python爬虫,13行代码把2520个美女带回家,快速掌握
今天发现一个宝藏网站,里面有许多宝藏图片。宝藏太多,点击一个一个下载太辛苦,就用爬虫来帮我一键下载所有宝藏图片。
部分截图如下:

接下来就看看我们是如何使用13行代码实现的。
爬虫一般步骤:
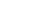
数据爬取
数据解析
数据存储
结合到本案例来说目的就是爬取所有美女图片:
1.先实现单张下载开始;
2.再实现全部图片的下载;
目标网站:
https://www.mn52.com/
宝藏网站首页:

我们先来实现单张图片的爬取:
1.获取单张图片链接,这个就是我们所要请求的目标url。(这图片质量,啧啧。没得说)

https://image.mn52.com/img/allimg/2020-08-08/973dbdc6-644d-437a-836a-1da23366ca52_a26042b121.jpg
2.可以看出我们第一张mn.jpg图片已经成功保存到本地。代码很简单,不再过多赘述哈,详见注释。
import requests
#目标url
img_url = 'https://image.mn52.com/img/allimg/2020-08-08/973dbdc6-644d-437a-836a-1da23366ca52_a26042b121.jpg'
#获取响应
resp = requests.get(img_url)
#打印响应状态码
#print(resp.status_code) #200 表示请求发送成功
#保存图片
with open('img\mn.jpg', 'wb') as fin:fin.write(resp.content)
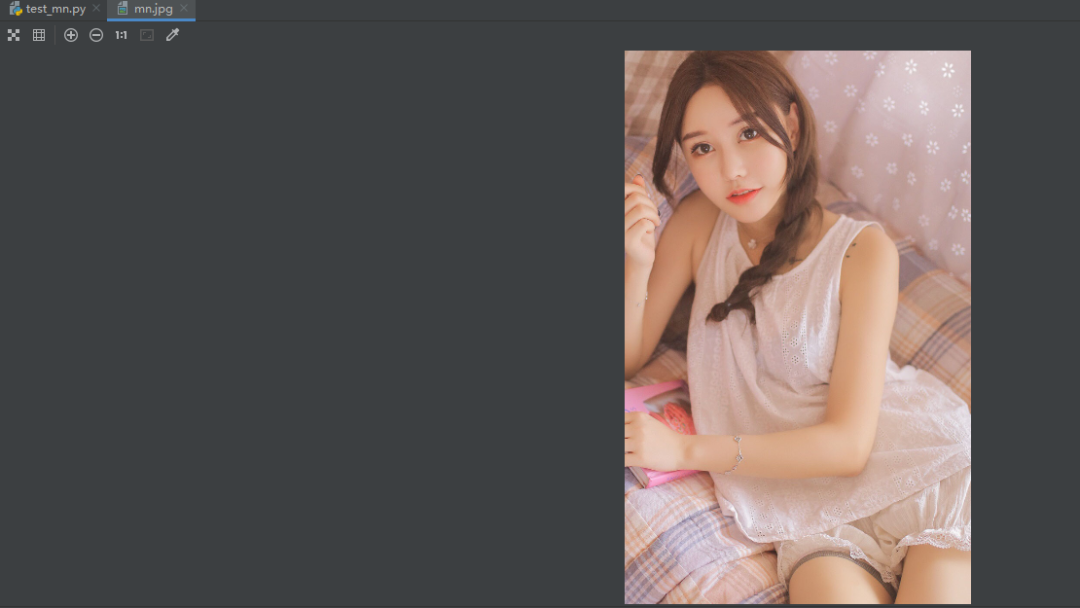
接下来我们要做的是获取全部图片,可以看得出本页有28张图片。所以我们要爬取的连接就是浏览器网页url。
https://www.mn52.com/meihuoxiezhen/
获取到网页信息如下:
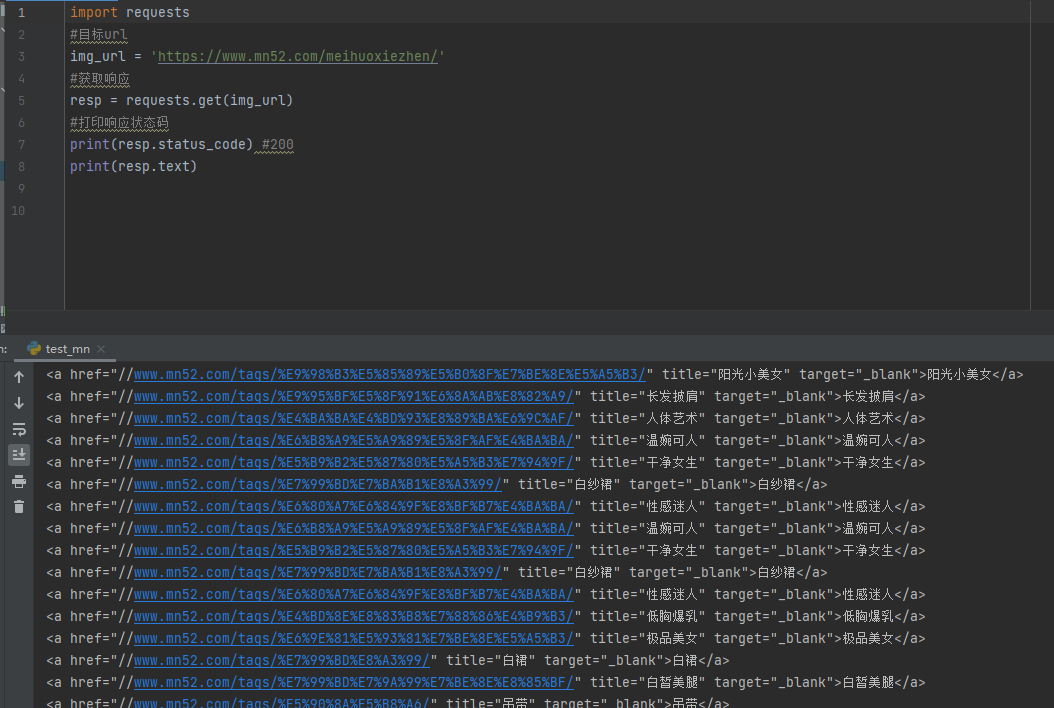
接下来我们在获取到的文档之中搜索我们想要的图片信息。
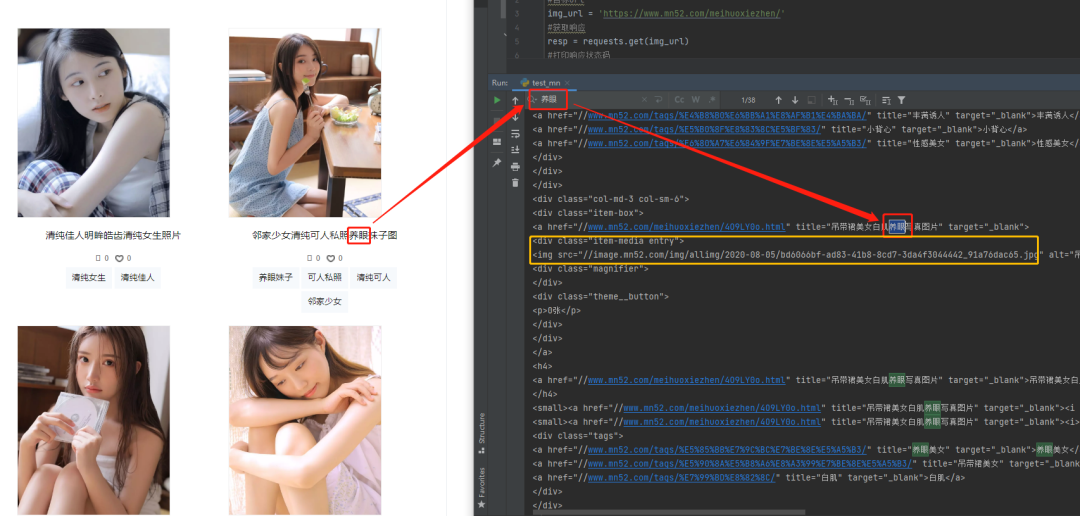
可以看到,每个图片的url都在
class="item-media entry"里面。
所以这里我们首先需要正则提取出所有图片的url。
class="item-media entry".*?src="(.*?)"代码如下:
import requests
import re
#目标url
img_url = 'https://www.mn52.com/meihuoxiezhen/'
#获取响应
resp = requests.get(img_url)
#打印响应状态码
#print(resp.status_code) #200
#跨行匹配所有字符
pattern = re.compile('class="item-media entry".*?src="(.*?)"', re.S)
#打印图片url
result = re.findall(pattern, resp.text)
print(result)
成功提取到所有图片的url。

接下来就可以下载所有图片了。
for img_url in result:#拼接urlresp = requests.get('http:' + img_url)with open('img\%d.jpg'%num, 'wb') as fin:fin.write(resp.content)print('正在下载第%d图片:'%num + 'http:' + img_url)num += 1
结果展示如下:
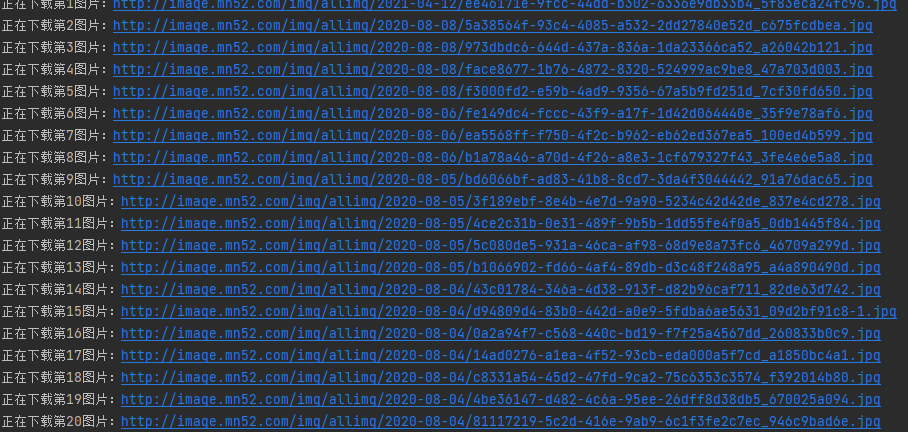
至此,代码已经成功下载至本地。代码提升和优化的空间还很大。我只是实现了基本的功能。
我在这里只是用13行代码实现了一页28张图片的爬取演示,大家可以尝试一下爬取全部92页2520张图片哈。

其实我已经写出了爬取全部2520张图片的代码,只不过没有在此演示。留给你操作空间。

若有需要。私我内回复’mn源码‘,我把源码和2520图都给你。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!