语音识别技术的前世今生【今生篇】
目录
1.前馈神经网络
1.1Tandem结构
1.2 Hybrid结构
2.循环神经网络
2.1 CTC
2.2 Graphheme系统
2.3 注意力机制
3 语音识别之未来
3.1 语音识别的现状
3.2 语音识别的未来
参考文献:

1.前馈神经网络
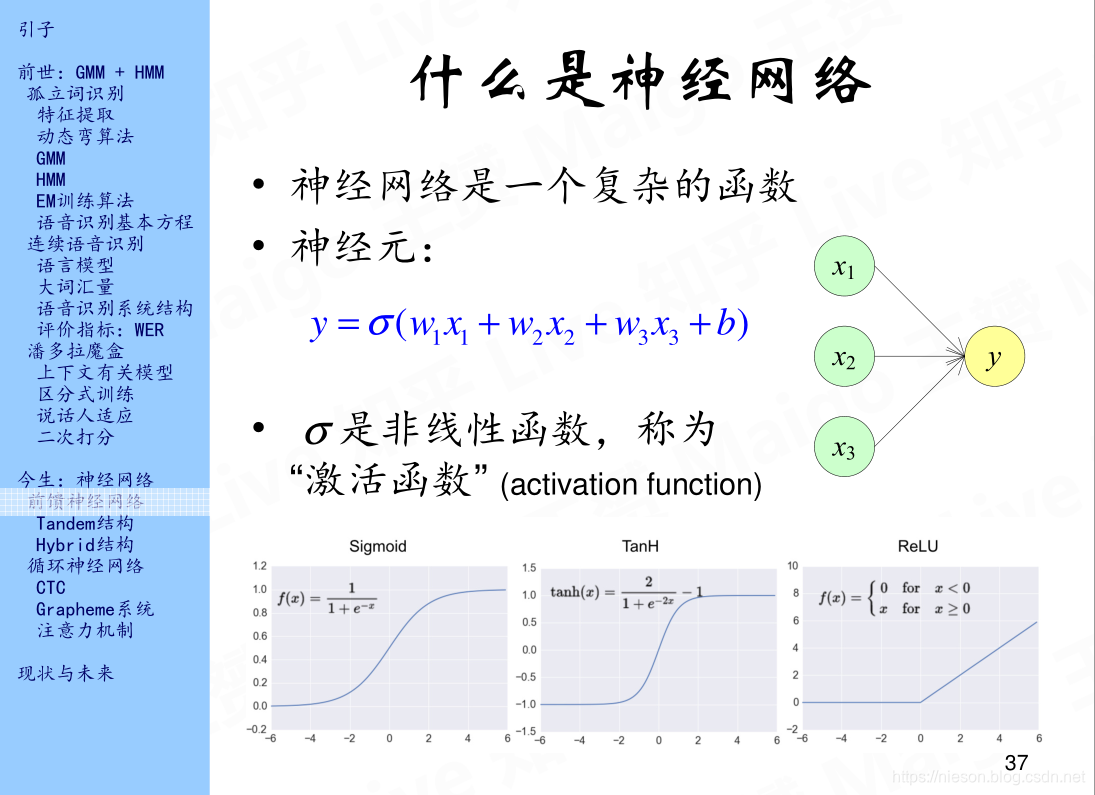
近几年深度学习的技术非常火,我们平时所说的深度学习主要是指深度神经网络,神经网络是一种监督学习的技术。神经网络是一个复杂的函数,类比于人脑的神经网络,人工神经网络也是由许多个神经元组成神经网络即不同神经元组合在一起的集合。如上图所示,x1,x2,x3为输入层,y为输出层,x1,x2,x3经过某种函数变换得到输出y,w1,w2,w3分别表示属性x1,x2,x3的权重,b为bias表示偏差,将w1x1+w2x2+w3x3+b经过类似于黑盒子的变换会得到y,我们称这个类似于黑盒子的东西为激活函数,常见的激活函数有三个,第一个是Sigmoid又称S函数,它把![[-\infty,+ \infty]](https://img-blog.csdnimg.cn/20181218192822706)
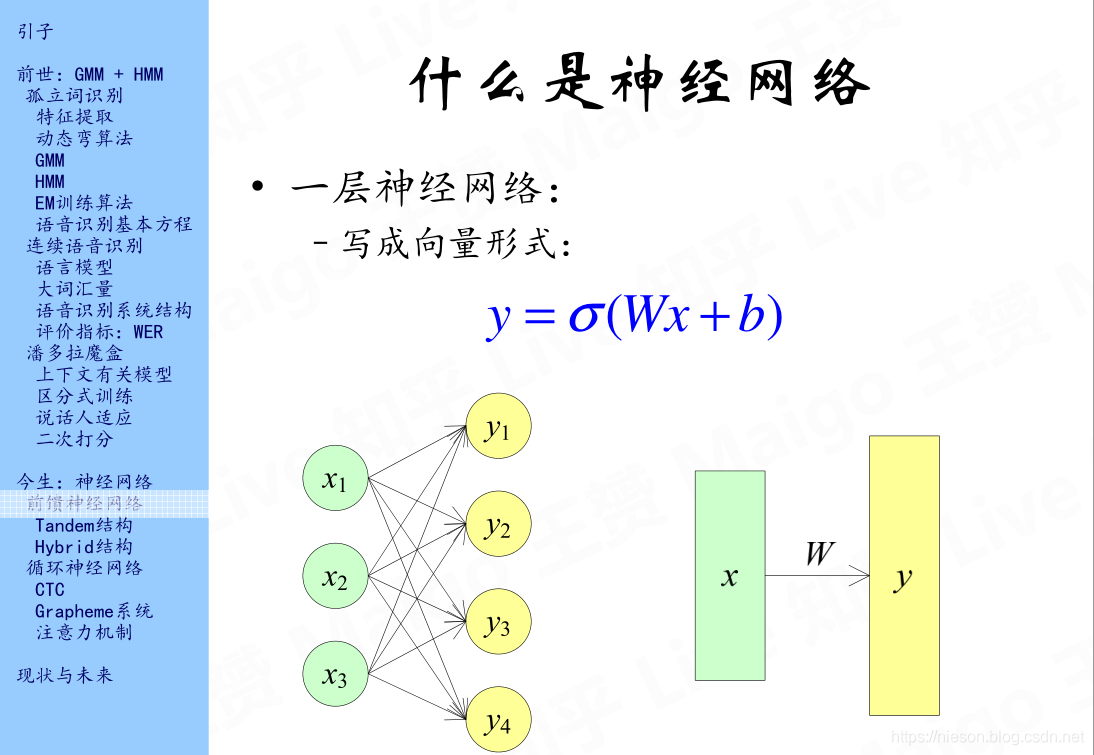
上边这个图是最简单的一层神经网络,输入层有3个神经元,经过激活函数后,得到4个输出神经元。
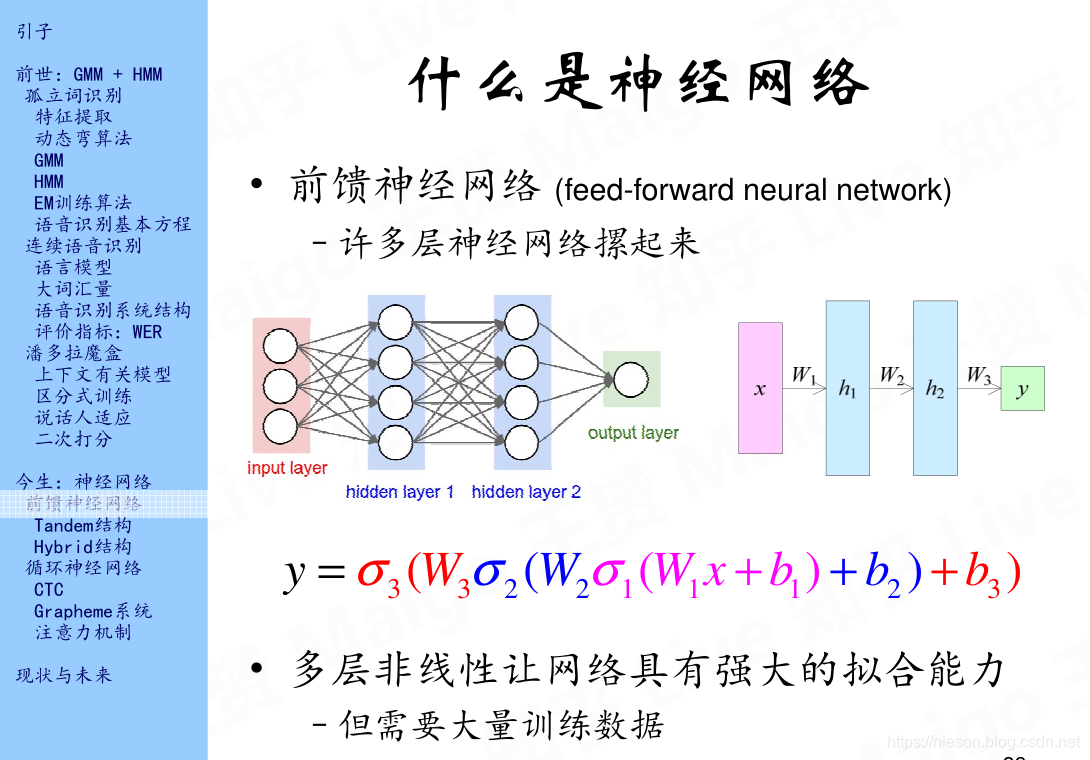
上边的图就是一个四层的网络,即输入输出层和两个隐藏层,当层数不断变多时,神经网络就变成了深度神经网络,这样的网络有很强的拟合能力,但是它需要大量的输入数据,否则它相比于其他的分类方法并没有什么优势,甚至有时候不如一般的分类算法。每一层到下一层都需要一个激活函数,也就是说,从输入层到第一隐藏层,我们会需要一个激活函数,同样的,第二层到第三层我们还是会需要一个激活函数,依次类推。最后得到由输入层到输出层的一个函数表达式。

那么神经网络能够做什么,神经网络可以解决机器学习中的两大问题:回归和分类。这里有关回归和分类的区别就不多说了。神经网络又继续分为卷积神经网络(CNN)和循环神经网络(RNN),这两种神经网络也是针对于不同的应用场景,CNN主要是解决图像、视频类的问题,比如人脸识别等等,而RNN主要是解决时间序列的问题,比如一些具有时间维度的信号,比如语音信号。下面将会讲解RNN在语音识别领域中的应用。其实神经网络很久以前就有了,经过几次冬天以后,在近几年迎来了井喷式的发展,这主要得益于两点:数据量的增加和计算力的提升。我们知道,数据之于AI就如石油煤炭之于工业革命时期,所以数据的重要性不言而喻,现在随着数据量的不断增加,为研究人员训练模型提供了原料支持;只有原料没有发动机也是白费的,随着GPU的诞生,计算机的计算力得到大大提升,这也为神经网络更进一步说是深度学习提供了硬件支持。

神经网络的功能很强大,但是它的训练过程是一大考验,其一是训练时长较长,其二就是训练过程的调参是一项巨大的工程。训练模型其实就是确定参数,从而使模型达到最好效果的过程,那么对于神经网络,我们需要找到合适的权值矩阵W以及误差b。首先我们需要定义一个损失函数(loss function),训练它我们可以使用梯度下降法(有关梯度的知识点我在之前的博客中有写到),通过反向传播也就是常说的BP算法,我们可以训练得到神经网络的模型。
1.1Tandem结构


语音信号的特征是MFCC序列,那么在Tandem结构中,我们可以用神经网络来提取特征,如上图所示,这里有一个输入,然后经过很多层就会得到一个输出,那么它的输入是什么呢,可以使连续若干帧的滤波器组输出,甚至可以直接输入波形。输出是上下文有关因素的分布,这其实是多分类问题,因为上下文有关的因素会有成百上千个,那么这就是一个千分类问题。因为神经网络是监督学习,那么它就需要有label也就是所谓的标准答案或者标签,通常这个标准答案是由传统的GMM+HMM系统获得。我们训练好模型之后,特征从哪里获取呢,通常特征从神经网络的中间层获取,上篇文章中距离说的MFCC序列为13维,我们在神经网络中会设置一个维度比较小的层,通常也就几十维,并以它作为语音信号的输出,这一层成为Bottleneck层,得到的这特征就可以代替MFCC序列。以为特征来自Bottleneck层,所以它后面的那些层可以认为是无用的。
1.2 Hybrid结构

在Hybrid结构中,用DNN代替GMM,而且省略了特征提取的部分。这部分直接看PPT,不多说明了。
2.循环神经网络

DNN在霸占了特征提取和GMM之后,还想取代HMM,于是引出了RNN,也就是循环神经网络。
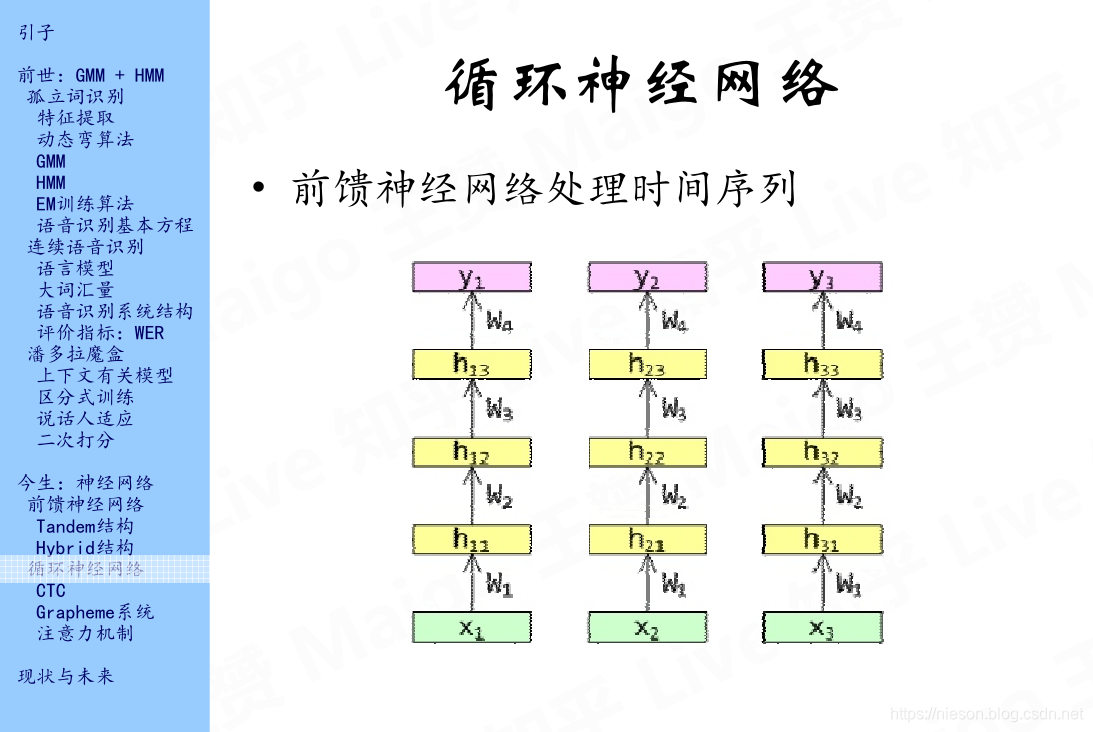
语音信号是一个时间序列,前馈神经网络每一帧都是独立处理的,不会有上下文。如上图所示,每一列为一帧,我们无法从输入x1到达y2,所以引入了RNN。
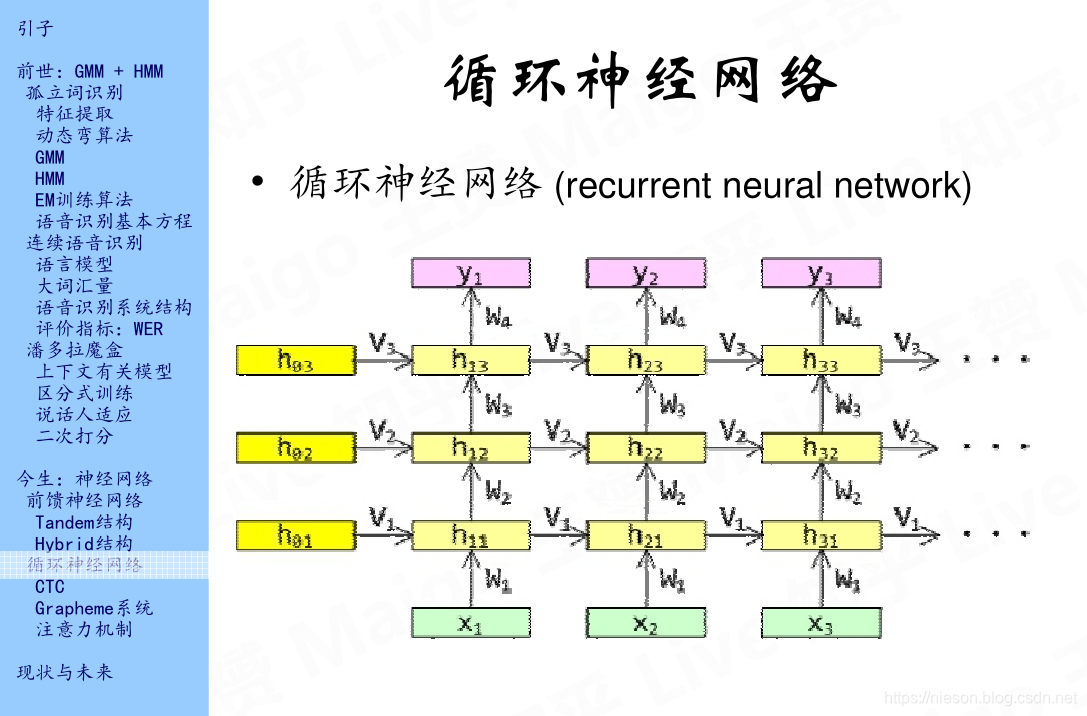
可以看到,在RNN建立了时间上的上下文,我们可以从输入特征x1沿着很多不同的路径到达y3。深黄色的h01,h02,h03表示隐层状态的初始值,可以把它设置为零向量,下标中的第一个数字表示所在的时间,第二个数字表示层,例如h01表示第一隐藏层的初始时间。这个神经网络的输入是x输出是y,应该是从下到上看,而不是习惯上的从左到右看。我们可以看到,我们可以从x1到达y2,但是我们不能从x3到达y2,y1,这是隐含的一种缺陷,因此,我们引入了双向循环神经网络,继续往下看。
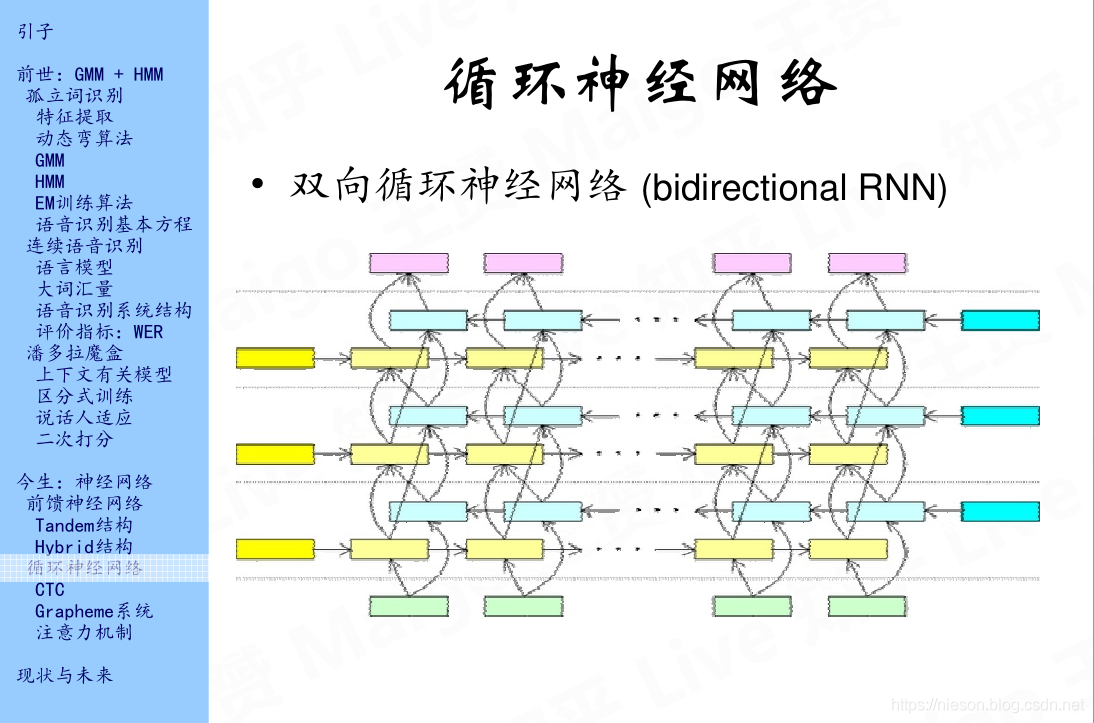
上图中黄色的矩形表示沿着时间轴正向的从左到右的一种关联,而浅蓝色的矩形表示沿着时间轴逆向的从右往左的一种关联,这样一来,我们不仅可以从前一状态到下一状态,还可以从下一状态到前一状态,所以对于输入,我们可以沿着不同的路径达到输出。

循环神经网络在处理语音信号时有许多难点。第一个就是梯度消失或爆炸问题,对于神经网络的训练,我们一般是使用BP算法进行梯度的下降,但是在循环神经网络中,梯度不仅沿前后传播,而且还沿着时间维度传播,反映到双向循环网络的框图中就是从左往右以及从右往左的传播,而梯度在每一次传播时都需要乘上一个矩阵V或者W,当矩阵中的值比较小时梯度会变小甚至会消失,而当矩阵中的值比较大时,梯度会变大,从而会爆炸,导致训练结果不收敛。解决方法就是使用LSTM/GRU。RNN可以代替DNN用于特征提取,这个是在Tandem结构,而RNN用于声学模型,这个是在Hybrid结构。RNN有处理上下文的能力,那么为什么还始终保留HMM呢,原因如上图所示,不再进行说明。
2.1 CTC

HMM存在一些缺点,所以提出了一种文字为CTC的技术,CTC技术不再进行逐帧判别,这样就不用再依赖HMM,对于皮卡丘这个词,普通声学模型和CTC输出得到的结果如上图PPT所示,这里没有什么可说明的。

CTC假设各帧输出相互独立,而且认为上下文已由RNN处理。它的训练过程与HMM的训练过程类似,但是因为没有转移概率,所以它要比HMM简单一些,解码过程中仍需要词典和语言模型。
2.2 Graphheme系统
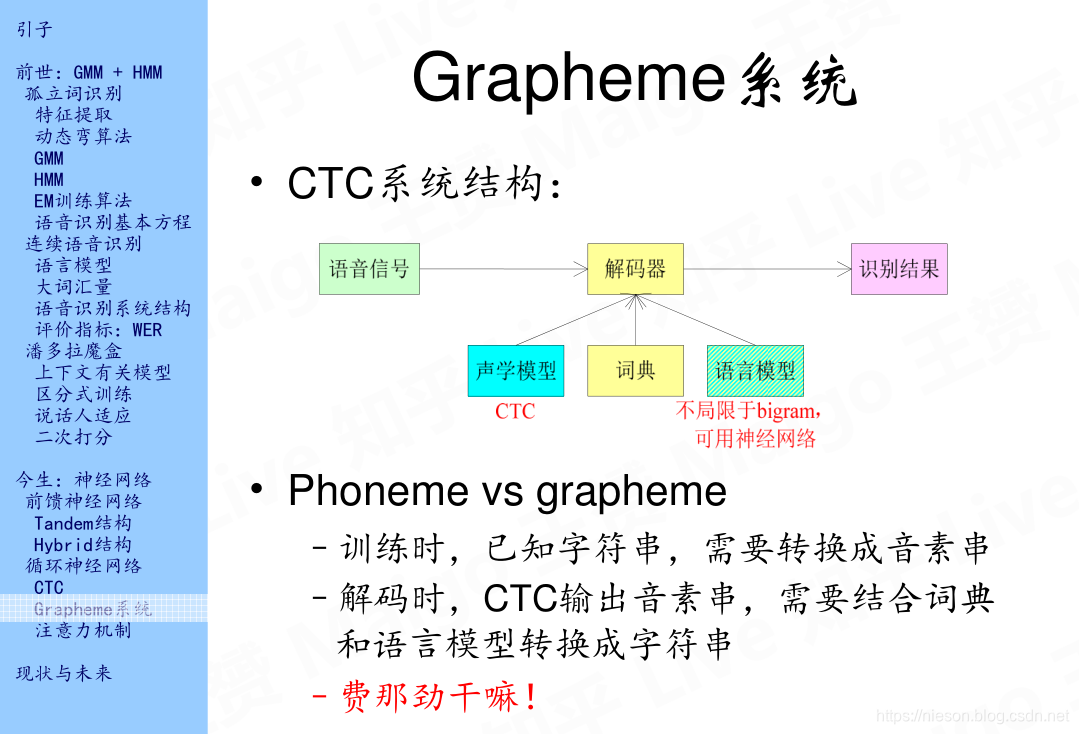
经过以上的变化之后,最初的语音识别的模型变成了如上PPT中的样子,声学模型用CTC代替。
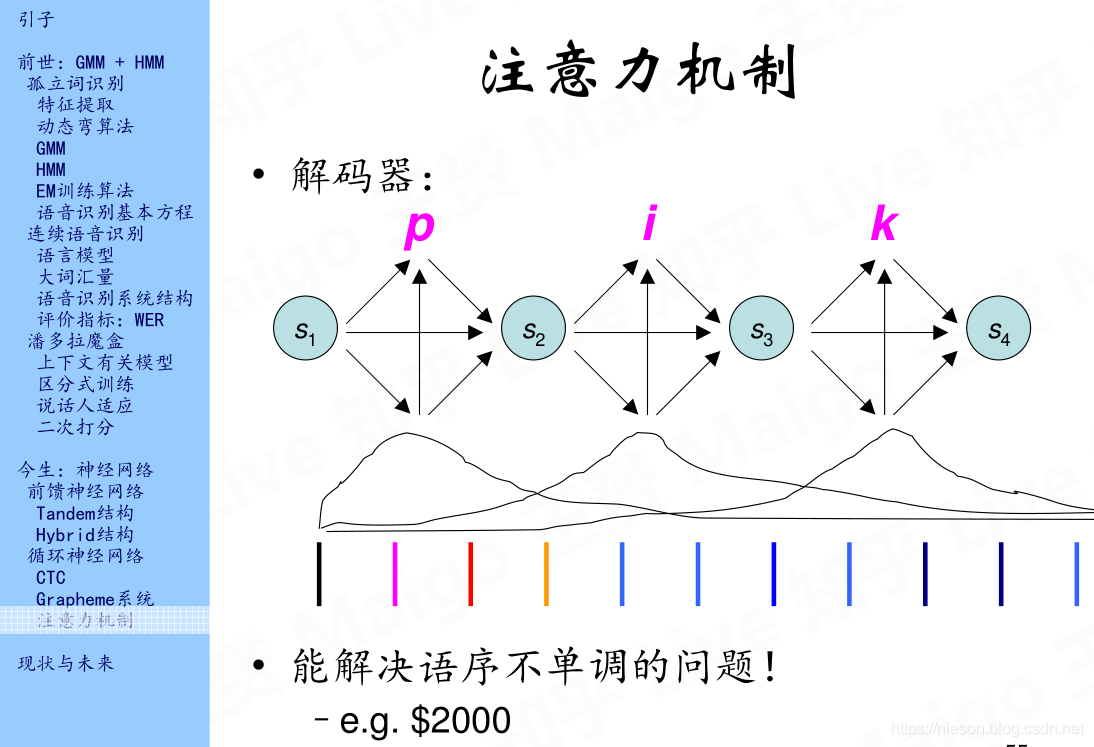
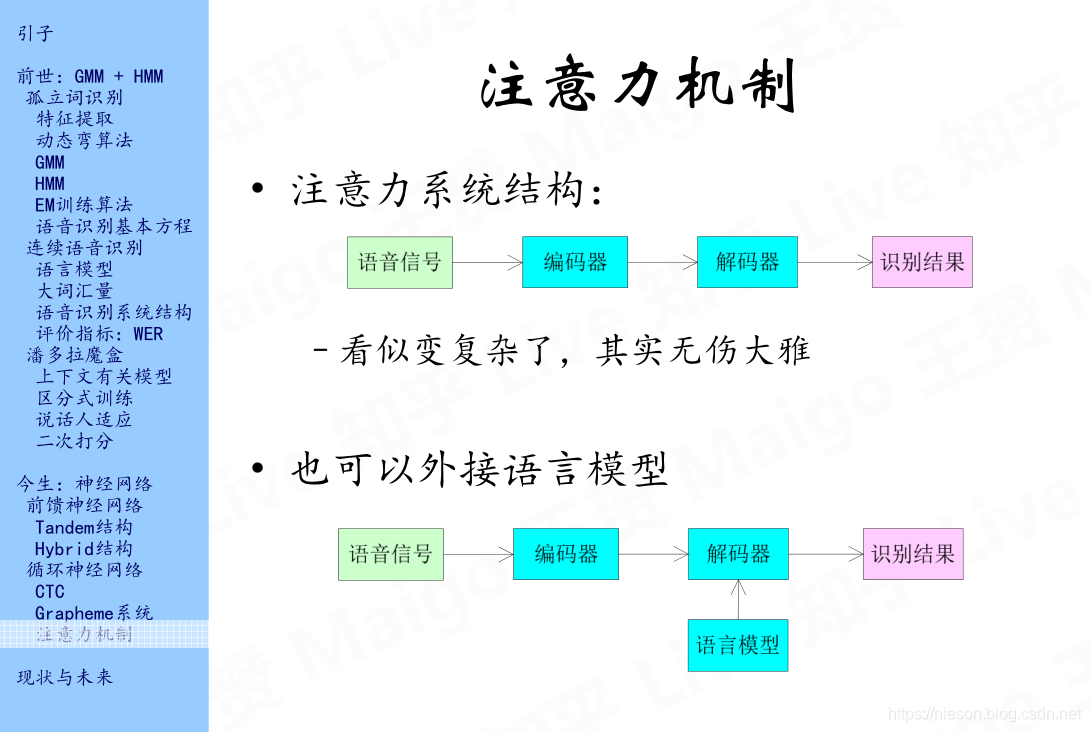
2.3 注意力机制

3 语音识别之未来

3.1 语音识别的现状

3.2 语音识别的未来

以上为语音识别技术前世今生之今生篇,如果你想了解它的前世,请查看语音识别技术的前世篇:
语音识别技术的前世今生【前世篇】
参考文献:
1. 深度学习工程师 https://mooc.study.163.com/smartSpec/detail/1001319001.htm
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!