关于机器学习的分类器整理
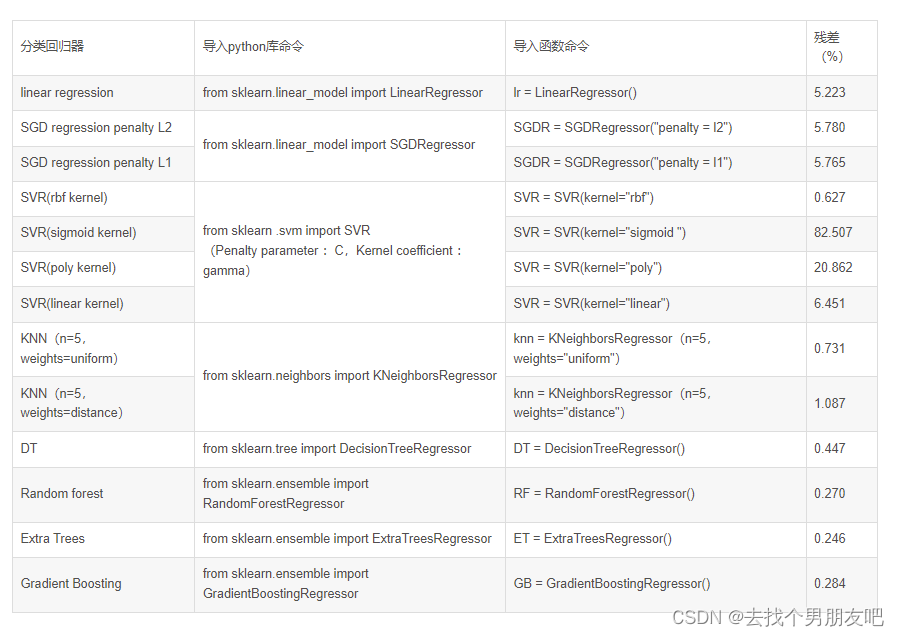
机器学习中的 5 种流行的分类算法
线性回归(Linear Regression)
linear regression是假设数据服从线性分布的,这一假设前提也限制了该模型的准确率,因为现实中由于噪声等的存在很少有数据是严格服从线性的。
基于这种假设,linear regression可以通过normal equation求闭合解的方式求得y_predict
逻辑回归(Logistic Regression)
SGD
逻辑回归是一种用于预测二元结果的算法:要么发生,要么不发生。
公式:P(Y=1|X) 或 P(Y=0|X)
假设自变量为 X,该公式可以计算因变量 Y 的概率
朴素贝叶斯(Naive Bayes)
朴素贝叶斯计算一个数据点是否属于某个类别的可能性。在文本分析中,朴素贝叶斯可用于将单词或短语归类为是否属于预设的“标签”
P(A|B) = P(B|A) * P(A) /P(B)
K-最近邻(K-Nearest Neighbor)
K-最近邻 (k-NN) 是一种模式识别算法,通过训练数据集在未来示例中找到 k 个最近邻。
当 k-NN 用于分类时,你需要计算将数据放在哪个类别中(即最近邻的类别中)。如果 k = 1,那么数据将被放在最接近 1 的类别中。通过对其近邻的多轮进行计算,从而得出K值,进行分类。
决策树(Decision Tree)
决策树是一种监督学习算法,非常适合解决分类问题,因为该算法能够精确地对类别进行排序。其工作原理类似于流程图,一次性将数据点分成两个相似的类别,从“树干”到“树枝”,再到“叶子”,让这些类别在有限范围内变得更加相似。通过决策树,你可以在类别中创建类别,在有限的人工监督下进行有机分类。
随机森林(Random Forest)
随机森林算法是决策树的扩展,首先通过训练数据构建大量决策树,然后将新数据作为“随机森林”放入其中一棵树中。
从本质上讲,随机森林可以对数据进行平均,并将其连接到数据规模上最近的树。随机森林模型非常有用,因为它可以解决决策树在不必要的情况下,强制对数据点进行归类的问题。
支持向量机(Support Vector Machines)
支持向量机 (SVM) 使用算法训练,并分类不同极性的数据,使其超出 X/Y 的预测范围。
SVM是将低维无序杂乱的数据通过核函数(RBF,poly,linear,sigmoid)映射到高维空间,通过超平面将其分开
在sklearn包中默认配置中三种核函数的准确率大概是RBF>poly>linear
集成模型
random forest:随机抽取样本形成多个分类器,通过vote,少数服从多数的方式决定最终属于多数的分类器结果,分类器之间是相互去之间关联的
gradient boost:弱弱变强,最典型的代表是adaboost(三个臭皮匠,顶个诸葛亮),弱分类器按照一定的计算方式组合形成强的分类器,分类器之间存在关联,最终分类是多个分类器组合的结果
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!