【20】Flink 实战案例开发(二):数据报表
1、应用场景分析
- 数据清洗【实时ETL】
- 数据报表
1.1、数据报表
1.1.1、架构图
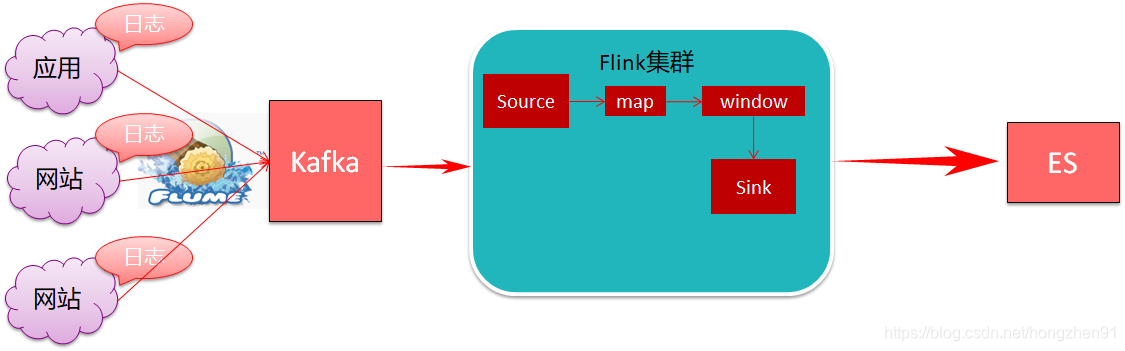
1.1.2、需求分析
主要针对直播/短视频平台审核指标的统计
- 统计不同大区每1 min内过审(上架)的数据量
- 统计不同大区每1 min内未过审(下架)的数据量
- 统计不同大区每1 min内加黑名单的数据量
2、DataClean代码开发
开发介绍采用的是 Java 代码实现的,完整工程代码及 Scala 代码的实现详见底部 GitHub 代码地址
2.1、MyAggFunction实现
功能: 聚合数据代码
package henry.flink.function;import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Date;
import java.util.Iterator;/*** @Author: Henry* @Description: 聚合数据代码**/
public class MyAggFunction implements WindowFunction<Tuple3<Long, String, String>, Tuple4<String, String, String, Long>, Tuple, TimeWindow>{@Overridepublic void apply(Tuple tuple,TimeWindow window,Iterable<Tuple3<Long, String, String>> input,Collector<Tuple4<String, String, String, Long>> out)throws Exception {//获取分组字段信息String type = tuple.getField(0).toString();String area = tuple.getField(1).toString();Iterator<Tuple3<Long, String, String>> it = input.iterator();//存储时间,为了获取最后一条数据的时间ArrayList<Long> arrayList = new ArrayList<>();long count = 0;while (it.hasNext()) {Tuple3<Long, String, String> next = it.next();arrayList.add(next.f0);count++;}System.err.println(Thread.currentThread().getId()+",window触发了,数据条数:"+count);//排序,默认正排Collections.sort(arrayList);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String time = sdf.format(new Date(arrayList.get(arrayList.size() - 1)));//组装结果Tuple4<String, String, String, Long> res = new Tuple4<>(time, type, area, count);out.collect(res);}
}
2.2、DataReport实现
主要代码:
/*** @Author: Henry* @Description: 数据报表***/
public class DataReport {private static Logger logger = LoggerFactory.getLogger(DataReport.class);public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度env.setParallelism(5);// 设置使用eventtimeenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// checkpoint配置...// 配置 kafkaSourceString topic = "auditLog"; // 审核日志Properties prop = new Properties();prop.setProperty("bootstrap.servers", "master:9092");prop.setProperty("group.id", "con1");FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<String>(topic, new SimpleStringSchema(),prop);/** 获取到kafka的数据* {"dt":"审核时间{年月日 时分秒}", "type":"审核类型","username":"审核人姓名","area":"大区"}* */DataStreamSource<String> data = env.addSource(myConsumer);// 对数据进行清洗DataStream<Tuple3<Long, String, String>> mapData = data.map(new MapFunction<String, Tuple3<Long, String, String>>() {@Overridepublic Tuple3<Long, String, String> map(String line) throws Exception {JSONObject jsonObject = JSON.parseObject(line);String dt = jsonObject.getString("dt");long time = 0;try {SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");Date parse = sdf.parse(dt);time = parse.getTime();} catch (ParseException e) {//也可以把这个日志存储到其他介质中logger.error("时间解析异常,dt:" + dt, e.getCause());}String type = jsonObject.getString("type");String area = jsonObject.getString("area");return new Tuple3<>(time, type, area);}});// 过滤掉异常数据DataStream<Tuple3<Long, String, String>> filterData = mapData.filter(new FilterFunction<Tuple3<Long, String, String>>() {@Overridepublic boolean filter(Tuple3<Long, String, String> value) throws Exception {boolean flag = true;if (value.f0 == 0) { // 即 time 字段为0flag = false;}return flag;}});// 保存迟到太久的数据OutputTag<Tuple3<Long, String, String>> outputTag = new OutputTag<Tuple3<Long, String, String>>("late-data"){};/** 窗口统计操作* */SingleOutputStreamOperator<Tuple4<String, String, String, Long>> resultData = filterData.assignTimestampsAndWatermarks(new MyWatermark()).keyBy(1, 2) // 根据第1、2个字段,即type、area分组,第0个字段是timestamp.window(TumblingEventTimeWindows.of(Time.minutes(30))) // 每隔一分钟统计前一分钟的数据.allowedLateness(Time.seconds(30)) // 允许迟到30s.sideOutputLateData(outputTag) // 记录迟到太久的数据.apply(new MyAggFunction());// 获取迟到太久的数据DataStream<Tuple3<Long, String, String>> sideOutput = resultData.getSideOutput(outputTag);// 存储迟到太久的数据到kafka中String outTopic = "lateLog";Properties outprop = new Properties();outprop.setProperty("bootstrap.servers", "master:9092");// 设置事务超时时间outprop.setProperty("transaction.timeout.ms", 60000*15+"");FlinkKafkaProducer011<String> myProducer = new FlinkKafkaProducer011<String>(outTopic,new KeyedSerializationSchemaWrapper<String>(new SimpleStringSchema()),outprop,FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);// 迟到太久的数据存储到 kafka 中sideOutput.map(new MapFunction<Tuple3<Long, String, String>, String>() {@Overridepublic String map(Tuple3<Long, String, String> value) throws Exception {return value.f0+"\t"+value.f1+"\t"+value.f2;}}).addSink(myProducer);/** 把计算的结存储到 ES 中* */List<HttpHost> httpHosts = new ArrayList<>();httpHosts.add(new HttpHost("master", 9200, "http"));ElasticsearchSink.Builder<Tuple4<String, String, String, Long>> esSinkBuilder = new ElasticsearchSink.Builder<Tuple4<String, String, String, Long>>(httpHosts,new ElasticsearchSinkFunction<Tuple4<String, String, String, Long>>() {public IndexRequest createIndexRequest(Tuple4<String, String, String, Long> element) {Map<String, Object> json = new HashMap<>();json.put("time",element.f0);json.put("type",element.f1);json.put("area",element.f2);json.put("count",element.f3);//使用time+type+area 保证id唯一String id = element.f0.replace(" ","_")+"-"+element.f1+"-"+element.f2;return Requests.indexRequest().index("auditindex").type("audittype").id(id).source(json);}@Overridepublic void process(Tuple4<String, String, String, Long> element,RuntimeContext ctx, RequestIndexer indexer) {indexer.add(createIndexRequest(element));}});// ES是有缓冲区的,这里设置1代表,每增加一条数据直接就刷新到ESesSinkBuilder.setBulkFlushMaxActions(1);resultData.addSink(esSinkBuilder.build());env.execute("DataReport");}
}
3、实践运行
3.1、启动 kafka 生产者
kafka 生产者消息数据:

创建 kafka topic:
./kafka-topics.sh --create --topic lateLog --zookeeper localhost:2181 --partitions 5 --replication-factor 1
./kafka-topics.sh --create --topic auditLog --zookeeper localhost:2181 --partitions 5 --replication-factor 1

3.2、启动 ES 和 kibana
1. 启动:
# 后台启动 ES
./bin/elasticsearch -d# 后台启动 kibana
nohup ./bin/kibana >/dev/null 2>&1 &
2. 启动 UI 访问:
3. 创建索引:
创建索引脚本代码:
# 注意,如果索引建的有问题,则先删除再重新创建索引
curl -XDELETE 'localhost:9200/auditindex'# 创建索引
curl -XPUT 'http://master:9200/auditindex?pretty'# 创建type的mapping信息
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/auditindex/audittype/_mapping?pretty' -d '
{
"audittype":{"properties":{"area":{"type":"keyword"},"type":{"type":"keyword"},"count":{"type":"long"},"time":{"type":"date","format": "yyyy-MM-dd HH:mm:ss"}}}
}
'
# 执行创建索引脚本
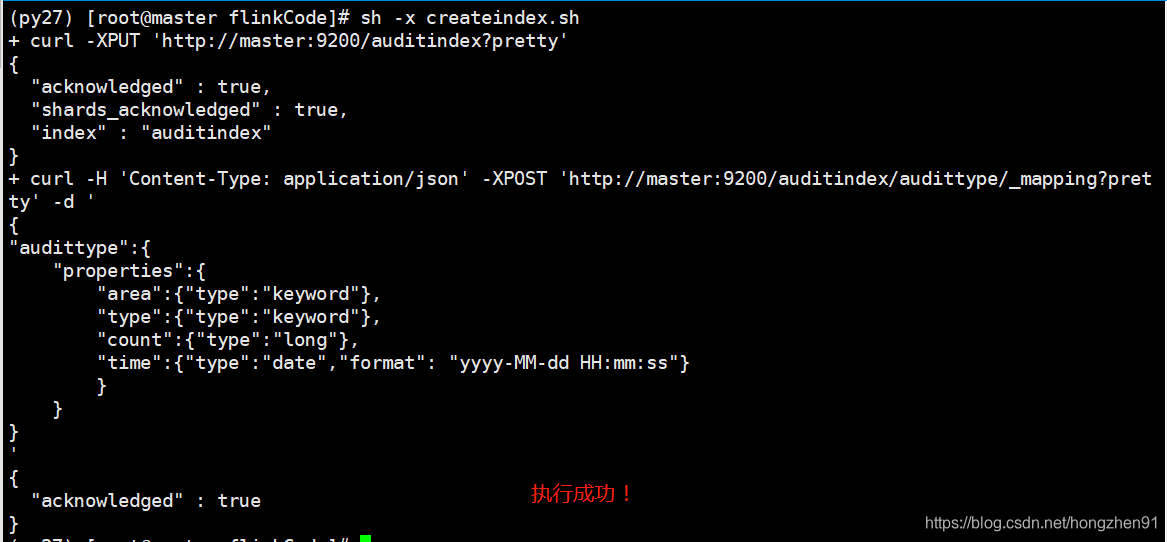
sh -x createindex.sh
创建索引执行结果:
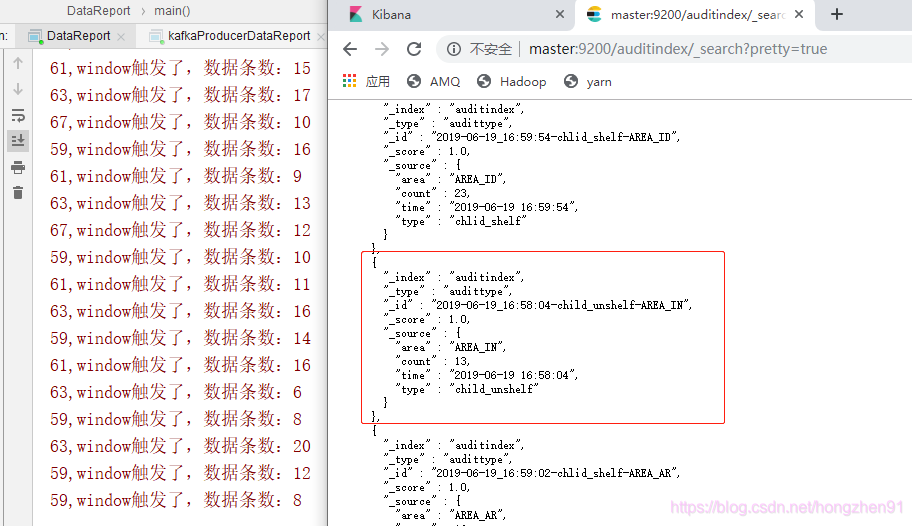
4. 查看 ES 数据:
# 访问网址
http://master:9200/auditindex/_search?pretty=true
3.3、可视化报表
1. Kibana 关联 ES:
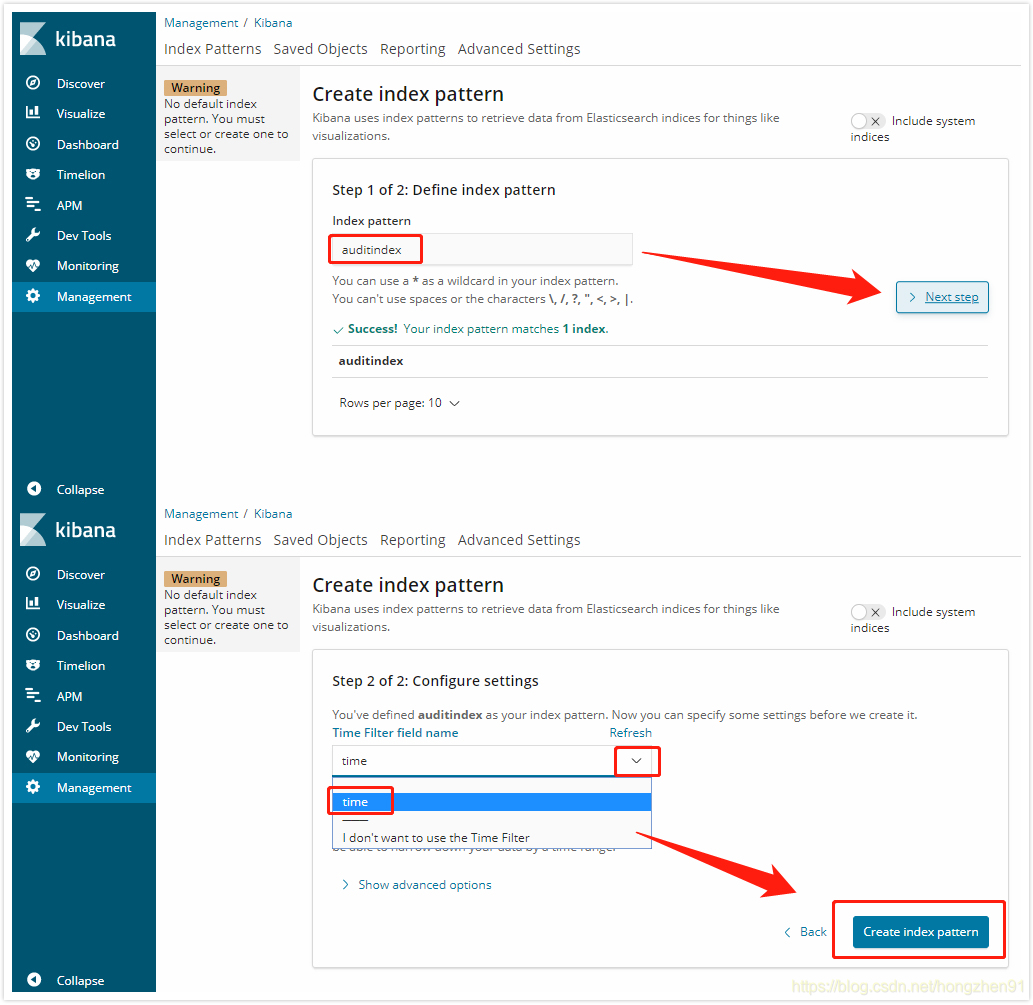
2. Discover 查看数据:
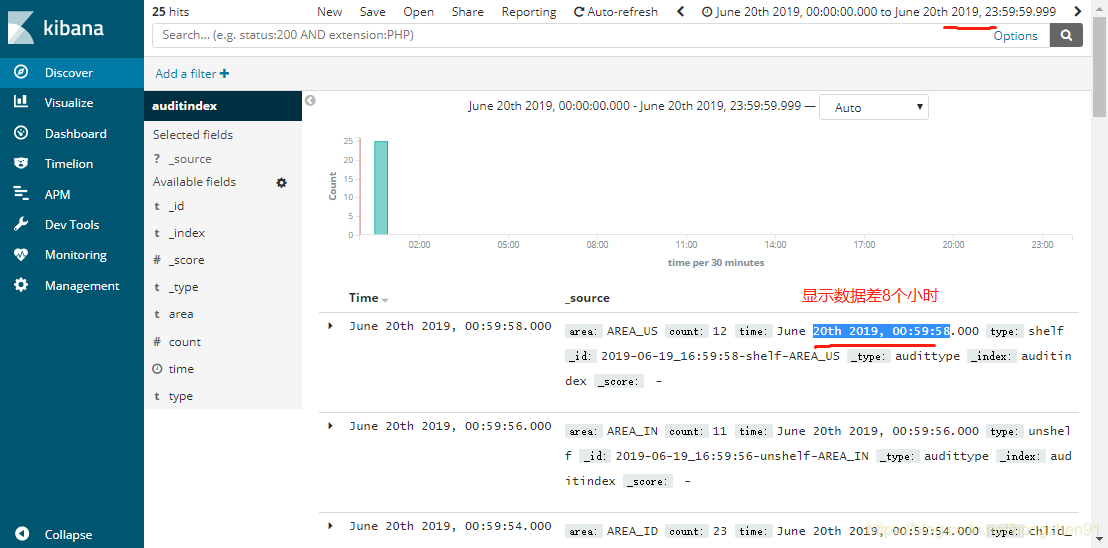
显示数据差8个小时原因:
在程序中向 ES 写数据没有带时区,就是默认时区,并且会检查浏览器时区
解决方法:
- 从代码中设置时间(不变)
- 从网页端进行设置(简单)
设置时区方法如下:
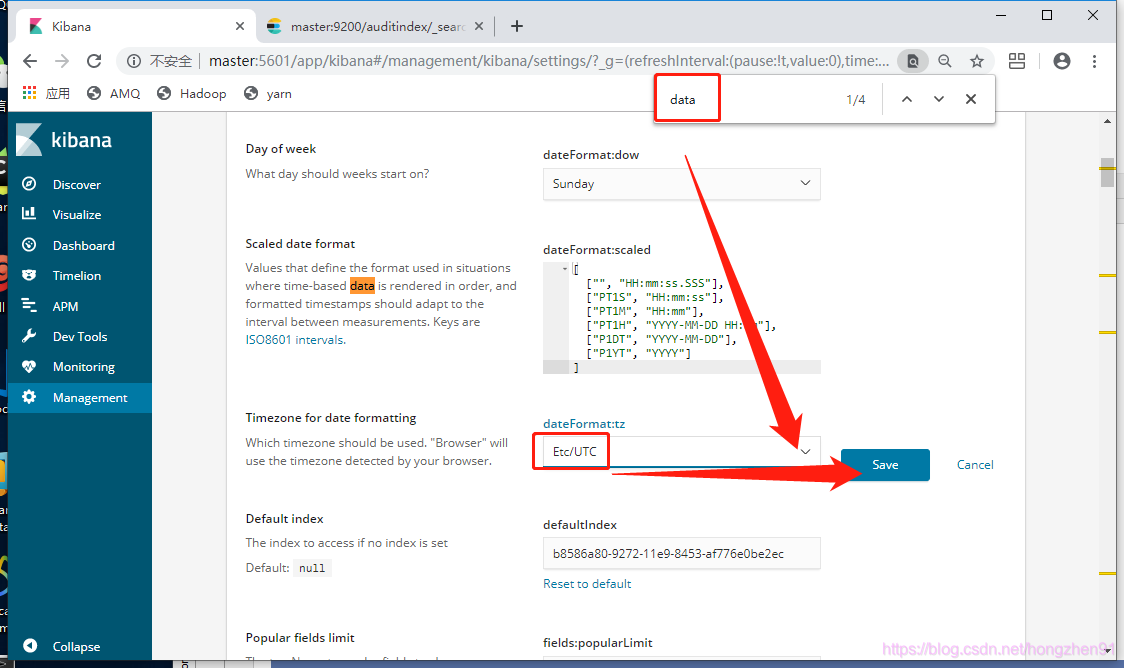
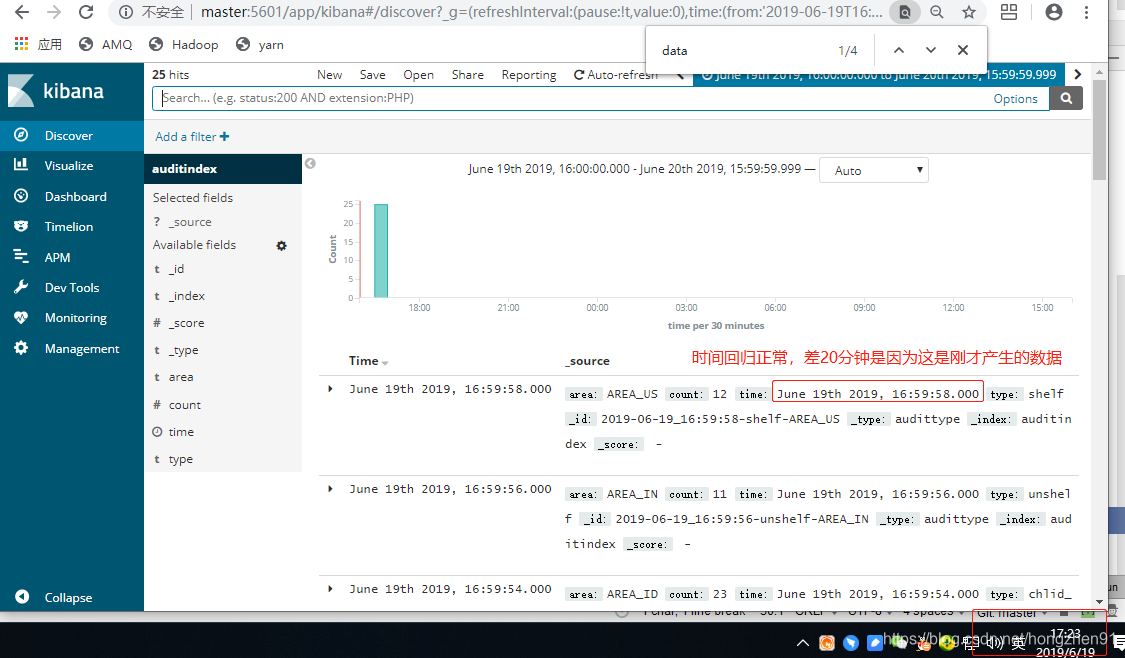
重新刷新并查看数据:
3. 新建饼图对数据可视化操作:
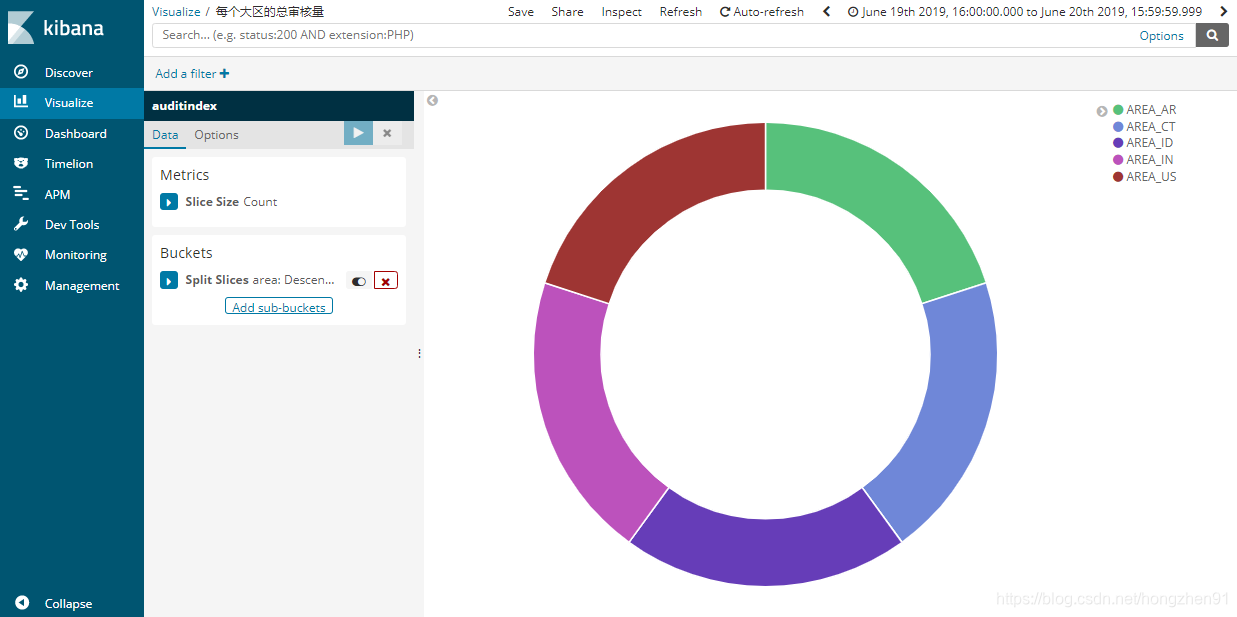
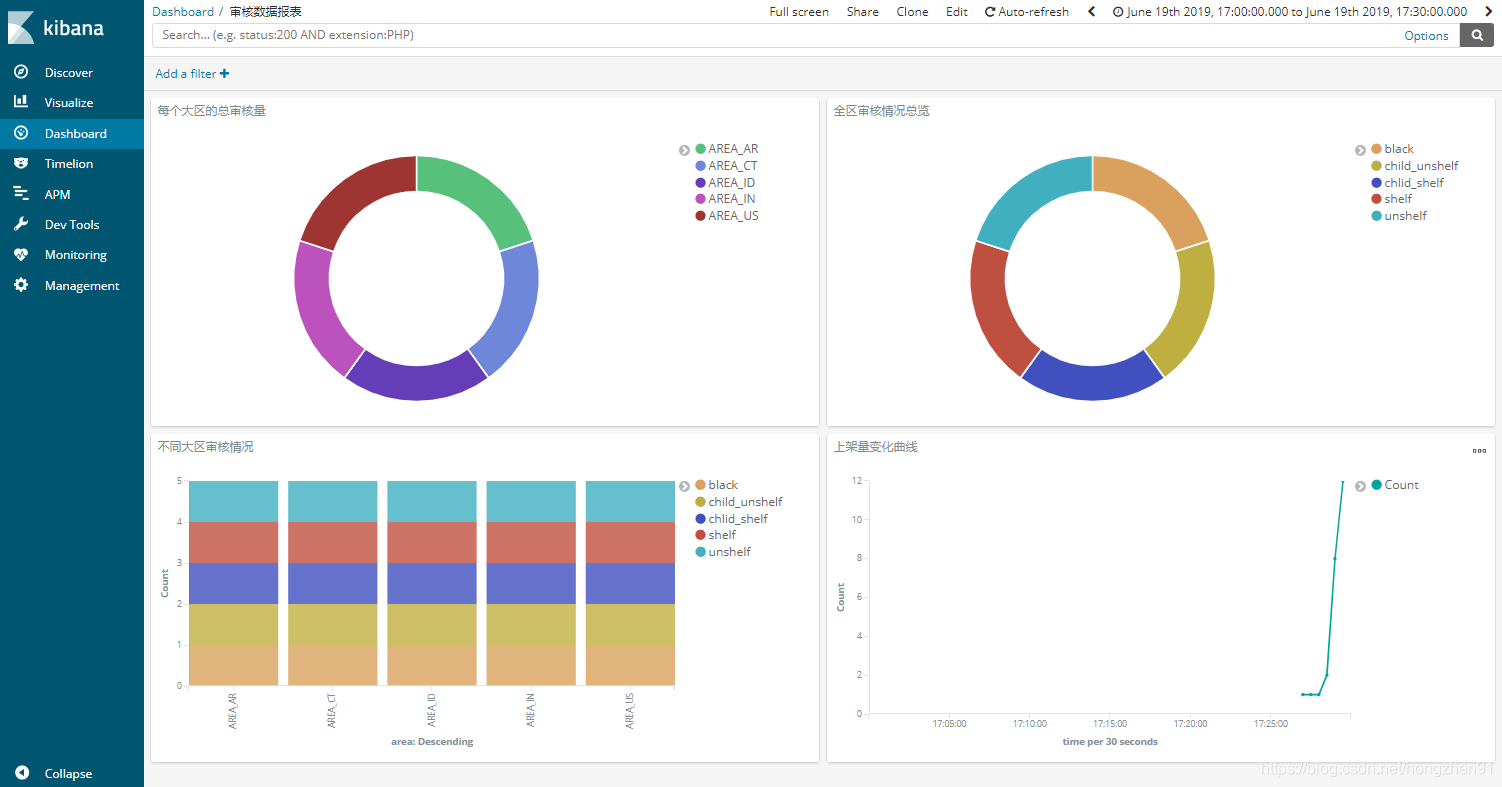
4. 新建 Dashboard 添加可视化图:
Github 工程源码地址
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!