入门数据挖掘-心电图信号预测datawhale组队学习笔记-task2
心电图信号预测datawhale组队学习笔记task2 EDA数据探索性分析
- 1. 数据总览
- 2. 查看缺失及异常
- 3. 了解预测分布情况
- 3.1 总体概率分布
- 3.2 skewness and kurtosis
- 3.3 label频数分布
- 3.4 pandas_profiling生成数据报告
[1] 本文参考datawhale数据挖掘入门指南
[2] 本文参考datawhale组队学习task2
1. 数据总览
- train.head().append(train.tail()) 观察首尾5行数据
- train.shape
- train.describe() 数据统计量信息(count,mean,std,min,max,…)
- train.info() 获取数据类型
- test同理
2. 查看缺失及异常
- train.isnull().sum() 此数据无缺失值/ any()
3. 了解预测分布情况
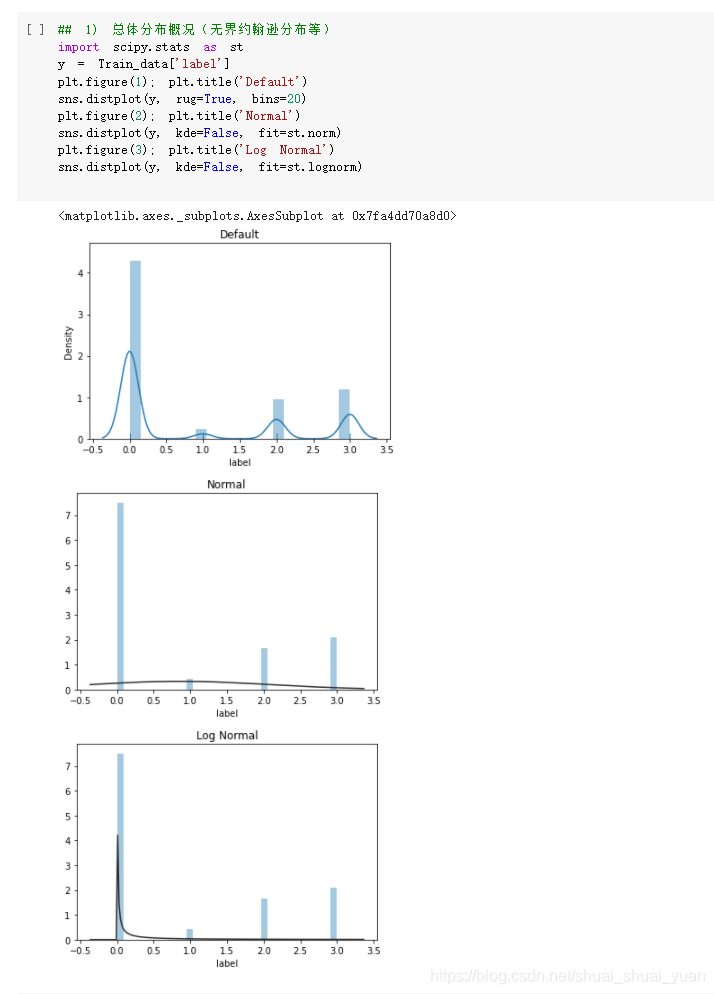
3.1 总体概率分布
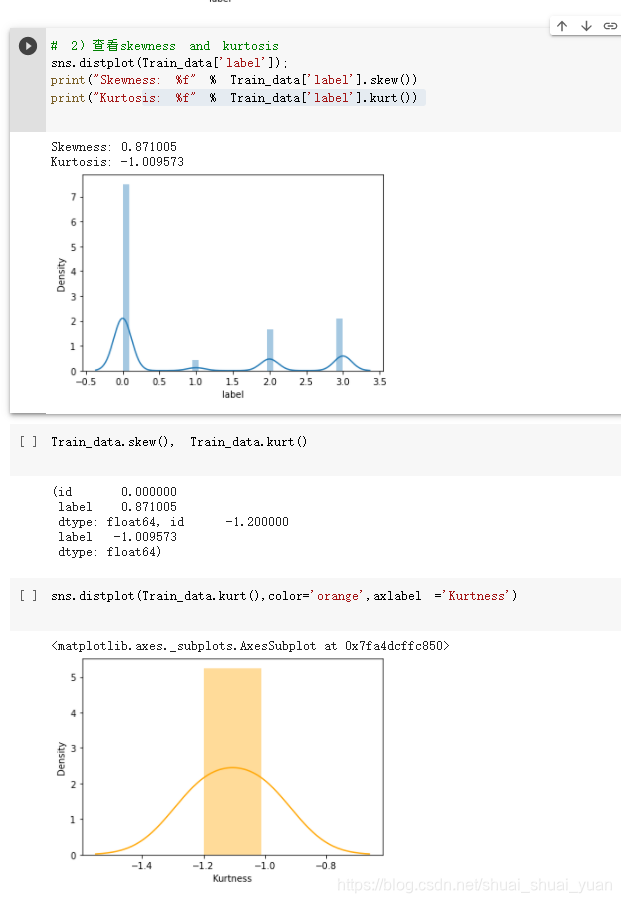
3.2 skewness and kurtosis
- skewness:偏度,(+/-/0),衡量随机变量概率分布的不对称性,是相对于平均值不对称程度的度量,通过对偏度系数的测量,我们能够判定数据分布的不对称程度以及方向。
- kurtosis:峰度(尖峰态,正态、低峰态)研究数据分布陡峭或平滑的统计量,通过对峰度系数的测量,我们能够判定数据相对于正态分布而言是更陡峭/平缓。
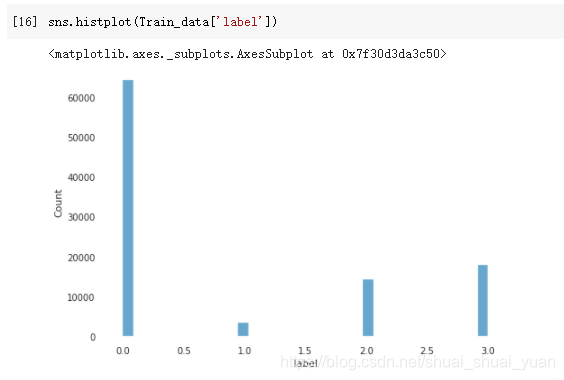
3.3 label频数分布
当某范围预测值很少时,可将其当作异常值处理填充或删除。若频数很失常,需对数据进行处理,例如进行log变换,使数据分布较均匀,可据处理后的数据进行预测,这也是预测问题常用的技巧。
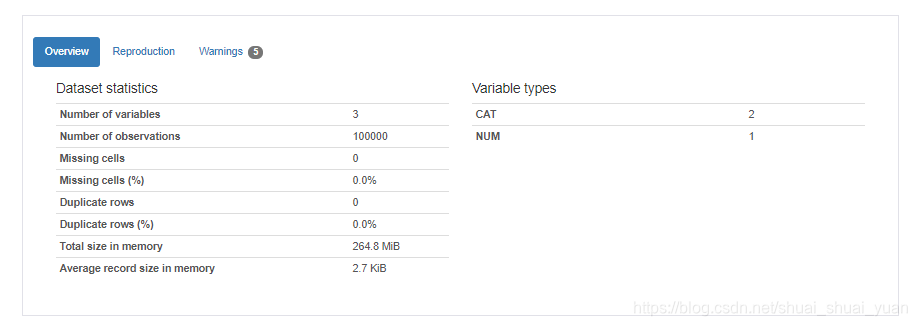
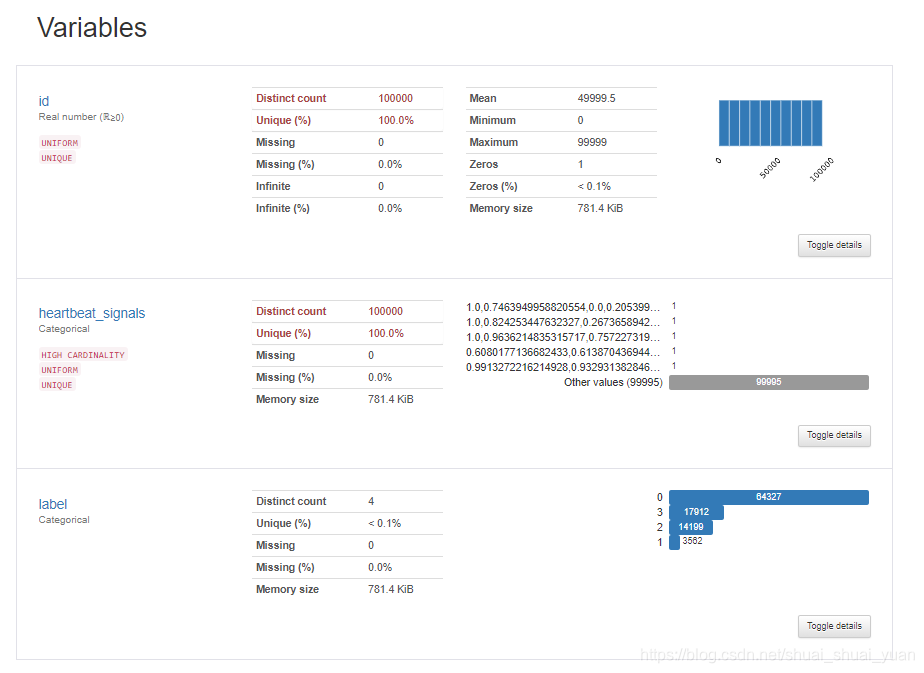
3.4 pandas_profiling生成数据报告
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!