FNet: Mixing Tokens with Fourier Transforms --粗读
摘要
我们证明,通过用简单的线性转换可以取代自注意力层,transformer编码器架构可以通过“混合”输入标记的线性转换来大幅提高速度,精度成本有限。这些线性变换,以及前馈层中简单的非线性层,足以在几个文本分类任务中建模语义关系。也许最令人惊讶的是,我们发现用标准的、非参数化的傅里叶变换替换transformer编码器中的自我注意层在GLUE基准上实现了92%的精度,但在GPU上运行速度快7倍,在TPU上快两倍。所得到的模型,我们命名为FNet,非常有效地扩展到长输入,与 the Long Range Arena benchmark上最精确的“高效的”transformer的精度相匹配,但在GPU上的所有序列长度和TPU上相对较短的序列长度上训练和运行得更快。最后,FNet具有较轻的内存占用,在较小的模型尺寸下特别有效:对于固定的速度和精度预算,小的FNet模型优于transformer对应的模型。
引言
在这项工作中,我们研究了是否使用一个简单的混合机制就可以完全取代trans类体系结构中相对复杂的注意力层。我们首先用两个参数化的矩阵乘法来替换注意力子层——一种是混合序列维数,另一种是混合隐藏维数。看到在这个简单的线性混合方案的有希望的结果,我们进一步研究了更快的,结构化的线性变换的有效性。令人惊讶的是,我们发现傅里叶变换,尽管没有参数,但达到了与致密线性混合相同的性能,并且非常有效地扩展到长输入,特别是在GPU上(FFT由于快速傅里叶变换)。我们称结果得到的模型为FNet。
通过用线性转换替换注意力层,我们能够减少trans体系结构的复杂性和内存占用。我们表明,FNet在速度、内存占用和准确性之间提供了很好的妥协,在GLUE基准上的常见分类转移学习设置中实现了92%的精度(Wang等人,2018),但在GPU上训练的速度是7倍,在TPU上的两倍。除了这些实际的考虑,值得注意的是,在前馈子层中,由离散的傅里叶变换系数促进,加上简单的非线性,足以建模GLUE任务。
我们还表明,一个只有两个自注意力层的FNet混合模型在GLUE基准测试上达到了BERT精度的97%,但是GPU上的训练速度几乎是它的六倍,而TPU上的训练速度则是它的两倍。
在第四节中,我们以两组实验结果的形式总结了本文的主要结果:
在第4.1节中,我们比较了FNet、BERT(Devlin等人,2018)和转移学习设置中的几个简单基线——屏蔽语言建模(MLM)和下次句子预测(NSP)预训练,然后在GLUE基准上进行微调。在第4.2节中,我们表明FNet比the Long Range Arena benchmark中评估的高效trans的大多数trans提供了更好的协调(Tay等人,2020c)。
model
核心:离散傅里叶变换
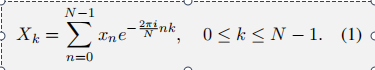
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!