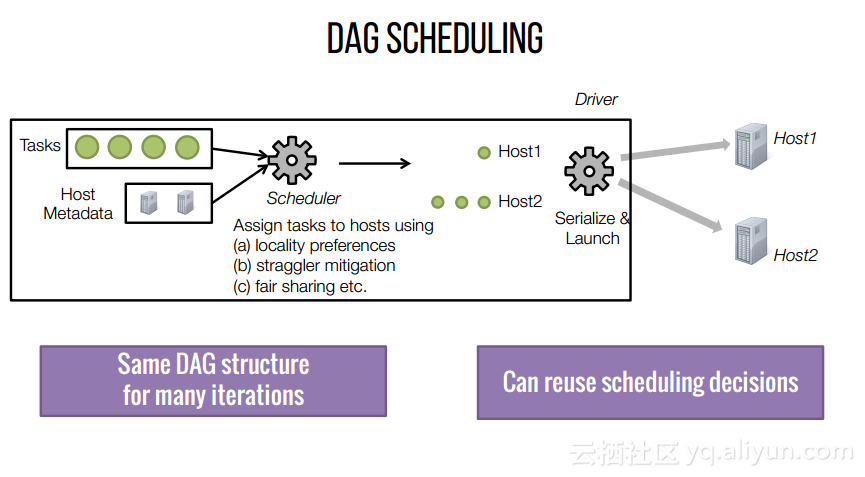
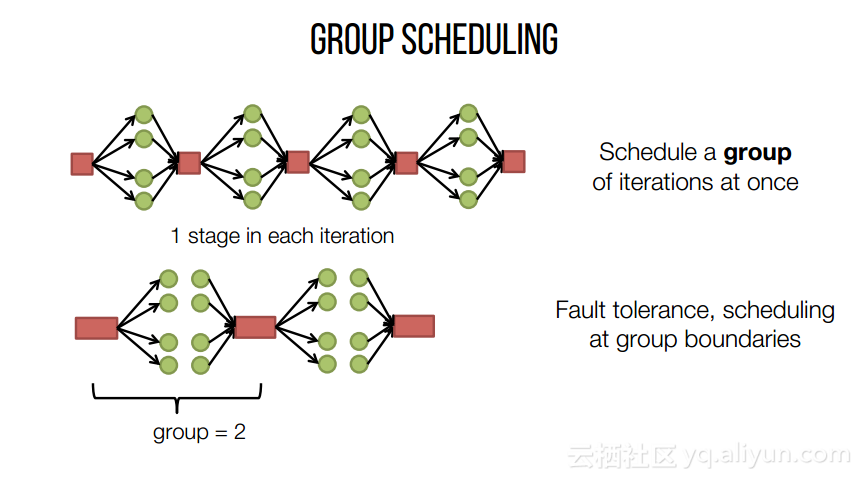
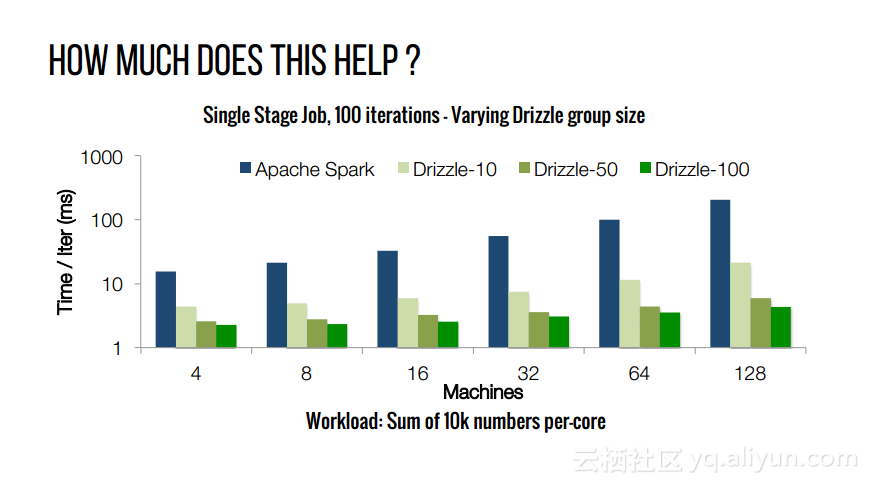
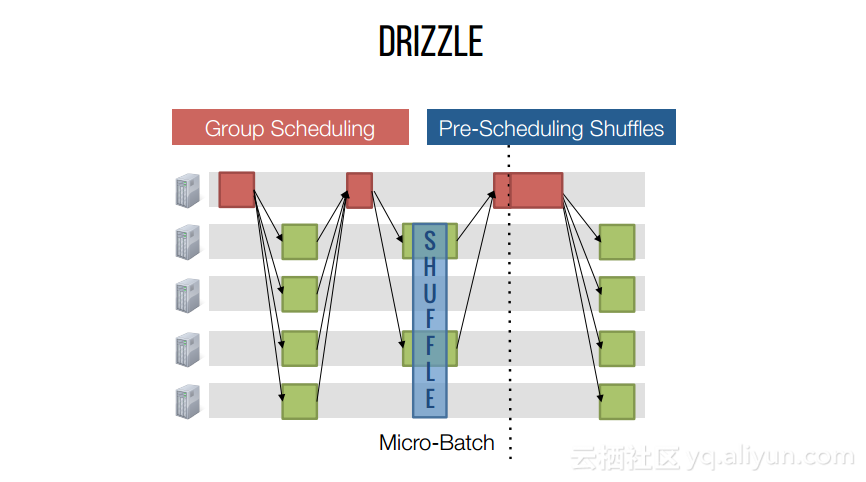
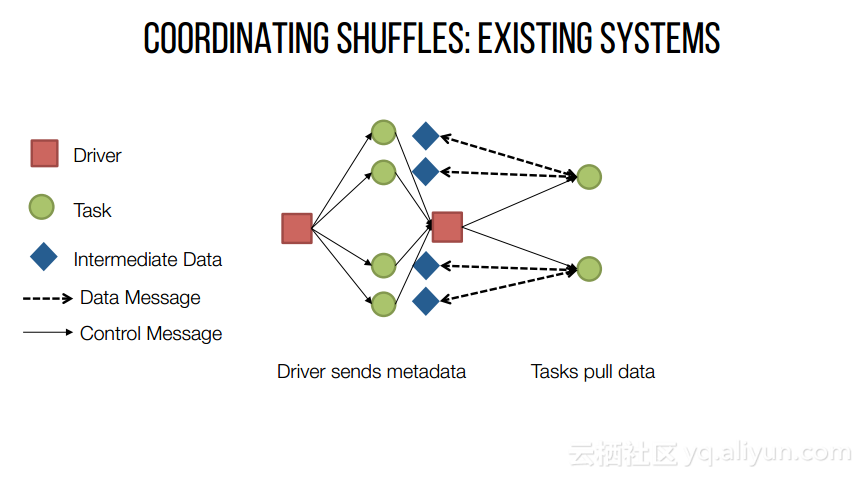
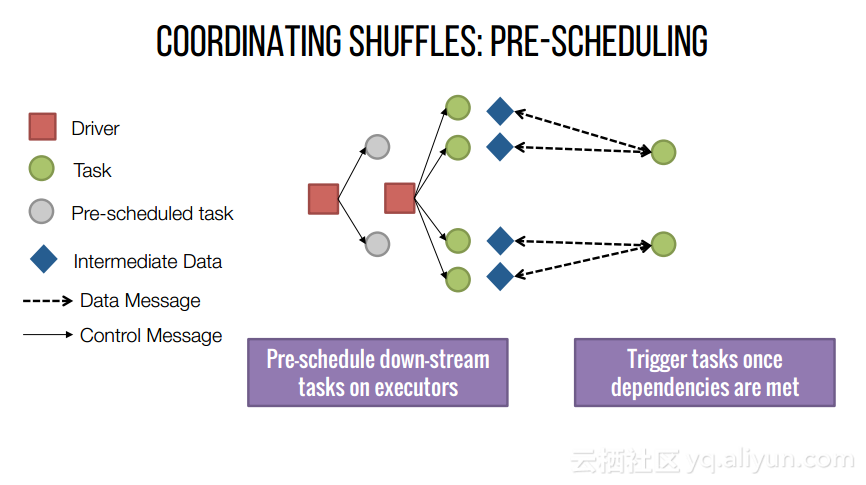
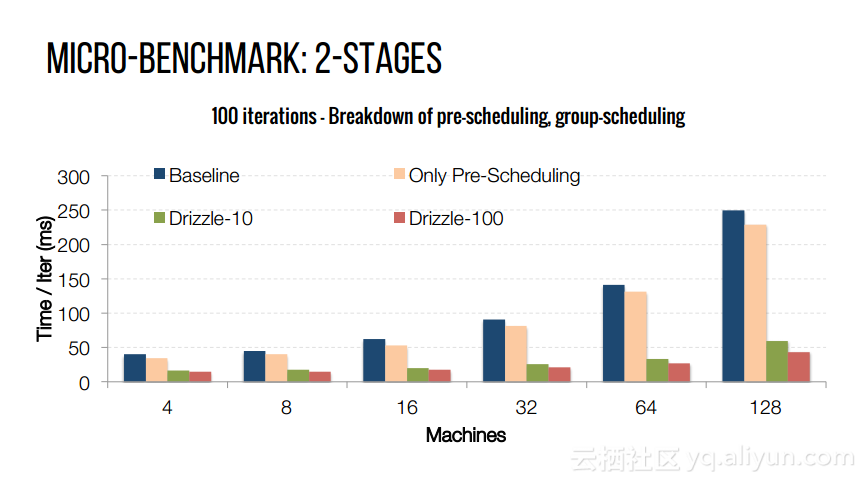
本讲义出自Shivaram Venkataraman在Spark Summit East 2017上的演讲,主要介绍了Spark的低延迟执行引擎——Drizzle,其设计目的在于对流进行处理以及进行迭代工作。目前Spark使用BSP计算模型,并每个任务结束时通知调度器,这就增加了额外的开销,导致导致吞吐量降低,延迟增加,而Drizzle引入了组调度,也就是一次可以对于一组的计算进行规划。








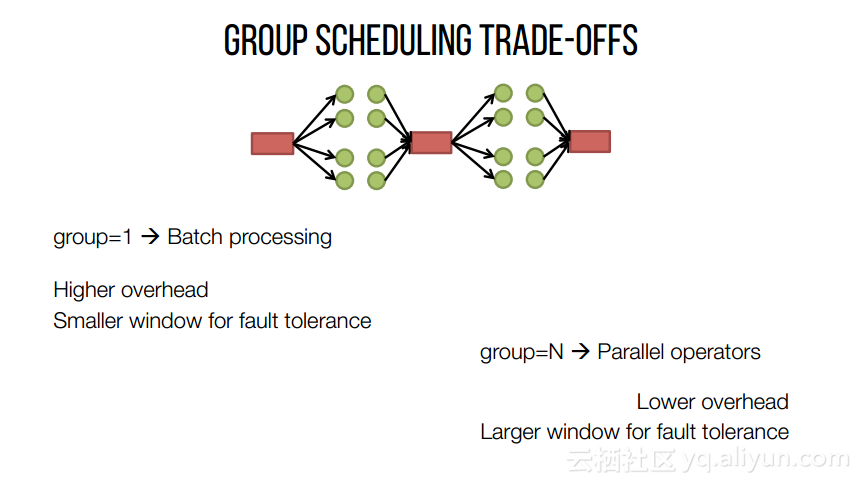
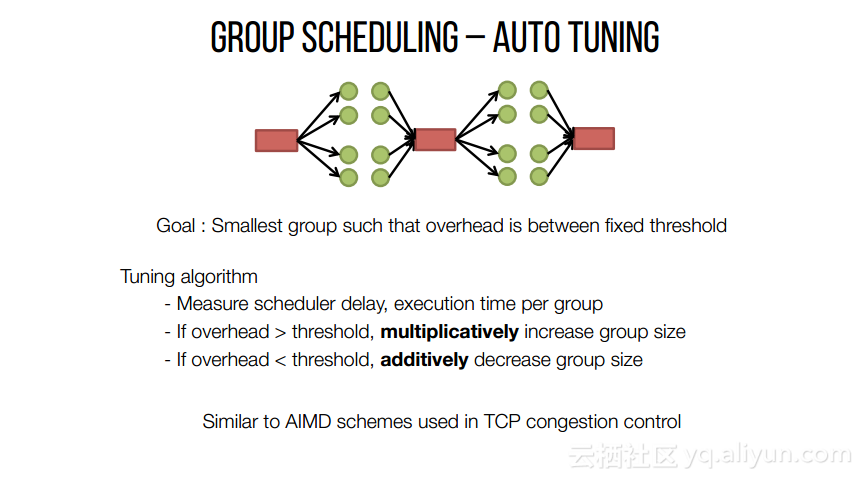
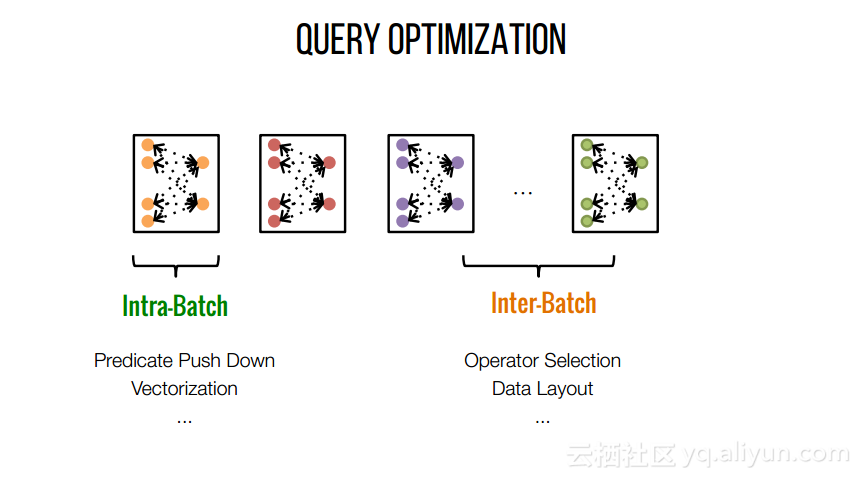
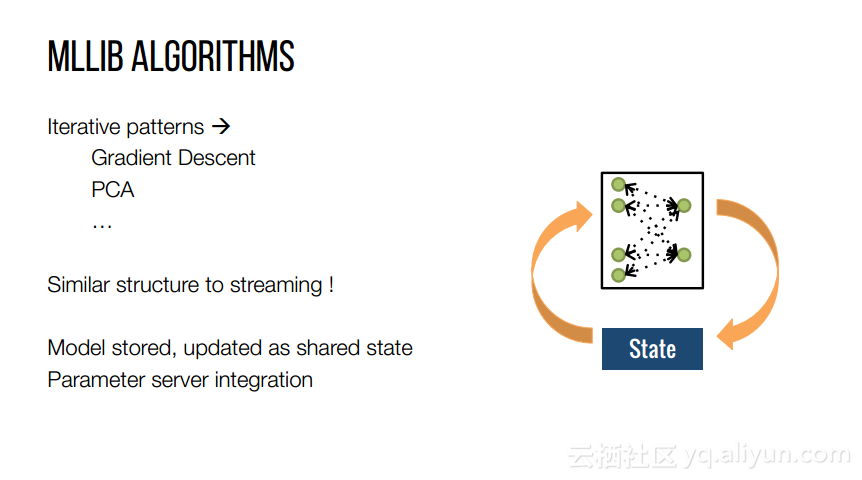

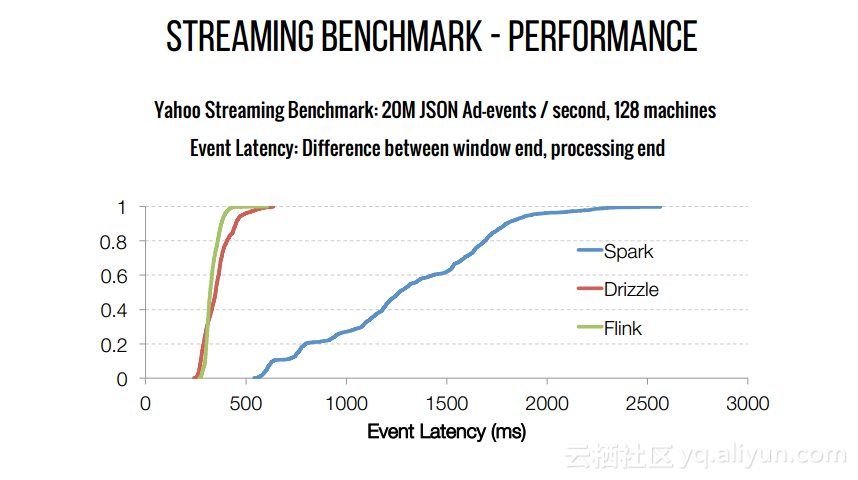
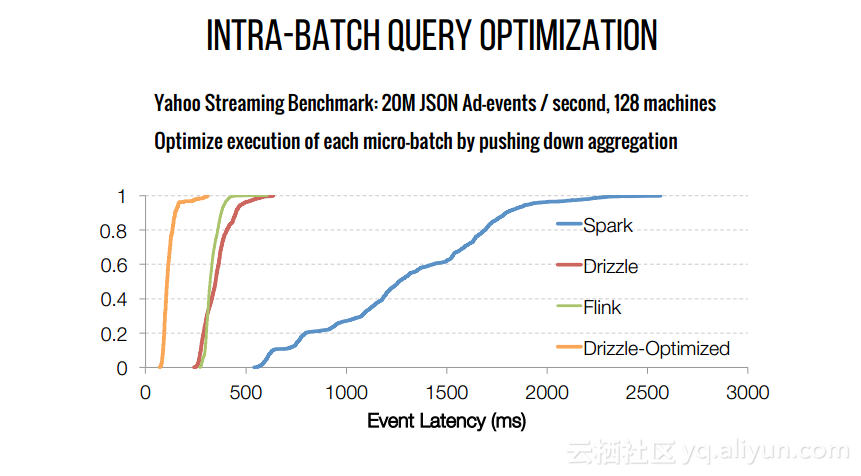
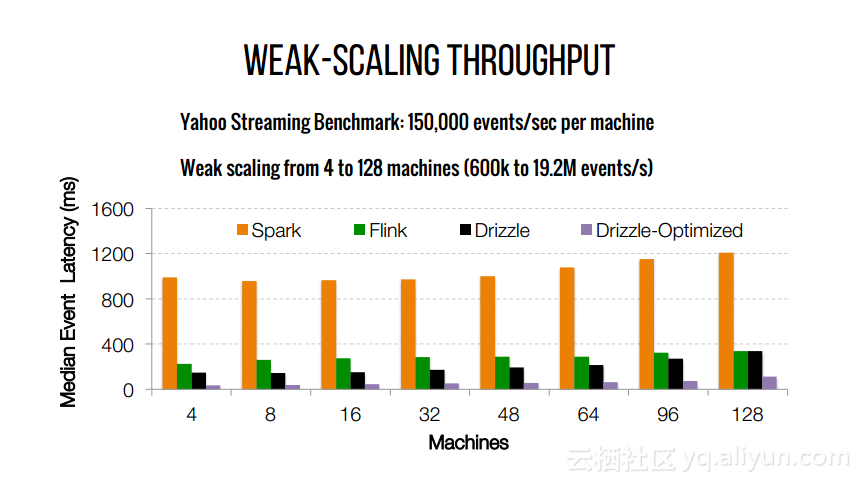
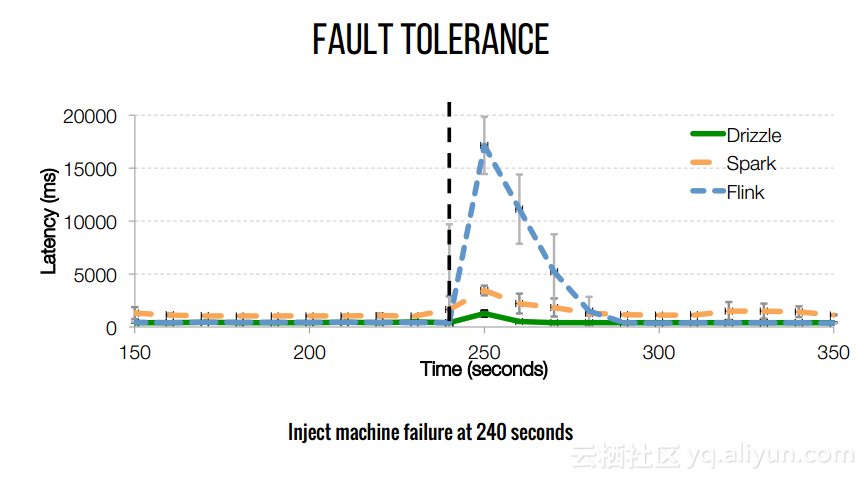


本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!