收手吧!阿组 汇报展示
任务要求:
Task Eight:
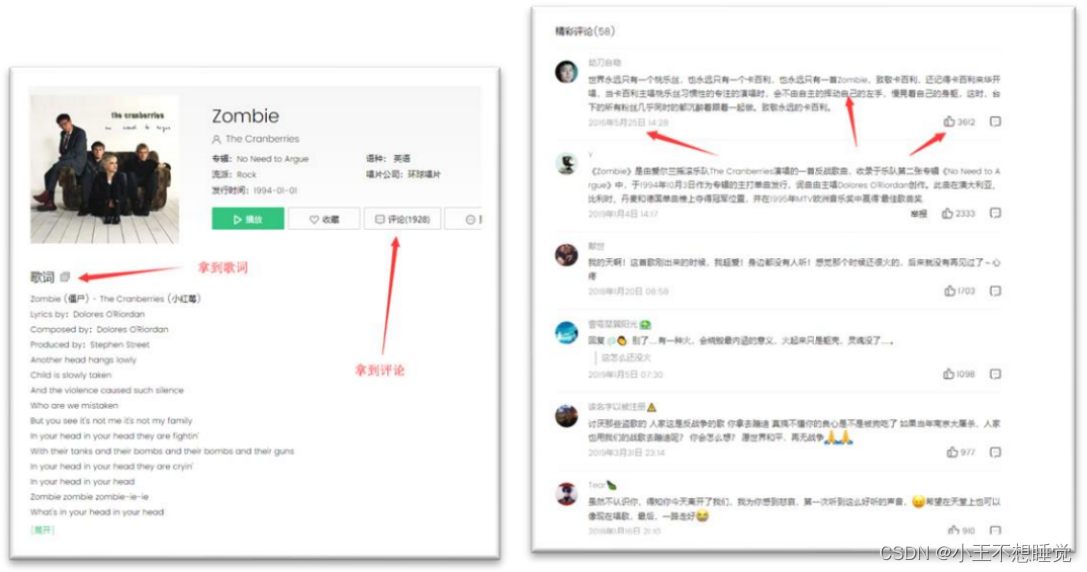
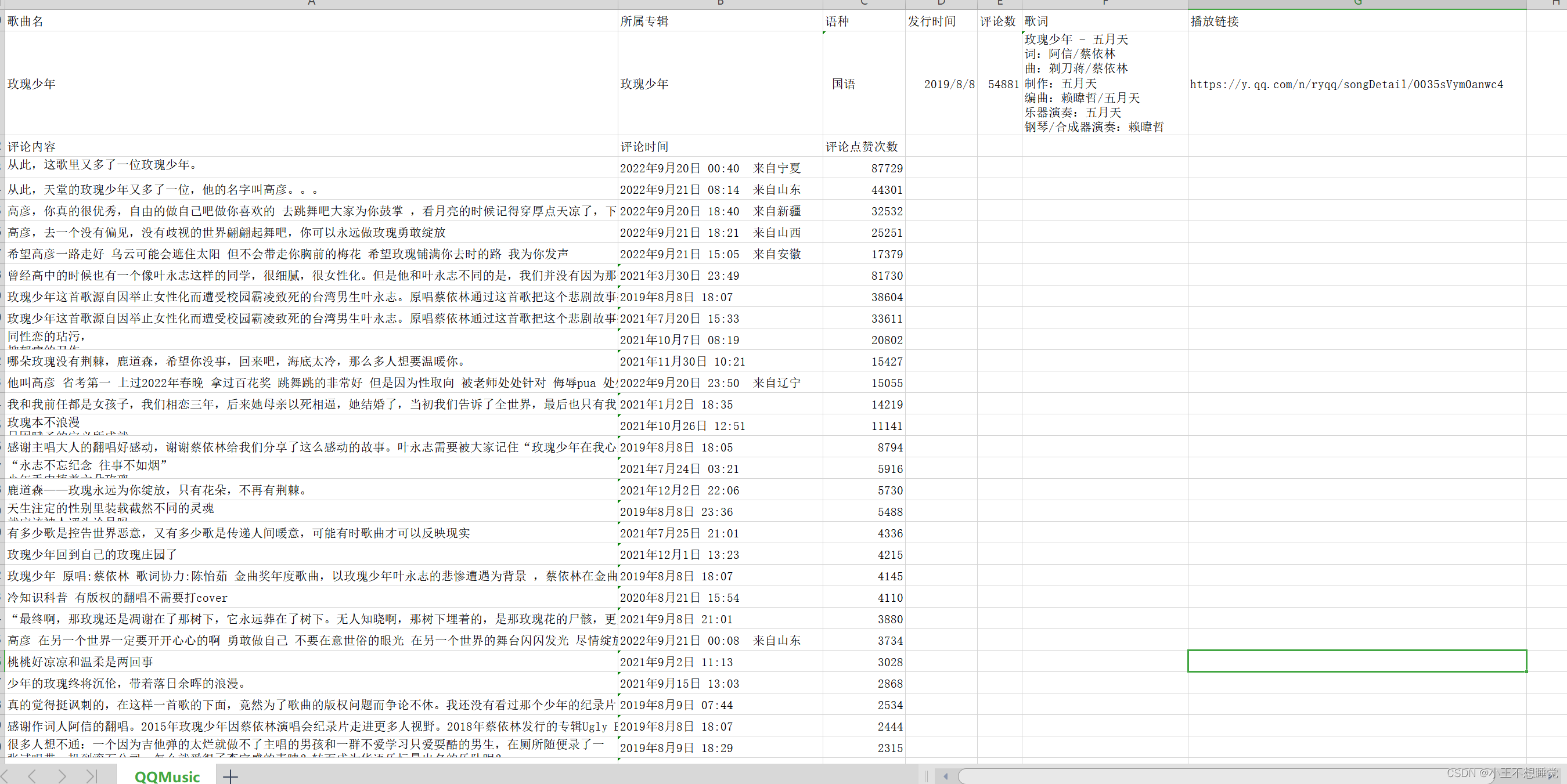
获取某音乐网站中某一首歌的详细信息,包括,
⚫ 歌曲名
⚫ 所属专辑
⚫ 播放链接
⚫ 歌词
⚫ 评论(日期,内容,点赞数量)
例如:
主要功能:
创建浏览器对象:

打开歌手页,写入csv文件:

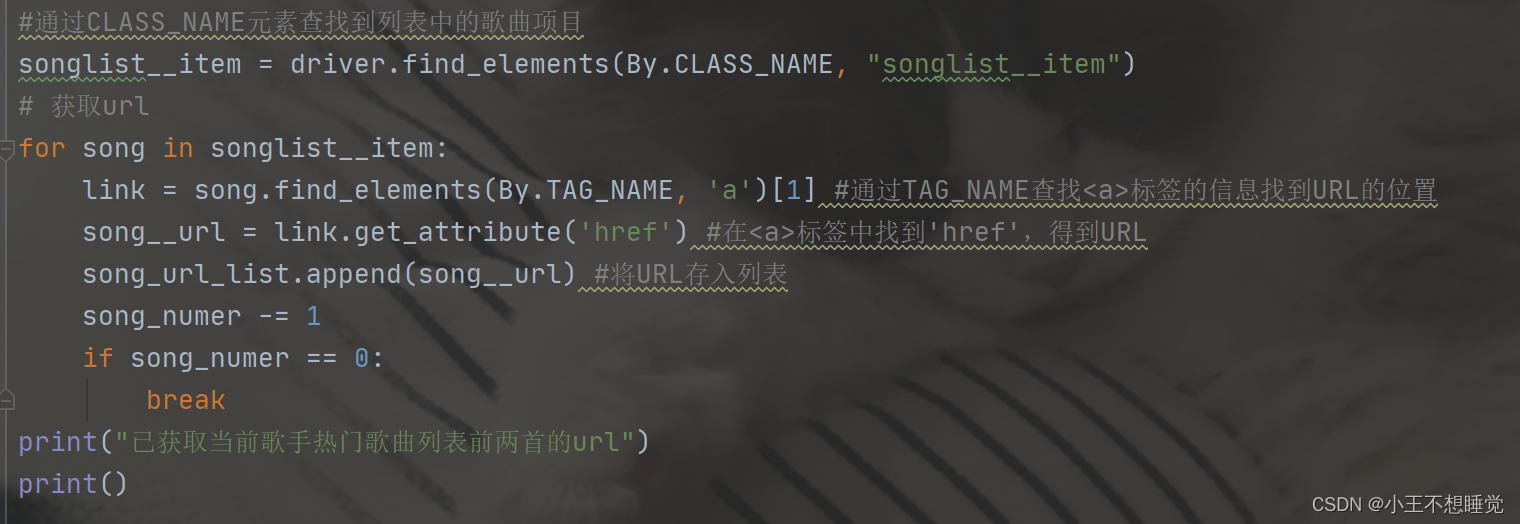
获取前两首歌曲的URL:
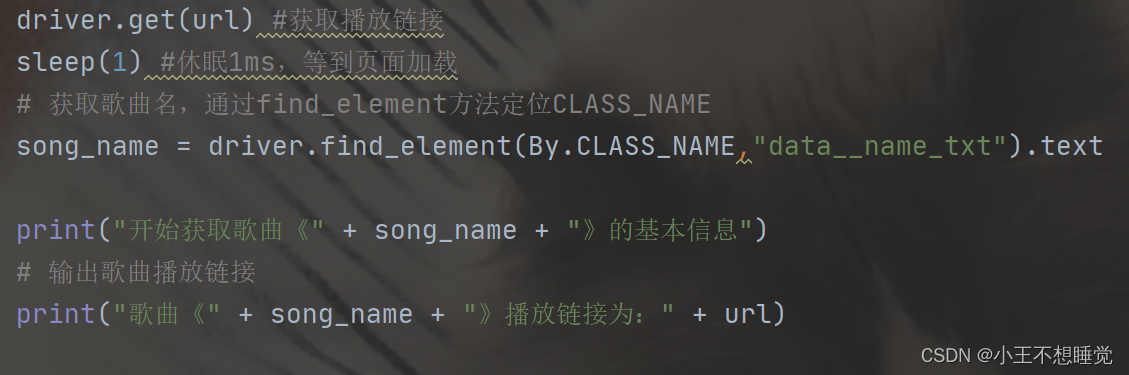
获取播放链接:
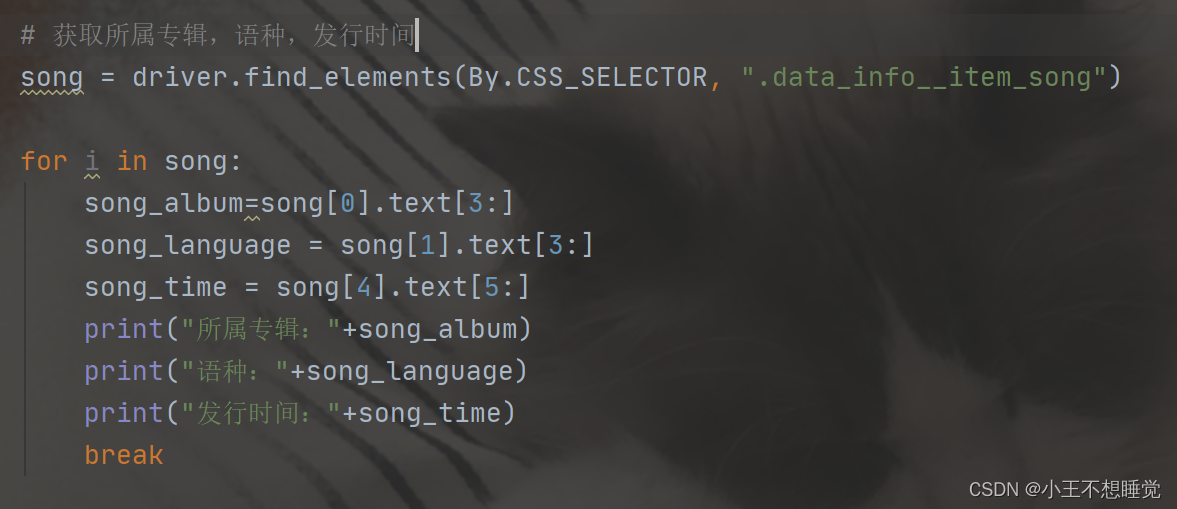
获取所属专辑、语种、发行时间:
获取评论数:

展开获取完整歌词:
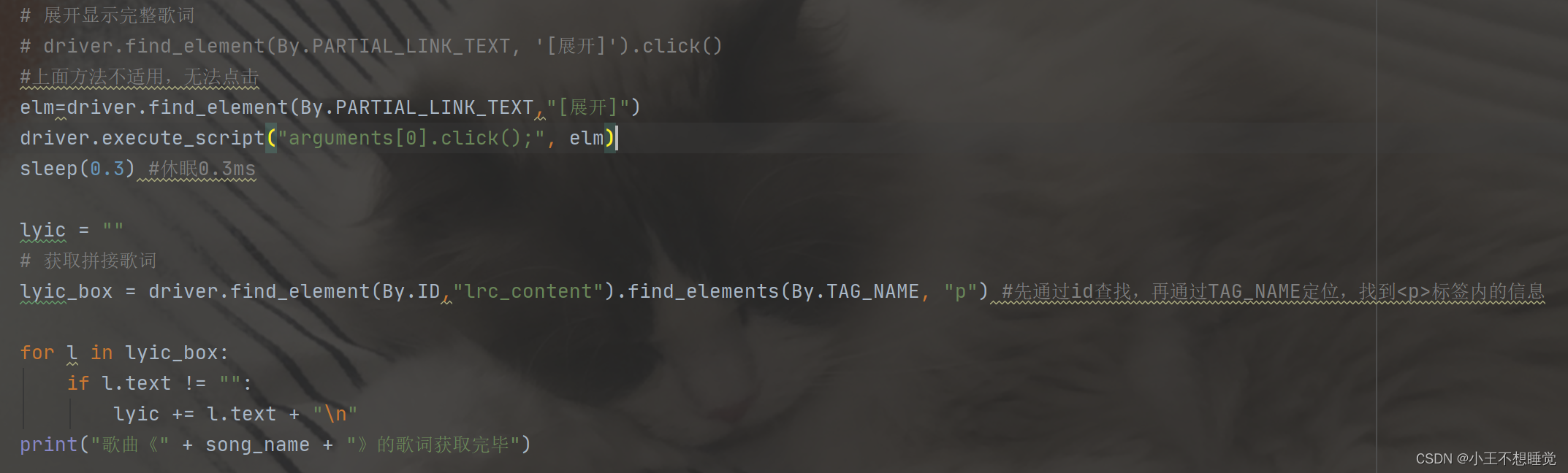
加载更多获取前100条评论:
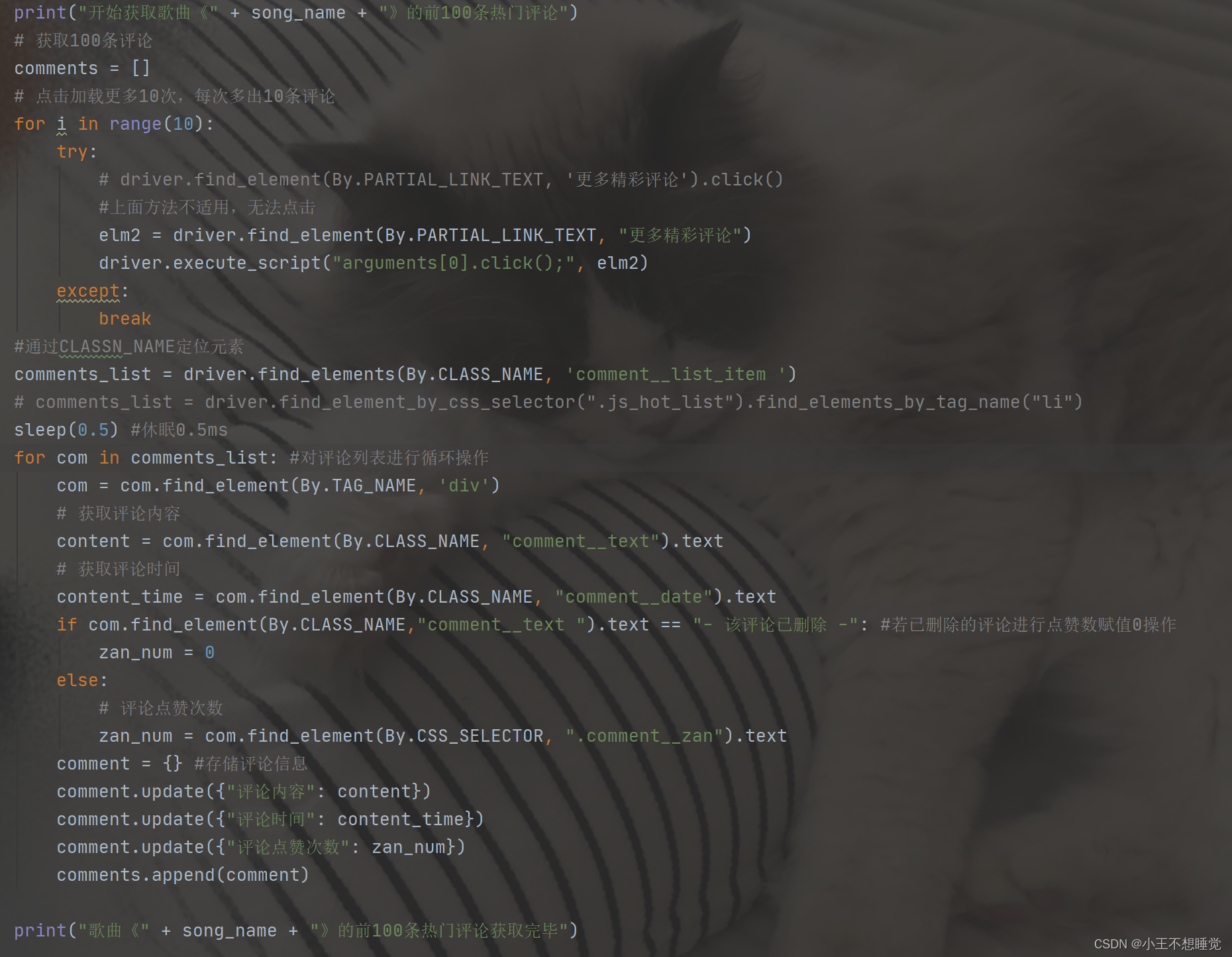
将所有信息写入csv文件:

问题及思考:
在操作过程中遇到了许多问题,通过查找相关资料后总结的解决方法。
问题一:driver=webdriver.Edge(service=s)方法报错
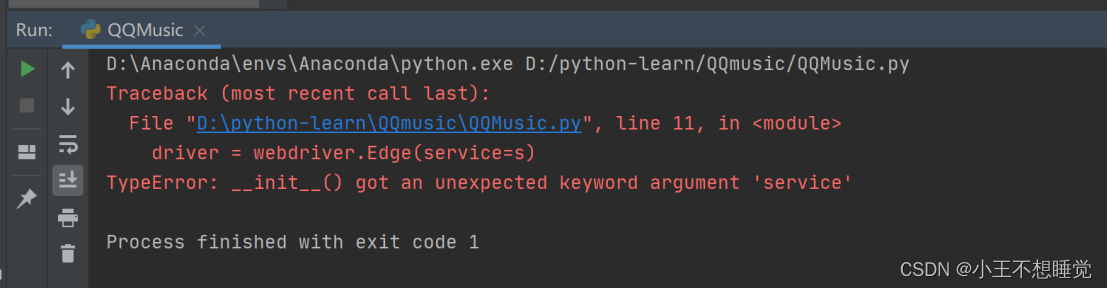
原因:Selenium版本与语句不适应,有些方法语句已被弃用,需搜索当前版本所匹配的语句。
解决方法:
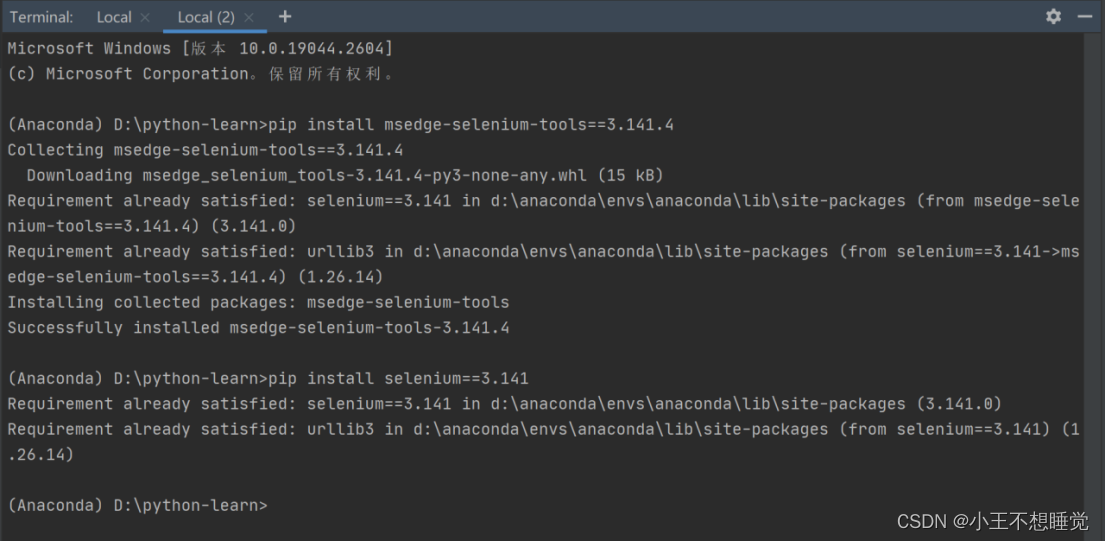
查看Selenium版本后,使用 pip 安装 msedge-selenium-tools 和 selenium 程序包,改用当前版本匹配的语句:

问题二:元素定位错误
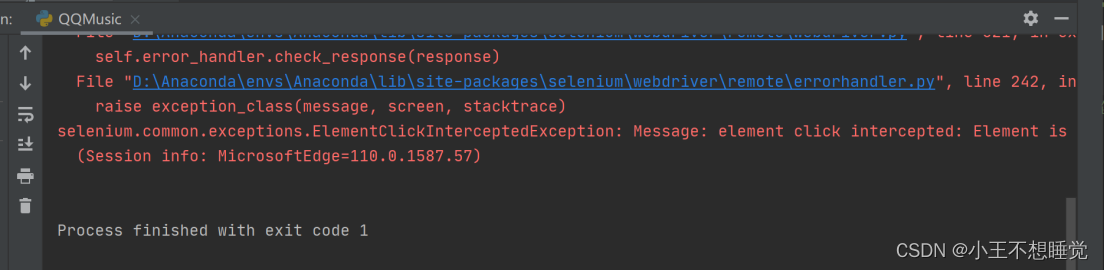
原因:页面未加载成功,元素点击有误,需要休眠给网页加载的时间。
解决方法:导入time包,在找到元素前休眠。

问题三:find_element 和 find_elements 使用不当,方法混淆
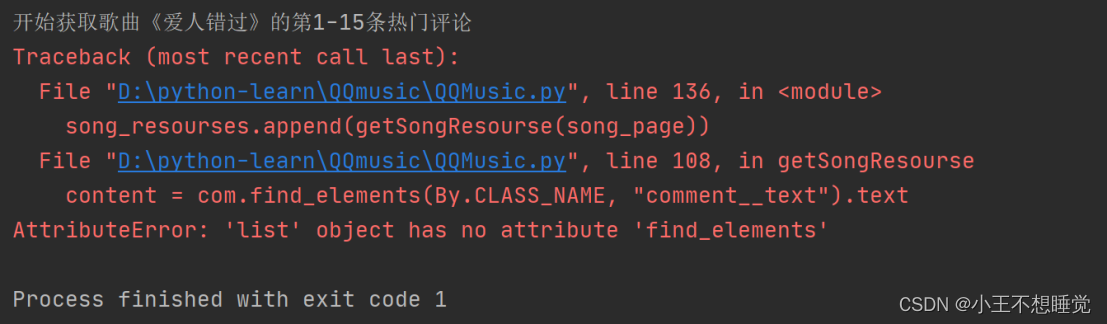
原因:原理不同,以下是其异同点:
只查找一个元素的时候:可以使用find_element(),find_elements()。find_element()会返回一个WebElement节点对象,但是没找到会抛出NoSuchElementException异常,而find_elements()不会,之后返回一个空列表;
查找多个元素的时候:只能用find_elements(),返回一个列表,列表里的元素全是WebElement节点对象
找到都是节点(标签)
如果想要获取相关内容(只对find_element()有效,列表对象没有这个属性) 使用 .text;
如果想要获取相关属性的值(如href对应的链接等,只对find_element()有效,列表对象没有这个属性):使用 .get_attribute("href")
解决方法:根据使用场景进行修改,find_element()改为find_elements(),或反之。
问题四:csv文件乱码

原因:编码格式不匹配,以下为相关拓展:
utf-8 与 utf-8-sig 有什么区别?
utf-8 以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,也因此它实际上并不需要 BOM;
uft-8-sig 中 sig 全拼为 signature,即带有签名的 utf-8(UTF-8 with BOM);
BOM 全称 ByteOrder Mark,字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
为什么写入 csv 文件要用 utf-8-sig 编码?
Excel 在读取 csv 文件的时候是通过读取文件头上的 BOM 来识别编码的,如果文件头无 BOM 信息,则默认按照 Unicode 编码读取。
当我们使用 utf-8 编码来生成 csv 文件的时候,并没有生成 BOM 信息,Excel 就会自动按照 Unicode 编码读取,就会出现乱码问题了。
为什么写入 txt 文件要用 utf-8 编码?
在写入 txt 文件时,Windows 会默认转码成 gbk,遇到某些 gbk 不支持的字符就会报错,在打开文件时就声明编码方式为 utf-8 就能避免这个错误。
解决方法: utf-8 改为 utf-8-sig

改为


问题五:歌词和评论无法显示全部,click()方法报错
selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted:
原因:网页使用Js动态加载,是不可交互式元素的点击。
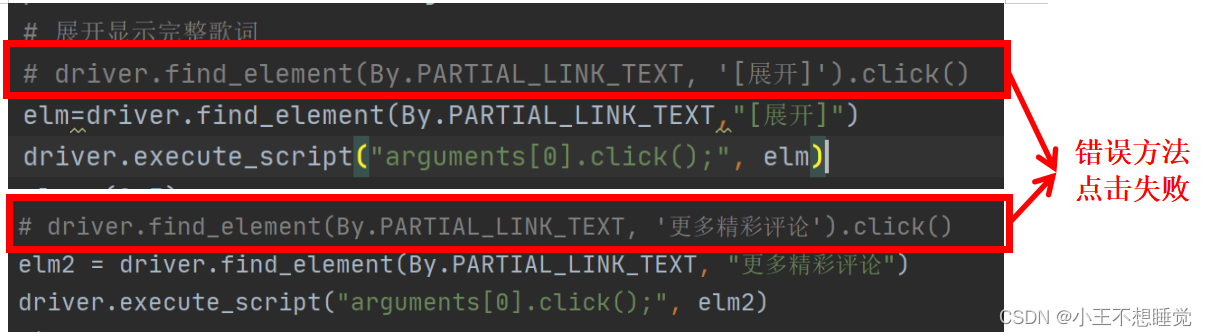
解决方法:
先查找元素,不要点击,例如:
element = wait.until(expected_conditions.element_to_be_clickable(locator), '等待超时')
使用如下语句执行点击动作,将元素作为参数传入
self.driver.execute_script("(arguments[0]).click();", element)
此办法可用于,JS动态加载,不可交互式元素的 input 点击事件
完整代码:
from selenium import webdriver
import csv
from selenium.webdriver.common.by import By
from time import sleep
import time# 创建Edge浏览器对象
driver=webdriver.Edge() ##以下为网上搜索的早期方法,因为Selenium的版本更新,有点方法语句不再适用,则需要改为现在的语句,才能正常运行
# s = Service(r"D:\Anaconda\envs\Anaconda\MicrosoftWebDriver.exe")
# driver = webdriver.Edge(service=s)
driver.maximize_window()#最大化窗口,防止页面遮挡,导致定位元素有误sleep(1)#休眠1ms,等待页面加载完成
# 打开QQ音乐-五月天页面
driver.get("https://y.qq.com/n/ryqq/singer/000Sp0Bz4JXH0o")#可根据自己想爬取的歌手进行修改
# 配置
csv_file = open('QQMusic.csv', 'w', newline='', encoding='utf-8-sig')#打开并写入csv文件,此处编码需要用utf-8-sig,否则csv文件会乱码
writer = csv.writer(csv_file)
start = time.time()#记录开始爬取的时间# 爬取前两首歌的信息
song_numer = 2 #可根据自身需求调整
song_url_list = [] #歌曲URL列表
song_resourses = [] #歌曲资源列表#通过CLASS_NAME元素查找到列表中的歌曲项目
songlist__item = driver.find_elements(By.CLASS_NAME, "songlist__item")
# 获取url
for song in songlist__item:link = song.find_elements(By.TAG_NAME, 'a')[1] #通过TAG_NAME查找标签的信息找到URL的位置song__url = link.get_attribute('href') #在标签中找到'href',得到URLsong_url_list.append(song__url) #将URL存入列表song_numer -= 1if song_numer == 0:break
print("已获取当前歌手热门歌曲列表前两首的url")
print()# 获取一首歌曲的信息
def getSongResourse(url): #获取URL,进入歌曲详情页song_resourse = {} #存储歌曲资源driver.get(url) #获取播放链接sleep(1) #休眠1ms,等到页面加载# 获取歌曲名,通过find_element方法定位CLASS_NAMEsong_name = driver.find_element(By.CLASS_NAME,"data__name_txt").textprint("开始获取歌曲《" + song_name + "》的基本信息")# 输出歌曲播放链接print("歌曲《" + song_name + "》播放链接为:" + url)# 获取所属专辑,语种,发行时间song = driver.find_elements(By.CSS_SELECTOR, ".data_info__item_song")for i in song:song_album=song[0].text[3:]song_language = song[1].text[3:]song_time = song[4].text[5:]print("所属专辑:"+song_album)print("语种:"+song_language)print("发行时间:"+song_time)break# 获取评论数pinlun = driver.find_elements(By.CSS_SELECTOR, ".mod_btn") #这里是通过按钮上的数值获取评论数for i in pinlun:song_comment_num = pinlun[2].text[3:-1]print("歌曲评论数:"+song_comment_num)breakprint("歌曲《" + song_name + "》基本信息获取完毕")print("开始获取歌曲《" + song_name + "》的歌词")# 展开显示完整歌词# driver.find_element(By.PARTIAL_LINK_TEXT, '[展开]').click()#上面方法不适用,无法点击elm=driver.find_element(By.PARTIAL_LINK_TEXT,"[展开]")driver.execute_script("arguments[0].click();", elm)sleep(0.3) #休眠0.3mslyic = ""# 获取拼接歌词lyic_box = driver.find_element(By.ID,"lrc_content").find_elements(By.TAG_NAME, "p") #先通过id查找,再通过TAG_NAME定位,找到标签内的信息for l in lyic_box:if l.text != "":lyic += l.text + "\n"print("歌曲《" + song_name + "》的歌词获取完毕")print("开始获取歌曲《" + song_name + "》的前100条热门评论")# 获取100条评论comments = []# 点击加载更多10次,每次多出10条评论for i in range(10):try:# driver.find_element(By.PARTIAL_LINK_TEXT, '更多精彩评论').click()#上面方法不适用,无法点击elm2 = driver.find_element(By.PARTIAL_LINK_TEXT, "更多精彩评论")driver.execute_script("arguments[0].click();", elm2)except:break#通过CLASSN_NAME定位元素comments_list = driver.find_elements(By.CLASS_NAME, 'comment__list_item ')# comments_list = driver.find_element_by_css_selector(".js_hot_list").find_elements_by_tag_name("li")sleep(0.5) #休眠0.5msfor com in comments_list: #对评论列表进行循环操作com = com.find_element(By.TAG_NAME, 'div')# 获取评论内容content = com.find_element(By.CLASS_NAME, "comment__text").text# 获取评论时间content_time = com.find_element(By.CLASS_NAME, "comment__date").textif com.find_element(By.CLASS_NAME,"comment__text ").text == "- 该评论已删除 -": #若已删除的评论进行点赞数赋值0操作zan_num = 0else:# 评论点赞次数zan_num = com.find_element(By.CSS_SELECTOR, ".comment__zan").textcomment = {} #存储评论信息comment.update({"评论内容": content})comment.update({"评论时间": content_time})comment.update({"评论点赞次数": zan_num})comments.append(comment)print("歌曲《" + song_name + "》的前100条热门评论获取完毕")print("歌曲《" + song_name + "》所有信息获取完毕")print()#将已获取的信息存入歌曲资源song_resourse.update({"歌曲名": song_name})song_resourse.update({"所属专辑": song_album})song_resourse.update({"语种": song_language})song_resourse.update({"发行时间": song_time})song_resourse.update({"评论数": song_comment_num})song_resourse.update({"歌词": lyic})song_resourse.update({"播放链接": url})song_resourse.update({"100条精彩评论": comments})return song_resourse #返回当前歌曲资源# 对歌曲列表进行循环操作,存储
for song_page in song_url_list:song_resourses.append(getSongResourse(song_page))
# 将已获取的信息写入csv文件
for i in song_resourses:writer.writerow(["歌曲名","所属专辑","语种", "发行时间", "评论数","歌词","播放链接"])writer.writerow([i["歌曲名"],i["所属专辑"],i["语种"], i["发行时间"], i["评论数"],i["歌词"],i["播放链接"]])writer.writerow(["评论内容", "评论时间", "评论点赞次数"])for j in i["100条精彩评论"]:writer.writerow([j["评论内容"], j["评论时间"], j["评论点赞次数"]])writer.writerow([])csv_file.close() #关闭csv文件
end = time.time() #记录爬取结束的时间
print("爬取完成,总耗时"+str(end-start)+"秒") #计算爬取全程所花费的时间
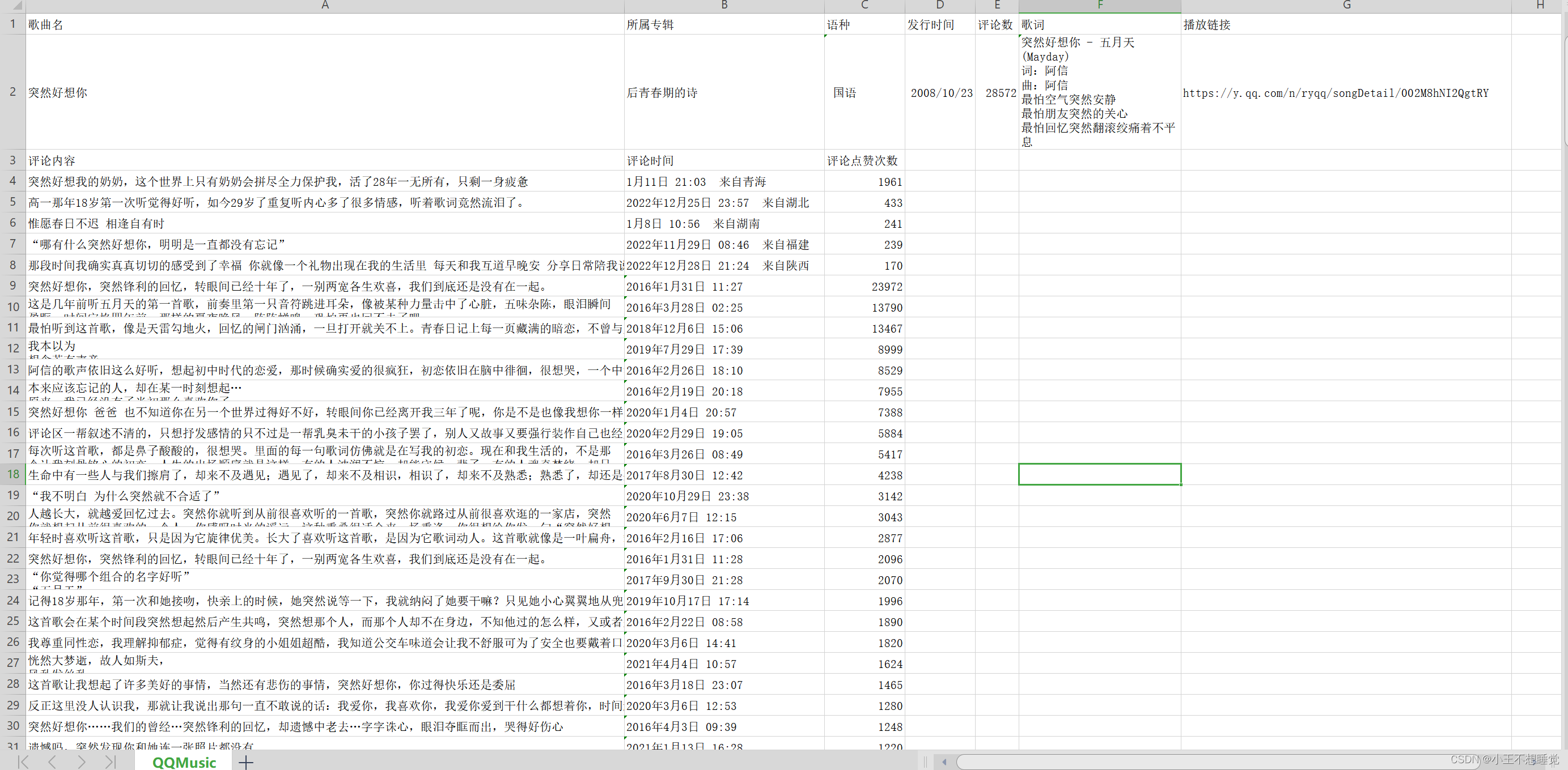
成果展示:
cr.收手吧!阿组
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!