目标检测(凑字数,凑字数,为什么标题一定要五个字)
写在最前:
昨天七夕,一个人躲在家里打游戏,不敢出门,怕被喂狗粮。
一个即将步入中年的老男人,弱小,无助,单身,肥胖,贫穷。但是怀揣着一丢丢情怀和梦想,妄图吃上天鹅肉,在奋斗与躺平之间挣扎着,最终,变成了间接性摆烂。
我是一条咸鱼,但是!我也要翻身,做个咸鱼之王(打钱!!!)话说煎的黄鱼是真的好吃,今晚奖励自己,搞一顿。
咳咳,跑题了,许个愿吧,愿你未来可期。
进入正题
又到了大家喜闻乐见的举栗子环节!!!

如图,这车真白,这车真的很白,凯迪拉克LYRIQ,这里就不贴参数了,帅就完事儿了!!!(方向盘跑偏的事儿,另说)
这篇文章主题是啥,目标检测
你们第一眼看到的是啥,我猜肯定是车,毕竟那么大(手动滑稽)

看框框,目标我就不赘述了,DDDD
什么是目标检测
• 物体识别是要分辨出图片中有什么物体,输入是图片,输出是类别标签和概率。物体检测算法不仅要检测图片中有什么物体,还要输出物体的外框( x, y, width, height)来定位物体的位置。 • object detection,也可以叫location(房地产最重要的是location location 还是TMD location) 就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。 • object detection,要解决的问题就是物体在哪里以及是什么的整个流程问题。 • 然而,这个问题可不是那么容易解决的,物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,更何况物体还可以是多个类别。 那怎么办捏?! 目前学术和工业界出现的目标检测算法分成3类: 1. 传统的目标检测算法:Cascade + HOG/DPM + Haar/SVM以及上述方法的诸多改进、优化; 2. 候选区域/框 + 深度学习分类:通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,如: • R-CNN(Selective Search + CNN + SVM) • SPP-net(ROI Pooling) • Fast R-CNN(Selective Search + CNN + ROI) • Faster R-CNN(RPN + CNN + ROI) 3. 基于深度学习的回归方法:YOLO/SSD 等方法 上面三种思想看看就行了,具体什么情况,我也不知道,也不敢乱说,那帮人,不熟
IOU(哎~欧呦~)
Intersection over Union 是一种测量在特定数据集中检测相应物体准确度的一个标准。 IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。 为了可以使IoU用于测量任意大小形状的物体检测,我们需要: 1、Ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围); 2、我们的算法得出的结果范围。 也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。再举一个栗子:

绿色是Ground-truth bounding boxes
红色是bounding boxex
IOU怎么算的呢:
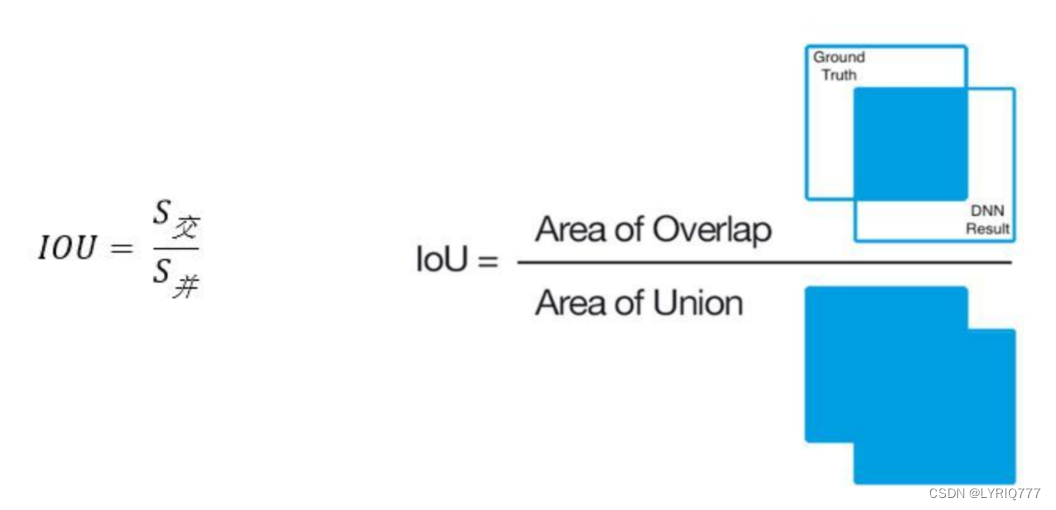
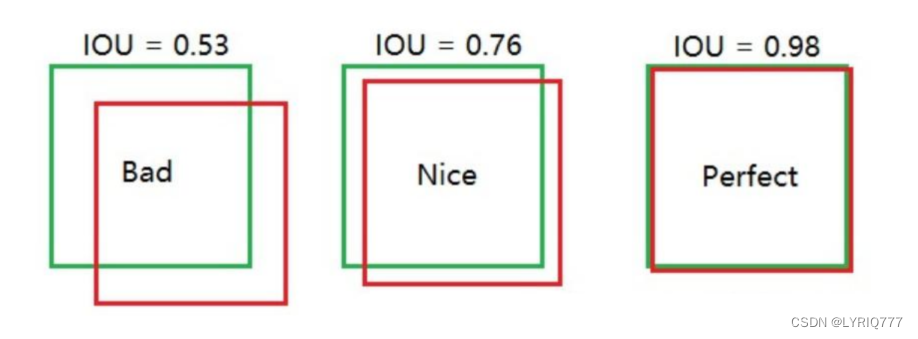
说明一下啊,这个评判标准不是死的啊,可以自己定,如果我设定标准是0.5,那么所有的都合格,如果是0.99,那么所有的都不合格,哎,好难,爱情也是(emo time)
TP TN FP FN
TP TN FP FN里面一共出现了4个字母,分别是T F P N。 T是True; F是False; P是Positive; N是Negative。 T或者F代表的是该样本 是否被正确分类。 P或者N代表的是该样本 原本是正样本还是负样本。
还是这张图,你把红框分类成车就是正样本,把绿框分类成车就是......emm,就是负样本,对负样本
TP(True Positives)意思就是被分为了正样本,而且分对了。 TN(True Negatives)意思就是被分为了负样本,而且分对了, FP(False Positives)意思就是被分为了正样本,但是分错了(事实上这个样本是负样本)。 FN(False Negatives)意思就是被分为了负样本,但是分错了(事实上这个样本是正样本)。 在mAP计算的过程中主要用到了,TP、FP、FN这三个概念。precision(精确度)和recall(召回率)
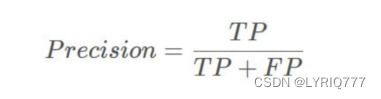
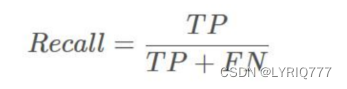

看!灰机!
打下来(手动狗头)
• 蓝色的框是真实框。绿色和红色的框是预测框,绿色的框是正样本,红色的框是负样本。 • 一般来讲,当预测框和真实框IOU>=0.5时,被认为是正样本。(注意:是一般来讲,你设置0.7也行)
边框回归Bounding-Box regression

红色的是BB,绿色是GT
可以看出绿色把飞机整体框出来了,但是红色就没有,鸡翅漏掉了,鸡翅呢?我吃掉了.
边框回归是什么? • 对于窗口一般使用四维向量(x,y,w,h) 来表示, 分别表示窗口的中心点坐标和宽高。 • 红色的框 P 代表原始的Proposal,; • 绿色的框 G 代表目标的 Ground Truth; 目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口G^。 所以,边框回归的目的即是: 给定(Px,Py,Pw,Ph)寻找一种映射f, 使得:f(Px,Py,Pw,Ph)=(Gx^ ,Gy^ ,Gw^ ,Gh^)并且 (Gx^ ,Gy^ ,Gw^ ,Gh^)≈(Gx,Gy,Gw,Gh) 中间的点是各个框的中心点,就是传说中的准心
怎么做?
比较简单的思路就是: 平移+尺度缩放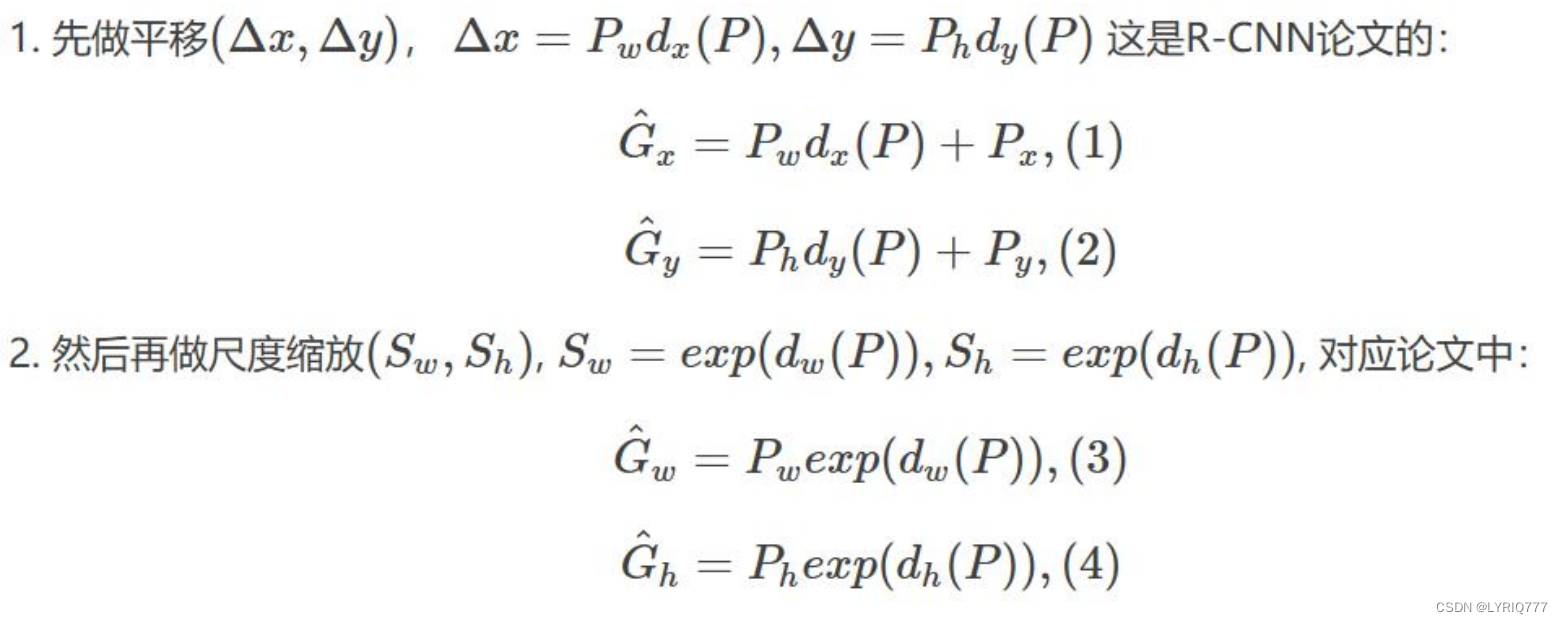
Two stage
候选区域/框 + 深度学习分类:通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,如: • R-CNN(Selective Search + CNN + SVM) • SPP-net(ROI Pooling) • Fast R-CNN(Selective Search + CNN + ROI) • Faster R-CNN(RPN + CNN + ROI)Selective Search
Selective Search 通过颜色、纹理、大小等特征的相似度把图像分成许多个不同的区域。目标检测算法可以从这些区域中检测对象,加快检测速度。

是不是感觉似曾相识?
图像聚类算法_LYRIQ777的博客-CSDN博客
是不是有点像啊
上菜!!!Faster-RCNN
Faster RCNN可以分为4个主要内容: 1. Conv layers: 作为一种CNN网络目标检测方法,FasterRCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。 2. Region Proposal Networks(RPN): RPN网络用于生成region proposals。通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。 3. Roi Pooling: 该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。 4. Classification: 利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。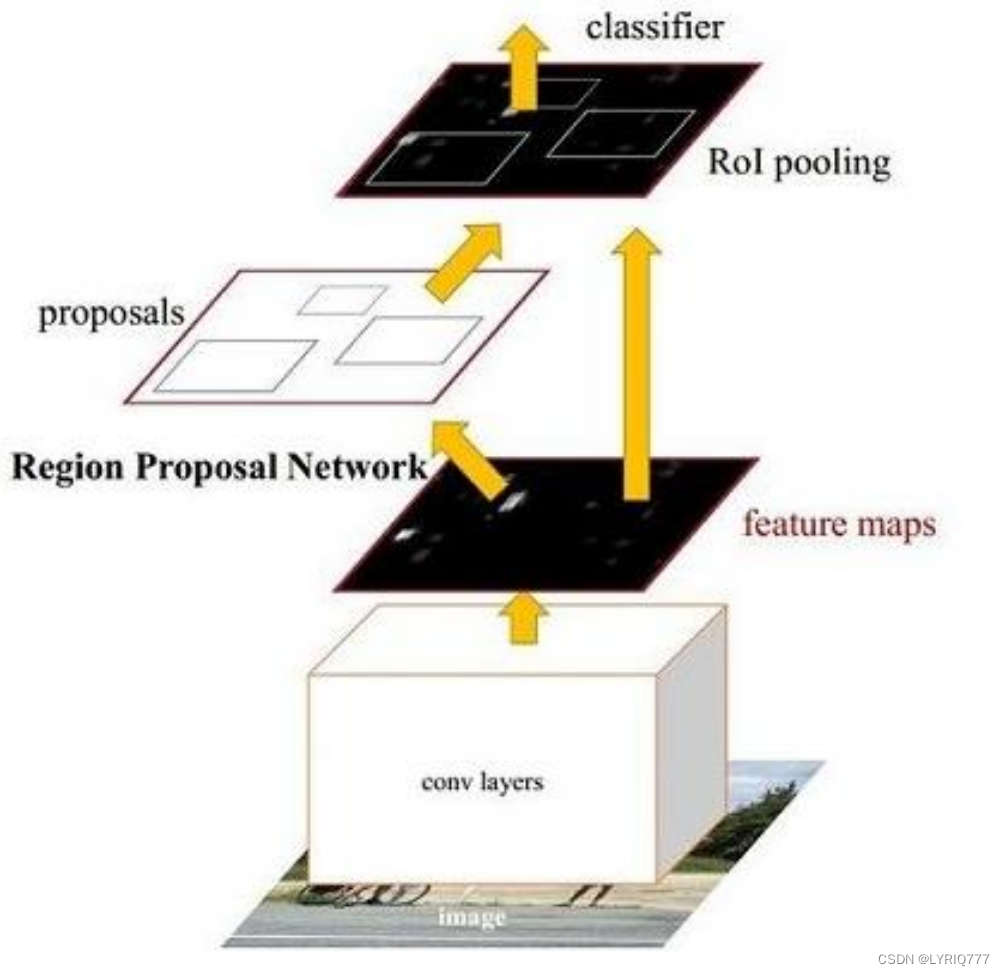
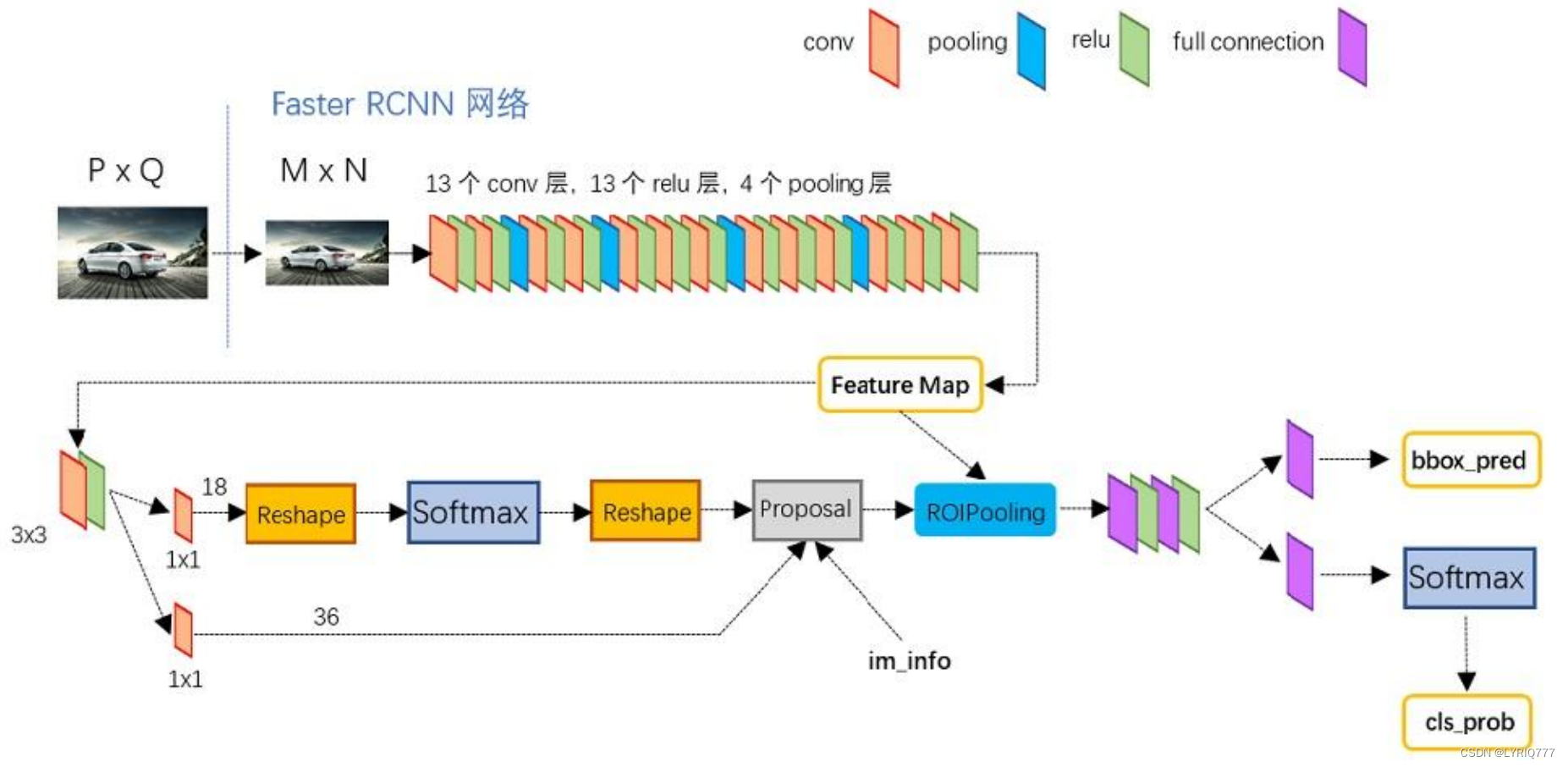
1:Conv layers
Conv layers包含了conv,pooling,relu三种层。共有13个conv层,13个relu层,4个pooling层。在Conv layers中: 1. 所有的conv层都是:kernel_size=3,pad=1,stride=1 2. 所有的pooling层都是:kernel_size=2,pad=1,stride=2 在Faster RCNN Conv layers中对所有的卷积都做了pad处理( pad=1,即填充一圈0),导致原图变为 (M+2)x(N+2)大小,再做3x3卷积后输出MxN 。正是这种设置,导致Conv layers中的conv层不改变输入和输出矩阵大小。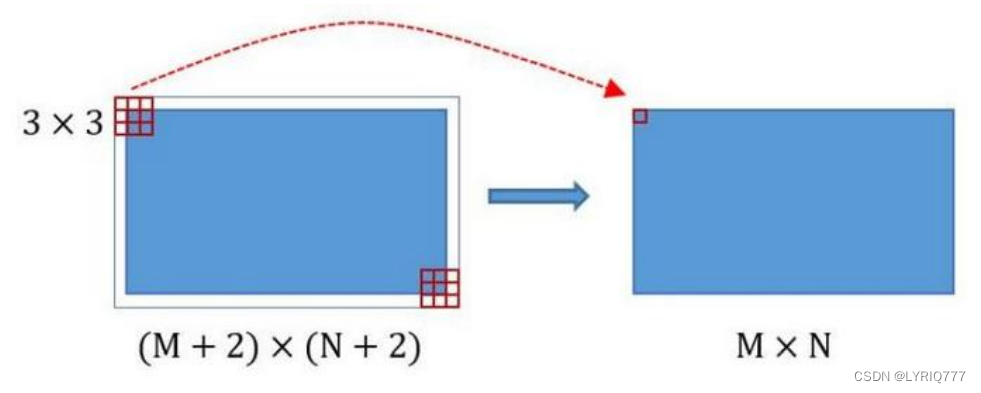
2:区域生成网络Region Proposal Networks(RPN)
经典的检测方法生成检测框都非常耗时。直接使用RPN生成检测框,是Faster R-CNN的巨 大优势,能极大提升检测框的生成速度。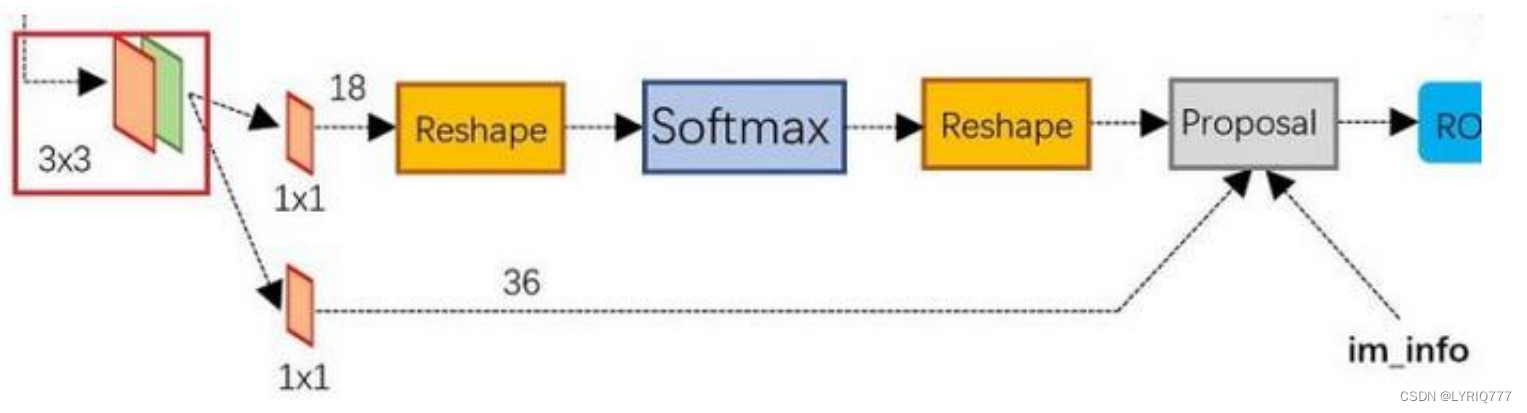
anchors
RPN网络在卷积后,对每个像素点,上采样映射到原始图像一个区域,找到这个区域的中心位置,然后基于这个中心位置按规则选取9种anchor box(就是9个不同尺寸的框框)。 9个矩形共有3种面积:128,256,512; 3种形状:长宽比大约为1:1, 1:2, 2:1。 (不是固定比例,可调)每行的4个值表示矩形左上和右下角点坐标。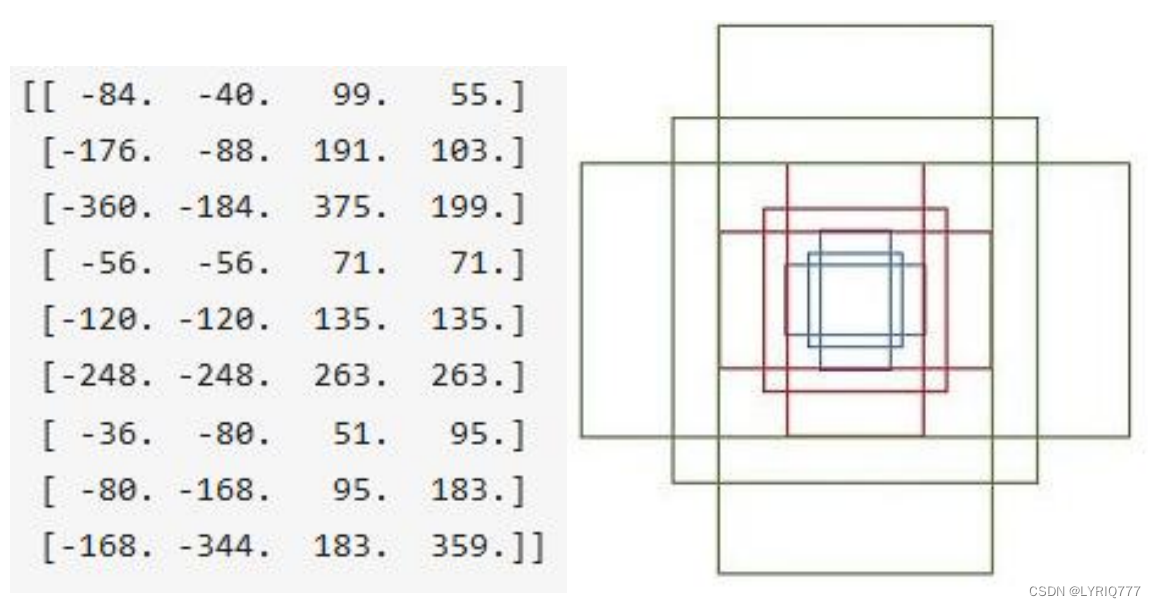
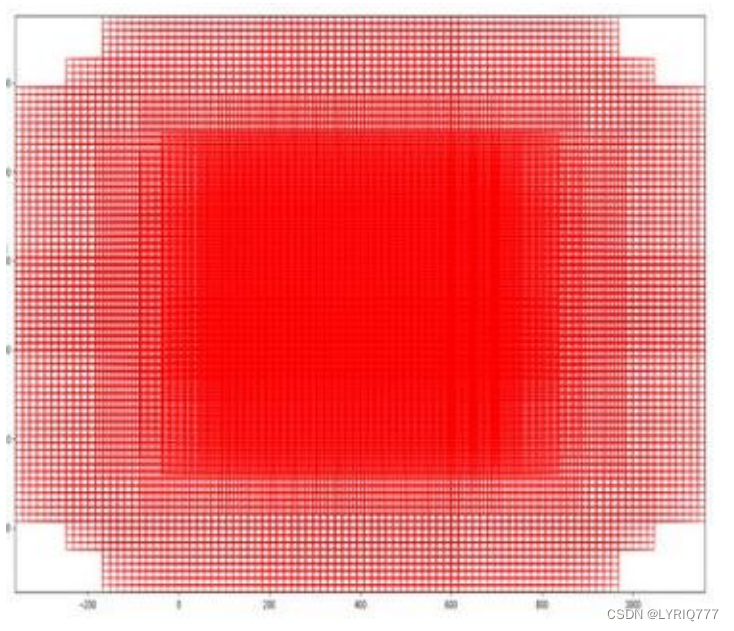
softmax判定positive与negative
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,仅仅是个二分类而已。
对proposals进行bounding box regression

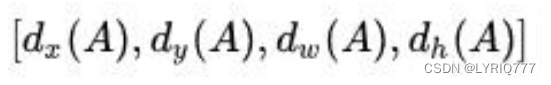
3:Proposal Layer
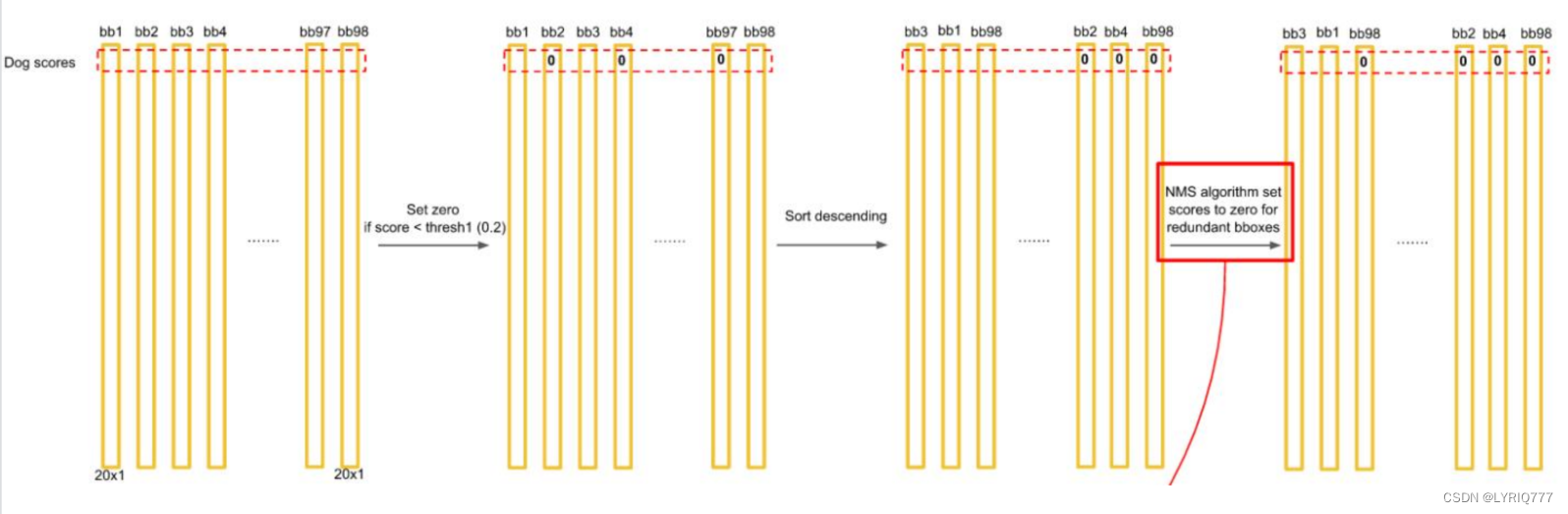
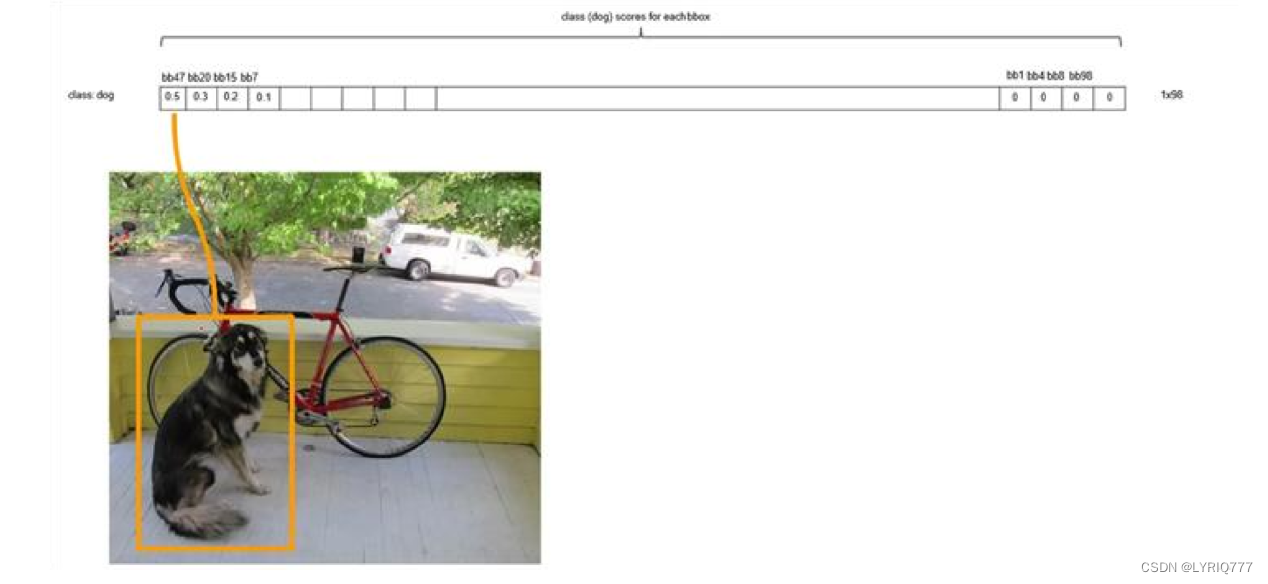
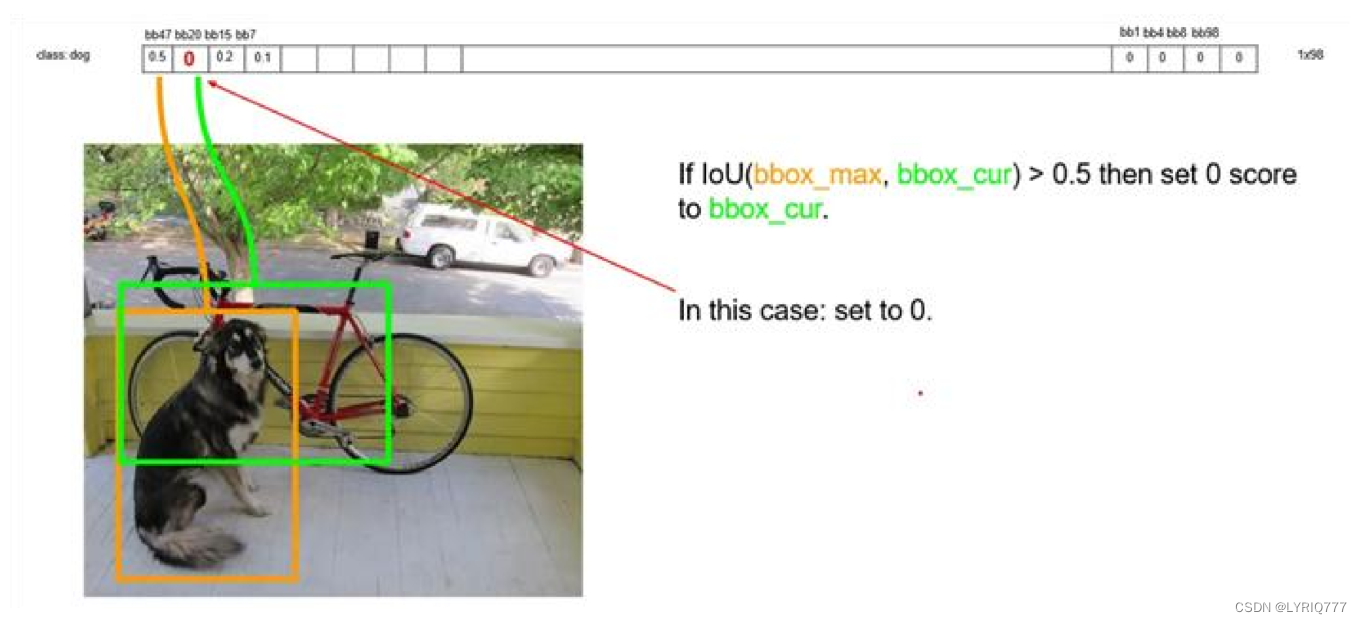
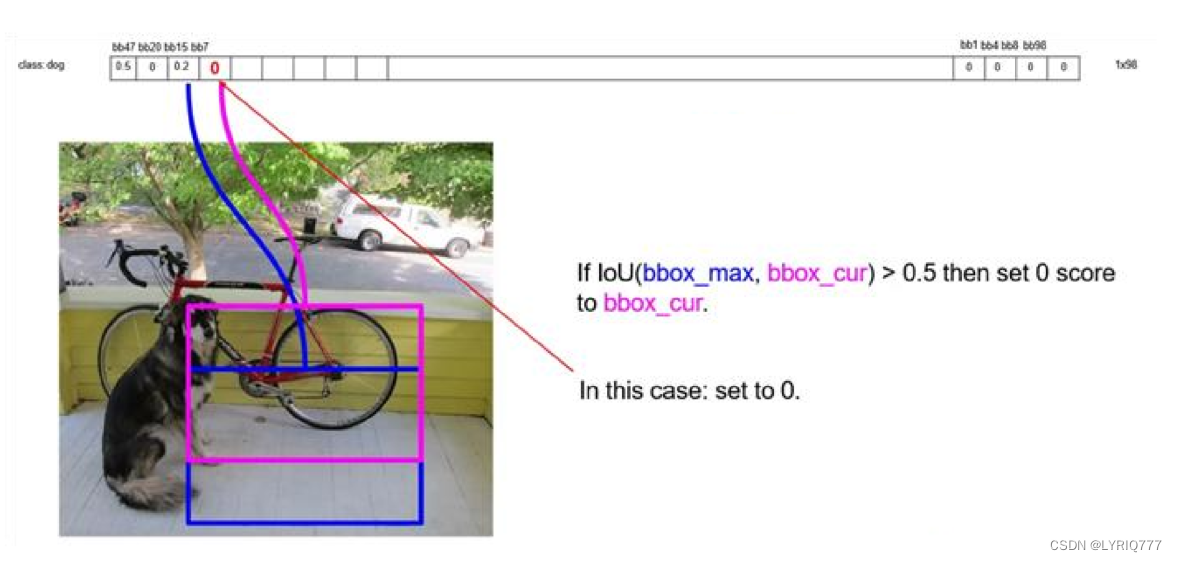
Proposal Layer负责综合所有变换量和positive anchors,计算出精准的proposal,送入后续RoI Pooling Layer。 Proposal Layer有4个输入: 1. positive vs negative anchors分类器结果rpn_cls_prob_reshape, 2. 对应的bbox reg的变换量rpn_bbox_pred, 3. im_info 4. 参数feature_stride=16 im_info:对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[M, N,scale_factor]则保存了此次缩放的所有信息。 输入图像经过Conv Layers,经过4次pooling变为WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。 Proposal Layer 按照以下顺序依次处理: 1. 利用变换量对所有的positive anchors做bbox regression回归 2. 按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors。 3. 对剩余的positive anchors进行NMS(non-maximum suppression)。 4. 之后输出proposal。 严格意义上的检测应该到此就结束了,后续部分应该属于识别了。 RPN网络结构,总结起来: 生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals4:Roi pooling
RoI Pooling层则负责收集proposal,并计算出proposal feature maps,送入后续网络。 Rol pooling层有2个输入: 1. 原始的feature maps 2. RPN输出的proposal boxes (大小各不相同) 为何需要RoI Pooling? 对于传统的CNN(如AlexNet和VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的vector or matrix。如果输入图像大小不定,这个问题就变得比较麻烦。 有2种解决办法: 1. 从图像中crop一部分传入网络将图像(破坏了图像的完整结构) 2. warp成需要的大小后传入网络(破坏了图像原始形状信息)
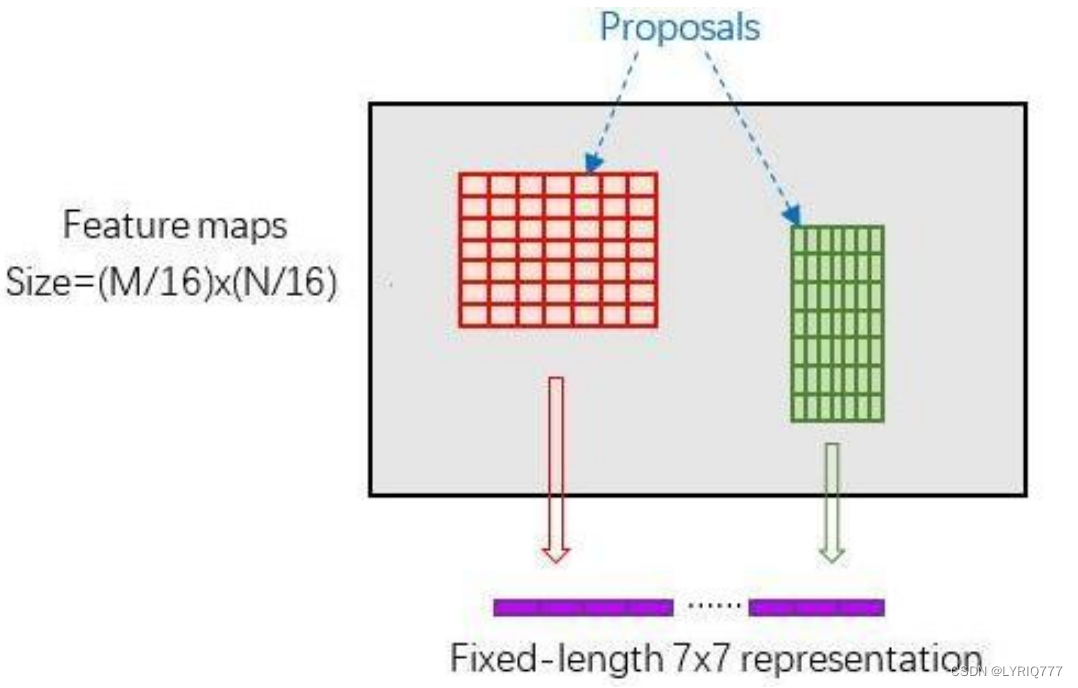
5:Classification
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量; 同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。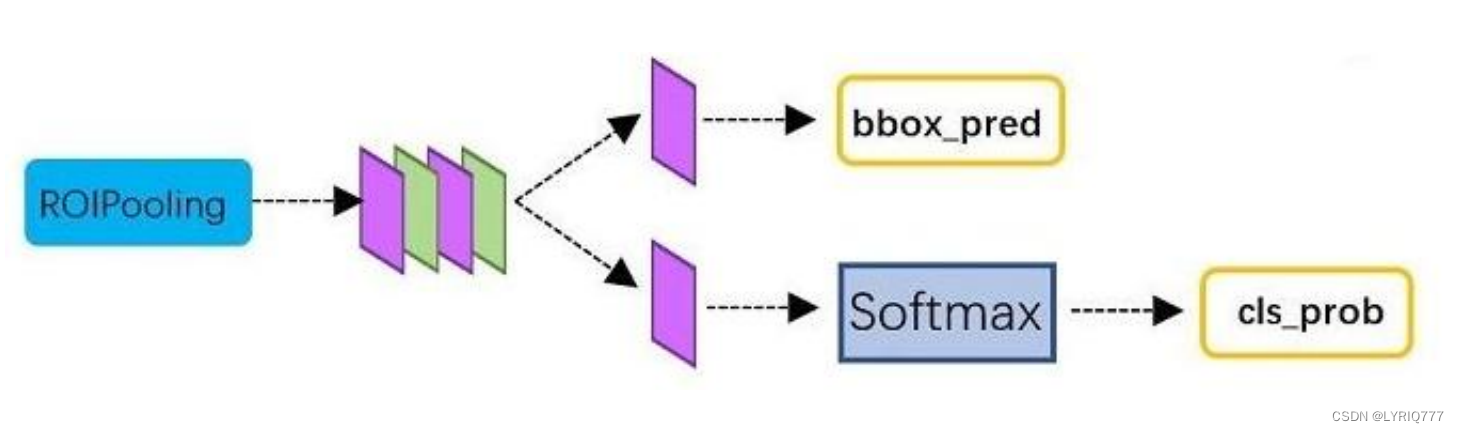
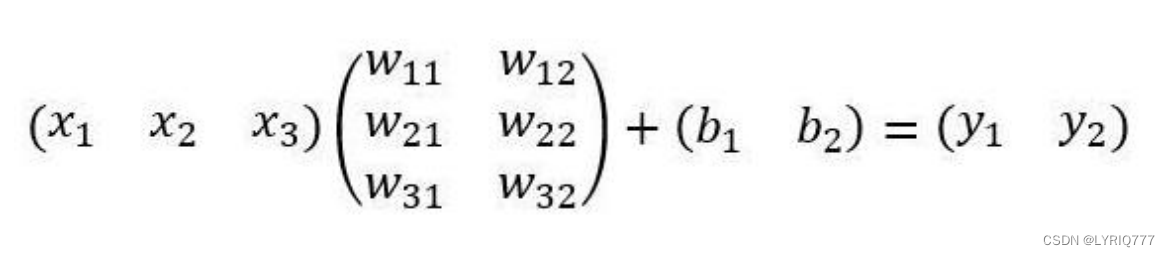
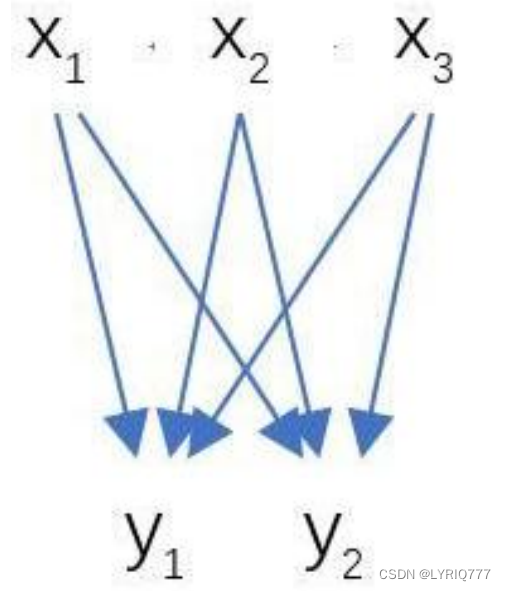
One stage(一步)
一步是我起的名字,作为一个有情怀的人很容易让我想起one step

这个图标是不是特别好看,没听过?锤子!(不是骂人哈,这是一个曾经辉煌,但是消失了的手机品牌)。

锤子死后,地球上就没有什么好用的手机了,小米很平庸,毫无亮点,小米的设计就没有设计(就是丑),小米最好看的手机是mix1代,小米就像红旗(车的品牌)一样。自行体会。
扯远了,回头有机会,专门出一期。
two stage和one stage
two-stage: two-stage算法会先使用一个网络生成proposal,如selective search和RPN网络, RPN出现后,ss方法基本就被摒弃了。RPN网络接在图像特征提取网络backbone后,会设置RPN loss(bbox regression loss+classification loss)对RPN网络进行训练,RPN生成的proposal再送到后面的网络中进行更精细的bbox regression和classification。 one-stage : One-stage追求速度舍弃了two-stage架构,即不再设置单独网络生成proposal,而 是直接在feature map上进行密集抽样,产生大量的先验框,如YOLO的网格方法。这些先验框没 有经过两步处理,且框的尺寸往往是人为规定。 two-stage 算法主要是RCNN系列,包括 RCNN , Fast - RCNN , Faster - RCNN 。之后的 Mask-RCNN融合了Faster-RCNN架构、ResNet和FPN(Feature Pyramid Networks)backbone,以及FCN里的segmentation方法,在完成了segmentation的同时也提高了detection的精度。 one-stage 算法最典型的是 YOLO, 该算法速度极快。YOLO(You Only Look Once)
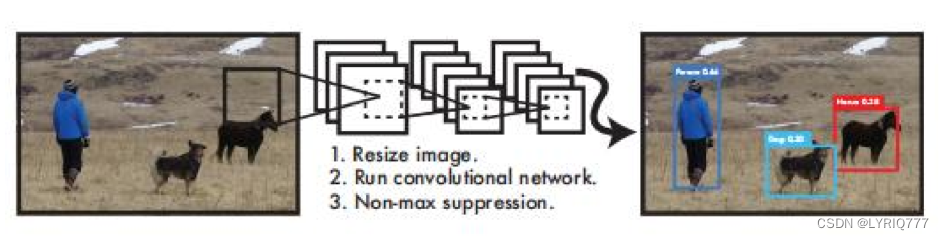
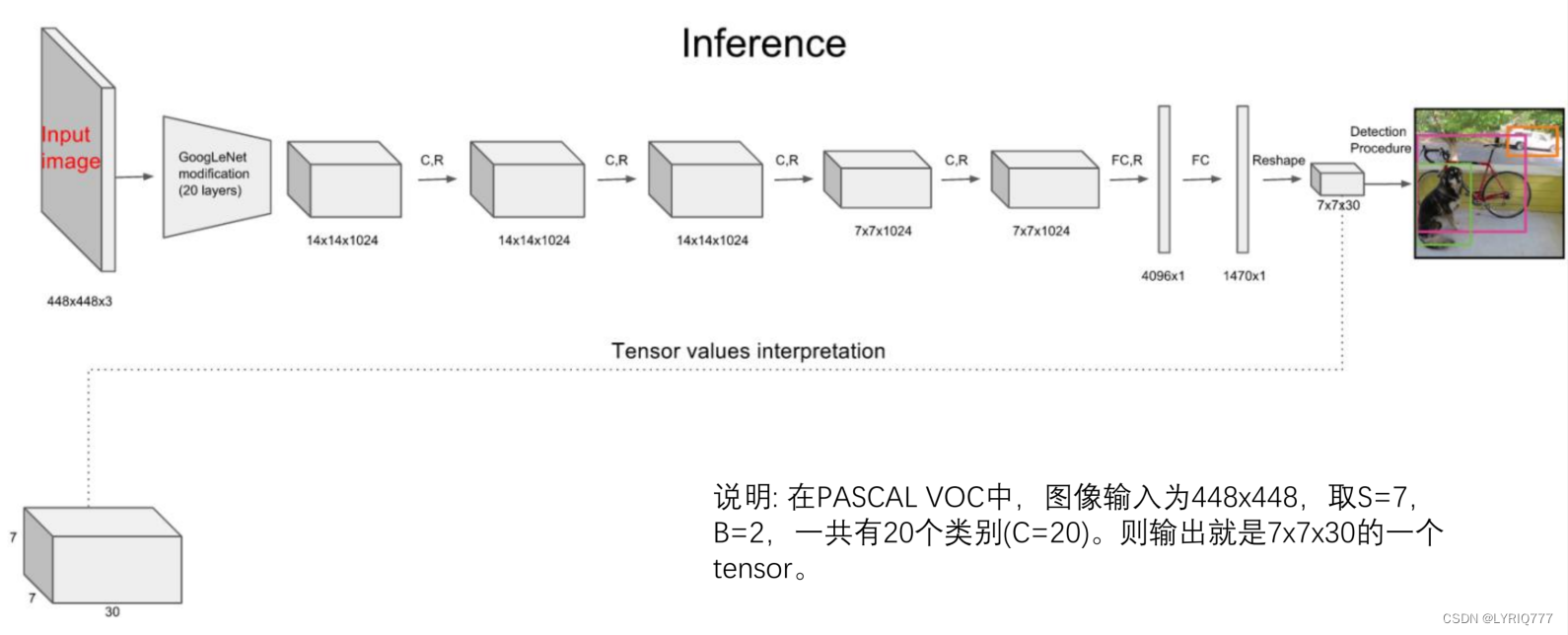
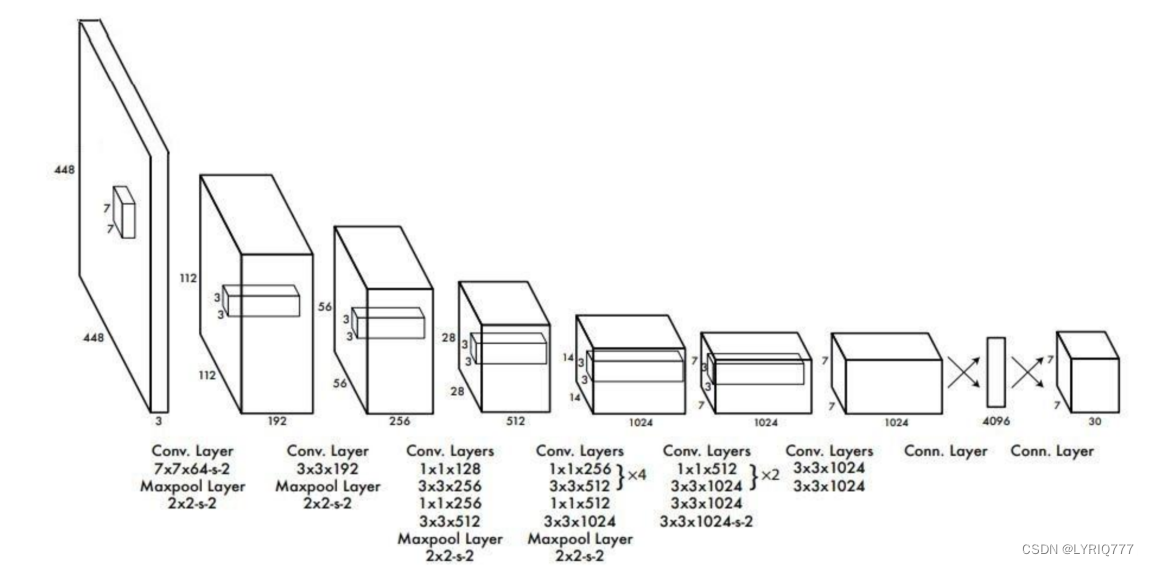
以YOLO3举例子:

图中,不同的颜色框代表的是识别出来的不同事物的类型,上方的数字代表几率,比如左图中的银色五菱宏光,机器识别是车的概率是0.72。
那人,那山 ,那狗,有些(大部分)领导是真的狗啊,做个人吧,求求你们了。





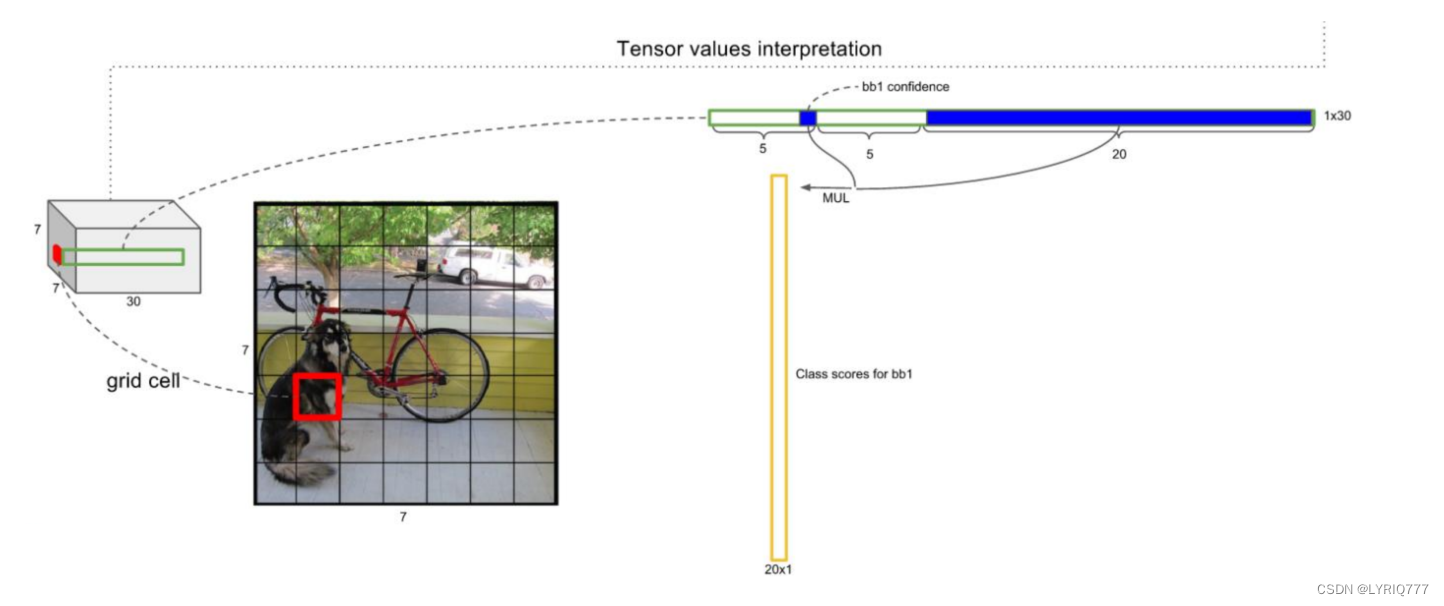
这个Feature Map包含了哪些信息呢
绿色:表示框的信息,tx,ty中心点坐标,tw宽,th高,
淡蓝色: 置信度得分
粉色:识别出来的类别的得分,或者说是几率,从大到小排
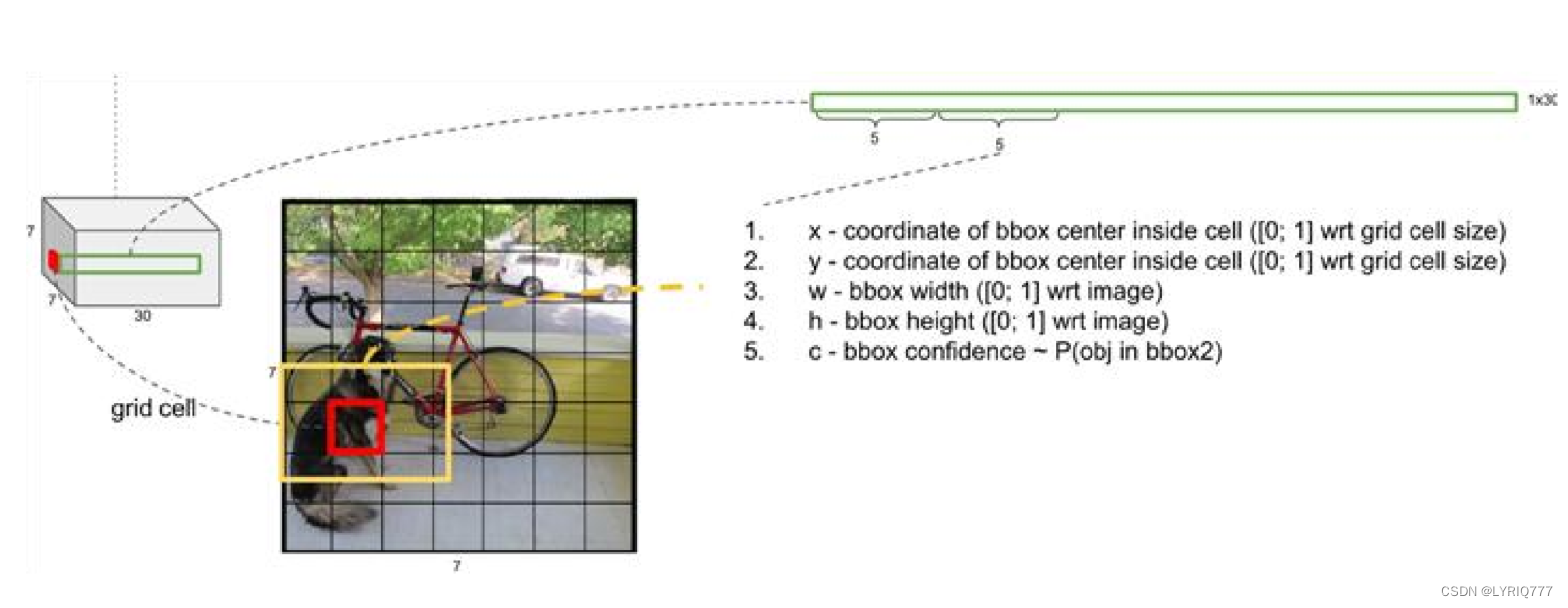
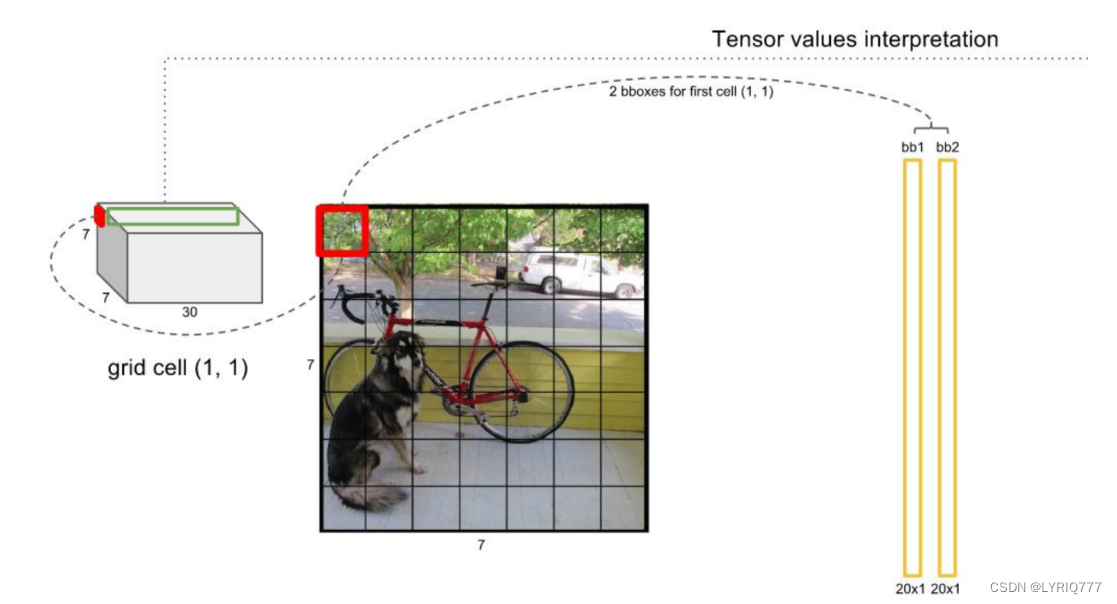
来~look一下介个图,红色的就是一个feature map,看最左边结合上虚线到右边看,是不是就理解了
一般情况下,YOLO 不会预测边界框中心的确切坐标。它预测: • 与预测目标的网格单元左上角相关的偏移; • 使用特征图单元的维度进行归一化的偏移。 例如: 以上图为例,如果中心的预测是 (0.4, 0.7),则中心在 13 x 13 特征图上的坐标是 (6.4, 6.7)(红色单元的左上角坐标是 (6,6))。 但是,如果预测到的 x,y 坐标大于 1,比如 (1.2, 0.7)。那么预测的中心坐标是 (7.2, 6.7)。注意该中心在红色单元右侧的单元中。这打破了 YOLO 背后的理论,因为如果我们假设红色框负责预测目标狗,那么狗的中心必须在红色单元中,不应该在它旁边的网格单元中。 因此,为了解决这个问题,我们对输出执行 sigmoid 函数,将输出压缩到区间 0 到 1 之间,有效确保中心处于执行预测的网格单元中。 每个标定框的置信度以及标定框的准确度信息: 左边代表包含这个标定框的格子里是否有目标。有=1没有=0。 右边代表标定框的准确程度, 右边的部分是把两个标定框(一个是Ground truth,一个是预测的标定框)进行一个IOU操作,即两个标定框的交集比并集,数值越大,即标定框重合越多,越准 确。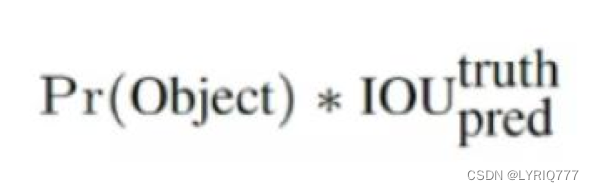
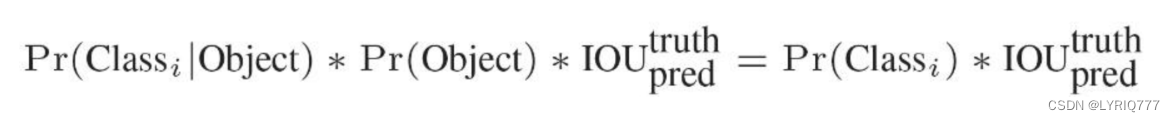

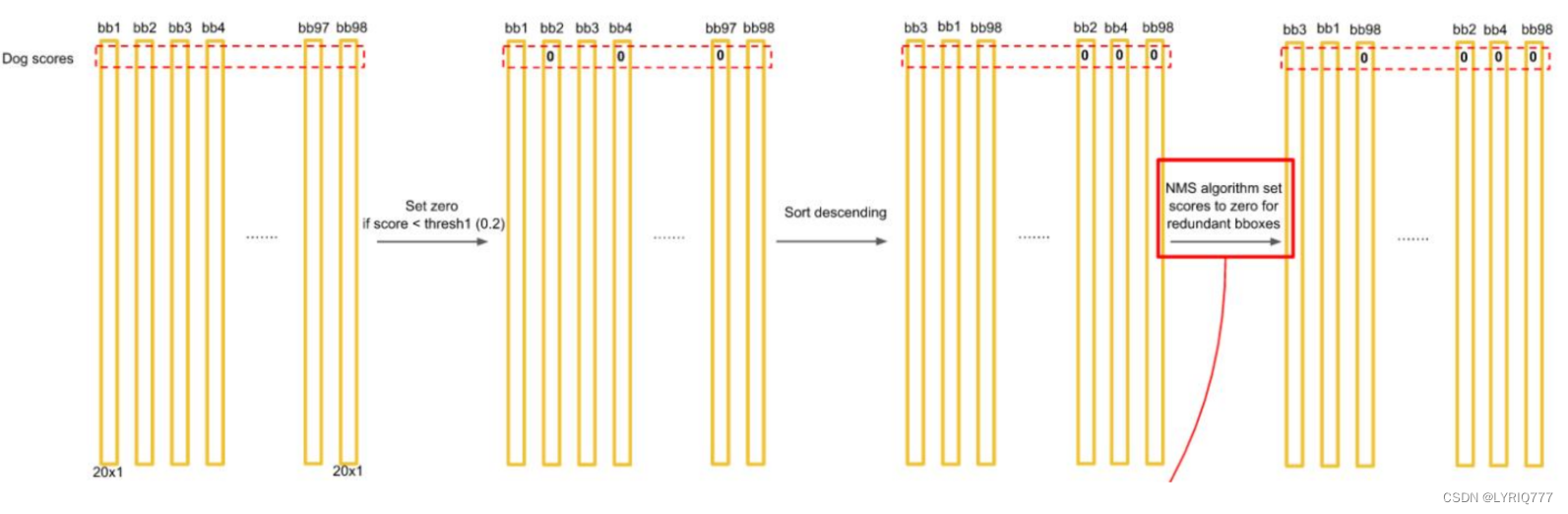
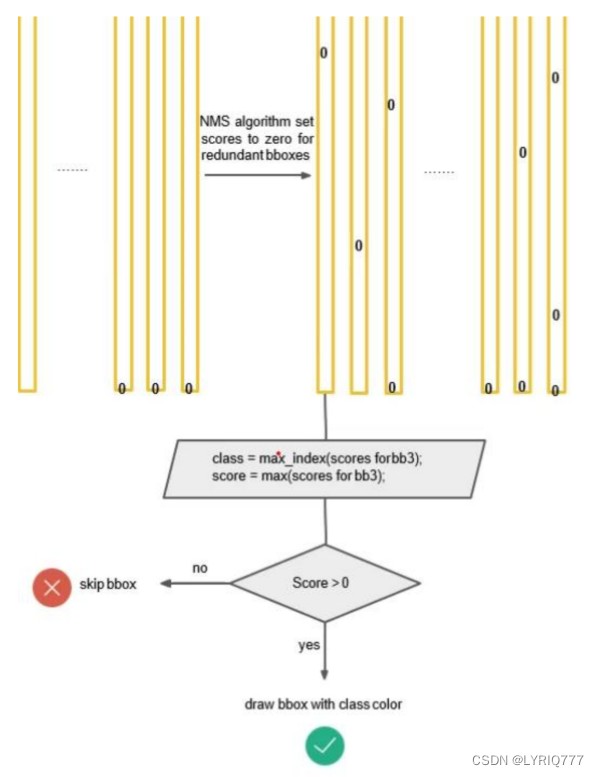
Yolo的缺点:
• YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。 • 测试图像中,当同一类物体出现不常见的长宽比和其他情况时泛化能力偏弱。放个YOLO对比:
目标检测:yolov1、yolov2、yolov3的对比理解 - 第一PHP社区
拓展-SSD
不是固态硬盘!!!长江存储yyds!!!

总结一下
累,好累,这篇文章稀稀拉拉写了一周吧,这周感觉格外疲惫,完全不想写,只想着好好休息一下,甚至想离职了。
如果哪天我TM中了500万,直接撂挑子!QTMD的爱谁谁,同志们,千万别学我,这个思想很不好。
想要暴富,一定不要想,立马去买彩票!!!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!