Adreno GPU上的DirectX平台优化 (5)
Adreno GPU上的DirectX平台优化 (5)
- 5.3.2 几何渲染
- 5.3.3 纹理
5.3.2 几何渲染
- 顶点重用
Adreno GPU 具有转换后顶点着色器缓存,可存储有限数量的顶点。 这意味着执行顶点着色器后,执行顶点着色器的转换后结果存储在缓存中。 如果在从缓存中驱逐之前在索引缓冲区中再次引用了相同的顶点,则可以跳过顶点着色器的执行。 图 5-7 中的示例说明了转换后顶点缓存的行为。

应用程序应始终使用索引渲染并创建索引缓冲区来保存索引。如果应用程序选择不使用索引渲染,它将无法从图 5-2 中描述的顶点重用中受益。实现转换后顶点缓存的最佳重用的最佳方法是使用三角形条带或条带排序索引三角形列表对索引缓冲区进行排序(两者都应实现大致相同的性能)。
-
使用静态和Baked-in照明
动态光、阴影贴图、法线贴图和每像素效果应保留给场景中具有视觉价值的对象。换句话说,在重要的对象上使用着色器指令。在实践中,这意味着尽可能地简化场景,例如使用Baked-in照明。 -
使用背面剔除
一个简单但有时被忽视的性能错误是关闭背面剔除。这可能会导致需要着色的像素数量在最坏情况下翻倍。对于不透明的非平面对象,应始终剔除背面。请注意,基于图块的渲染算法遵循 D3D 剔除模式,因此背面剔除多边形也可以提高顶点处理性能。 -
使用前后渲染
GPU 包含特殊电路来优化像素块,否则这些像素块将无法通过深度测试。 GPU 会尝试在流水线的早期检测此类像素块,以节省进一步的处理。为了辅助 GPU,渲染应该尽可能接近前后。让 CPU 对单个三角形进行排序是多余的,但是,例如,最后绘制天空框和倒数第二个地形是一个明智的策略。 -
避免过度剪辑
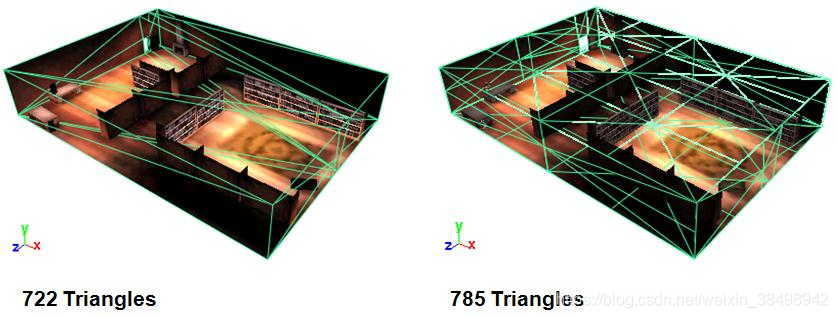
通过将几何图形进一步划分为更多图元,避免过度裁剪,尤其是对于静态几何图形。 例如,在图 5-8 中,一个静态房间从 722 个三角形变为 785 个三角形。 整体几何体中添加了更多三角形,但由于没有过度剪裁过大的三角形,因此性能有所提高。
-
使用交错、压缩的顶点
对于顶点获取性能,交错顶点属性(xyz、uv、xyz、uv、…而不是 xyz、xyz、xyz、… uv、uv、uv、…)是最好的。交错顶点的吞吐量更好,压缩顶点甚至更好。基于平铺的渲染为这些优化提供了很大的优势。顶点缓冲区中支持半浮点坐标。这些可用于纹理或法线坐标,其中较低的精度不会损害最终图像。 -
最后绘制天空盒
许多游戏仍然首先渲染天空盒。这在几代硬件之前曾经是最快的方式,因为它直接填充颜色缓冲区而不进行深度测试。然而,在现代硬件上,天空盒应该在帧中尽可能晚地渲染。只有与天空盒混合的透明对象才能在它之后渲染。这样做的原因是天空盒本身往往被场景的大部分遮挡。如果你先渲染天空盒,你会着色很多稍后会被覆盖的像素。这会浪费像素处理和带宽。通过最终渲染天空盒,只会对必要的像素进行着色。最后渲染天空盒时,您可能希望将其与远剪裁平面挂钩,以避免天空盒切入场景时出现任何问题。这可以很容易地通过将 MVP 矩阵的第四行复制到第三行来实现,以便 Z 和 W 评估为相同的值,因此 Z / W 变为 1.0。或者,可以将 W 值复制到顶点着色器中的 Z 中。 -
延迟更新
对于 Direct3D11.1 Level 9 应用程序,D3D 运行时将批量处理所有持续更新并按需将它们广播给驱动程序。应用程序应考虑对常量状态进行延迟更新,以最大限度地减少 Direct3D 运行时完成的工作量。 -
最小化状态变化
对于基于 tile 的渲染架构,每个状态更新都会在每个 bin 中重放。应用程序应该小心地只设置给定绘制操作绝对必要的任何状态。话虽如此,请确保状态代表您打算如何渲染场景。例如,如果渲染不依赖于最终图像的混合,则不要将混合启用状态设置或保留为 TRUE。驱动程序启用基于状态的优化,不正确设置状态可能会对性能产生负面影响。 -
着色器组合的预热阶段
Adreno GPU 要求驱动程序在将所有着色器提交给 GPU 之前将它们合并在一起。在绘制时,如果存在布局状态、顶点着色器和像素着色器的唯一组合,驱动程序将链接所有着色器并将生成的着色器缓存在内存中。如果可能,应用程序使用布局状态、顶点和像素着色器的预期组合绘制虚拟图元是有益的,以允许驱动程序在加载屏幕期间预缓存这些组合。 -
遮挡查询
在基于图块的渲染模式下,遮挡查询与给定渲染目标的渲染一起进行批处理。由于在遇到刷新条件之前不会处理给定渲染目标的渲染,因此 GPU 可能在调用 Present 时尚未处理查询,即使 ID3D11DeviceContext::Begin 和 ID3D11DeviceContext::End 已在附近发出帧的开始。使用遮挡查询的最有效方法是在可能的情况下在前一帧上发出查询。应用程序可以调用 Flush 或 GetData 向驱动程序提示应用程序需要挂起的查询,但这可能会导致额外的 GMEM 加载和 GMEM 存储(请参阅第 5.2 节)。
如果必须在与查询相同的帧中使用遮挡数据,如果在给定渲染目标上为渲染发出 Begin 和 End,则最好等到在调用 GetData 之前在另一个渲染目标上发出渲染命令。这样,驱动程序的自然流程将处理呈现目标和查询,并且不会有任何额外的 GMEM 加载或 GMEM 存储。
永远不要在一个紧密的循环中等待一个查询得到满足。虽然这将正常工作,但它不允许应用程序或驱动程序继续向 GPU 提供命令,并且会影响性能。应用程序应该有一个备用路径,以防在调用 GetData 时查询未准备好。 -
更新数据
修改顶点和/或索引缓冲区数据的理想方法是让应用程序管理自己的缓冲区。以下应用程序伪代码将在驱动程序中以最佳方式运行。
- 创建一个已知大小的缓冲区,最好足够大以容纳至少一帧数据。
- 记录有多少数据添加到该缓冲区,
- 如果缓冲区中有数据空间,请使用 D3D11_MAP_WRITE_NO_OVERWRITE 映射缓冲区以获取指向表面的指针。将数据写入该位置并增加数据计数。
- 如果缓冲区中没有足够的空间容纳您的数据,请使用 D3D11_MAP_WRITE_DISCARD 映射缓冲区并将数据计数重置为零。
- 将新数据复制到映射缓冲区中,然后取消映射。
上述路径在应用程序中相当常用,并在驱动程序中进行了优化。
5.3.3 纹理
-
压缩纹理
纹理缓存友好性要求尽可能压缩纹理。请注意,渲染目标未压缩。虽然 CPU 时间可用于压缩已解析的渲染目标,但 CPU-GPU 同步和实际压缩时间会使实时渲染变得不可能。使用 Adreno Texture Converter 等外部工具来压缩纹理和法线贴图。 -
使用 Mipmap
当可以使用较低 LOD 的 mips 时,Mipmap 有两方面的好处。当它们从系统内存中获取时,它们更小并且消耗更少的带宽。此外,由于较低的 LOD mips 明显更小,因此它们更有可能驻留在纹理缓存中,从而无需通过系统内存总线获取数据。
如果应用程序决定使用 GenerateMips,则应在加载场景时执行此操作,以避免在最终用户看到的渲染过程中出现任何潜在故障。 -
使用多重纹理
在 Adreno GPU 上,可以在单个渲染通道中使用多个纹理(多达 16 个)。混合是一种廉价的效果,因此使用多个纹理来实现可能的效果,例如静态照明而不是动态照明。 -
资源绑定标志
仅为给定资源设置必要的绑定标志。例如,不要将只读纹理标记为渲染目标。驱动程序使用这些标志来优化一些事情,如果信息不正确,应用程序将通过驱动程序和 GPU 采取不太理想的路径。 -
纹理更新
在运行 Direct3D11.1 Level 9 应用程序时,应用程序应考虑避免 UpdateSubresource 调用。 Direct3D 运行时将创建一个临时资源并将系统内存数据复制到其中,然后再调用驱动程序以 blt 数据。为了更直接地控制更新的处理方式,应用程序应该创建和管理自己的暂存资源,并使用 CopyResource/CopySubresourceRegion 来更新纹理。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!