北理慕课——Python组合数据类型
1 集合类型及操作
1.1 - 集合类型定义
集合是多个元素的无序组合
- 集合用大括号 {} 表示,元素间用逗号分隔
- 建立集合类型用 {} 或 set() - 建立空集合类型,必须使用set()
>>> A = {"python", 123, ("python",123)} #使用{}建立集合
{123, 'python', ('python', 123)}
>>> B = set("pypy123") #使用set()建立集合
{'1', 'p', '2', '3', 'y'}
>>> C = {"python", 123, "python",123}
{'python', 123}1.2 - 集合操作符
6个操作符

4个增强操作符

>>> A = {"p", "y" , 123}
>>> B = set("pypy123")
>>> A-B {123}
>>> B-A
{'3', '1', '2'}
>>> A&B
{'p', 'y'}
>>> A|B
{'1', 'p', '2', 'y', '3', 123}
>>> A^B
{'2', 123, '3', '1'}1.3 - 集合处理方法


1.4 - 集合类型应用场景
数据去重:集合类型所有元素无重复
还可以将集合转换为列表
2 序列类型及操作
2.1 - 序列类型定义
序列是具有先后关系的一组元素
- 序列是一维元素向量,元素类型可以不同
- 类似数学元素序列: s0, s1, … , sn-1
- 元素间由序号引导,通过下标访问序列的特定元素
序列类型:字符串类型、元组类型、列表类型
2.2 - 序列处理函数及方法
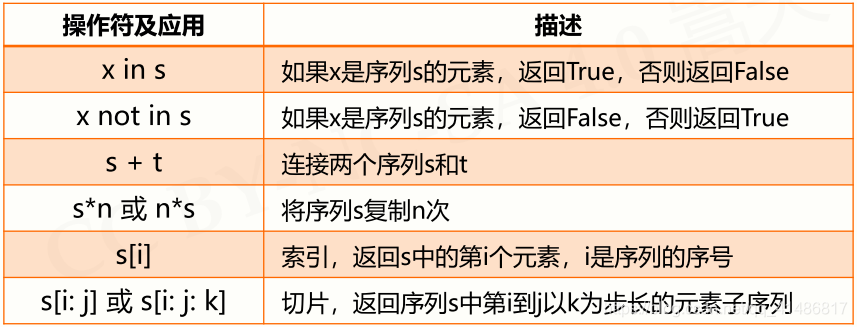

2.3 - 元组类型及操作
- 元组是一种序列类型,一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
- 可以使用或不使用小括号
元组继承了序列的全部通用操作
2.4 - 列表类型及操作
- 列表是一种序列类型,创建后可以随意被修改
- 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔
- 列表中各元素类型可以不同,无长度限制
列表类型操作函数和方法


2.5 - 序列类型应用场景
数据表示:元组和列表
- 元组用于元素不改变的应用场景,更多用于固定搭配场景
- 列表更加灵活,它是最常用的序列类型
- 最主要作用:表示一组有序数据,进而操作它们
元素遍历,或者数据保护(如果不希望数据被程序所改变,转换为元祖类型)
- 序列是基类类型,扩展类型包括:字符串、元组和列表
- 元组用()和tuple()创建,列表用[]和set()创建
- 元组操作与序列操作基本相同
- 列表操作在序列操作基础上,增加了更多的灵活性
实例9: 基本统计值计算
给出不定个数的数据,求出平均值,方差,中位数
#CalStatisticsV1.py
def getNum(): #获取用户输入的不定长数字nums = []iNumber = input("请输入数字(回车退出)")while iNumber != "":nums.append(eval(iNumber))iNumber = input("请输入数字(回车退出)")return numsdef mean(numbers): #计算平均值s = 0.0for item in numbers:s += itemreturn s/len(numbers)def median(numbers): #计算中位数sorted(numbers)if len(numbers)%2 == 0:return (numbers[len(numbers)//2-1]+numbers[len(numbers)//2])/2else:return numbers[len(numbers)//2]def dev(numbers,mean): #计算方差sdev = 0.0for num in numbers:sdev = sdev + (num - mean)**2return pow(sdev/(len(numbers)-1),0.5)
Numbers = getNum()
Mean = mean(Numbers)
Median = median(Numbers)
Dev = dev(Numbers,Mean)
print("平均值是:{:.2f},方差是{:.2f},中位数是{:.2f}".format(Mean,Dev,Median))
print(len(Numbers)//2)
3 字典类型及操作
3.1 - 字典类型定义
- 映射是一种键(索引)和值(数据)的对应
- 键值对:键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 采用大括号{}和dict()创建,键值对用冒号: 表示
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
在字典变量中,通过键获得值
<字典变量> = {<键1>:<值1>, … , <键n>:<值n>}
<值> = <字典变量>[<键>] [ ] 用来向字典变量中索引或增加元素
<字典变量>[<键>] = <值>
[ ]用来向字典变量中索引或增加元素
3.2 - 字典处理函数及方法


3.3 - 字典类型应用场景
- 映射无处不在,键值对无处不在
- 例如:统计数据出现的次数,数据是键,次数是值
- 最主要作用:表达键值对数据,进而操作它们
4 jieba库的使用
jieba分词的三种模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
jieba库常用函数


实例10: 文本词频统计
- 英文文本:Hamet 分析词频
https://python123.io/resources/pye/hamlet.txt
#CalHamletV1
def getText():txt = open('hamlet.txt','r').read()txt = txt.lower()for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':txt = txt.replace(ch," ")return txthamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):word,count = items[i]print("{:<10}{:>5}".format(word,count))- 中文文本:《三国演义》分析人物
https://python123.io/resources/pye/threekingdoms.txt
#CalThreeKingdomsV1
import jieba
txt = open("ThreeKingdoms.txt","r",encoding='utf-8').read()
excludes = {"将军","却说","荆州","二人","不可","不能","如此"}
words = jieba.lcut(txt)
counts = {}
for word in words:if len(word) == 1:continueelif word =='诸葛亮' or word =='孔明曰':rword = '孔明'elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰": rword = "刘备"elif word == "孟德" or word == "丞相": rword = "曹操"else:rword = wordcounts[rword] = counts.get(rword,0) + 1
for word in excludes:del counts[word]
items = list(counts.items())
items.sort(key = lambda x:x[1],reverse=True)
for i in range(15):word, count = items[i]print("{:<10}{:>5}".format(word,count))
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!