Lucene搜索引擎,做程序员的你了解多少?
Lucene搜索引擎,做程序员的你了解多少?
- 1.全文解析
- 1.1数据分类
- 1.2结构化数据搜索
- 1.3非结构化数据查询方法
- 1.3.1 顺序扫描法(Serial Scanning)
- 1.3.2 全文检索(Full-text Search)
- 1.4 Lucene源码必须知道的基本规则和算法
- 1.4.1前缀后缀规则(Prefix+Suffix)
- 1.4.2差值规则(Delta)
- 1.4.3LZ4算法(Realtime Compression Algorithm)
- 1.4.4跳跃表规则(Skip list)
- 1.4.5有限自动机算法(FST,Finite State Transducer)
- 2.Lucene实现全文检索的流程
- 2.1索引和搜索流程图
- 2.2创建索引
- 2.2.1获得原始文档
- 2.2.2创建文档对象
- 2.2.3分析文档
- 3.2.4创建索引
- 2.1实际应用
- 2.1.1 导入pom/xml依赖
- 2.1.2 后台代码:
- 2.1.3 前台代码
- 2.1.4 效果图
- 2.2 对索引的增删改
- 2.3文档域加权
- 2.4特定项搜索
1.全文解析
1.1数据分类
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
1.2结构化数据搜索
常见的结构化数据也就是数据库中的数据。在数据库中搜索很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果。
为什么数据库搜索很容易?
因为数据库中的数据存储是有规律的,有行有列而且数据格式、数据长度都是固定的。
1.3非结构化数据查询方法
1.3.1 顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。
1.3.2 全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
1.4 Lucene源码必须知道的基本规则和算法
1.4.1前缀后缀规则(Prefix+Suffix)
在Lucene的反向索引中,要保存词典的信息,所有的词再词典中是按照字典顺序进行排列的,然后词典中包含了文档中的几乎所有的词,并且有的词还是很长的,这样索引文件会非常的大,所谓前缀后缀规则,就是某个词和前一个词有共同的前缀的时候,后面的词仅仅保存前缀在词中的偏移(offset),和剩下的部分(后缀)。
比如:北京天安门 这个词词典里通常都会包含北京 天安门 北京天安门 这三个词。北京和北京天安门由于前缀相同,在字典表里会相邻存储,两个词存成 北京2天安门 ,这样存比北京北京天安门 省空间。
1.4.2差值规则(Delta)
在lucene的反向索引中,需要保存很多整形数字的信息,比如文档ID号,比如词在文档中的位置等等。整形数字是以可变长整型的格式存储的。随着数值的增大,每个数字占用的比特位增多。所谓差值规则就是先后保存两个整数的时候,后面的整数仅仅保存和前面整数的差即可。多唠叨两句:因为看到有的哥哥们定义数据库字段的时候总是想都不想就用varchar,MD5的结果也用varchar[汗]。MD5的结果长度是固定的,没有必要用varchar来节省空间。定长的char效率会高些。
1.4.3LZ4算法(Realtime Compression Algorithm)
在操作系统(linux/freeBSD),文件系统(OpenZFS),大数据(Hadoop),搜索引擎(Lucene/solr),数据库(Hbase)等中都可以看到它的身影,很通用。压缩/解压速度快。
1.4.4跳跃表规则(Skip list)
跳跃表是一种数据结构。额,要不能用几句话把它介绍明白,真不好意思说自己有那么多算法专利。首先使用跳跃表的前提是因为搜索引擎的索引数据是高度有序的。打个比方:我从北京回老家青州市可以做北京南到青岛的动车或者高铁。它们的路线是一样的,后者贵100块钱。贵在哪里呢?后者停的站少,就是跳站了。有的高铁到青州市不停。我只能在前一站淄博或者后一站潍坊下车,然后坐慢车去青州市。跳跃表就是这个原理。所有的搜索数据存在一个链表里,这就是慢车(最传统的绿皮车)。然后新加一个链表,存的数据中间有间隔(K字头车)。这时候我不得不说一个原则:所有原来的时间复杂度是delta(找这个符号比较费劲,我就直接用英文了,记住它是很有好处的,去米国总免不了和这个航空公司打交道~~) n的算法,期待的终极优化后的结果基本都是 delta log n。所以只有两层的话,时间复杂度是达不到要求的。怎样达到要求呢?最终要形成一棵树。怎么形成一棵树呢?加层呗。加大跳站的间隔,T字头车,D字头车,G字头车。一直到中间是所有的站,形成了一个root。树形结构就形成了。时间复杂度变成了delta log n[耶][耶] Lucene3.0之前很多地方使用这种数据结构来提高查找速度。但是因为它对模糊查询的支持不太好,现在Lucene改用FST了。
1.4.5有限自动机算法(FST,Finite State Transducer)
通过输入有序字符串构建最小有向无环图。通过共享前缀来节省空间,内存存放前缀索引,磁盘存放后缀词块。Lucene的源码中可以看到它的具体实现。
有限自动机是Lucene的核心查找算法,理解需要一定的时间。下面介绍Lucene的打分相关规则,这部分很容易理解。
文档权重(Document boost):在索引时给某个文档设置的权重值。
域权重(Field boost):在查询的时候给某个域设置的权重值。
调整因子(Coord):基于文档中包含查询关键词个数计算出来的调整因子。一般而言,如果一个文档中相比其它的文档出现了更多的查询关键词,那么其值越大。
逆文档频率(Inerse document frequency):基于Term的一个因子,存在的意义是告诉打分公式一个词的稀有程度。其值越低,词越稀有(这里的值是指单纯的频率,即多少个文档中出现了该词;而非指Lucene中idf的计算公式)。打分公式利用这个因子提升包含稀有词文档的权重。
长度归一化(Length norm):基于域的一个归一化因子。其值由给定域中Term的个数决定(在索引文档的时候已经计算出来了,并且存储到了索引中)。域越的文本越长,因子的权重越低。这表明Lucene打分公式偏向于域包含Term少的文档。
词频(Term frequency):基于Term的一个因子。用来描述给定Term在一个文档中出现的次数,词频越大,文档的得分越大。
查询归一化因子(Query norm):基于查询语句的归一化因子。其值为查询语句中每一个查询词权重的平方和。查询归一化因子使得比较不同查询语句的得分变得可行,当然比较不同查询语句得分并不总是那么易于实现和可行的。
2.Lucene实现全文检索的流程
2.1索引和搜索流程图
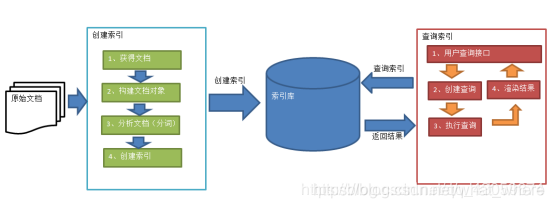
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容采集文档创建文档分析文档索引文档
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面创建查询执行搜索,从索引库搜索渲染搜索结果
2.2创建索引
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。
这里我们要搜索的文档是磁盘上的文本文件,根据案例描述:凡是文件名或文件内容包括关键字的文件都要找出来,这里要对文件名和文件内容创建索引。
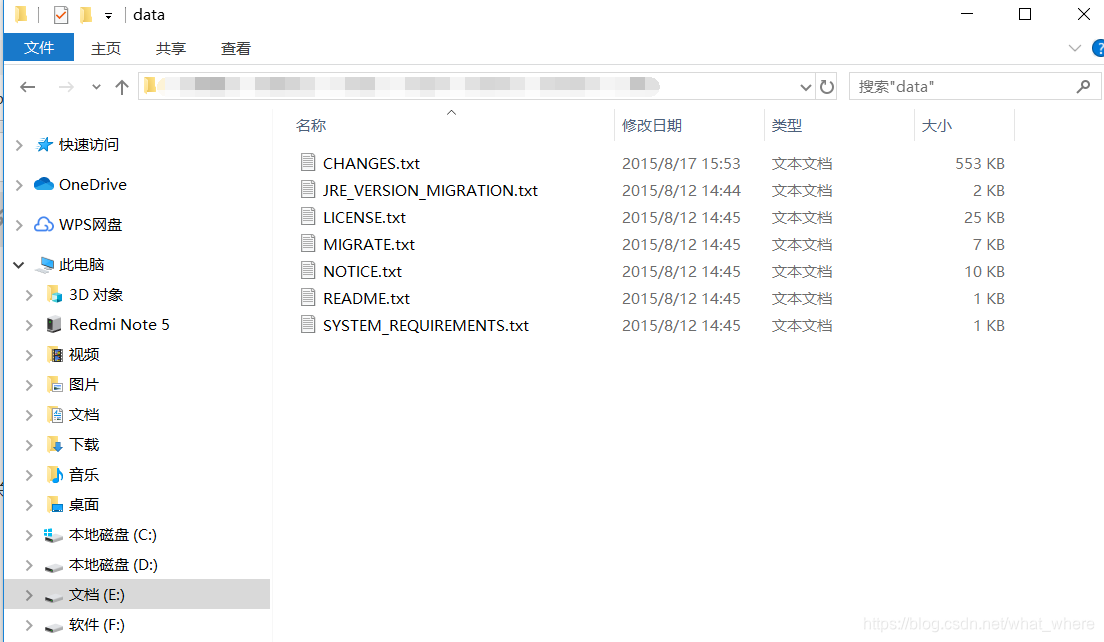
2.2.1获得原始文档
原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。 小编案例中的原始内容就是磁盘上的文件,如下图:
从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,信息采集的目的是为了对原始内容进行索引。
在Internet上采集信息的软件通常称为爬虫或蜘蛛,也称为网络机器人,爬虫访问互联网上的每一个网页,将获取到的网页内容存储起来。
本案例我们要获取磁盘上文件的内容,可以通过文件流来读取文本文件的内容,对于pdf、doc、xls等文件可通过第三方提供的解析工具读取文件内容,比如Apache POI读取doc和xls的文件内容。
2.2.2创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field 相当于数据库中的列段),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(fileName文件名称、fullPath文件路径、contents文件内容),如下图:
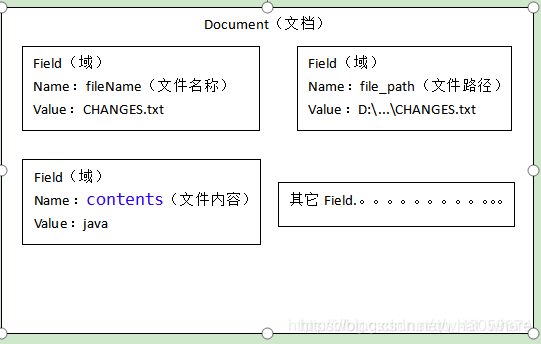
注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)
每个文档都有一个唯一的编号,就是文档id。
2.2.3分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
比如下边的文档经过分析如下:
原文档内容:
Lucene is a Java full-text search engine. Lucene is not a complete
application, but rather a code library and API that can easily be used
to add search capabilities to applications.
分析后得到的语汇单元:
lucene、java、full、search、engine。。。。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。
例如:文件名中包含apache和文件内容中包含的apache是不同的term。
3.2.4创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被 索引的语汇单元从而找到Document(文档)。
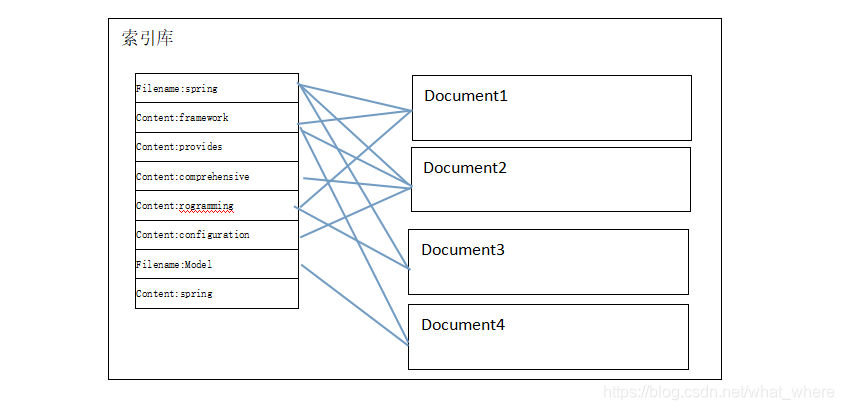
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。
倒排索引结构是根据内容(词语)找文档,如下图:
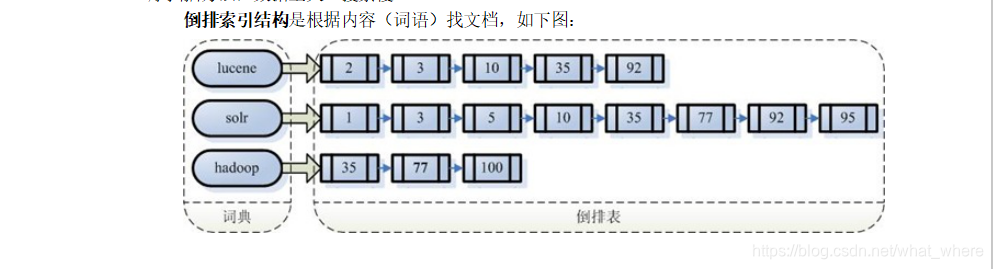
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
2.1实际应用
2.1.1 导入pom/xml依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.javaxl</groupId><artifactId>javaxl_lunece_freemarker</artifactId><packaging>war</packaging><version>0.0.1-SNAPSHOT</version><name>javaxl_lunece_freemarker Maven Webapp</name><url>http://maven.apache.org</url><properties><httpclient.version>4.5.2</httpclient.version><jsoup.version>1.10.1</jsoup.version><!-- <lucene.version>7.1.0</lucene.version> --><lucene.version>5.3.1</lucene.version><ehcache.version>2.10.3</ehcache.version><junit.version>4.12</junit.version><log4j.version>1.2.16</log4j.version><mysql.version>5.1.44</mysql.version><fastjson.version>1.2.47</fastjson.version><struts2.version>2.5.16</struts2.version><servlet.version>4.0.1</servlet.version><jstl.version>1.2</jstl.version><standard.version>1.1.2</standard.version><tomcat-jsp-api.version>8.0.47</tomcat-jsp-api.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>${junit.version}</version><scope>test</scope></dependency><!-- jdbc驱动包 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><!-- 添加Httpclient支持 --><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>${httpclient.version}</version></dependency><!-- 添加jsoup支持 --><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>${jsoup.version}</version></dependency><!-- 添加日志支持 --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>${log4j.version}</version></dependency><!-- 添加ehcache支持 --><dependency><groupId>net.sf.ehcache</groupId><artifactId>ehcache</artifactId><version>${ehcache.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version></dependency><dependency><groupId>org.apache.struts</groupId><artifactId>struts2-core</artifactId><version>${struts2.version}</version></dependency><dependency><groupId>javax.servlet</groupId><artifactId>javax.servlet-api</artifactId><version>${servlet.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>${lucene.version}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>${lucene.version}</version></dependency><!-- <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>${lucene.version}</version> </dependency> --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-smartcn</artifactId><version>${lucene.version}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>${lucene.version}</version></dependency><!-- 5.3、jstl、standard --><dependency><groupId>jstl</groupId><artifactId>jstl</artifactId><version>${jstl.version}</version></dependency><dependency><groupId>taglibs</groupId><artifactId>standard</artifactId><version>${standard.version}</version></dependency><!-- 5.4、tomcat-jsp-api --><dependency><groupId>org.apache.tomcat</groupId><artifactId>tomcat-jsp-api</artifactId><version>${tomcat-jsp-api.version}</version></dependency></dependencies><build><finalName>javaxl_lunece_freemarker</finalName><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.7.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin></plugins></build>
</project>2.1.2 后台代码:
BlogAciton.java
package com.javaxl.blog.web;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;import javax.servlet.http.HttpServletRequest;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.store.Directory;
import org.apache.struts2.ServletActionContext;import com.javaxl.blog.dao.BlogDao;
import com.javaxl.blog.util.LuceneUtil;
import com.javaxl.blog.util.PropertiesUtil;
import com.javaxl.blog.util.StringUtils;/*** IndexReader* IndexSearcher* Highlighter* @author Administrator**/
public class BlogAction {private String title;private BlogDao blogDao = new BlogDao();public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public String list() {try {HttpServletRequest request = ServletActionContext.getRequest();if (StringUtils.isBlank(title)) {List<Map<String, Object>> blogList = this.blogDao.list(title, null);request.setAttribute("blogList", blogList);}else {Directory directory = LuceneUtil.getDirectory(PropertiesUtil.getValue("indexPath"));DirectoryReader reader = LuceneUtil.getDirectoryReader(directory);IndexSearcher searcher = LuceneUtil.getIndexSearcher(reader);SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
// 拿一句话到索引目中的索引文件中的词库进行关键词碰撞Query query = new QueryParser("title", analyzer).parse(title);Highlighter highlighter = LuceneUtil.getHighlighter(query, "title");TopDocs topDocs = searcher.search(query , 100);//处理得分命中的文档List<Map<String, Object>> blogList = new ArrayList<>();Map<String, Object> map = null;ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {map = new HashMap<>();Document doc = searcher.doc(scoreDoc.doc);map.put("id", doc.get("id"));String titleHighlighter = doc.get("title");if(StringUtils.isNotBlank(titleHighlighter)) {titleHighlighter = highlighter.getBestFragment(analyzer, "title", titleHighlighter);}map.put("title", titleHighlighter);map.put("url", doc.get("url"));blogList.add(map);}request.setAttribute("blogList", blogList);}} catch (Exception e) {e.printStackTrace();}return "blogList";}
}BlogDao.java dao方法
package com.javaxl.blog.dao;import java.sql.SQLException;
import java.util.List;
import java.util.Map;import com.javaxl.blog.util.JsonBaseDao;
import com.javaxl.blog.util.PageBean;
import com.javaxl.blog.util.StringUtils;public class BlogDao extends JsonBaseDao{public List<Map<String,Object>> list(String title, PageBean pageBean) throws InstantiationException, IllegalAccessException, SQLException{String sql = "select * from t_lucene_crawler_blog where 1=1";if(StringUtils.isNotBlank(title)) {sql += " and title like '%"+title+"%'";}return super.executeQuery(sql, pageBean);}public int save(Map<String,String[]> paMap) throws InstantiationException, IllegalAccessException, SQLException, NoSuchFieldException, SecurityException, IllegalArgumentException{String sql = "insert into t_lucene_crawler_blog values(?,?,?,?,0)";return super.executeUpdate(sql, new String[] {"id","title","content","url"}, paMap);}}调用方法 LuceneUilts
package com.javaxl.blog.util;import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.highlight.Formatter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryTermScorer;
import org.apache.lucene.search.highlight.Scorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;/*** lucene工具类* @author Administrator**/
public class LuceneUtil {/*** 获取索引文件存放的文件夹对象* * @param path* @return*/public static Directory getDirectory(String path) {Directory directory = null;try {directory = FSDirectory.open(Paths.get(path));} catch (IOException e) {e.printStackTrace();}return directory;}/*** 索引文件存放在内存* * @return*/public static Directory getRAMDirectory() {Directory directory = new RAMDirectory();return directory;}/*** 文件夹读取对象* * @param directory* @return*/public static DirectoryReader getDirectoryReader(Directory directory) {DirectoryReader reader = null;try {reader = DirectoryReader.open(directory);} catch (IOException e) {e.printStackTrace();}return reader;}/*** 文件索引对象* * @param reader* @return*/public static IndexSearcher getIndexSearcher(DirectoryReader reader) {IndexSearcher indexSearcher = new IndexSearcher(reader);return indexSearcher;}/*** 写入索引对象* * @param directory* @param analyzer* @return*/public static IndexWriter getIndexWriter(Directory directory, Analyzer analyzer){IndexWriter iwriter = null;try {IndexWriterConfig config = new IndexWriterConfig(analyzer);config.setOpenMode(OpenMode.CREATE_OR_APPEND);// Sort sort=new Sort(new SortField("content", Type.STRING));// config.setIndexSort(sort);//排序config.setCommitOnClose(true);// 自动提交// config.setMergeScheduler(new ConcurrentMergeScheduler());// config.setIndexDeletionPolicy(new// SnapshotDeletionPolicy(NoDeletionPolicy.INSTANCE));iwriter = new IndexWriter(directory, config);} catch (IOException e) {e.printStackTrace();}return iwriter;}/*** 关闭索引文件生成对象以及文件夹对象* * @param indexWriter* @param directory*/public static void close(IndexWriter indexWriter, Directory directory) {if (indexWriter != null) {try {indexWriter.close();} catch (IOException e) {indexWriter = null;}}if (directory != null) {try {directory.close();} catch (IOException e) {directory = null;}}}/*** 关闭索引文件读取对象以及文件夹对象* * @param reader* @param directory*/public static void close(DirectoryReader reader, Directory directory) {if (reader != null) {try {reader.close();} catch (IOException e) {reader = null;}}if (directory != null) {try {directory.close();} catch (IOException e) {directory = null;}}}/*** 高亮标签* * @param query* @param fieldName* @return*/public static Highlighter getHighlighter(Query query, String fieldName){Formatter formatter = new SimpleHTMLFormatter("", "");Scorer fragmentScorer = new QueryTermScorer(query, fieldName);Highlighter highlighter = new Highlighter(formatter, fragmentScorer);highlighter.setTextFragmenter(new SimpleFragmenter(200));return highlighter;}
}创建 数据库 索引
package com.javaxl.blog.web;import java.io.IOException;
import java.nio.file.Paths;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;import com.javaxl.blog.dao.BlogDao;
import com.javaxl.blog.util.PropertiesUtil;/*** 构建lucene索引* @author Administrator* 1。构建索引 IndexWriter* 2、读取索引文件,获取命中片段* 3、使得命中片段高亮显示**/
public class IndexStarter {private static BlogDao blogDao = new BlogDao();public static void main(String[] args) {IndexWriterConfig conf = new IndexWriterConfig(new SmartChineseAnalyzer());Directory d;IndexWriter indexWriter = null;try {d = FSDirectory.open(Paths.get(PropertiesUtil.getValue("indexPath")));indexWriter = new IndexWriter(d , conf );// 为数据库中的所有数据构建索引List<Map<String, Object>> list = blogDao.list(null, null);for (Map<String, Object> map : list) {Document doc = new Document();doc.add(new StringField("id", (String) map.get("id"), Field.Store.YES));
// TextField用于对一句话分词处理 java培训机构doc.add(new TextField("title", (String) map.get("title"), Field.Store.YES));doc.add(new StringField("url", (String) map.get("url"), Field.Store.YES));indexWriter.addDocument(doc);}} catch (IOException e) {e.printStackTrace();} catch (InstantiationException e) {e.printStackTrace();} catch (IllegalAccessException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();}finally {try {if(indexWriter!= null) {indexWriter.close();}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}
}
2.1.3 前台代码
<%@ page language="java" contentType="text/html; charset=UTF-8"pageEncoding="UTF-8"%><%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
</head>
<body>
<form action="${pageContext.request.contextPath}/sy/blog_list.action"method="post">博客标题:<input type="text" name="title"> <input type="submit"value="确定"></form><button id="add">添加</button><button id="refresh">刷新全局索引</button><table border="1" width="100%"><tr><td>编号</td><td>名称</td><td>价格</td><td>操作</td></tr><c:forEach items="${blogList }" var="blog"><tr><td>${blog.id }</td><td>${blog.title }</td><td><a href="${blog.url }">${blog.title }</a></td><td><a href="">修改</a><a href="">删除</a></td></tr></c:forEach></table>
</body>
</html>
2.1.4 效果图

2.2 对索引的增删改
package com.cpc.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;/*** 构建索引* 对索引的增删改* @author Administrator**/
public class Demo3 {private String ids[]={"1","2","3"};private String citys[]={"qingdao","nanjing","shanghai"};private String descs[]={"Qingdao is a beautiful city.","Nanjing is a city of culture.","Shanghai is a bustling city."};private FSDirectory dir;/*** 每次都生成索引文件* @throws Exception*/@Beforepublic void setUp() throws Exception {dir = FSDirectory.open(Paths.get("D:\\temp\\demo2\\indexDir"));IndexWriter indexWriter = getIndexWriter();for (int i = 0; i < ids.length; i++) {Document doc = new Document();doc.add(new StringField("id", ids[i], Field.Store.YES));doc.add(new StringField("city", citys[i], Field.Store.YES));doc.add(new TextField("desc", descs[i], Field.Store.NO));indexWriter.addDocument(doc);}indexWriter.close();}/*** 获取索引输出流* @return* @throws Exception*/private IndexWriter getIndexWriter() throws Exception{Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig conf = new IndexWriterConfig(analyzer);return new IndexWriter(dir, conf );}/*** 测试写了几个索引文件* @throws Exception*/@Testpublic void getWriteDocNum() throws Exception {IndexWriter indexWriter = getIndexWriter();System.out.println("索引目录下生成"+indexWriter.numDocs()+"个索引文件");}/*** 打上标记,该索引实际并未删除* @throws Exception*/@Testpublic void deleteDocBeforeMerge() throws Exception {IndexWriter indexWriter = getIndexWriter();System.out.println("最大文档数:"+indexWriter.maxDoc());indexWriter.deleteDocuments(new Term("id", "1"));indexWriter.commit();System.out.println("最大文档数:"+indexWriter.maxDoc());System.out.println("实际文档数:"+indexWriter.numDocs());indexWriter.close();}/*** 对应索引文件已经删除,但是该版本的分词会保留* @throws Exception*/@Testpublic void deleteDocAfterMerge() throws Exception {
// https://blog.csdn.net/asdfsadfasdfsa/article/details/78820030
// org.apache.lucene.store.LockObtainFailedException: Lock held by this virtual machine:indexWriter是单例的、线程安全的,不允许打开多个。IndexWriter indexWriter = getIndexWriter();System.out.println("最大文档数:"+indexWriter.maxDoc());indexWriter.deleteDocuments(new Term("id", "1"));indexWriter.forceMergeDeletes(); //强制删除indexWriter.commit();System.out.println("最大文档数:"+indexWriter.maxDoc());System.out.println("实际文档数:"+indexWriter.numDocs());indexWriter.close();}/*** 测试更新索引* @throws Exception*/@Testpublic void testUpdate()throws Exception{IndexWriter writer=getIndexWriter();Document doc=new Document();doc.add(new StringField("id", "1", Field.Store.YES));doc.add(new StringField("city","qingdao",Field.Store.YES));doc.add(new TextField("desc", "dsss is a city.", Field.Store.NO));writer.updateDocument(new Term("id","1"), doc);writer.close();}
}效果图:
新增索引

删除索引
合并前

合并后:

注意: 数据量大时用合并前的删除,只是给索引文件打标,定时清理打标的索引文件。 数据量不是特别大的时候,可以及时删除索引文件。
2.3文档域加权
package com.cpc.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;/*** 文档域加权* @author Administrator**/
public class Demo4 {private String ids[]={"1","2","3","4"};private String authors[]={"Jack","Marry","John","Json"};private String positions[]={"accounting","technician","salesperson","boss"};private String titles[]={"Java is a good language.","Java is a cross platform language","Java powerful","You should learn java"};private String contents[]={"If possible, use the same JRE major version at both index and search time.","When upgrading to a different JRE major version, consider re-indexing. ","Different JRE major versions may implement different versions of Unicode,","For example: with Java 1.4, `LetterTokenizer` will split around the character U+02C6,"};private Directory dir;//索引文件目录@Beforepublic void setUp()throws Exception {dir = FSDirectory.open(Paths.get("D:\\temp\\demo3\\indexDir"));IndexWriter writer = getIndexWriter();for (int i = 0; i < authors.length; i++) {Document doc = new Document();doc.add(new StringField("id", ids[i], Field.Store.YES));doc.add(new StringField("author", authors[i], Field.Store.YES));doc.add(new StringField("position", positions[i], Field.Store.YES));TextField textField = new TextField("title", titles[i], Field.Store.YES);// Json投钱做广告,把排名刷到第一了if("boss".equals(positions[i])) {textField.setBoost(2f);//设置权重,默认为1}doc.add(textField);
// TextField会分词,StringField不会分词doc.add(new TextField("content", contents[i], Field.Store.NO));writer.addDocument(doc);}writer.close();}private IndexWriter getIndexWriter() throws Exception{Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig conf = new IndexWriterConfig(analyzer);return new IndexWriter(dir, conf);}@Testpublic void index() throws Exception{IndexReader reader = DirectoryReader.open(dir);IndexSearcher searcher = new IndexSearcher(reader);String fieldName = "title";String keyWord = "java";Term t = new Term(fieldName, keyWord);Query query = new TermQuery(t);TopDocs hits = searcher.search(query, 10);System.out.println("关键字:‘"+keyWord+"’命中了"+hits.totalHits+"次");for (ScoreDoc scoreDoc : hits.scoreDocs) {Document doc = searcher.doc(scoreDoc.doc);System.out.println(doc.get("author"));}}
}文档域加权前结果:

文档域加权后结果变成:

2.4特定项搜索
package com.cpc.lucene;import java.io.IOException;
import java.nio.file.Paths;import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;/*** 特定项搜索* 查询表达式(queryParser)* @author Administrator**/
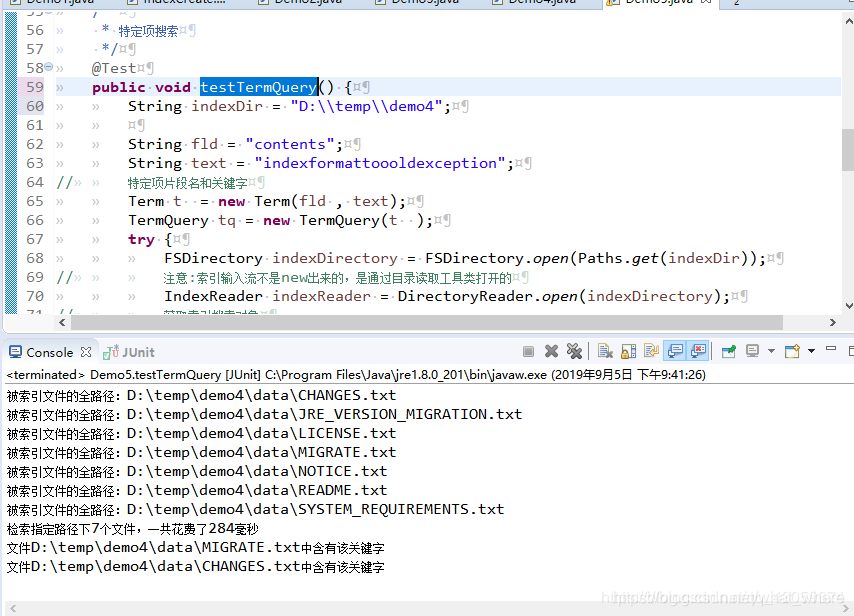
public class Demo5 {@Beforepublic void setUp() {// 索引文件将要存放的位置String indexDir = "D:\\temp\\demo4";// 数据源地址String dataDir = "D:\\temp\\demo4\\data";IndexCreate ic = null;try {ic = new IndexCreate(indexDir);long start = System.currentTimeMillis();int num = ic.index(dataDir);long end = System.currentTimeMillis();System.out.println("检索指定路径下" + num + "个文件,一共花费了" + (end - start) + "毫秒");} catch (Exception e) {e.printStackTrace();} finally {try {ic.closeIndexWriter();} catch (Exception e) {e.printStackTrace();}}}/*** 特定项搜索*/@Testpublic void testTermQuery() {String indexDir = "D:\\temp\\demo4";String fld = "contents";String text = "indexformattoooldexception";
// 特定项片段名和关键字Term t = new Term(fld , text);TermQuery tq = new TermQuery(t );try {FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));
// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的IndexReader indexReader = DirectoryReader.open(indexDirectory);
// 获取索引搜索对象IndexSearcher is = new IndexSearcher(indexReader);TopDocs hits = is.search(tq, 100);
// System.out.println(hits.totalHits);for(ScoreDoc scoreDoc: hits.scoreDocs) {Document doc = is.doc(scoreDoc.doc);System.out.println("文件"+doc.get("fullPath")+"中含有该关键字");}} catch (IOException e) {e.printStackTrace();}}@Testpublic void testQueryParser() {String indexDir = "D:\\temp\\demo4";
// 获取查询解析器(通过哪种分词器去解析哪种片段)QueryParser queryParser = new QueryParser("contents", new StandardAnalyzer());try {FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));
// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的IndexReader indexReader = DirectoryReader.open(indexDirectory);
// 获取索引搜索对象IndexSearcher is = new IndexSearcher(indexReader);// 由解析器去解析对应的关键字TopDocs hits = is.search(queryParser.parse("indexformattoooldexception") , 100);for(ScoreDoc scoreDoc: hits.scoreDocs) {Document doc = is.doc(scoreDoc.doc);System.out.println("文件"+doc.get("fullPath")+"中含有该关键字"); }} catch (IOException e) {e.printStackTrace();} catch (ParseException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}
效果图:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!