基于深度学习GNN的智能合约漏洞检测特征提取流程
我们先对时间戳依赖进行特征的提取和分析
背景
为了训练模型得到漏洞的特征,我们必须将智能合约的代码转换成机器能识别的数字,进一步就是onehot编码。
主要脚本
AutoExtractGraph:实现初步提取智能合约的特征,输出包括英文和数字
vec2onehot:提供将所有特征转换为01编码的类
graph2vec:将由auto提取出来的初步特征转换为onehot编码从而作为模型的输入
我们可以先看看最终模型的输入:

包括target(是否有漏洞,先验知识),graph(图中所有边的起始位置和类型),contract_name(合约名字)
还有最重要的node_features(节点的各种属性组成的onehot编码)
首先看看最开始的输入:一个智能合约

进入autoextractgraph
1.split_function函数将合约中的每个函数分开:
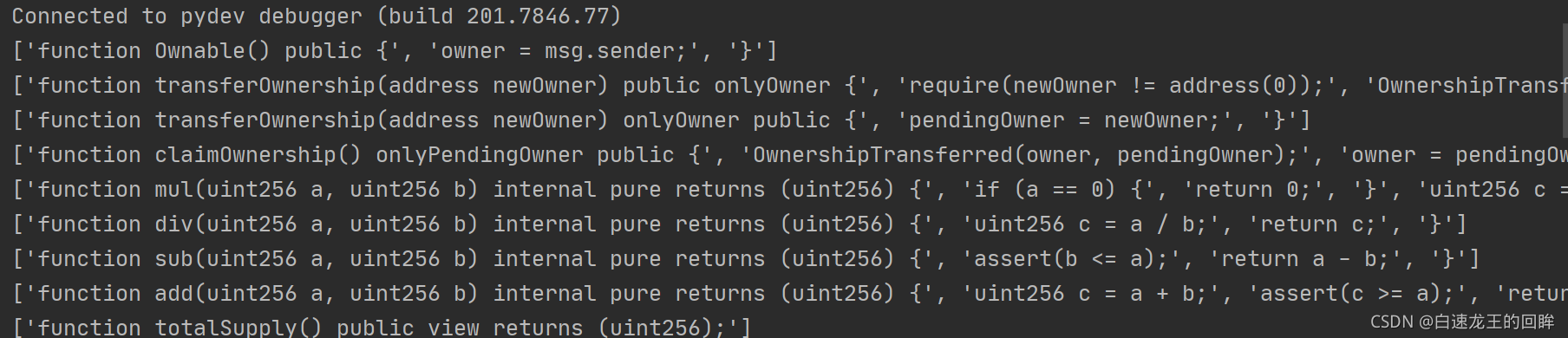
2.进入到核心的genrate_graph函数:
第一步:找到含有block.timestamp的句子
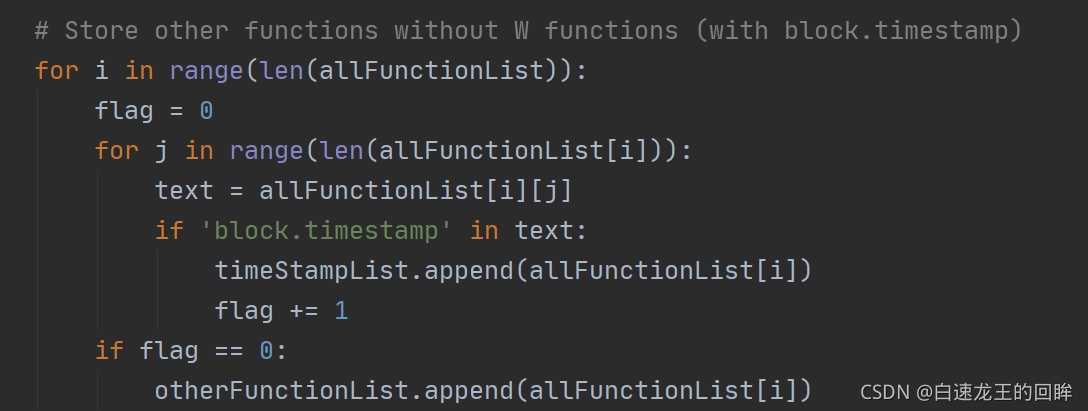
出现几次timestamp就放几次。。。
2.遍历含有timestamp的句子,判断限制条件:
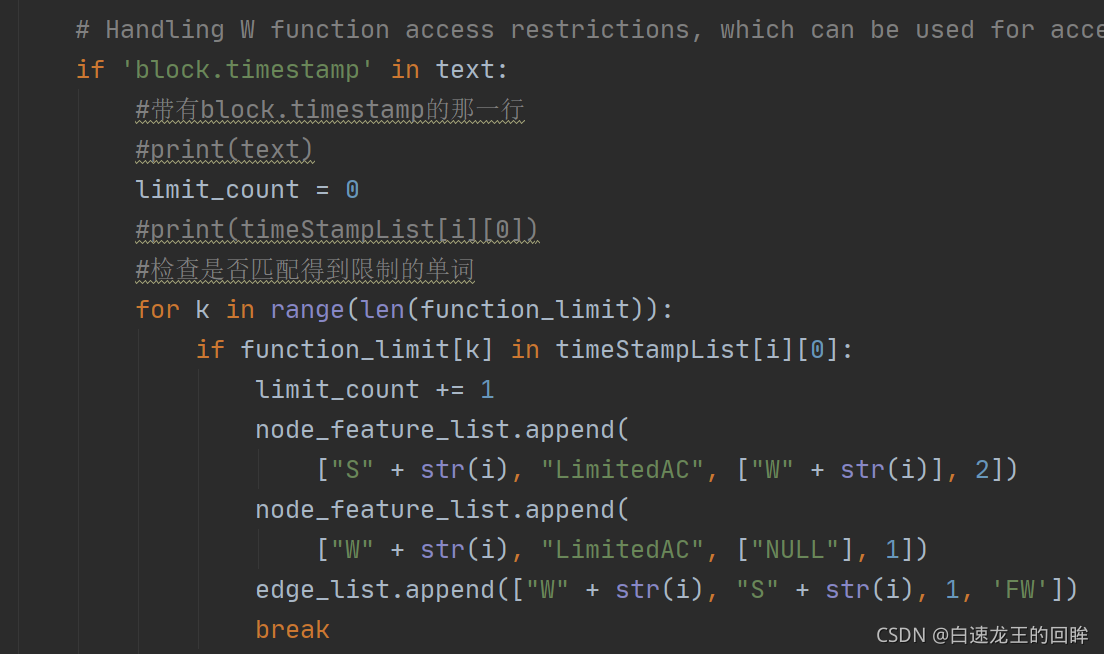
3.存储赋值为timestamp的变量
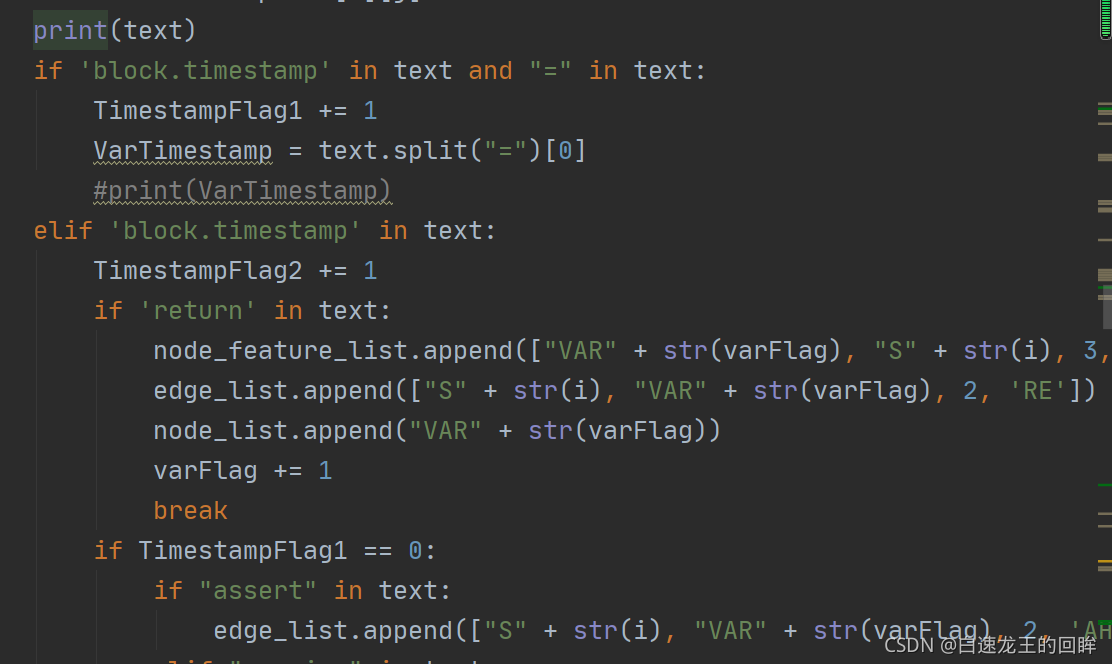
4.最终输出结果

5.结果解释
只有一句话和timestamp相关
节点特征那里S0和W0就凭空出来了(我也不知道为啥),然后都是无限制函数内的,var0对应的就是currentTimestamp这个变量
边的特征的话就是遵循(起点,终点,顺序,类型)进行排列
vec2onehot.py
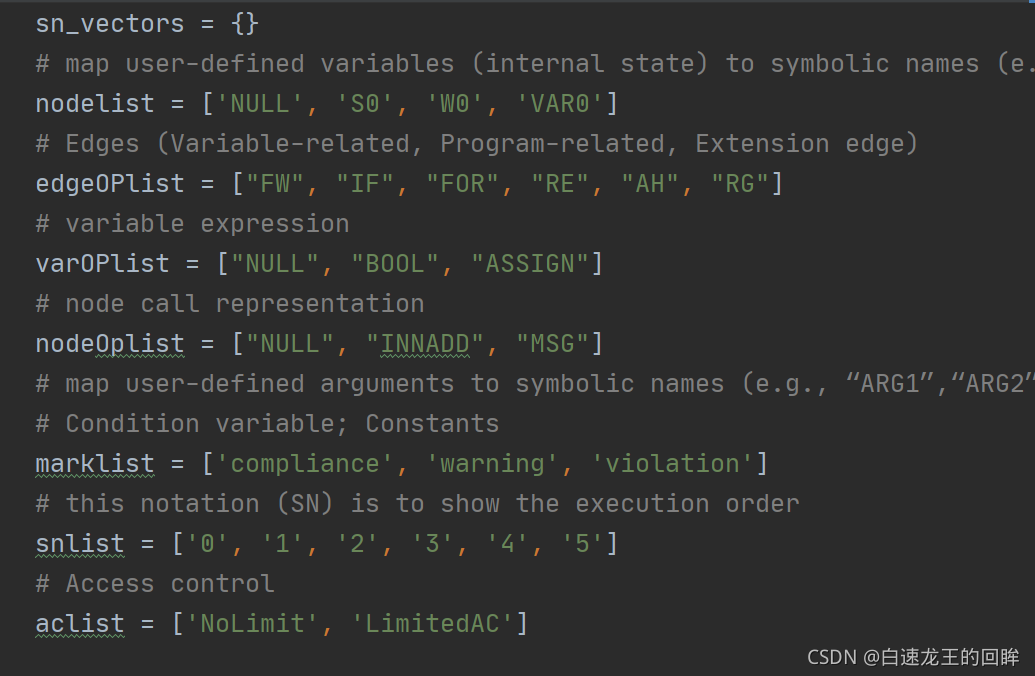
把所有这些特征,变成01编码,比如nolimit就是10,limitedAC就是01这样子
graph2vec
非常复杂的一个函数,逻辑很啰嗦,但我们也看看
它的主要功能是将特征进行整合。。。
这个脚本的输入就是autoextractgraph的输出,也就是点和边的信息,以1813.sol为例子:


最终的输出可以预告一下:
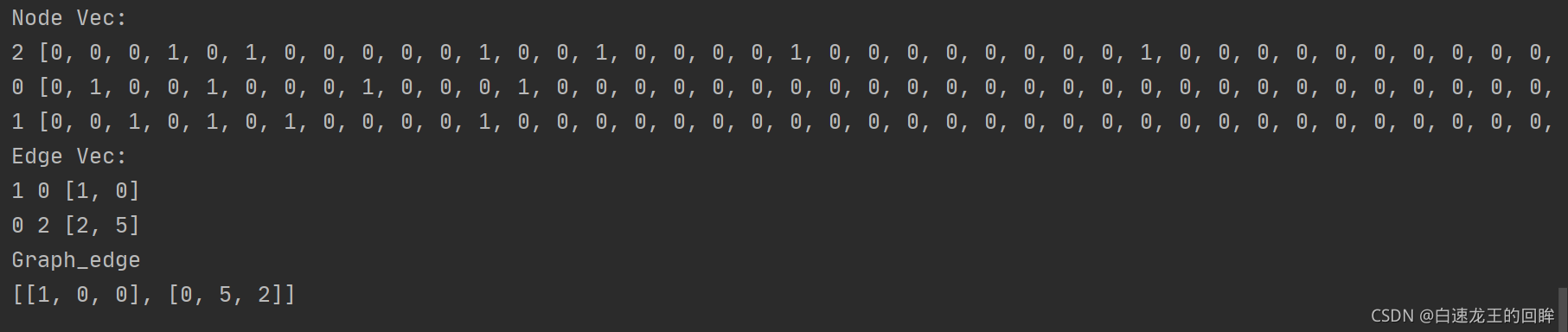
最终在traindata中用到的是所有的点特征和图中的边
图中的边就很简单啦:(起点,终点,类型),直接由之前的结果转换一下就好
主要是如何得到图中的点特征???
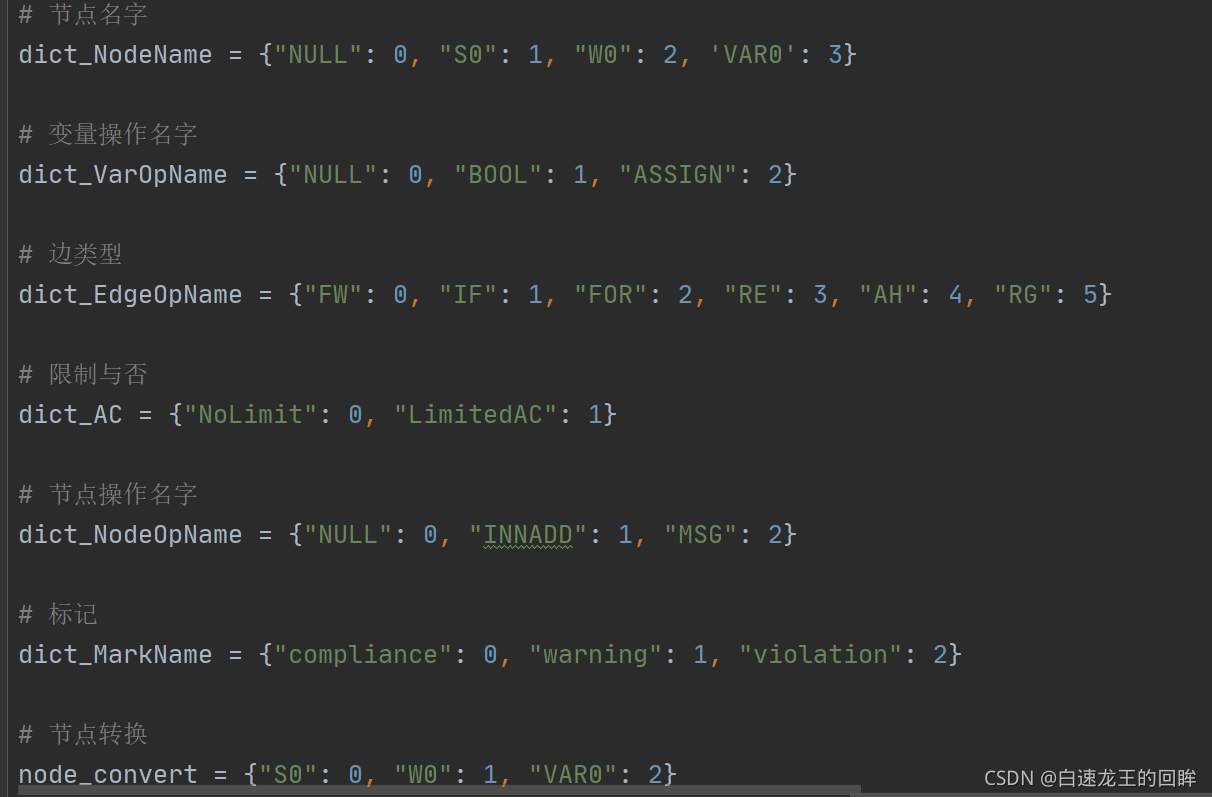
首先将英文数字化。。
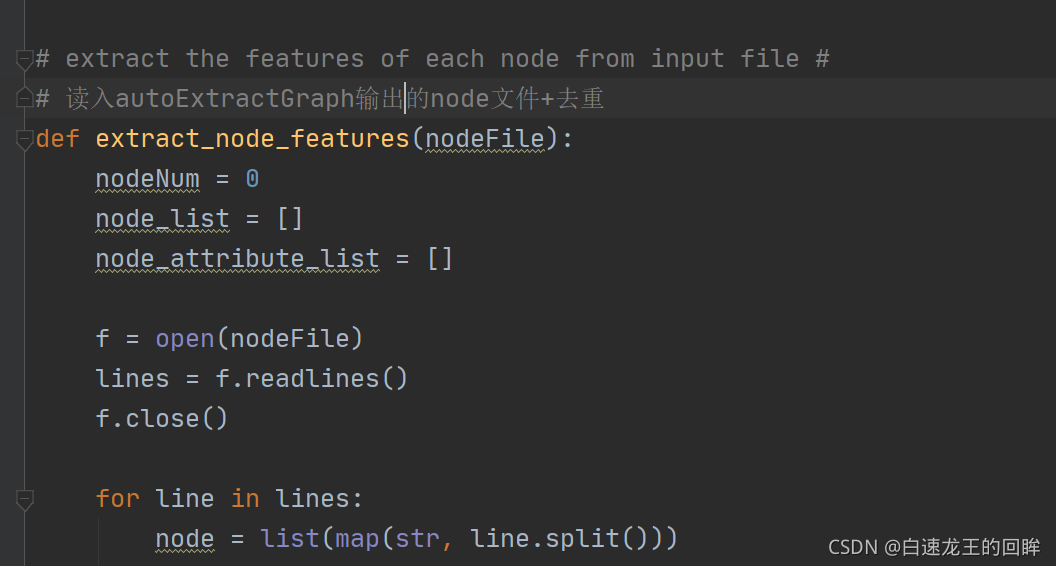
然后读入node文件+去重
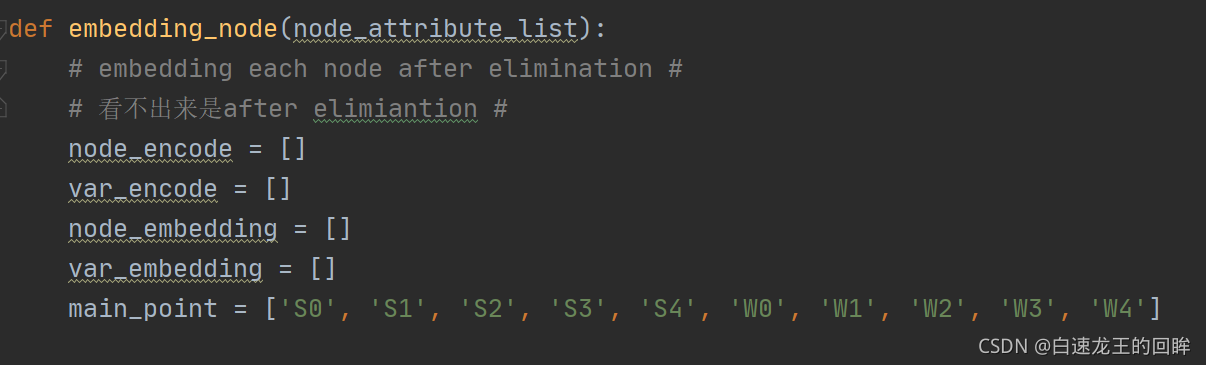
对node中的信息数字化+onehot编码
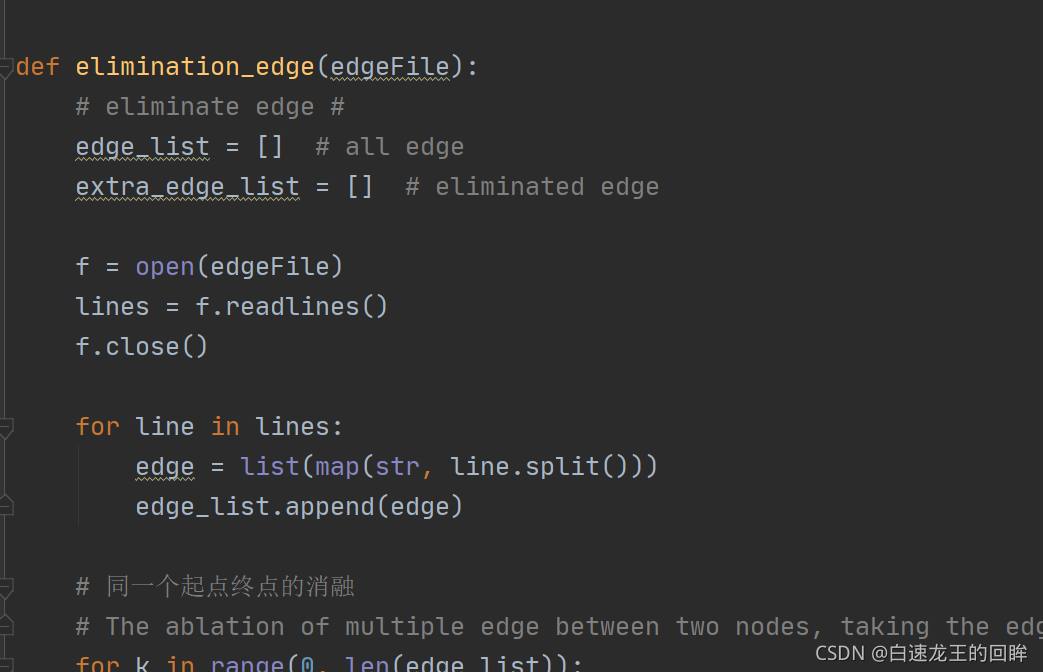
读入边的信息,进行边的消融

边的数字化表示和onehot编码
关键来了:特征构建!!
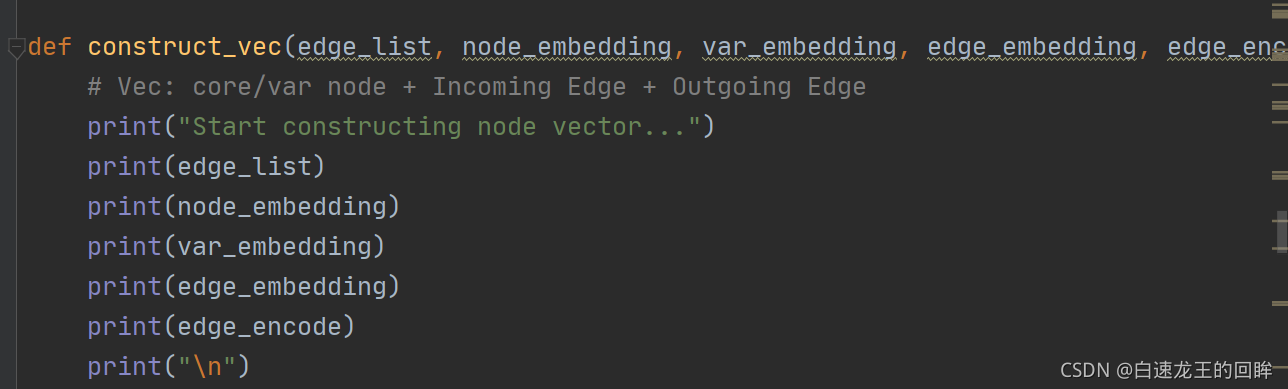
输入由边列表、特征匹配字母的node编码,和变量var的编码,edge编码和onehot构成

找到var0是in还是out:

它是一个in的节点,也就是边的终点,然后给出这条边的onehot编码。。

统计出入的节点:

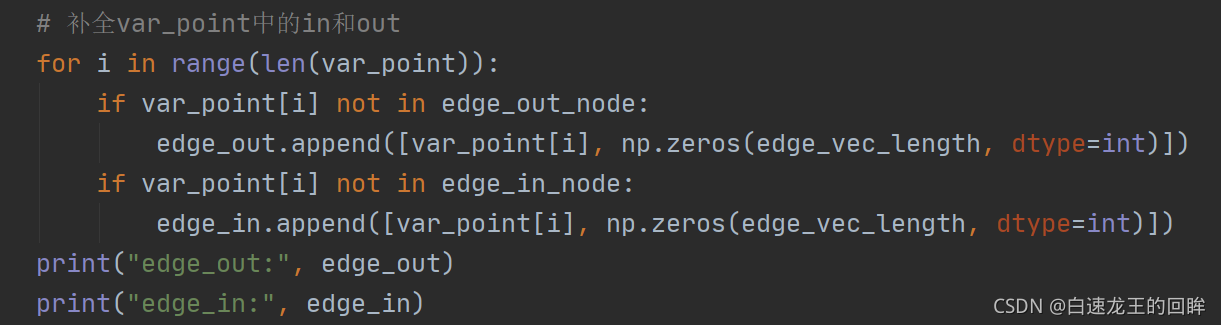
var_point在timestamp类型中只定义了var0,别问为啥,我也不知道,结果就是,out的补全0

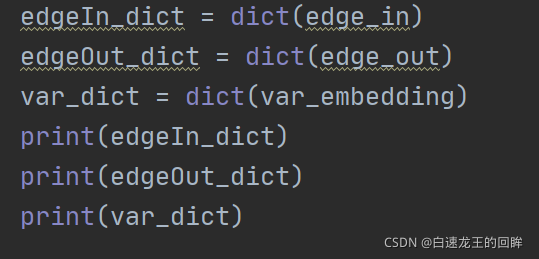
构建三个字典:

我们可以发现,var本身的embedding是长于边的embedding的
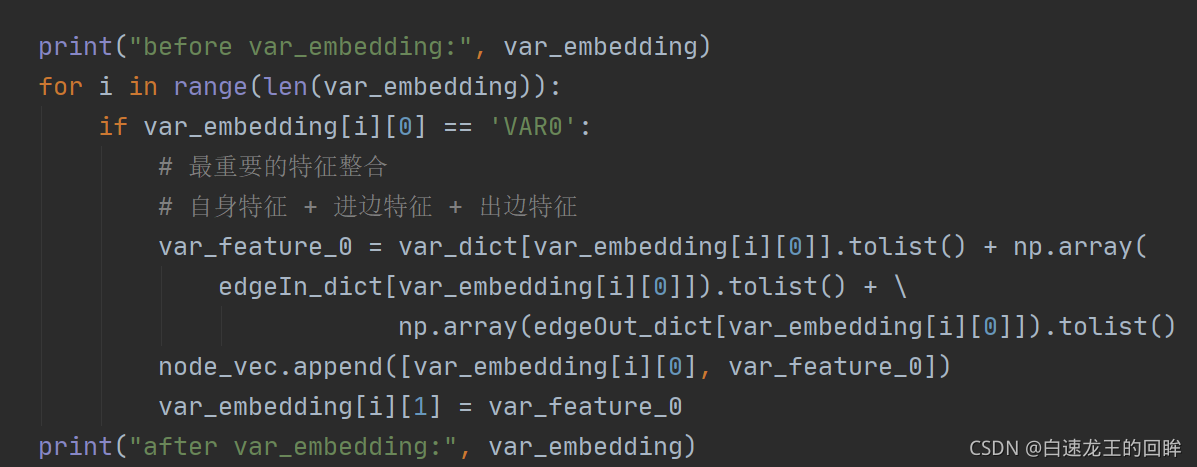
变量var的特征整合:本身+进边+出边,结果为:

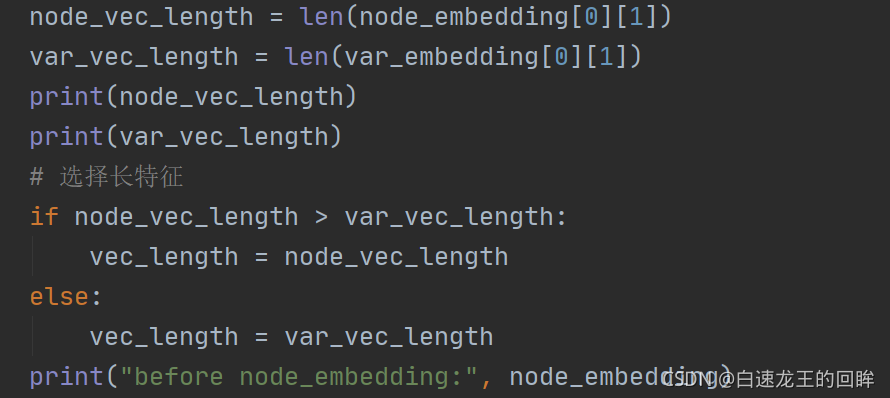
随后对node特征长度和var特征长度进行比较,并选择长度长的特征作为最终的节点特征:
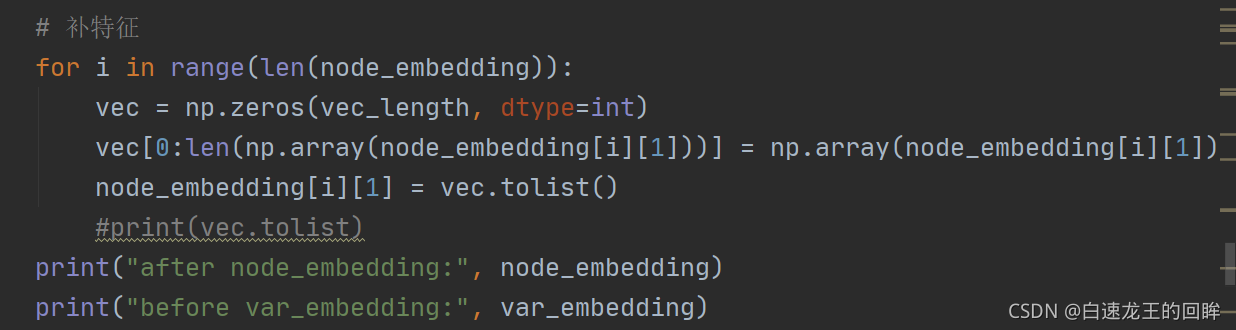
随后进行node的补特征(长度为node和var的较大者),结果为:

由于node特征小于var特征,因此node的特征全部拉长(后面补0),var特征不变
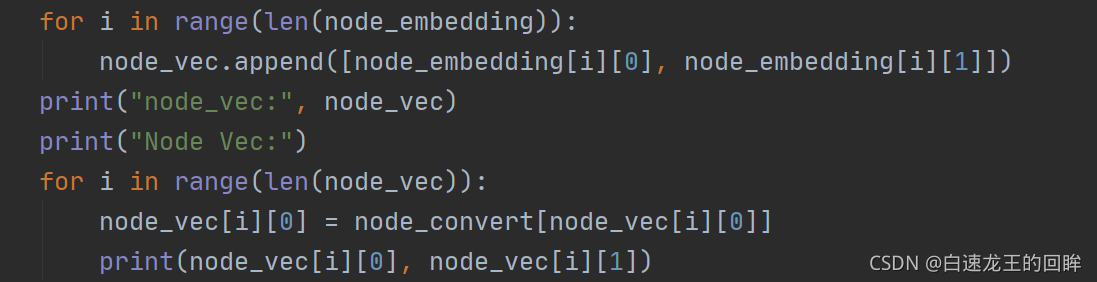
输出node特征(包括var):

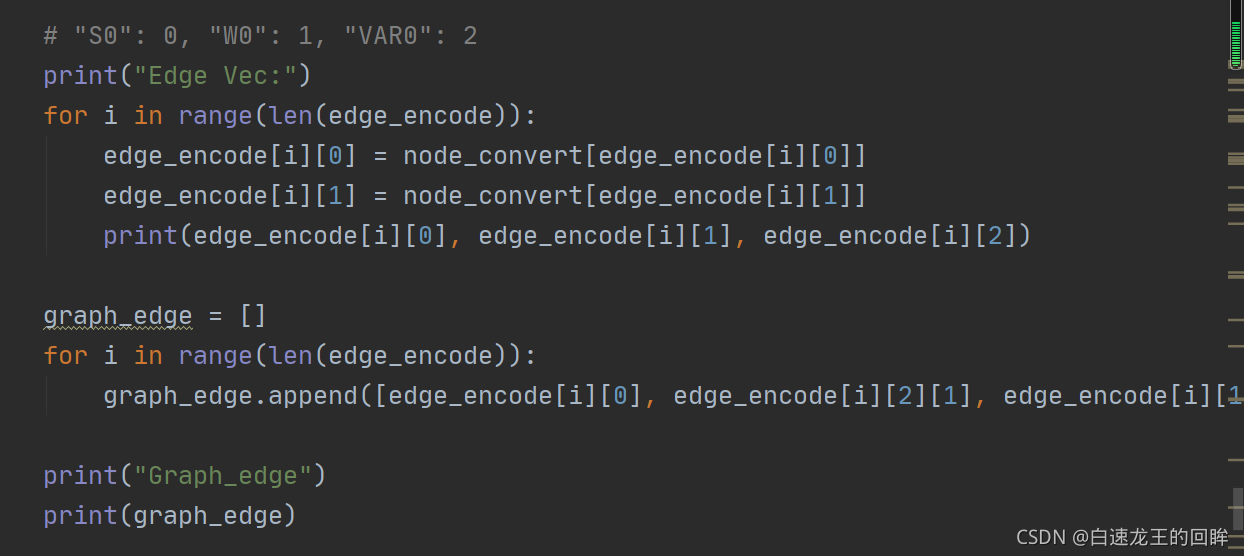
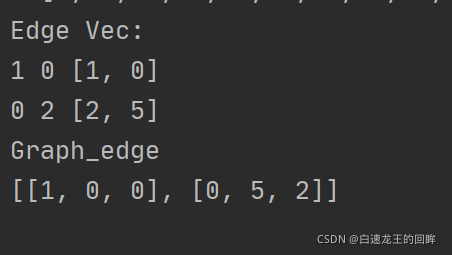
输出edge特征和图的所有edge:
总结:
至此,graphedge和nodefeature全部得到!

traindata.json就构建出来了
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!