机器学习的三个基本要素
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
第2章 机器学习概述
通俗地讲 , 机器学习 ( Machine Learning , ML ) 就是 让计算机从数据中进 行自动学习 , 得到某种知识 ( 或规律 ) . 作为一门学科 , 机器学习通常指一类问题 以及解决这类问题的方法 , 即如何从观测数据 ( 样本 ) 中寻找规律 , 并利用学习 到的规律 ( 模型 ) 对未知或无法观测的数据进行预测 . 在早期的工程领域 , 机器学习也经常称为 模式识别 ( Pattern Recognition , PR ), 但模式识别更偏向于具体的应用任务 , 比如光学字符识别 、 语音识别 、 人脸 识别等 . 这些任务的特点是 , 对于我们人类而言 , 这些任务很容易完成 , 但我们不 知道自己是如何做到的 , 因此也很难人工设计一个计算机程序来完成这些任务 . 一个可行的方法是设计一个算法可以让计算机自己从有标注的样本上学习其中 的规律 , 并用来完成各种识别任务 . 随着机器学习技术的应用越来越广 , 现在机 器学习的概念逐渐替代模式识别 , 成为这一类问题及其解决方法的统称 . 以手写体数字识别为例 , 我们需要让计算机能自动识别手写的数字 . 比如 图 2.1 中的例子 , 将 识别为数字 5 , 将 识别为数字 6 . 手写数字识别是一个经典 的机器学习任务 , 对人来说很简单 , 但对计算机来说却十分困难 . 我们很难总结 每个数字的手写体特征 , 或者区分不同数字的规则 , 因此设计一套识别算法是一 项几乎不可能的任务 . 在现实生活中 , 很多问题都类似于手写体数字识别这类问 题 , 比如物体识别 、 语音识别等 . 对于这类问题 , 我们不知道如何设计一个计算机 程序来解决 , 即使可以通过一些启发式规则来实现 , 其过程也是极其复杂的 . 因 此 , 人们开始尝试采用另一种思路 , 即让计算机 “ 看 ” 大量的样本 , 并从中学习到 一些经验 , 然后用这些经验来识别新的样本 . 要识别手写体数字 , 首先通过人工 标注大量的手写体数字图像 ( 即每张图像都通过人工标记了它是什么数字 ), 这 些图像作为训练数据 , 然后通过学习算法自动生成一套模型 ,并依靠它来识别新 的手写体数字 . 这个过程和人类学习过程也比较类似 , 我们教小孩子识别数字也 是这样的过程 . 这种通过数据来学习的方法就称为 机器学习 的方法 .
2.1 基本概念
首先我们以一个生活中的例子来介绍机器学习中的一些基本概念 : 样本 、 特 征 、 标签 、 模型 、 学习算法等 . 假设我们要到市场上购买芒果 , 但是之前毫无挑选 芒果的经验 , 那么如何通过学习来获取这些知识 ? 首先, 我们从市场上随机选取一些芒果 , 列出每个芒果的 特征 (Feature), 特征也可以称为 属性 (Attribute ). 包括颜色 、 大小 、 形状 、 产地 、 品牌 , 以及我们需要预测的 标签 ( Label ). 标签可以 是连续值 ( 比如关于芒果的甜度 、 水分以及成熟度的综合打分 ), 也可以是离散 值 ( 比如 “ 好 ”“ 坏 ” 两类标签 ). 这里 , 每个芒果的标签可以通过直接品尝来获得 , 也可以通过请一些经验丰富的专家来进行标记 . 我们可以将一个标记好 特征 以及 标签 的芒果看作一个 样本 ( Sample ), 也 经常称为 示例 ( Instance ). 一组样本构成的集合称为 数据集 ( Data Set ). 在很多领域 , 数据集也 经常称为 语料库 ( Cor-pus). 一般将数据集分为两部分 : 训练集和测试集. 训练集 ( Training Set ) 中的样本是用来训练模型的 , 也叫 训练样本 ( Training Sample ), 而 测试集 ( Test Set ) 中的样本是用来检验模型好坏 的 , 也叫 测试样本 ( Test Sample ). 我们通常用一个 𝐷 维向量 𝒙 = [𝑥 1 , 𝑥 2 , ⋯ , 𝑥 𝐷 ] T 表示一个芒果的所有特征构 成的向量 , 称为 特征向量 ( Feature Vector ), 其中每一维表示一个特征 . 而芒果的标签通常用标量𝑦来表示 .并不是所有的样本特征都是数值型,需要通过转换表示为特征向量.
假设训练集 𝒟 由 𝑁 个样本组成 , 其中每个样本都是 独立同分布的 ( Identi cally and Independently Distributed , IID ), 即独立地从相同的数据分布中抽取 的 , 记为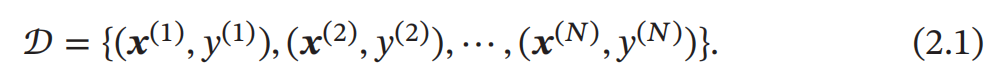 给定训练集 𝒟 , 我们希望让计算机从一个函数集合 ℱ = {𝑓 1 (𝒙), 𝑓 2 (𝒙), ⋯} 中
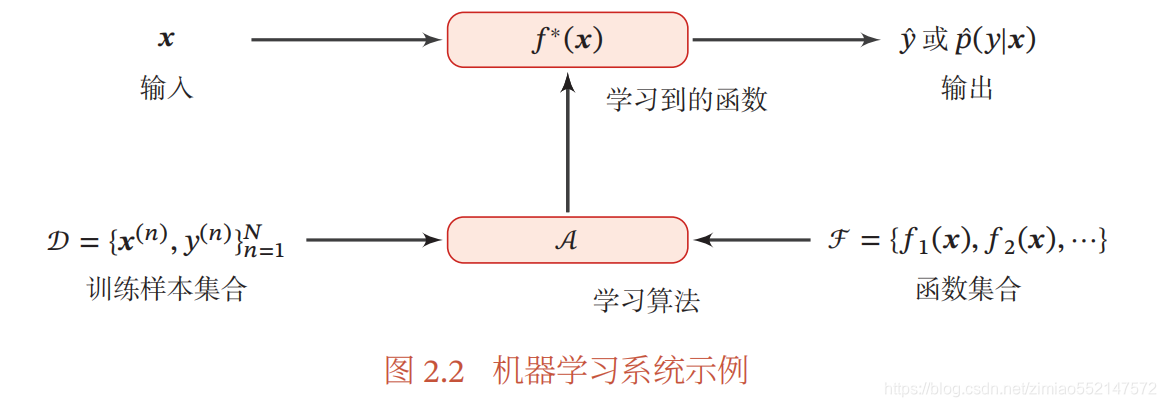
自动寻找一个 “ 最优 ” 的 函数 𝑓 ∗ (𝒙) 来近似每个样本的特征向量 𝒙 和标签 𝑦 之间
的真实映射关系 . 对于一个样本 𝒙 , 我们可以通过函数 𝑓 ∗ (𝒙) 来预测其标签的值
给定训练集 𝒟 , 我们希望让计算机从一个函数集合 ℱ = {𝑓 1 (𝒙), 𝑓 2 (𝒙), ⋯} 中
自动寻找一个 “ 最优 ” 的 函数 𝑓 ∗ (𝒙) 来近似每个样本的特征向量 𝒙 和标签 𝑦 之间
的真实映射关系 . 对于一个样本 𝒙 , 我们可以通过函数 𝑓 ∗ (𝒙) 来预测其标签的值
 或标签的条件概率
或标签的条件概率

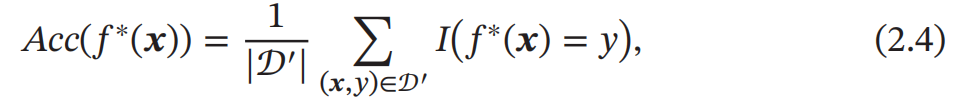
2.2 机器学习的三个基本要素
机器学习是从有限的观测数据中学习 ( 或 “ 猜测 ”) 出具有一般性的规律 , 并 可以将总结出来的规律推广应用到未观测样本上 . 机器学习方法可以粗略地分 为三个基本要素 : 模型 、 学习准则 、 优化算法 .2.2.1 模型
对于一个机器学习任务 , 首先要确定其输入空间 𝒳 和输出空间 𝒴 . 不同机器 学习任务的主要区别在于输出空间不同 . 在二分类问题中 𝒴 = {+1, −1} , 在 𝐶 分 类问题中 𝒴 = {1, 2, ⋯ , 𝐶} , 而在回归问题中 𝒴 = ℝ . 这里 , 输入空间 默认为样本的特征空间. 输入空间 𝒳 和输出空间 𝒴 构成了一个样本空间 . 对于样本空间中的样本 (𝒙, 𝑦) ∈ 𝒳 × 𝒴 , 假定 𝒙 和 𝑦 之间的关系可以通过一个未知的 真实映射函数 𝑦 = 𝑔(𝒙) 或 真实条件概率分布 𝑝 𝑟 (𝑦|𝒙) 来描述 . 机器学习的目标是找到一个模型来近 似真实映射函数 𝑔(𝒙) 或真实条件概率分布 𝑝 𝑟 (𝑦|𝒙) . 映射函数 𝑔 ∶ 𝒳 → 𝒴 . 由于我们不知道真实的映射函数 𝑔(𝒙) 或条件概率分布 𝑝 𝑟 (𝑦|𝒙) 的具体形式 , 因而只能根据经验来假设一个函数集合 ℱ , 称为 假设空间 ( Hypothesis Space ), 然后通过观测其在训练集 𝒟 上的特性 , 从中选择一个理想的 假设 ( Hypothesis ) 𝑓 ∗ ∈ ℱ . 假设空间 ℱ 通常为一个参数化的函数族
2.2.1.1 线性模型
线性模型的假设空间为一个参数化的线性函数族 , 即
其中参数𝜃 包含了权重向量𝒘和偏置𝑏.对于分类问题,一般为广义线性函数.
2.2.1.2 非线性模型
广义的非线性模型可以写为多个非线性 基函数 𝜙(𝒙) 的线性组合
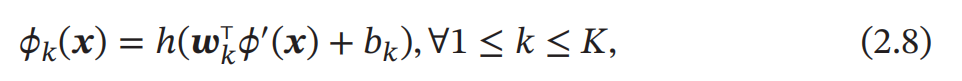
2.2.2 学习准则
令训练集 𝒟 = {(𝒙 (𝑛) , 𝑦 (𝑛) )} 𝑁 𝑛=1 是由 𝑁 个 独立同分布的 ( Identically and Independently Distributed , IID ) 样本组成 , 即每个样本 (𝒙, 𝑦) ∈ 𝒳 × 𝒴 是从 𝒳 和 𝒴 的联合空间中按照某个未知分布 𝑝 𝑟 (𝒙, 𝑦) 独立地随机产生的 . 这里要求样 本分布 𝑝 𝑟 (𝒙, 𝑦) 必须是固定的 ( 虽然可以是未知的 ), 不会随时间而变化 . 如果 𝑝 𝑟 (𝒙, 𝑦) 本身可变的话 , 就无法通过这些数据进行学习 . 一个好的模型 𝑓(𝒙, 𝜃 ∗ ) 应该在所有 (𝒙, 𝑦) 的可能取值上都与真实映射函数 𝑦 = 𝑔(𝒙) 一致 , 即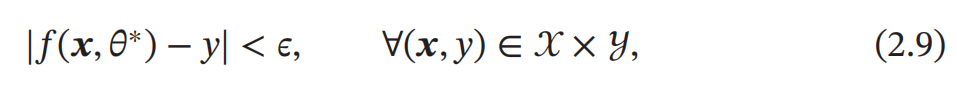
或与真实条件概率分布𝑝𝑟 (𝑦|𝒙)一致,即
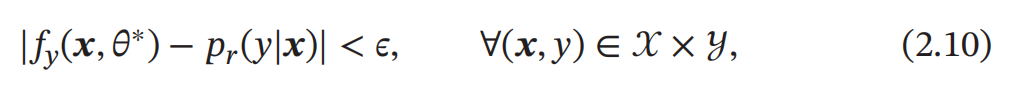
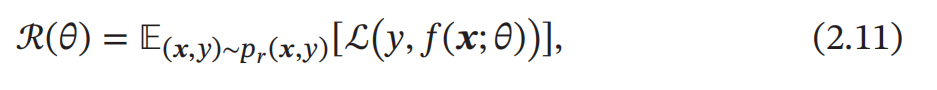
2.2.2.1 损失函数
损失函数是一个非负实数函数 , 用来量化模型预测和真实标签之间的差异 . 下面介绍几种常用的损失函数 . 0-1 损失函数 最直观的损失函数是模型在训练集上的错误率 , 即 0-1 损失函数 ( 0-1 Loss Function ):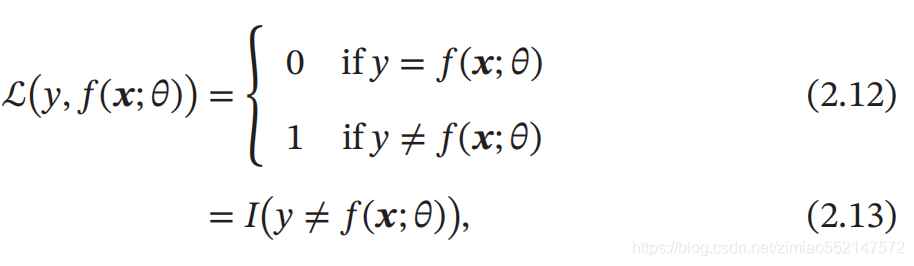
平方损失函数
平方损失函数 ( Quadratic Loss Function ) 经常用在预测标签𝑦 为实数值的任务中 , 定义为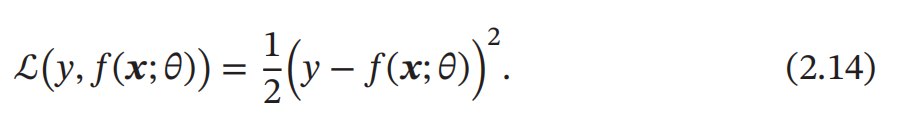
交叉熵损失函数
交叉熵损失函数 (Cross-Entropy Loss Function)一般用于 分类问题 . 假设样本的标签 𝑦 ∈ {1, ⋯ , 𝐶} 为离散的类别, 模型 𝑓(𝒙; 𝜃) ∈ [0, 1]𝐶 的输出为类别标签的条件概率分布,即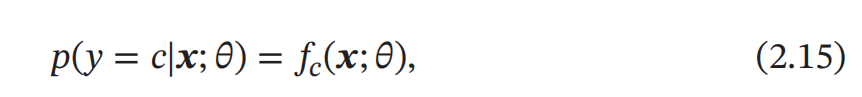

并满足
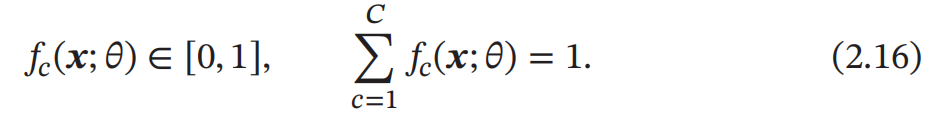
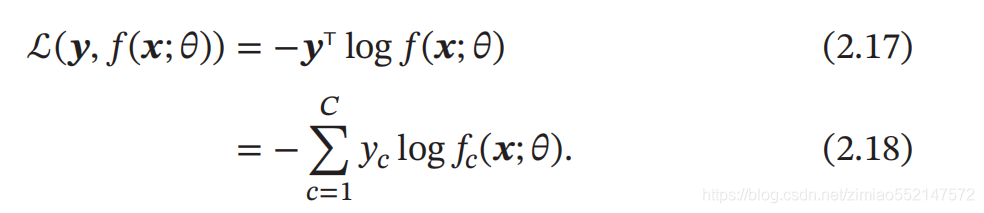
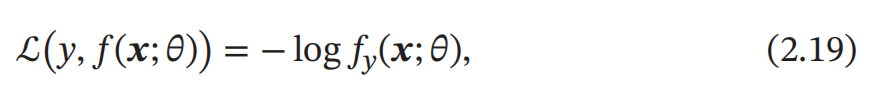
Hinge 损失函数
对于二分类问题 , 假设 𝑦 的取值为 {−1, +1} ,𝑓(𝒙; 𝜃) ∈ ℝ. Hinge 损失函数 ( Hinge Loss Function ) 为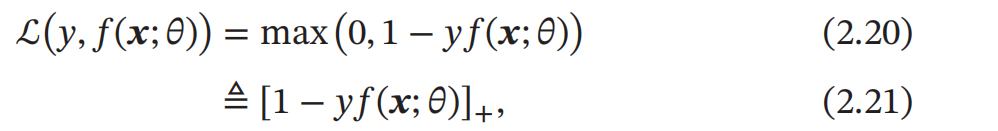
2.2.2.2 风险最小化准则
一个好的模型 𝑓(𝒙; 𝜃) 应当有一个比较小的期望错误,但由于不知道真实的数据分布和映射函数 ,实际上无法计算其期望风险 ℛ(𝜃).给定一个训练集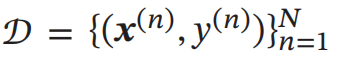 我们可以计算的是 经验风险 ( Empirical Risk),即在训练集上 的平均损失: 经 验 风 险 也 称 为 经 验错误 (Empirical Error).
我们可以计算的是 经验风险 ( Empirical Risk),即在训练集上 的平均损失: 经 验 风 险 也 称 为 经 验错误 (Empirical Error).
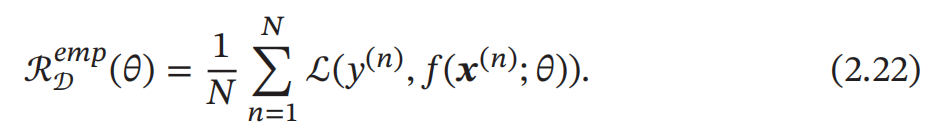

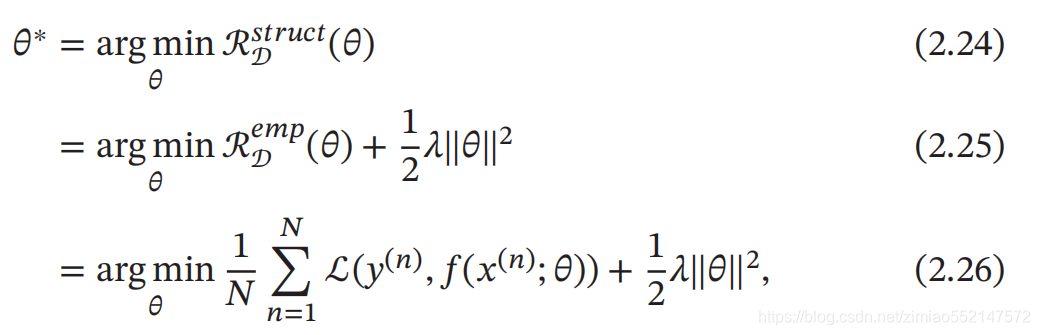
2.2.3 优化算法
在确定了训练集 𝒟、假设空间 ℱ 以及学习准则后,如何找到最优的模型 𝑓(𝒙, 𝜃∗) 就成了一个 最优化 (Optimization)问题 . 机器学习的训练过程其实就 是最优化问题的求解过程.参数与超参数
在机器学习中,优化又可以分为参数优化和超参数优化.模型 𝑓(𝒙; 𝜃)中的𝜃 称为模型的参数, 可以通过优化算法进行学习.除了可学习的参数 𝜃 之外, 还有一类参数是用来定义模型结构或优化策略的,这类参数叫作 超参数 (Hyper-Parameter). 在贝叶斯方法中,超参 数可以理解为参数的参数,即控制模型参数分布的参数 . 常见的超参数包括 : 聚类算法中的类别个数 、 梯度下降法中的步长 、 正则化 项的系数、 神经网络的层数 、 支持向量机中的核函数等 . 超参数的选取一般都是 组合优化问题 , 很难通过优化算法来自动学习 . 因此 , 超参数优化 是机器学习的 一个经验性很强的技术 , 通常是按照人的经验设定 , 或者通过搜索的方法对一组 超参数组合进行不断试错调整 .2.2.3.1 梯度下降法
为了充分利用凸优化中一些高效 、 成熟的优化方法 , 比如共轭梯度 、 拟牛顿 法等, 很多机器学习方法都倾向于选择合适的模型和损失函数 , 以构造一个凸函 数作为优化目标 . 但也有很多模型 ( 比如神经网络 ) 的优化目标是非凸的 , 只能 退而求其次找到局部最优解 . 在机器学习中,最简单 、 常用的优化算法就是 梯度下降法 ,即首先初始化参 数𝜃 0,然后按下面的迭代公式来计算训练集𝒟 上风险函数的最小值: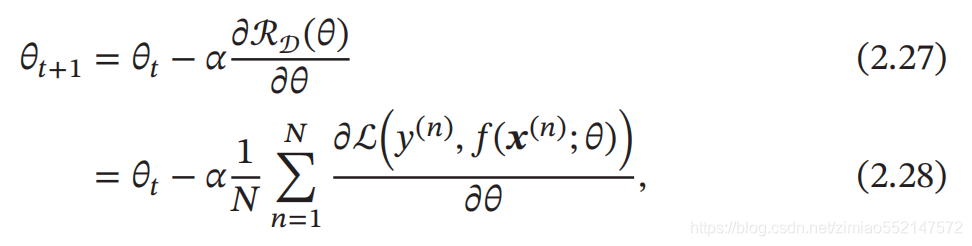
2.2.3.2 提前停止
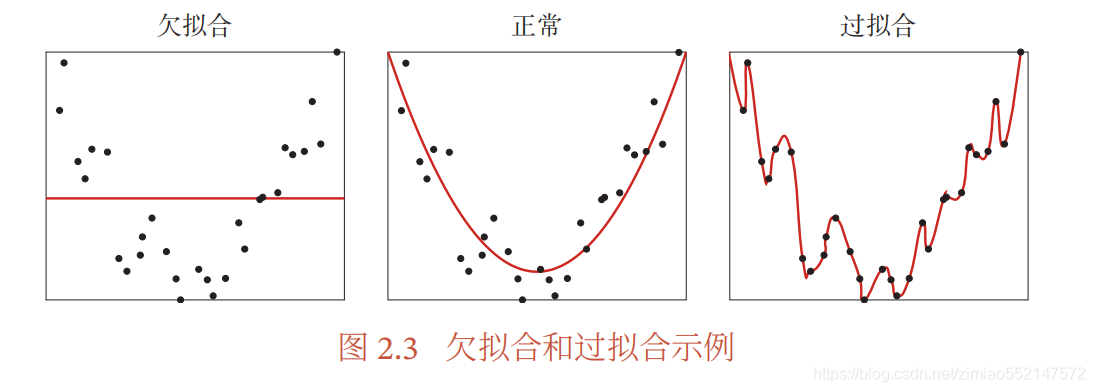
针对梯度下降的优化算法 , 除了加正则化项之外 , 还可以通过提前停止来防 止过拟合. 在梯度下降训练的过程中, 由于过拟合的原因 , 在训练样本上收敛的参数 , 并不一定在测试集上最优 . 因此 , 除了训练集和测试集之外 , 有时也会使用一 个 验证集 ( Validation Set ) 来进行模型选择,测试模型在验证集上是否最优. 验证集也叫作 开发集 (Development Set). 在每次迭代时, 把新得到的模型 𝑓(𝒙; 𝜃) 在验证集上进行测试,并计算错误率. 如果在验证集上的错误率不再下降,就停止迭代.这种策略叫 提前停止 ( Early Stop). 如果没有验证集 , 可以在训练集上划分出一个小比例的子集作为验证集 . 图 2.4 给出了提前停止的示例 .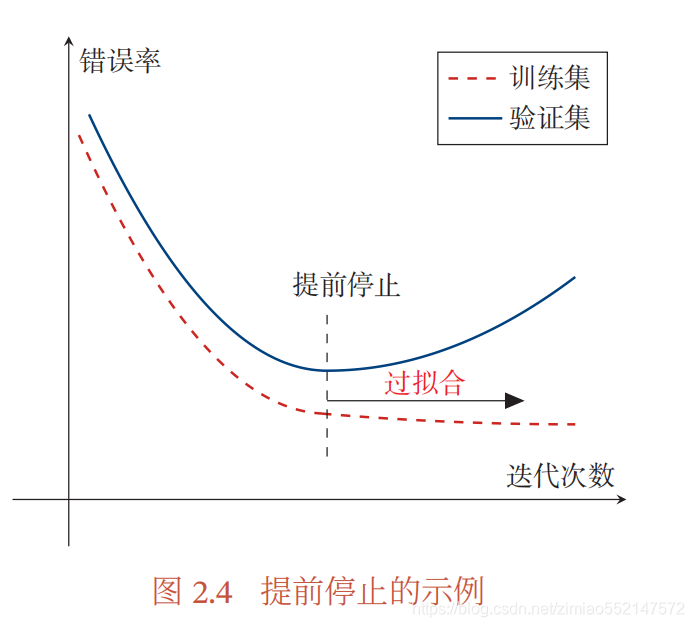
2.2.3.3 随机梯度下降法
在公式 ( 2.27 ) 的梯度下降法中 , 目标函数是整个训练集上的风险函数 , 这种 方式称为 批量梯度下降法 ( Batch Gradient Descent , BGD ). 批量梯度下降法在 每次迭代时需要计算每个样本上损失函数的梯度并求和.当训练集中的样本数 量𝑁 很大时, 空间复杂度比较高,每次迭代的计算开销也很大. 在机器学习中 , 我们假设每个样本都是独立同分布地从真实数据分布中随 机抽取出来的, 真正的优化目标是期望风险最小.批量梯度下降法相当于是从 真实数据分布中采集 𝑁 个样本 , 并由它们计算出来的 经验风险 的梯度来近似 期 望风险 的梯度 . 为了减少每次迭代的计算复杂度,我们也可以在每次迭代时只 采集一个样本 , 计算这个样本损失函数的梯度并更新参数 , 即 随机梯度下降法 ( Stochastic Gradient Descent , SGD ). 随机梯度下降法也叫 作 增量梯度下降法 . 当经过足够次数的迭代时 , 随机梯度下降 也可以收敛到局部最优解[ Nemirovski et al. , 2009 ] . 随机梯度下降法的训练过程如算法 2.1 所示 .
2.2.3.4 小批量梯度下降法
随机梯度下降法的一个缺点是无法充分利用计算机的并行计算能力 . 小批 量梯度下降法 ( Mini-Batch Gradient Descent ) 是批量梯度下降和随机梯度下 降的折中 . 每次迭代时 , 我们随机选取一小部分训练样本来计算梯度并更新参 数 , 这样既可以兼顾随机梯度下降法的优点,也可以提高训练效率. 第𝑡 次迭代时 , 随机选取一个包含𝐾 个样本的子集𝒮𝑡 , 计算这个子集上每个 样本损失函数的梯度并进行平均,然后再进行参数更新: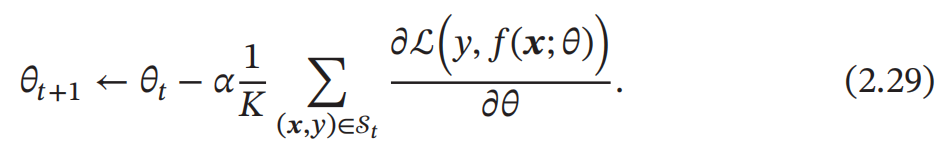

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!