1、luigid的启动与简单使用
目录
前言
一、Central Scheduler的简单使用
1、Central Scheduler的启动
1.1 配置luigid的启动配置与环境配置
1.2 准备一个task例子
前言
我们在使用luigi简单调试时,在启动luigi任务时,经常加上参数 local_scheduler=True,如下。
luigi.build([Join()], local_scheduler=True, detailed_summary=False)但是,这只是为了调试时,聚焦于代码自身的正确性,才会用它。
而luigi内置了一个调度器叫做Central Scheduler。我们在生产中也是用这个Central Scheduler来控制、监控我们的task。为什么用这个Central Scheduler呢?因为它可以将我们所有的task关联、监控起来,并且luigi提供了可视化界面,让我们能够可视化的控制各个task(后面我会详细介绍这个可视化界面的功能,并且会基于它的原理改造它)。
那么,肯定有人会问,local_scheduler和Central Scheduler有什么却别呢?我认为是2个方面:
- Central Scheduler可以监控与控制所有task,而local_scheduler只能服务于某个task
- Central Scheduler有很牛的可视化页面,让我们可以直接干预任务的执行(当然,这得益于luigi暴露的控制task的api)
一、Central Scheduler的简单使用
官网文档:https://luigi.readthedocs.io/en/stable/central_scheduler.html
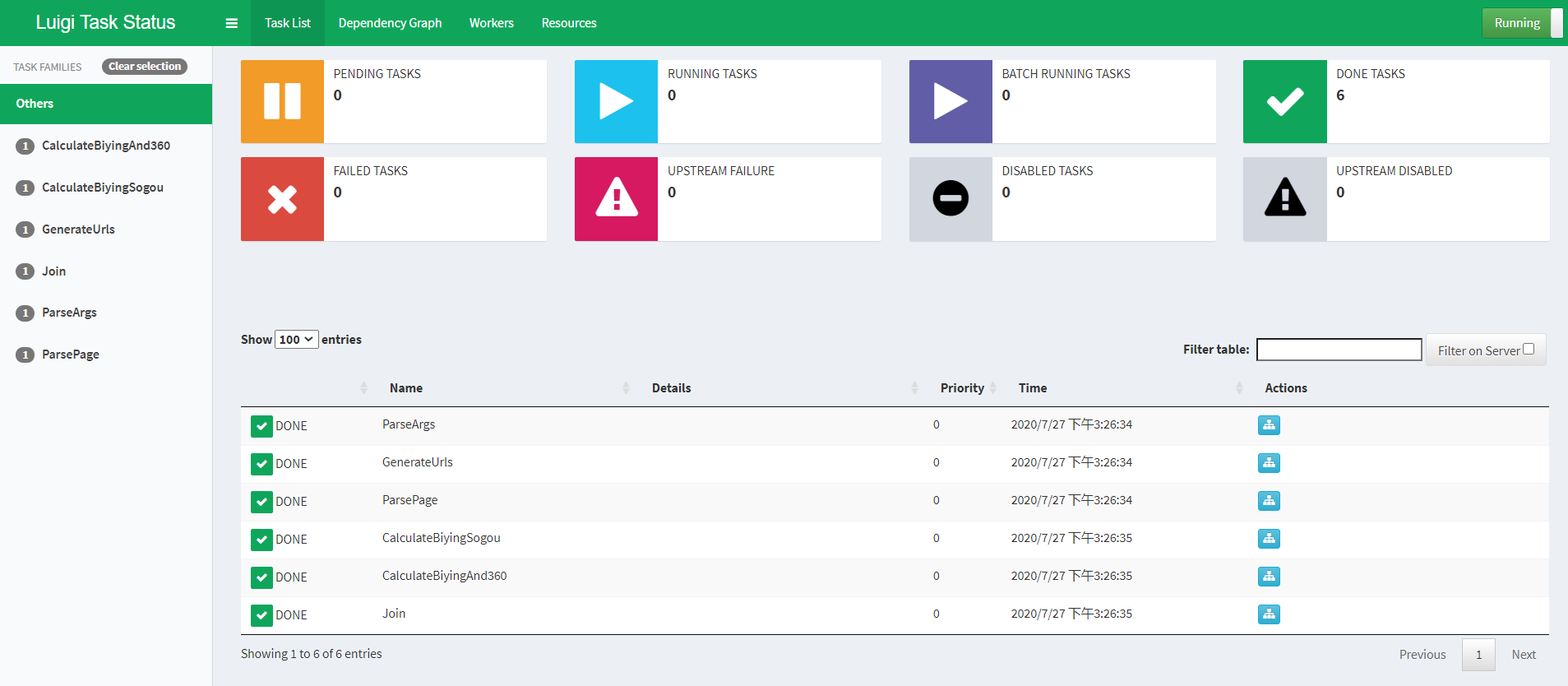
首先注意:central scheduler,不要被它的名字锁迷惑了,它不会真正的给你的task去定时、触发、定期运行等。我理解它只是将你所有的task给收集与记录起来,让我们对于我们task的执行状态有一个总体话的概念与记录。并且配合可视化界面(如下所示),很友好的将task占线出来。
当然,并不是只有展示功能,他还可以通过可视化界面让用户自己控制task的执行与暂停、重启等多种操作。
1、Central Scheduler的启动
这里有两个准备条件,完成这两个条件,就可以启动起来Central Scheduler了
- 配置luigid的启动配置与环境配置
- 准备一个task执行的例子(我是自己写的)
1.1 配置luigid的启动配置与环境配置
怎么又冒出来一个luigid??? 这是什么?
不要慌,这其实就是luigi的server。就像我们在用mysql时,我们进入的mysql其实是客户端,而mysqld是server。我们在使用mysql客户端输入命令时,mysqld作为server会接收client发出的执行并解释执行。
luigid作为server,我们也需要执行起来,才能处理我们客户端发出的请求。
纳尼?luigi客户端?luigi没说客户端啊?
luigi的客户端在哪里呢,还记得我们说过task的可视化界面可以操作task的执行吗?对了,这个可视化界面就可以看作是luigid的客户端。我们在启动了luigid后,访问luigid配置好的地址,就可以获取这个可视化界面了。
1.1.1 启动luigid
很简单,直接在cmd中执行一条语句即可
lugid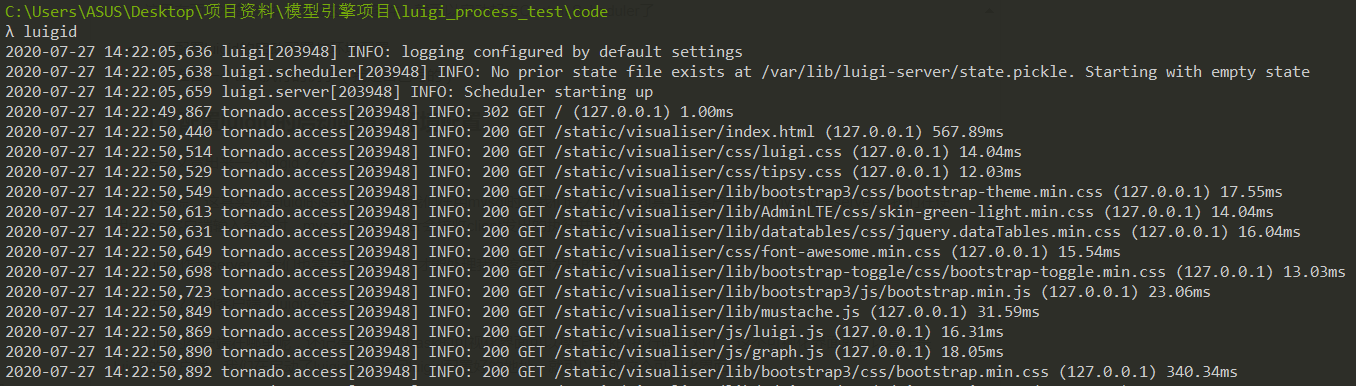
这样就启动好了luigid。我们就可以访问可视化界面了。
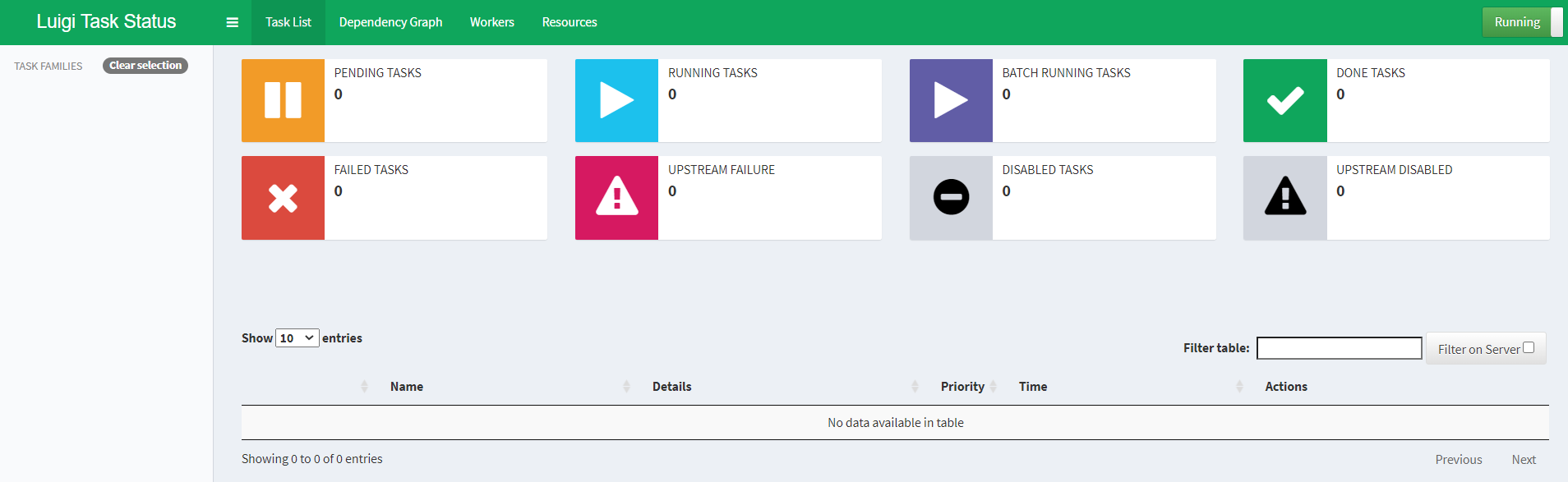
默认下,可视化界面端口为8082,所以访问127.0.0.1:8082
ok,页面跳出来了,但是所有数据都为0。因为我们还没有执行task。
当然,可以执行port,使用 --prot参数即可, 如 luigid --port 8088 这个自己去试,就不演示了。
1.2 准备一个task例子
从上一步知道,访问luigid的可视化界面时,所有数据都为0,因为我们还没有跑task。那我们跑一个简单的task,看看是不是就有数据了。
其实官网提供了一个很好的例子: TopArtist的luigi任务代码,但是代码中使用了hdfs存储,我们好多小伙伴可能没有hdfs,自然就跑不起来。安装了hdfs可以尝试跑一下,代码地址如下:
https://github.com/spotify/luigi/blob/master/examples/top_artists.py
这里,我自己写了一个简单的task,我们执行一下看一下效果。
import math
import re
import timeimport jieba
import luigi
from luigi import LocalTarget
import requests
import urllibdef calculate_similarity(text1, text2):s1_cut = [i for i in jieba.cut(text1, cut_all=True) if i != '']s2_cut = [i for i in jieba.cut(text2, cut_all=True) if i != '']word_set = set(s1_cut).union(set(s2_cut))# print(word_set)word_dict = dict()i = 0for word in word_set:word_dict[word] = ii += 1s1_cut_code = [word_dict[word] for word in s1_cut]s1_cut_code = [0] * len(word_dict)for word in s1_cut:s1_cut_code[word_dict[word]] += 1s2_cut_code = [word_dict[word] for word in s2_cut]s2_cut_code = [0] * len(word_dict)for word in s2_cut:s2_cut_code[word_dict[word]] += 1# 计算余弦相似度sum = 0sq1 = 0sq2 = 0for i in range(len(s1_cut_code)):sum += s1_cut_code[i] * s2_cut_code[i]sq1 += pow(s1_cut_code[i], 2)sq2 += pow(s2_cut_code[i], 2)try:result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 2)except ZeroDivisionError:result = 0.0return resultrecord = dict()class MemoryTarget(luigi.Target):def __init__(self, key):self.key = keysuper().__init__()def exists(self):return record.get(self.key, False)def touch(self, value):record[self.key] = valueclass ParseArgs(luigi.Task):def output(self):return MemoryTarget("keyword")def run(self):keyword = "nihao"m = MemoryTarget("keyword")m.touch(keyword)class GenerateUrls(luigi.Task):def requires(self):return ParseArgs()def run(self):keyword = urllib.parse.quote(record.get(self.input().key))urls_dict = dict(biying=f"https://cn.bing.com/search?q={keyword}",s_360=f"https://www.so.com/s?ie=utf-8&fr=none&src=home_none&nlpv=basesc&q={keyword}",sougou=f"https://www.sogou.com/web?query={keyword}")m = MemoryTarget("urls_dict")m.touch(urls_dict)def output(self):return MemoryTarget("urls_dict")class ParsePage(luigi.Task):def requires(self):return GenerateUrls()def run(self):html_string_dict = {}with open("biying.txt", 'r', encoding='UTF8') as f:biying = f.read()with open("s_360.txt", 'r', encoding='UTF8') as f:s_360 = f.read()with open("sougou.txt", 'r', encoding='UTF8') as f:sougou = f.read()html_string_dict.update({"biying": biying, "s_360":s_360, "sougou":sougou})m = MemoryTarget("html_string_dict")m.touch(html_string_dict)def output(self):return MemoryTarget("html_string_dict")class CalculateBiyingAnd360(luigi.Task):def requires(self):return ParsePage()def run(self):string_dict = record.get(self.input().key)t1 = string_dict.get('biying')t2 = string_dict.get('s_360')biying_360_result = calculate_similarity(t1, t2)m = MemoryTarget("biying_360_result")m.touch(biying_360_result)def output(self):return MemoryTarget("biying_360_result")class CalculateBiyingSogou(luigi.Task):def requires(self):return ParsePage()def run(self):string_dict = record.get(self.input().key)t1 = string_dict.get('biying')t2 = string_dict.get('sougou')biying_sougou_result = calculate_similarity(t1, t2)m = MemoryTarget("biying_sougou_result")m.touch(biying_sougou_result)def output(self):return MemoryTarget("biying_sougou_result")class Join(luigi.Task):def requires(self):return {"biying_360": CalculateBiyingAnd360(), "biying_sougou": CalculateBiyingSogou()}def run(self):result_360 = record.get(self.input()["biying_360"].key)result_sougou = record.get(self.input()["biying_sougou"].key)final_result = f"biying and 360 is {result_360}; biying and sougou result is {result_sougou}"m = MemoryTarget("final_result")m.touch(final_result)def output(self):return MemoryTarget("final_result")
执行此代码,分两步:
1、配置环境变量PYTHONPATH
为什么要配置这个东西?(你也可以不理解为什么要配置,直接配置就可以了)
我们使用luigi的命令行工具执行代码,而luigi会把你的py文件当成model执行。
而python对于模块的搜索一定规则,请看我另一篇文章:https://blog.csdn.net/NeverLate_gogogo/article/details/107615838
2、执行命令
luigi --module luigi_cost_time_without_request Join# luigi_cost_time_without_request为py文件的名称
# Join为task任务链的最后一个任务出现下面日志,表示执行成功

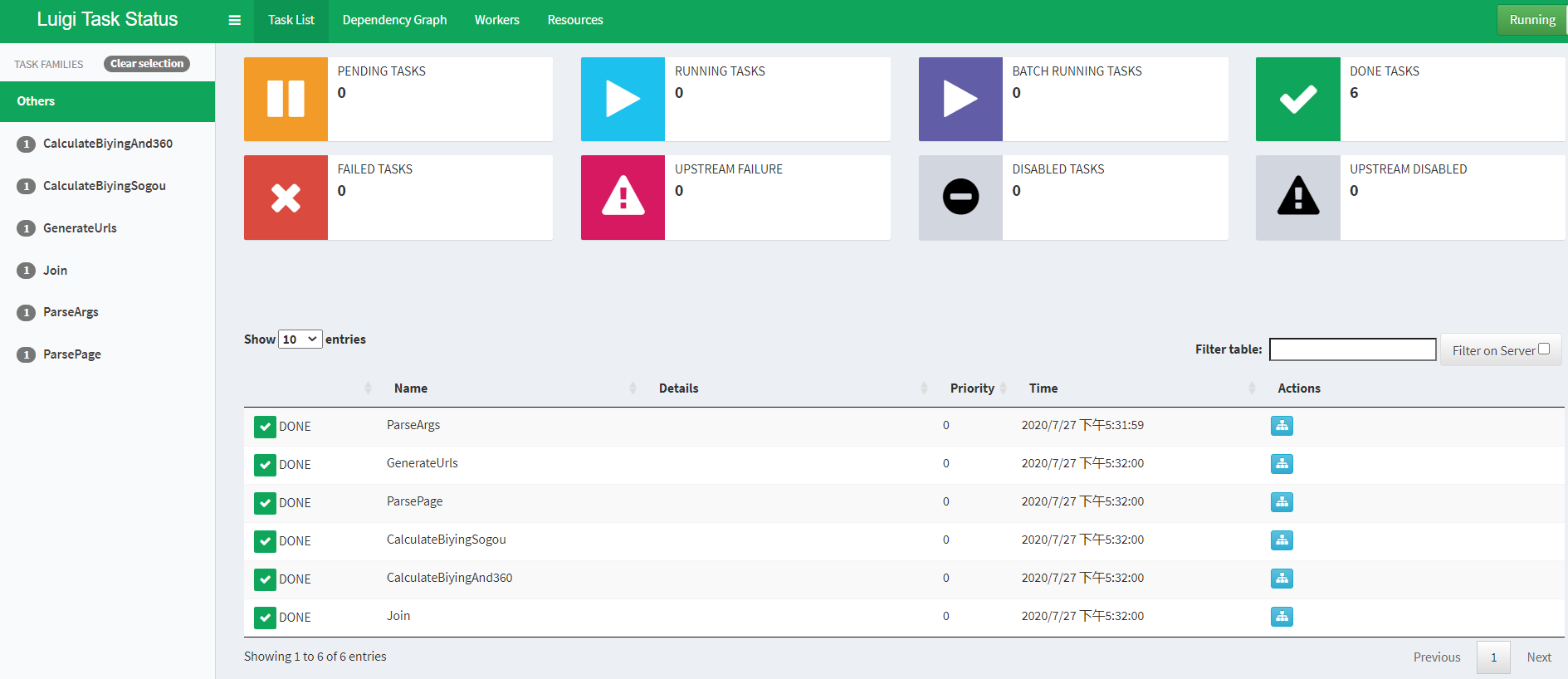
这时,我们再看前端可视化页面发生了变化,将每个task的task_family记录下来,并且任务执行状态记录下来。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!