yolov5的简单应用:滑块验证码缺口识别
滑块验证码缺口位置识别(yolov5)
- 一,数据集处理
- 二,数据标注,格式化
- 1.下载地址
- 2.傻瓜式安装
- 3.创建虚拟环境
- 4.激活环境
- 5. 安装依赖包
- 6.安装labelme
- 7. 打开labelme进行标注
- 三,模型训练
- 1.数据分组
- 2.配置data.yaml
- 3.开始训练
- 3. 测试模型
- 结束!
一,数据集处理
这里直接选取某验在线体验,接口比较简单,也没有反爬,我这里采集了一百张左右
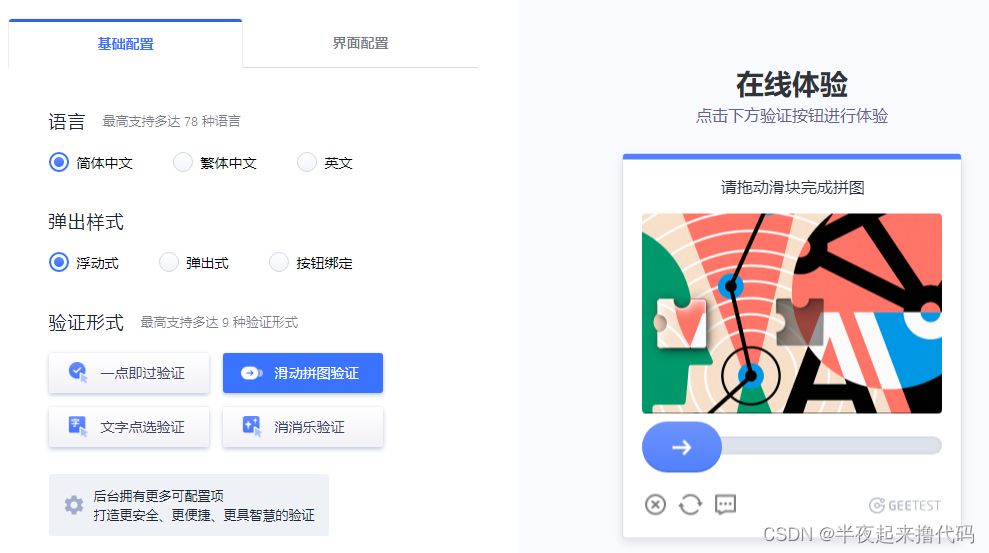
采集代码示例
import requests, json, timesession = requests.session()
session.headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"
}url = "https://xxxx.xxxx.com/load"for i in range(100):callback = f"geetest_{int(time.time() * 1000)}"params = {"captcha_id": "xxxx","challenge": "xxxx","client_type": "web","risk_type": "slide","lang": "zh","callback": callback,}resp = session.get(url=url, params=params)html = resp.textresp_json = json.loads(html.replace(callback, "")[1:-1]).get("data")img_url = "https://static.geetest.com/" + resp_json["bg"]resp = session.get(url=img_url)with open(f"img/{i + 1}.png", "wb") as w1:w1.write(resp.content)
二,数据标注,格式化
这里使用的是网络上开源的数据标注工具labelme。我这里是使用anaconda环境进行安装的。
1.下载地址
https://www.anaconda.com/products/individual
2.傻瓜式安装
......
3.创建虚拟环境
conda create -n labelme python=3.6
4.激活环境
conda activate labelme
5. 安装依赖包
conda install pyqt pillow
6.安装labelme
conda install labelme=3.16.2
7. 打开labelme进行标注
labelme
这里贴一张网图
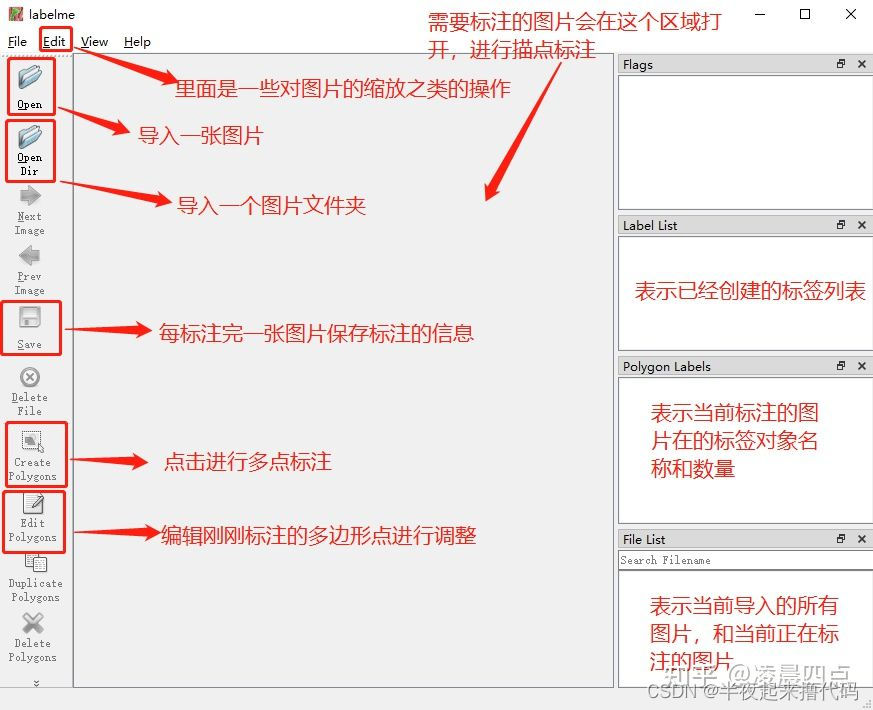
开始一张一张标注,保存标注信息
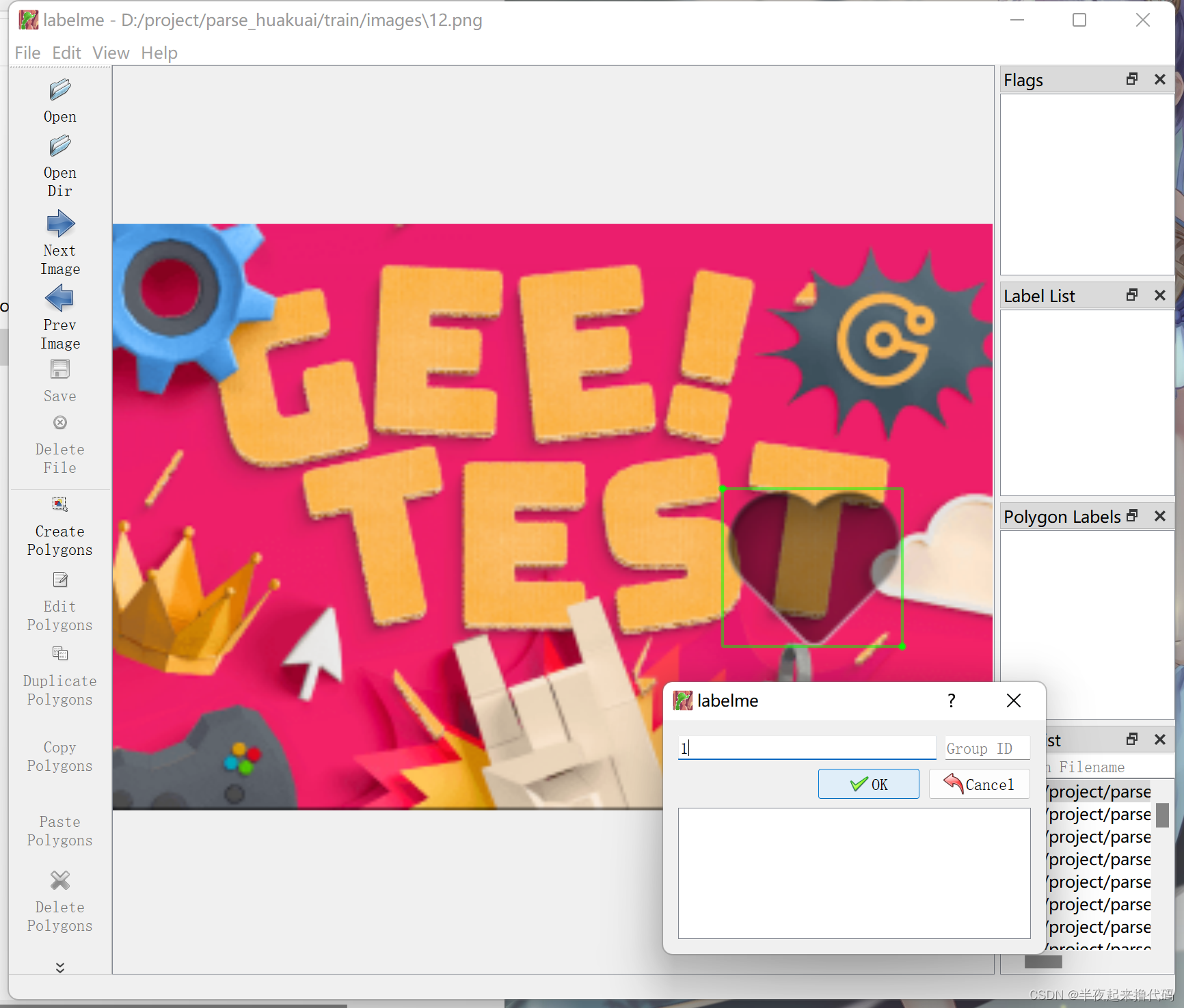
标注的结果是json文件,类似这种
{"version": "5.0.1","flags": {},"shapes": [{"label": "1","points": [[280.38461538461536,65.15384615384613],[346.15384615384613,134.38461538461536]],"group_id": null,"shape_type": "rectangle","flags": {}}],"imagePath": "1.png","imageHeight": 190,"imageWidth": 500
}
这里需要把他转成yolo专用的格式,方便训练
转换代码如下
import os,jsondef jsonToTxt(data_json):"""需要从json数据中获取的信息图片尺寸、标签类型、标注中心点坐标、标注目标尺寸:param data_json:json数据:return:[“ ”,]""" # 图片的宽和高image_width = data_json.get("imageWidth")image_height = data_json.get("imageHeight")box_list = []for i in data_json.get("shapes",[]):# 标签类型# labels = i.get("labels")label = "1"# 标签坐标label_x= i.get("points")[0][0]label_y = i.get("points")[0][1]# 标签大小label_width = i.get("points")[1][0]-label_xlabel_height = i.get("points")[1][1]-label_y# 计算中心点坐标(归一后)central_point_x = (label_x + (label_width/2))/image_widthcentral_point_y = (label_y + (label_height/2))/image_height# 标签的宽和高(归一后)label_width = label_width/image_widthlabel_height = label_height/image_heightresult = [str(label), str(central_point_x), str(central_point_y), str(label_width), str(label_height)]box_list.append(result)return box_listif __name__ == '__main__':# 需要格式化的标签路径source_path = r"img"for i in os.listdir(source_path):if i.endswith(".json"):# 读取标签json数据with open(f"{source_path}/{i}","r",encoding="utf-8") as r1:data_json = r1.read()# 转为python数据data_json = json.loads(data_json.strip())# 进行yolov5数据转换result = jsonToTxt(data_json)# 数据按yolov5格式保存with open(f"label/{i.replace('json', 'txt')}", "w", encoding="utf-8") as w1:w1.write('\n'.join([' '.join(i) for i in result]))
补一下处理好的数据:数据集
三,模型训练
1.数据分组
把数据分成训练集和验证集,创建两个文件夹且二级目录分别创建 images目录(放图片)和labels目录(放标注信息)
训练集我放了85张图片和对应标注信息,
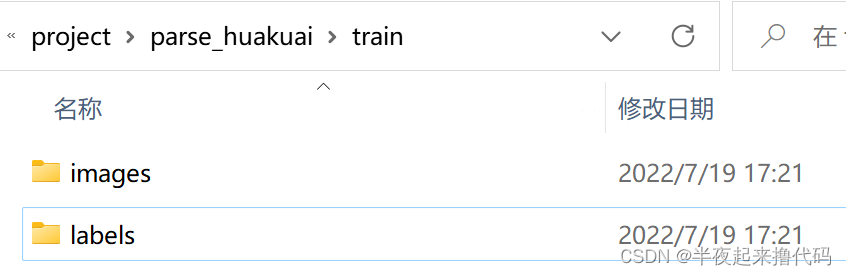
验证集我放了15张图片和对应标注信息
2.配置data.yaml
# train:训练集绝对路径
# val:验证集绝对路径
# nc:类别数量
# names:类别列表
train: D:/project/parse_huakuai/train/images
val: D:/project/parse_huakuai/valid/images
nc: 1
names: ["lable1"]
还有其他参数可以去探索…
3.开始训练
打开yolov5项目,源码地址:yolov5
初次下载后需要配置下环境,装一下依赖包等等…
常用配置参数介绍
--data(必选)数据集的yaml文件路径 ./dianxuan/data.yaml
--cfg(必选)训练的配置yaml,在yolov5的models目录中 ./models/yolov5s.yaml
--batch-size(必选)所有gpu的总批处理大小,-1表示自动批处理 ,默认16
--single-cls训练任务的单类为store_false,多类为store_true
--resume指定上次训练的结果继续训练 last.pt
--epochs训练迭代次数
--batch-size每次送给神经网络的图片数目
--imgsz训练图片尺寸
--device训练使用cpu还是gpu
cmd执行命令
python train.py --data D:/project/parse_huakuai/data.yaml --cfg ./models/yolov5s.yaml --batch-size 8
等待训练完成
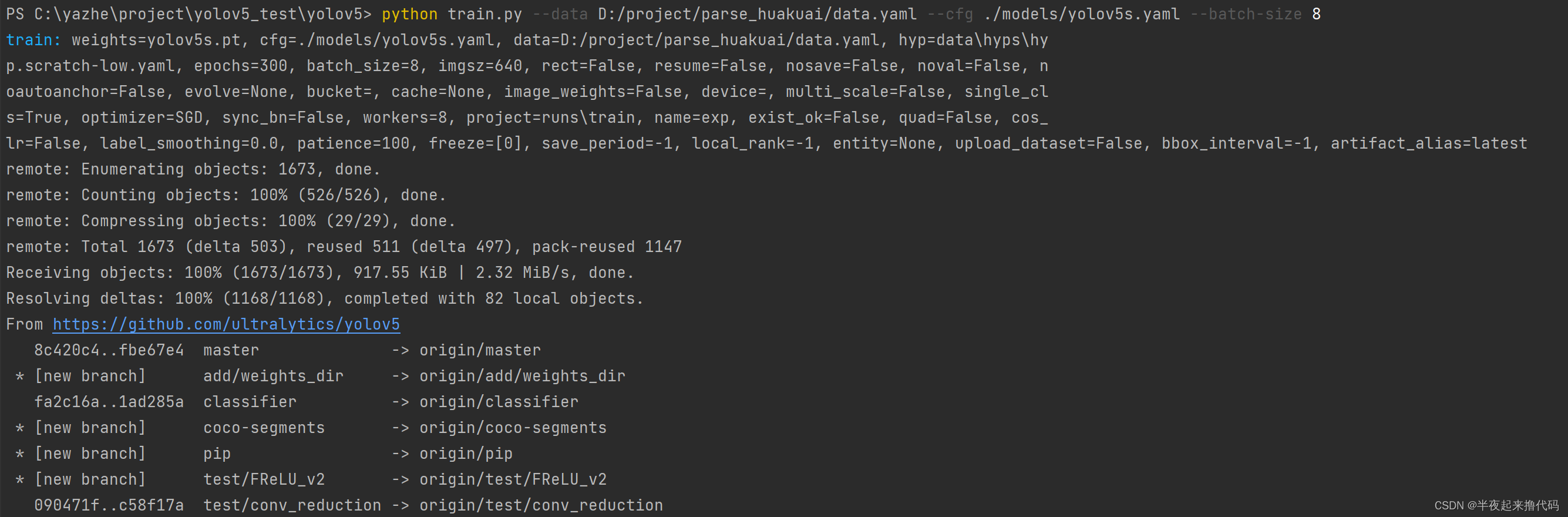
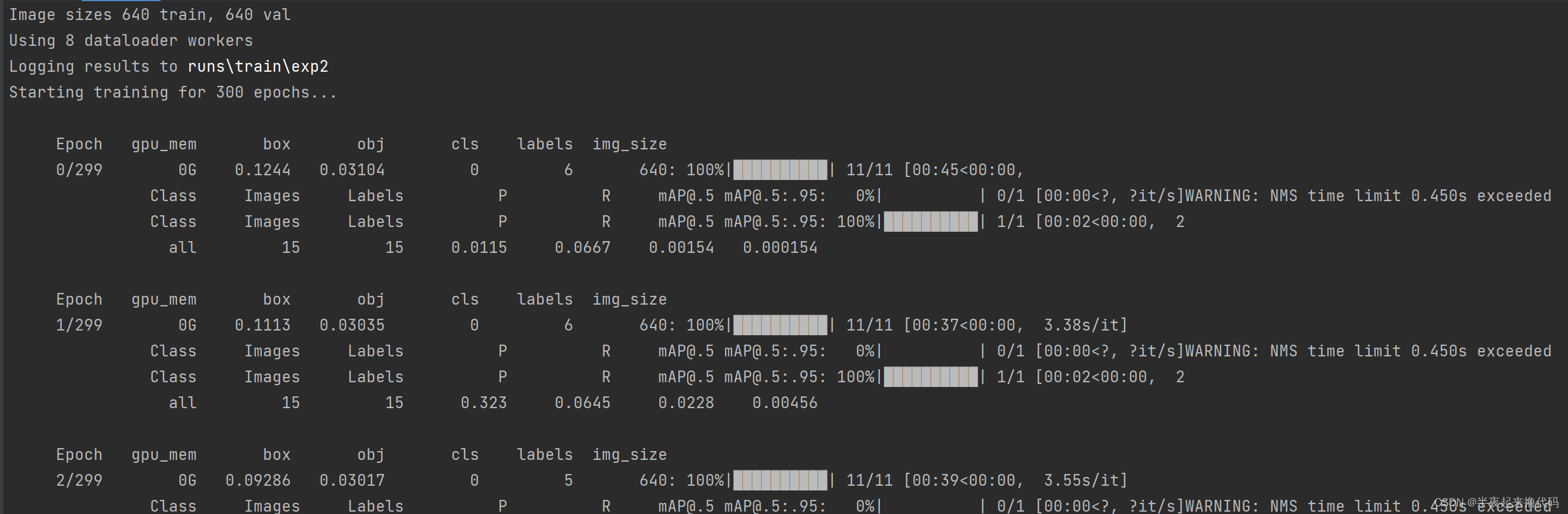
训练完成后,在项目目录找到模型文件,一般是yolov5目录下/runs/train下的目录,找最新的exp/weights下bast.pt,两个文件一个是最后的[last],另一个是最好的[bast]
3. 测试模型
选取一张全新的验证码图片
python detect.py --source ./7_1.png --weights ./runs/train/exp2/weights/best.pt
测试结果在项目下 runs/detect 中查看,测试了几张基本都能正确识别,准确率还是不错的,感觉有点大材小用了


本文仅作记录,分享交流,不喜勿喷,后面分享怎么对接接口使用
结束!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!