人工智能学习(八)Attention机制中的位置编码(固定)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、为什么要引入位置编码
- 二、位置编码的实现方式
- 2.1 位置编码实现
- 2.1 绝对位置编码信息
- 2.2 相对位置编码信息
提示:以下是本篇文章正文内容,下面案例可供参考
一、为什么要引入位置编码
我们都知道Attention是一种模拟生物注意力的机制。我们可以通过简单的全连接层或者汇聚层来实现非自主性注意力。也可以通过注意力机制即查询匹配的方式来实现自主性的注意力。
同样注意力机制在NLP中虽然能够较好应对长句子的情况,但是他的计算复杂度也会比RNN或者CNN的方式要高,不同它的优点在于可以很好的利用矩阵向量化的思想来完成并行操作。
为了能够实现并行操作,注意力机制丢掉了在时序问题中非常重要的顺序,为了解决这个问题,我们考虑引入位置编码这一方案。
补充:在这里,我们主要考虑固定的位置编码,不考虑可学习的位置编码。
二、位置编码的实现方式
2.1 位置编码实现
我们在这里考虑使用的位置编码方式为基于余弦和正弦函数的位置编码方案。
具体公式如下:
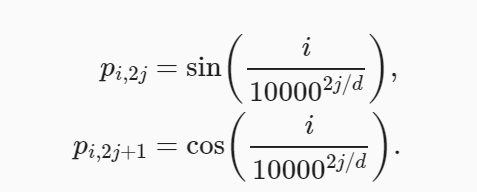
其中p表示对应的位置编码矩阵。 i i i表示行, j j j表示列,我们可以发现该位置编码方案是奇偶列相互交替变换的。那么我们为什么需要使用基于正余弦的方式来实现位置编码呢?在后续的2.1和2.2节中会有相应的讨论和解释。
import math
import torch
import torch.nn as nn# position encode
# based on cos or sin function
class PositionEncoding(nn.Module):def __init__(self,num_hiddens,max_len:int=1000):super(PositionEncoding, self).__init__()self.pos=torch.zeros(size=(1,max_len,num_hiddens))X=torch.arange(max_len,dtype=torch.float32).reshape(-1,1)/torch.pow(10000,torch.arange(0,num_hiddens,2,dtype=torch.float32)/num_hiddens)self.pos[:,:,0::2]=torch.sin(X)self.pos[:,:,1::2]=torch.cos(X)def forward(self,inputs):return inputs+self.pos[:,:inputs.shape[1],:].to(inputs.device)
2.1 绝对位置编码信息
我们首先考虑对0-7进行二进制编码。
得到如下:
| 数字 | 编码 |
|---|---|
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
由上表,我们可以很明显的发现在编码的低位部分它的交替频率会高于高维编码部分·。
而我们考虑基于正余弦函数的位置编码,得到如下图所示:

很明显,发现第8、9两列的频率要低于第6、7两列。这正是模拟了上述编码的特征。然而相对于二进制的编码,我们发现基于正余弦的编码会更加节省空间。
2.2 相对位置编码信息
在上一节中,我们考虑了正余弦编码对于绝对位置信息的考量。在这一节中,我们分析正余弦函数能够很好的表示相对位置信息。
我们考虑对于任何确定的位置偏移 δ,我们发现位置 i+δ 处 的位置编码可以线性投影到位置 i 处的位置编码来表示。
这种投影的数学解释是,令 ωj=1/100002j/d , 对于任何确定的位置偏移 δ ,任何一对 (pi,2j,pi,2j+1) 都可以线性投影到 (pi+δ,2j,pi+δ,2j+1) :
数学公式证明如下:

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!