【 Kernelized Bayesian Softmax for Text Generation 】 现有的文本生成神经模型在解码阶段都依赖softmax层来选择合适的单词embedding。现在大多数方法都是在softmax层采取一个单词一一映射一个embedding的方式。然而,同样的单词在不同的上下文会有不同的语义。在本文作者提出了核化贝叶斯方法KerBS,他能够更好的学习文本生成中的embedding。KerBS的优势如下:它采用了embedding的贝叶斯组合来表征具有不同语义的单词;KerBS适用于解决一词多义带来的语义差异问题,并且通过核学习在embedding空间中捕捉语义的紧密程度,KerBS对极少出现的句子也能保持较高的鲁棒性。研究表明,KerBS显著提高几大文本生成任务的性能。
【 Topic-Guided Variational Auto-Encoder for Text Generation】- NAACL 2019 参考博文: https://blog.csdn.net/Forlogen/article/details/102815558
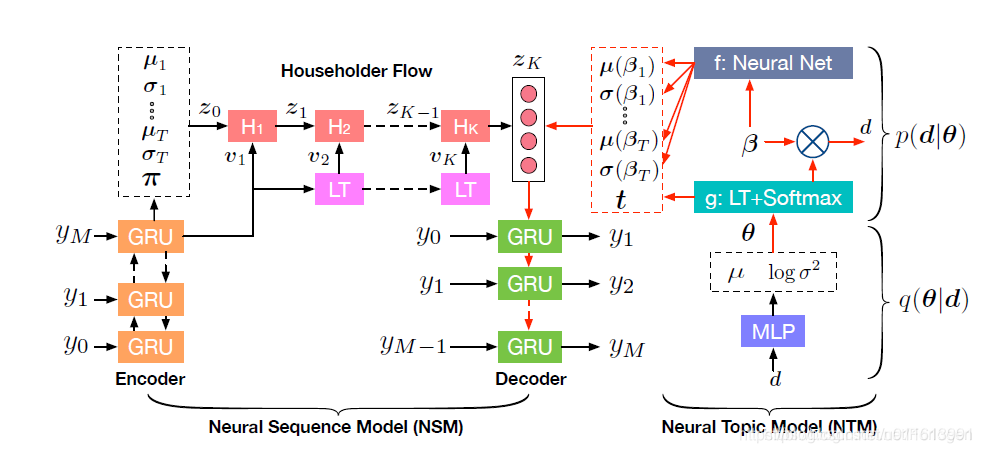
本文提出了一种基于主题指导的VAE模型(topic-guided variational autoencoder, TGVAE),它不再是从标准高斯分布中进行采样,而是将每一个主题模块都看作是一个高斯混合模型,即每一个混合成分都表示了一个对应的latent topic。那么直接从中进行采样,decoder在 解码的过程中过程中就会利用到latent code所表示的主题信息。另外,作者还采用了Householder Transformation 操作,使得latent code的近似后验具有较高的灵活性。实验证明TGVAE在无条件文本生成和条件文本生成任务中都可以取得更好的效果,并且模型可以生成不同主题下语义更加丰富的句子。而且通过主题信息的指导,使得模型在文本生成阶段所依赖的词汇表变小,从而减少解码过程的计算量。
【 Towards Generating Long and Coherent Text with Multi-Level Latent Variable Models .】-ACL 2019 参考博文: https://zhuanlan.zhihu.com/p/86532302
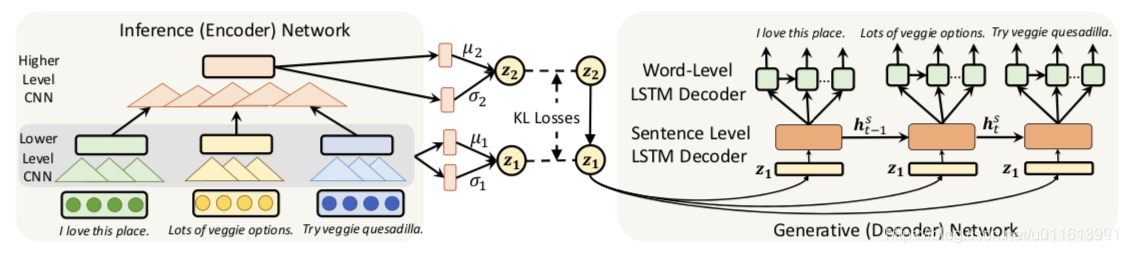
本文利用multi-level structures 学习VAE模型以生成长文本。主要目的是利用长文本的高级抽象特征(如主题、情感等)和低级细粒度细节(如特定的词选择)来做长文本的生成。本文所做的改进:
1.在编码器和解码器之间采用了一个随机层结构来抽象出更多的语义丰富的隐含编码
2.利用一个多级解码器结构通过生成句子高层次的中间表示来捕获长文本中固有的长期结构
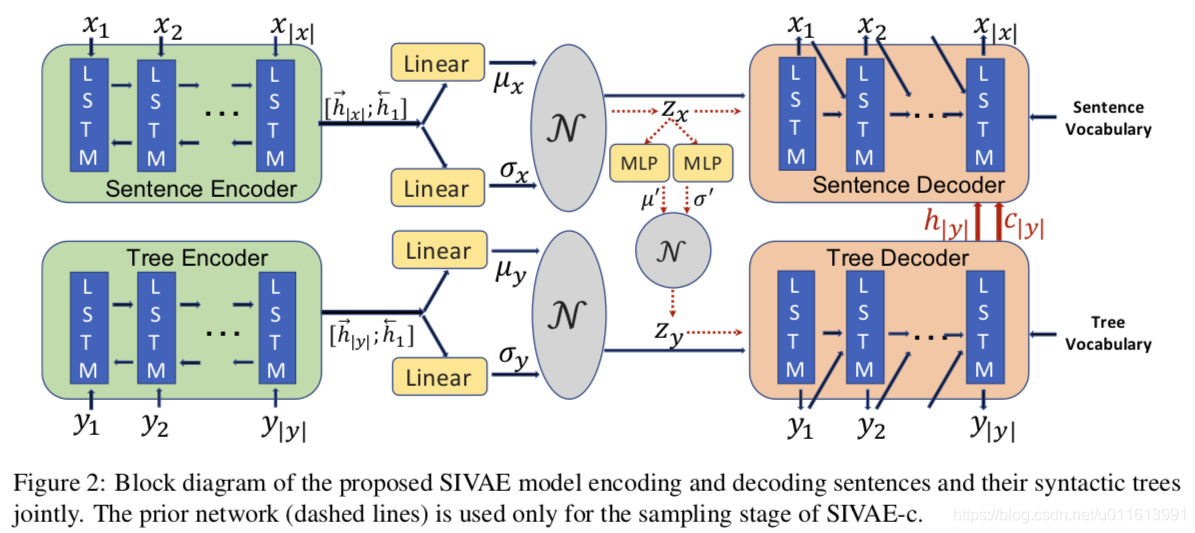
【 Long and Diverse Text Generation with Planning-based Hierarchical Variational Model 】 现有的数据到文本生成的神经方法仍然难以生成长而多样的文本:它们不足以在生成过程中对输入数据进行动态建模、捕捉句子间的连贯性或生成多样化的表达式。为了解决这些问题,我们提出了一种基于规划的层次变分模型(PHVM)。我们的模型首先规划一个组序列(每个组是一个句子所涵盖的输入项的子集),然后根据规划结果和前面生成的上下文实现每个句子,从而将长文本生成分解为依赖的句子生成子任务。为了捕获表达的多样性,我们设计了一个层次潜结构,其中全局规划潜变量对合理规划的多样性进行建模,局部潜变量序列控制句子的实现。给定输入数据x = {d1, d2,…}其中每个di可以是一个属性-值对或一个关键字,我们的任务是生成一个长而多样的文本y = s1 s2…sT (sT是第t个句子)表示尽可能多地表示x。生成过程概述: 1.根据输入生成一组规划,g1,g2,..;gt是输入中的子项 2.结合规划子项,输入编码,生成子句编码 3.结合子项,子句编码进行子句的单词级生成,生成子句si 4.根据时间步,结合上步隐层信息,重复1-3步,生成其余的子句si+1,si+2… 5.拼接所以子句si-N,形成最终的长句。【 Syntax-Infused Variational Autoencoder for Text Generation 】-ACL 2019 博文参考: https://zhuanlan.zhihu.com/p/87355823
Syntax-Infused VAE顾名思义就是结合了语法信息的VAE文本生成,结合输入文本的语法树,可以提升生成句子的语法信息。作者分别为句子和语法树生成了隐变量,并且重写了变分下界的目标函数,以此优化2者的联合分布。
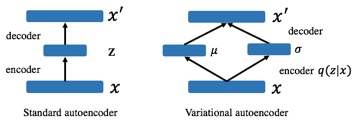 与自编码对比:
自编码通过编码器将输入x进行编码成z,然后通过解码器将z解码成x`,使得x`与x一样。缺陷:1.需要有原始输入,是有监督的;2.生成的结果是使得x`与原始输入一样,不能泛化生成多样的结果。3.主要用于获取输入的隐藏表示。
变分自编码结构与自编码类似,也是由编码器和解码器构成,不同的是在编码的目标是生成一个概率分布 q(z|x)代替确定性z来重建输入,强制模型将输入映射到空间的区域而不是单个点,。在这种情况下,实现良好重构误差的最直接方法是预测非常潜在的概率分布,有效地对应于潜在空间中的单个点(Raiko等人2014)。引入 KL divergence 让后验 q(z|x) 接近先验 p(z).
与自编码对比:
自编码通过编码器将输入x进行编码成z,然后通过解码器将z解码成x`,使得x`与x一样。缺陷:1.需要有原始输入,是有监督的;2.生成的结果是使得x`与原始输入一样,不能泛化生成多样的结果。3.主要用于获取输入的隐藏表示。
变分自编码结构与自编码类似,也是由编码器和解码器构成,不同的是在编码的目标是生成一个概率分布 q(z|x)代替确定性z来重建输入,强制模型将输入映射到空间的区域而不是单个点,。在这种情况下,实现良好重构误差的最直接方法是预测非常潜在的概率分布,有效地对应于潜在空间中的单个点(Raiko等人2014)。引入 KL divergence 让后验 q(z|x) 接近先验 p(z).
 【 Generating Sentences from a Continuous Space】-第20届计算自然语言学习大会 2016
参考博文: https://blog.csdn.net/lrt366/article/details/89388171
作者为了弥补传统的 RNNLM 结构缺少的一些全局特征(其实可以理解为想要 sentence representation)。其实抛开 generative model,之前也有一些比较成功的 non-generative 的方法,比如 sequence autoencoders[1],skip-thought[2] 和 paragraph vector[3]。但随着 VAE 的加入,generative model 也开始在文本上有更多 的可能性。
【 Generating Sentences from a Continuous Space】-第20届计算自然语言学习大会 2016
参考博文: https://blog.csdn.net/lrt366/article/details/89388171
作者为了弥补传统的 RNNLM 结构缺少的一些全局特征(其实可以理解为想要 sentence representation)。其实抛开 generative model,之前也有一些比较成功的 non-generative 的方法,比如 sequence autoencoders[1],skip-thought[2] 和 paragraph vector[3]。但随着 VAE 的加入,generative model 也开始在文本上有更多 的可能性。
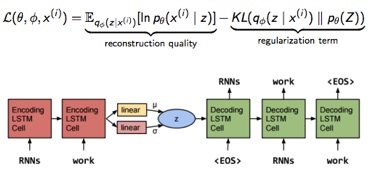
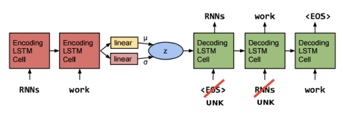
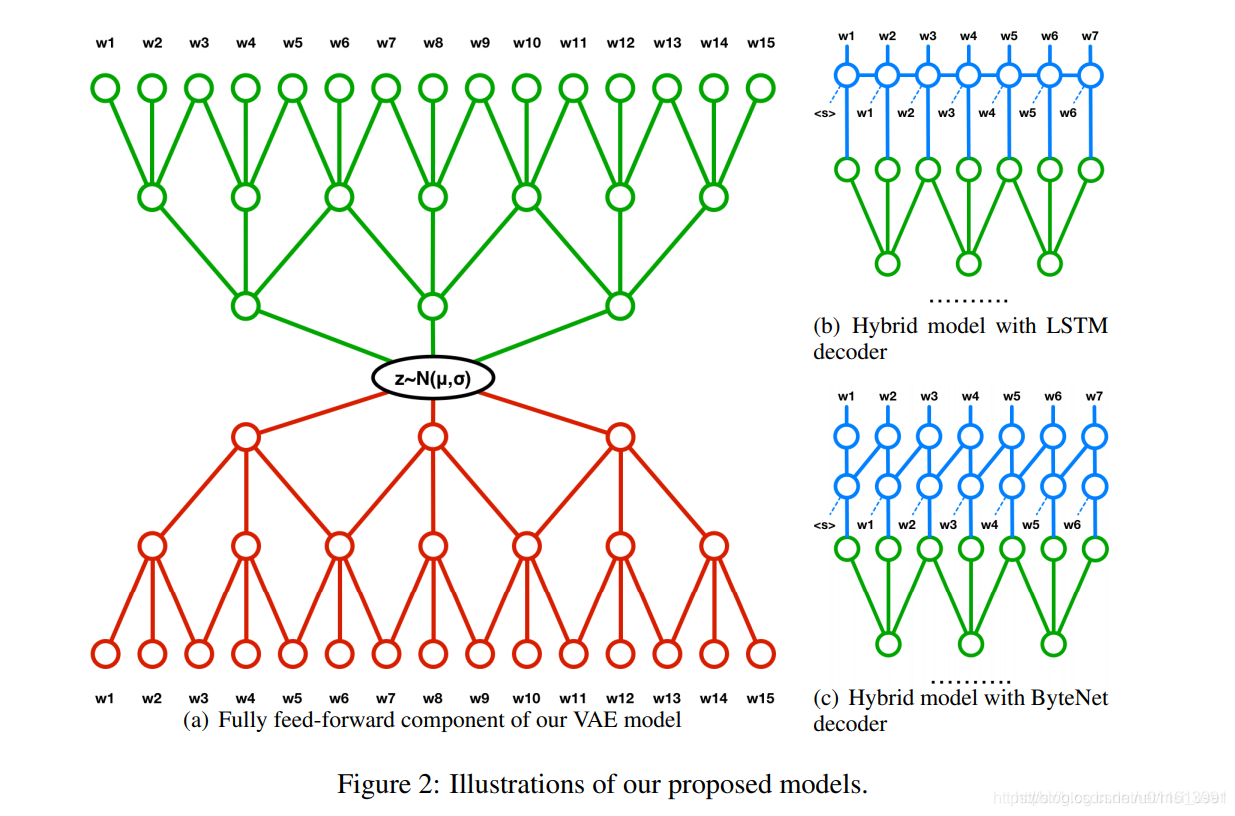
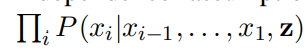
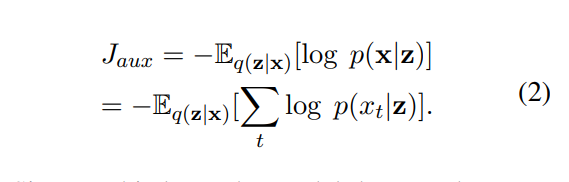

 生成过程概述:
1.根据输入生成一组规划,g1,g2,..;gt是输入中的子项
2.结合规划子项,输入编码,生成子句编码
3.结合子项,子句编码进行子句的单词级生成,生成子句si
4.根据时间步,结合上步隐层信息,重复1-3步,生成其余的子句si+1,si+2 …
5.拼接所以子句si-N,形成最终的长句。
【 Syntax-Infused Variational Autoencoder for Text Generation 】- ACL 2019
博文参考: https://zhuanlan.zhihu.com/p/87355823
Syntax-Infused VAE顾名思义就是结合了语法信息的VAE文本生成,结合输入文本的语法树,可以提升生成句子的语法信息。作者分别为句子和语法树生成了隐变量,并且重写了变分下界的目标函数,以此优化2者的联合分布。
生成过程概述:
1.根据输入生成一组规划,g1,g2,..;gt是输入中的子项
2.结合规划子项,输入编码,生成子句编码
3.结合子项,子句编码进行子句的单词级生成,生成子句si
4.根据时间步,结合上步隐层信息,重复1-3步,生成其余的子句si+1,si+2 …
5.拼接所以子句si-N,形成最终的长句。
【 Syntax-Infused Variational Autoencoder for Text Generation 】- ACL 2019
博文参考: https://zhuanlan.zhihu.com/p/87355823
Syntax-Infused VAE顾名思义就是结合了语法信息的VAE文本生成,结合输入文本的语法树,可以提升生成句子的语法信息。作者分别为句子和语法树生成了隐变量,并且重写了变分下界的目标函数,以此优化2者的联合分布。