R语言两阶段最小⼆乘法2SLS回归、工具变量法分析股息收益、股权溢价和surfaces曲面图可视化...
全文链接:http://tecdat.cn/?p=31757
投资者最关心的两个问题就是收益率和股息,两者作为公司经营状况的两个重要方面,往往同时出现在投资报告中,二者之间具有较强的关联性(点击文末“阅读原文”获取完整代码数据)。
目前,国内外对于股票股息收益、股息收益率和股权溢价等方面的研究已有很多,但大多数是关于市场环境或宏观因素对上述指标产生影响的研究。
相关视频
本文选择沪深两市股票作为研究对象,帮助客户构建两阶段最小二乘法2 SLS回归、工具变量法分析股息收益、股息收益率和股权溢价,旨在探究指标间是否具有显著相关关系。研究结论不仅为投资者提供了分析投资机会的理论依据,还有助于上市公司进行决策分析。此外,文章还对相关行业的发展具有一定指导意义。
1.数据
表格中包括从1965年到2014年的月度数据,需要用到的是:yyyymm(年⽉),
index(s&p 500 price index) , Dividend, D12(dividend yield), Rfree(risk-free rate)
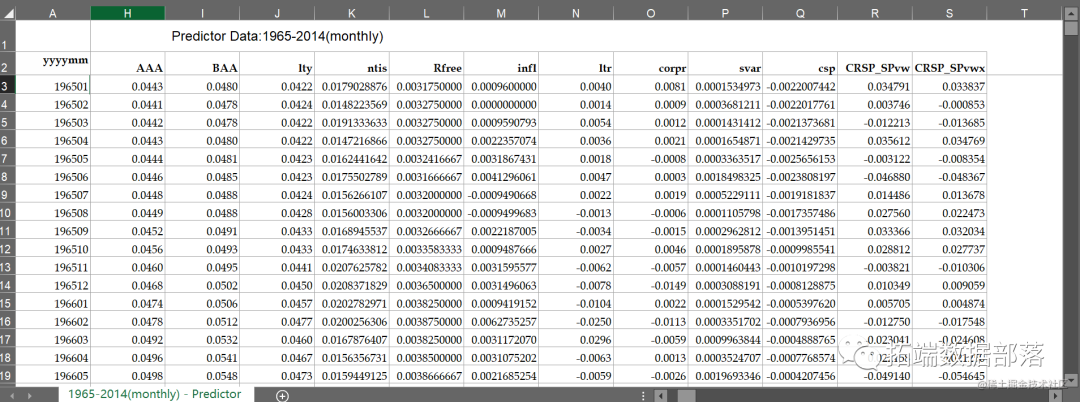
读取数据,查看数据
head(data)## yyyymm Index Dividend D12 E12 b/m tbl AAA BAA
## 1 196501 87.56 2.51667 2.51667 4.59333 0.4717232 0.0381 0.0443 0.0480
## 2 196502 87.43 2.53333 2.53333 4.63667 0.4713995 0.0393 0.0441 0.0478
## 3 196503 86.16 2.55000 2.55000 4.68000 0.4694899 0.0393 0.0442 0.0478
## 4 196504 89.11 2.57000 2.57000 4.73333 0.4525593 0.0393 0.0443 0.0480
## 5 196505 88.42 2.59000 2.59000 4.78667 0.4546643 0.0389 0.0444 0.0481
## 6 196506 84.12 2.61000 2.61000 4.84000 0.4808590 0.0380 0.0446 0.0485
## lty ntis Rfree infl ltr corpr svar
## 1 0.0422 0.01790289 0.003175000 0.0009600000 0.0040 0.0081 0.0001534973
## 2 0.0424 0.01482236 0.003275000 0.0000000000 0.0014 0.0009 0.0003681211
## 3 0.0422 0.01913336 0.003275000 0.0009590793 0.0054 0.0012 0.0001431412
## 4 0.0422 0.01472169 0.003275000 0.0022357074 0.0036 0.0021 0.0001654871
## 5 0.0423 0.01624416 0.003241667 0.0031867431 0.0018 -0.0008 0.0003363517
## 6 0.0423 0.01755028 0.003166667 0.0041296061 0.0047 0.0003 0.0018498325
## csp CRSP_SPvw CRSP_SPvwx
## 1 -0.0022007442 0.034791 0.033837
## 2 -0.0022017761 0.003746 -0.000853
## 3 -0.0021373681 -0.012213 -0.013685
## 4 -0.0021429735 0.035612 0.034769
## 5 -0.0025656153 -0.003122 -0.008354
## 6 -0.0023808197 -0.046880 -0.048367#需要用到的是有红色标记的:yyyy(年份),price index(s&p 500 price index),D12(dividend yield),Rfree(risk-free)
CampaignData <- na.omit(subset(AllData, select=c("yyyymm","Index","D12","Rfree","Dividend")))2.自变量x
⾃变量x是D12(dividend-yield), DY(t)=log[D(t)/P(t-1)],这⾥的D(t)就是表格中的Dividend。P(t-1) 就是表格中的index.
DY=log(Dt/Pt)3.因变量y
因变量y是股权溢价(equity premium),公式是equity premium=rm(t)-rf(t) 关于rm(t): rm(t)=log[Rm,t]=log[ (P(t)+D(t)) / P(t-1) ],D(t)就是表格中的Dividend.
P(t),P(t-1)就是表格中的index. 关于 rf(t): rf(t)=log[1+Rf(t)],这⾥的Rf(t)就是表格中的Rfree(risk-free rate)
equity_premium=Rm-Rf
y=equity_premium4.模型
y(t)=β* x(t-1)+ε(t) (1)
oequity_premium[-1] ~ CampaignData$D12[-n] +I(1:(n-1)), data=CampaignData)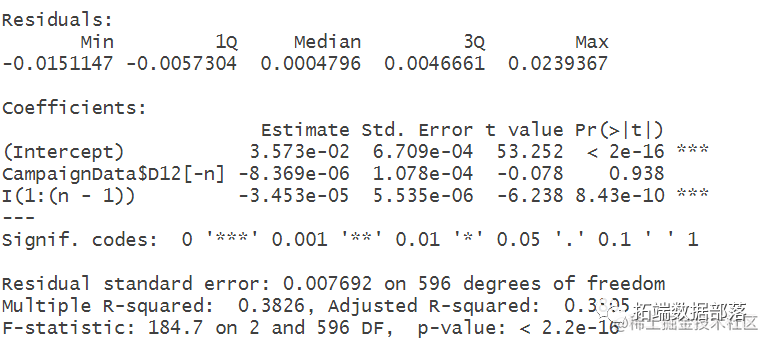
x(t)= ρ* x(t-1)+u(t) (2)
点击标题查阅往期内容

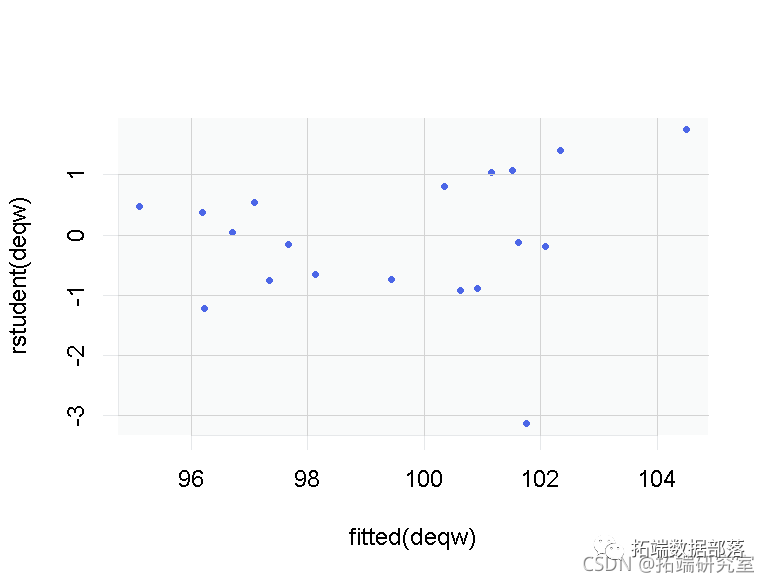
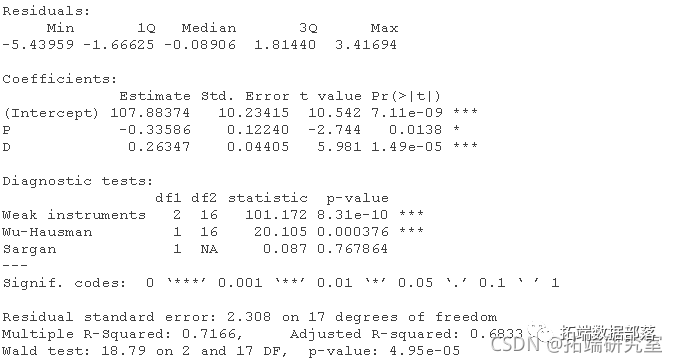
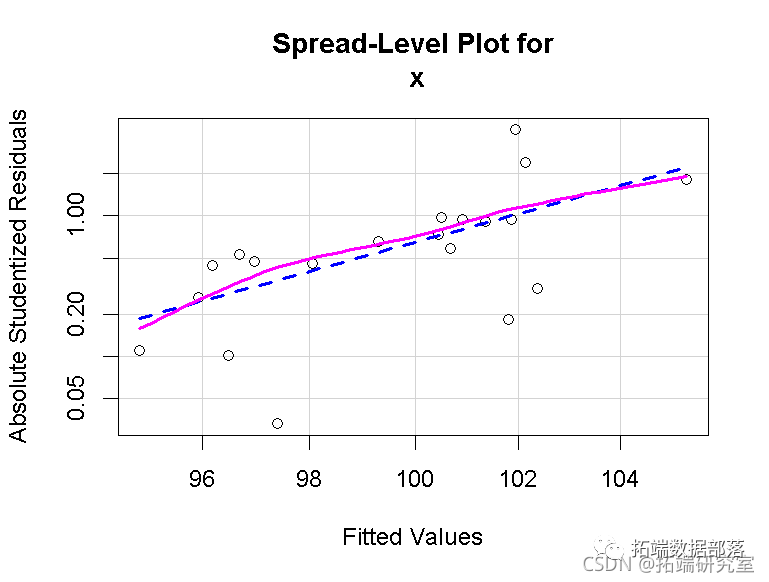
工具变量法(两阶段最小二乘法2SLS)线性模型分析人均食品消费时间序列数据和回归诊断

左右滑动查看更多
01
02
03
04
5.工具变量:
z(t)=ρz* z(t-1)+Δx(t) ,其中ρz是z(t-1)的系数,和式⼦(2)中的ρ不是同⼀个值.
这⾥的 z0=0,ρz=1+c/nκ , c=-1,k=0.95
c=-1
z=0
ρz=1+c/(n^k)
for(i in 1:n)z[i+1]=ρz*z[i]+x[i]
z=z[-1]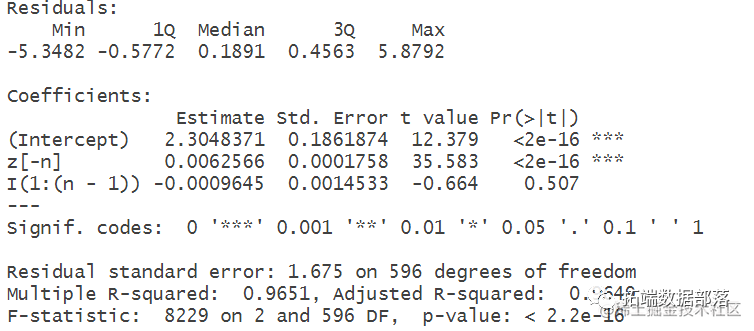
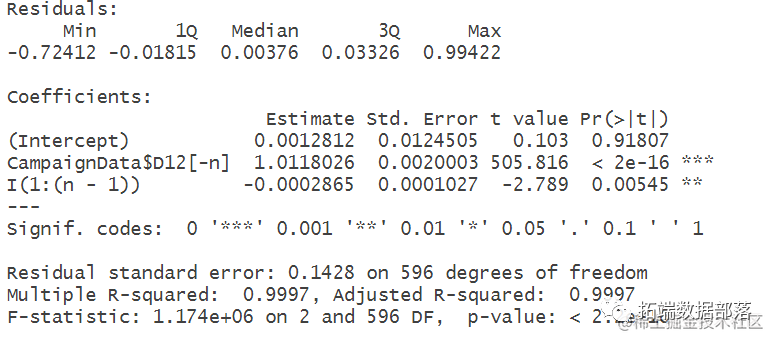
6.用两阶段最⼩二乘法做回归, 2SLS
具体做法: (1)通过工具变量计算出z(t-1)的数值
(2)建⽴x(t-1)与z(t-1)的函数关系:x(t-1)=αz(t-1)+ e(t),通过OLS得出α的估计值,
然后得出x(t-1)的估计值。x(t-1)的估计值= α的估计值* z(t-1) (3)把x(t-1)的估计值带⼊到第⼀个式⼦中,即y(t)=β* x(t-1)的估计值+ε(t) ,再
进⾏OLS回归,最后得到β的估计值,以及test-statistic的值,和p-value.
# 建⽴x(t-1)与z(t-1)的函数关系 n=length(x) olsmodel <- lm(x[-1] ~ z[-n] +I(1:(n-1)), data=CampaignData)
# summary(olsmodel) # 得出x(t-1)的估计值
# fitted(olsmodel) # 把x(t-1)的估计值带⼊到第1⼀个式⼦中,即y(t)=β*x(t-1)的估计值+ε(t) p=summary(olsmodel)[4]$coefficients[,4][2] return(p) p=numeric(0)
fo){ p=c(p,f(x[xx[i]:xx[i+1]],y[yy[j]:yy[j+1]]))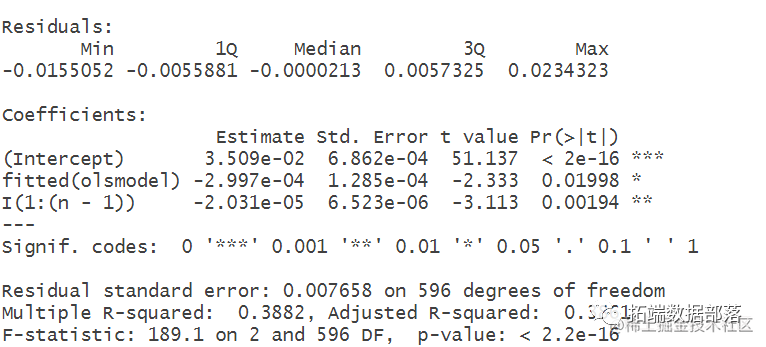
7.p-value surfaces图:
需要的是得到下⾯的这样一张图,⽤p-value 构建的。
具体描述是:所选取的样本区间是从1965年1⽉到2014年12⽉,以5年为⼀个最短的⼦样本。图的y轴为样本的起始点⼀共540个(从1965年1⽉到2009年12⽉), x轴为样本的终点⼀共也是540个(从1970年1⽉到2014年12⽉)。图中的每⼀个点为⼀个⼦样本的p-value的值。
for(j in 1:(length(yy)-1)){ p=c(p,f(x[xx[i]:xx[i+1]],y[yy[j]:yy[j+1]]))
persp(xx, yy, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue")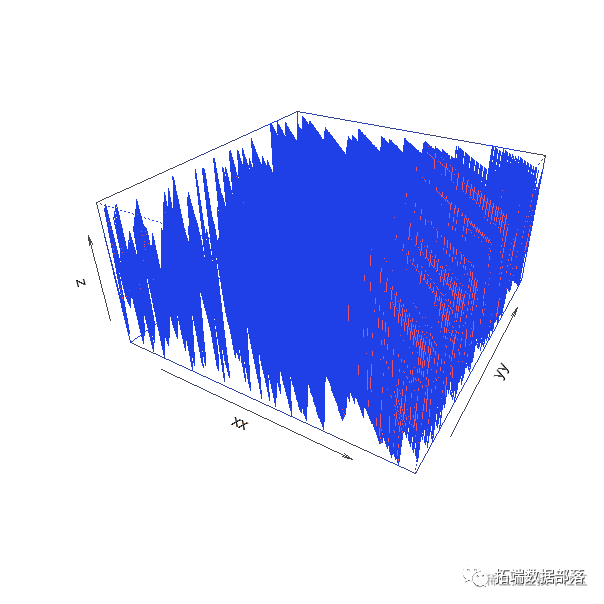

本文中分析的数据分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言两阶段最小⼆乘法2SLS回归、工具变量法分析股息收益、股权溢价和surfaces曲面图可视化》。
点击标题查阅往期内容
工具变量法(两阶段最小二乘法2SLS)线性模型分析人均食品消费时间序列数据和回归诊断
工具变量法(两阶段最小二乘法2SLS)线性模型分析人均食品消费时间序列数据和回归诊断
贝叶斯线性回归和多元线性回归构建工资预测模型
逻辑回归、随机森林、SVM支持向量机预测心脏病风险数据和模型诊断可视化
高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据
分类回归决策树交互式修剪和更美观地可视化分析细胞图像分割数据集
实现广义相加模型GAM和普通最小二乘(OLS)回归
贝叶斯线性回归和多元线性回归构建工资预测模型
Python支持向量回归SVR拟合、预测回归数据和可视化准确性检查实例
逻辑回归(对数几率回归,Logistic)分析研究生录取数据实例
广义线性模型glm泊松回归的lasso、弹性网络分类预测学生考试成绩数据和交叉验证
非线性回归nls探索分析河流阶段性流量数据和评级曲线、流量预测可视化
特征选择方法——最佳子集回归、逐步回归
线性回归和时间序列分析北京房价影响因素可视化案例
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
spss modeler用决策树神经网络预测ST的股票
R语言中使用线性模型、回归决策树自动组合特征因子水平
R语言中自编基尼系数的CART回归决策树的实现
R语言用rle,svm和rpart决策树进行时间序列预测
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言ISLR工资数据进行多项式回归和样条回归分析
R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
如何用R语言在机器学习中建立集成模型?
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
在python 深度学习Keras中计算神经网络集成模型
R语言ARIMA集成模型预测时间序列分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言基于Bootstrap的线性回归预测置信区间估计方法
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
matlab使用分位数随机森林(QRF)回归树检测异常值

![]()

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!