【大数据技术】实验1:Hadoop集群环境搭建和熟悉常用的Linux操作
文章目录
- 一、实验环境
- 二、实验内容
- 0.安装Linux操作系统(虚拟机)
- 1.熟悉常用的Linux操作
- 出现的问题
一、实验环境
- 操作系统:Linux(Centos8.4);
- Hadoop版本:3.3.1
二、实验内容
0.安装Linux操作系统(虚拟机)
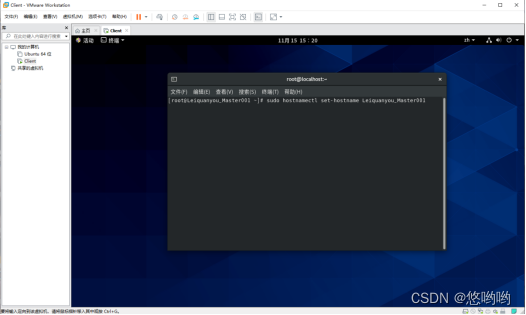
要求:主机名设置为”自拟主机名_Master001”,在实验内容第一行中写明自拟主机名。

1.熟悉常用的Linux操作
1)cd命令:切换目录
(1)切换到目录“/usr/local”

(2)切换到当前目录的上一级目录

(3)切换到当前登录Linux系统的用户的自己的主文件夹

2)ls命令:查看文件与目录
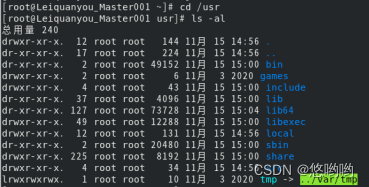
查看目录“/usr”下的所有文件和目录
3)mkdir命令:新建目录
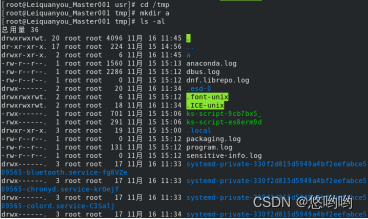
(1)进入“/tmp”目录,创建一个名为“a”的目录,并查看“/tmp”目录下已经存在哪些目录
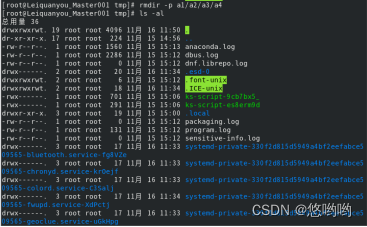
(2)进入“/tmp”目录,创建目录“a1/a2/a3/a4”

4)rmdir命令:删除空的目录
(1)将上面创建的目录a(在“/tmp”目录下面)删除

(2)删除上面创建的目录“a1/a2/a3/a4” (在“/tmp”目录下面),然后查看“/tmp”目录下面存在哪些目录
5)cp命令:复制文件或目录
(1)将当前用户的主文件夹下的文件.bashrc复制到目录“/usr”下,并重命名为bashrc1
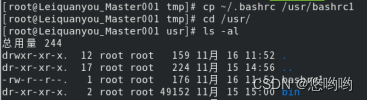
(2)在目录“/tmp”下新建目录test,再把这个目录复制到“/usr”目录下
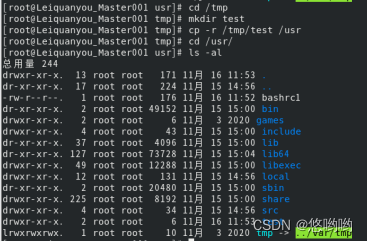
6)mv命令:移动文件与目录,或更名
(1)将“/usr”目录下的文件bashrc1移动到“/usr/test”目录下

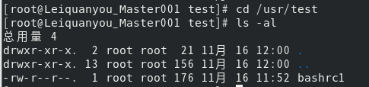
(2)将“/usr”目录下的test目录重命名为test2

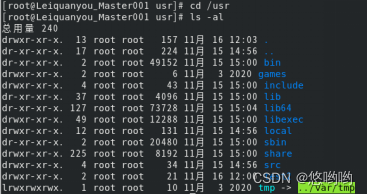
7)rm命令:移除文件或目录
(1)将“/usr/test2”目录下的bashrc1文件删除
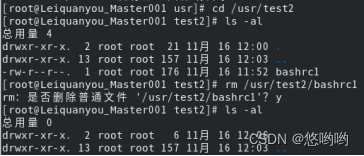
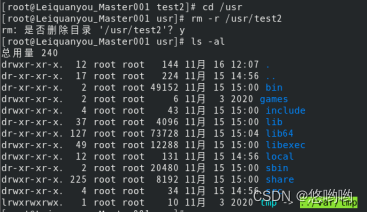
(2)将“/usr”目录下的test2目录删除
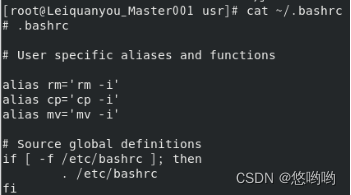
8)cat命令:查看文件内容
查看当前用户主文件夹下的.bashrc文件内容
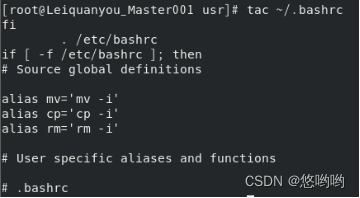
9)tac命令:反向查看文件内容
反向查看当前用户主文件夹下的.bashrc文件的内容
10)more命令:一页一页翻动查看
翻页查看当前用户主文件夹下的.bashrc文件的内容
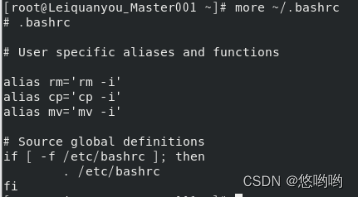
11)head命令:取出前面几行
(1)查看当前用户主文件夹下.bashrc文件内容前20行
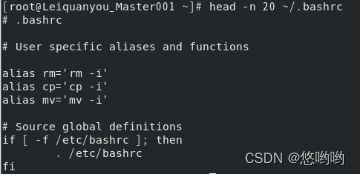
(2)查看当前用户主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行、
(我的.bashrc文件内容较少,改为测试后面5行不显示,只显示前面几行)
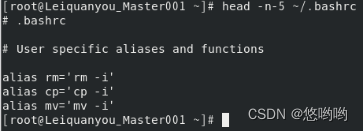
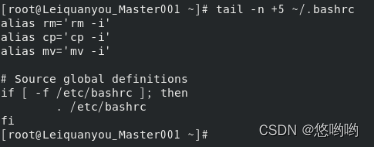
12)tail命令:取出后面几行
(1)查看当前用户主文件夹下.bashrc文件内容最后20行
(我的.bashrc文件内容较少,改为测试最后5行)
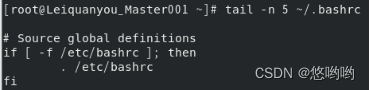
(2)查看当前用户主文件夹下.bashrc文件内容,并且只列出50行以后的数据
(我的.bashrc文件内容较少,改为测试5行以后)
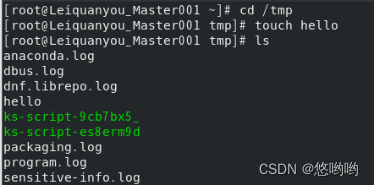
13)touch命令:修改文件时间或创建新文件
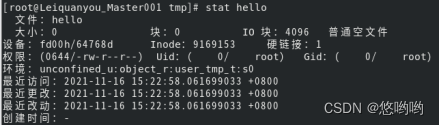
(1)在“/tmp”目录下创建一个空文件hello,并查看文件时间
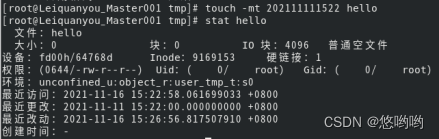
(2)修改hello文件,将文件时间整为5天前
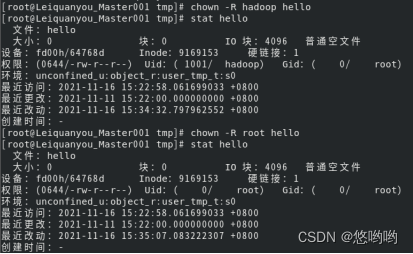
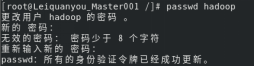
14)chown命令:修改文件所有者权限
将hello文件所有者改为root帐号,并查看属性
15)find命令:文件查找
找出主文件夹下文件名为.bashrc的文件

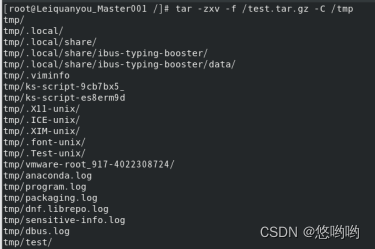
16)tar命令:压缩命令
(1)在根目录“/”下新建文件夹test,然后在根目录“/”下打包成test.tar.gz

(4)把上面的test.tar.gz压缩包,解压缩到“/tmp”目录
2.安装Hadoop
(1)根据个人电脑条件选择安装伪分布式模式或者分布式模式
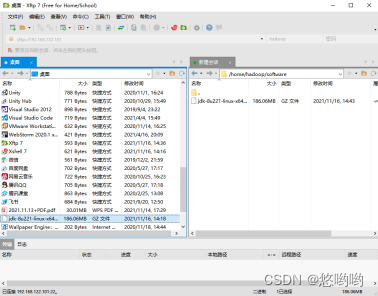
(2)给出Linux环境变量配置




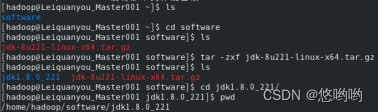


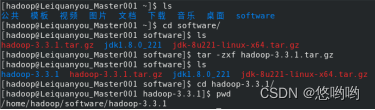
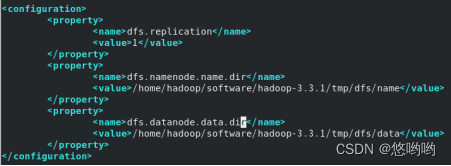
(3)给出Hadoop配置文件配置详细清单
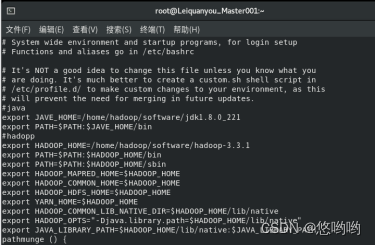
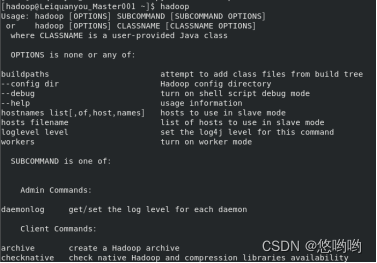
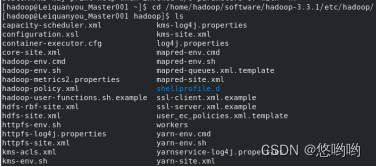
1.core-site.xml

2.hadoop-env.sh

3.hdfs-site.xml
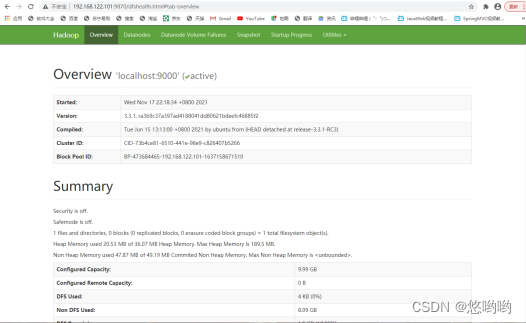
(5)给出Hadoop启动后,各个节点进程截图,浏览器总览截图

3.熟悉基本的Hadoop hdfs操作
(1)使用hadoop用户登录Linux系统,启动Hadoop(Hadoop的安装目录为“/home/software/hadoop”),为hadoop用户在HDFS中创建用户目录“/user/hadoop”

(2)接着在HDFS的目录“/user/hadoop”下,创建test文件夹,并查看文件列表

(3)将Linux系统本地的“~/.bashrc”文件上传到HDFS的test文件夹中,并查看test


(4)将HDFS文件夹test复制到Linux系统本地文件系统的“/usr/local/hadoop”目录下
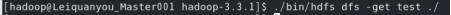
出现的问题
1.vim /etc/profile 写入时 出现 E121:无法打开并写入文件解决方案。
2.出现“不在sudoers文件中,此事将被报告”的问题。
3.启动hadoop,报错Error JAVA_HOME is not set and could not be found。
4.Hadoop启动后没有DataNode节点。
ssh远程执行命令时报错Permission denied。
解决方案:
1.保存的时候用:w !sudo tee % 后输入密码即可。
2.
(1)切换到root用户权限,输入命令:“su root”,回车后输入密码再回车;
(2)查看/etc/sudoers文件权限,如果只读权限,修改为可写权限;
(3)执行vim命令,编辑/etc/sudoers文件,添加要提升权限的用户;在文件中找到root ALL=(ALL) ALL,在该行下添加提升权限的用户信息,如:
输入编辑文件命令:“vim /etc/sudoers”;
查找到Allow root to run any commands anywhere,在root命令下增加一行命令,先输入命令:“i”,下方会出现“插入”的字样,此时可输入你要加入的信息。
(4)保存退出,并恢复/etc/sudoers的访问权限为440;
先按Esc按键退出编辑模式,再输入强制保存命令:“:wq!”(注意:一定要先输入:,否则无法输入这个命令)返回到命令页面,输入回复权限的命令:“chmod 440 /etc/sudoers”。
(5)切换到普通用户,测试用户权限提升功能。
3.在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME。
4.是因为之前多次格式化namenode导致的namenode与datanode之间的不一致。
所以需要删除之前配置的data目录(即为dfs.data.dir所创建的文件夹),然后将temp文件夹与logs文件夹删除,重新格式化namenode。
5.
(1)生成私钥:ssh-keygen -t rsa -P ‘’;
(2)将公钥导入到认证文件:cat /home/名字/.ssh/id_rsa.pub >> /home/名字/.ssh/authorized_keys;
(3)设置文件访问权限:chmod 700 /home/名字/.ssh;chmod 600 /home/名字/.ssh/authorized_keys。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!