PSO变种策略——解决大规模问题:(2)TPLSO
基于两阶段学习的大规模优化粒子群算法(TPLSO)
简介:TPLSO采用群体学习和精英学习。在群体学习阶段,TPLSO具有不同探索和开发潜力的粒子被随机选择三个粒子组成学习组,然后采用竞争机制更新学习组成员。然后对群中的所有粒子进行排序,并挑选出具有更好拟合值的精英粒子,可以保持高度的多样性,避免陷入局部最优。在精英学习阶段,一些具有良好拟合值的精英粒子将粒子聚集到群体中形成新的群体,然后这些精英粒子更新它们的位置,从而将更好的粒子替换。上面提到的那些更好的粒子是随机选择的,加速它们的收敛速度。
具体实现:
(1) 群体学习
在这个阶段,假设粒子群中的粒子数量为NP,将粒子进一步划分为NP/K组。对于每个群体来说,不同的粒子在探索和开拓搜索空间方面有不同的能力,这些粒子通过协作和竞争策略更新自己的位置。具体来说,参与者相互竞争来确定他们在组中的排名。较弱的粒子用W表示,较弱的粒子和最差的粒子分别用L1和L2表示。然后,L1通过从W学习来更新它的位置,对于L2,L1和L2都用于更新其状态。赢家直接进入精英学习阶段,输家使用以下策略更新自己的位置和速度:
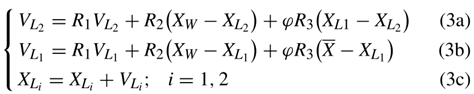
(2) 精英学习
在精英学习阶段,粒子群中的粒子按照合适值的升序排序。然后,这个群体的排序较前的一批粒子被选择形成一个新的群体,用粒子数来表示,剩余的粒子直接传递给群体的下一代。此外,该集合的群体大小为NP/2,其中NP是原始群体大小。观察下一代中的粒子,我们可以看到这些粒子是精英粒子,它们比原始的粒子具有更好的拟合值。因此,这些粒子通常拥有更好的信息来指导其他粒子的学习。在形成的新群体中,粒子(j)从当前粒子群中随机选择两个更好的粒子,然后通过
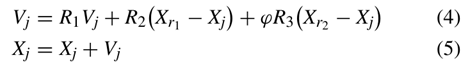
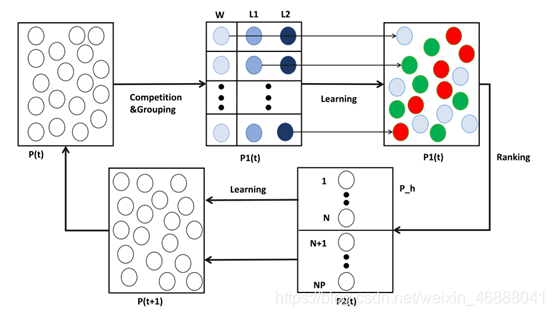
图1:总流程图
创新:在多样性和收敛性中实现平衡。
理论分析证明,与LLSO相比,使其不陷入局部最优;与LLSO和Gpso相比,步调更小,增强探索能力。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!