Spark中RDD内部进行值转换遇到的问题
问题内容
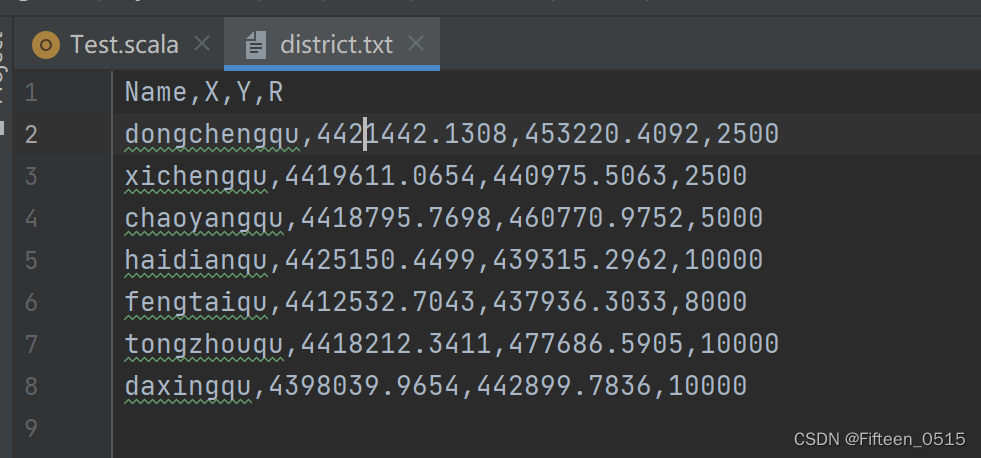
txt文件内容
鄙人需求是去除第一行的数据,代码如下
object Test {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("demo").setMaster("local")val sc = new SparkContext(conf)val dis = sc.textFile("D:\\BigDate\\spark-core\\src\\main\\resources\\datas\\district.txt")dis.filter(_!=dis.first()).collect().foreach(println)}sc.stop()}
于是发生了以下错误
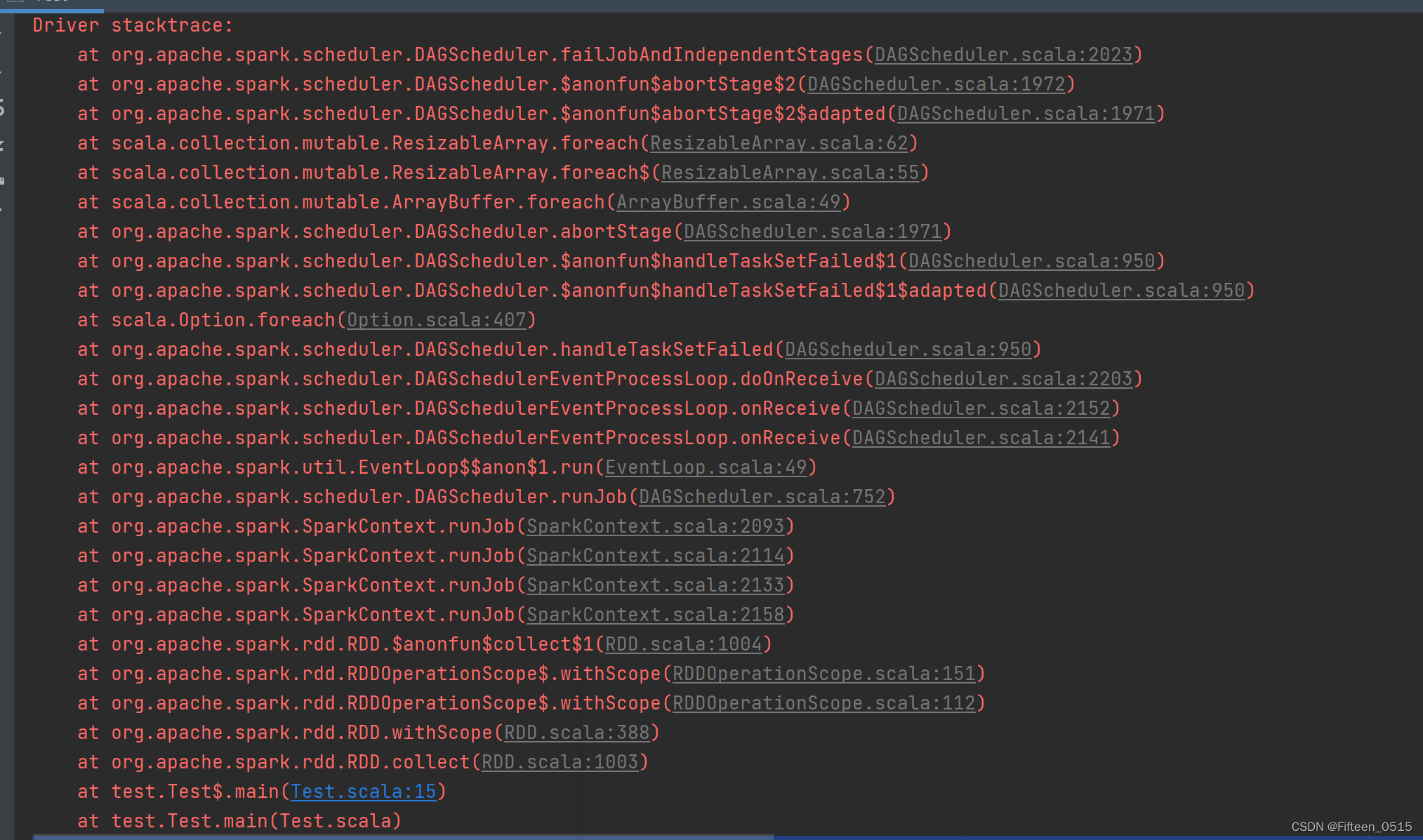
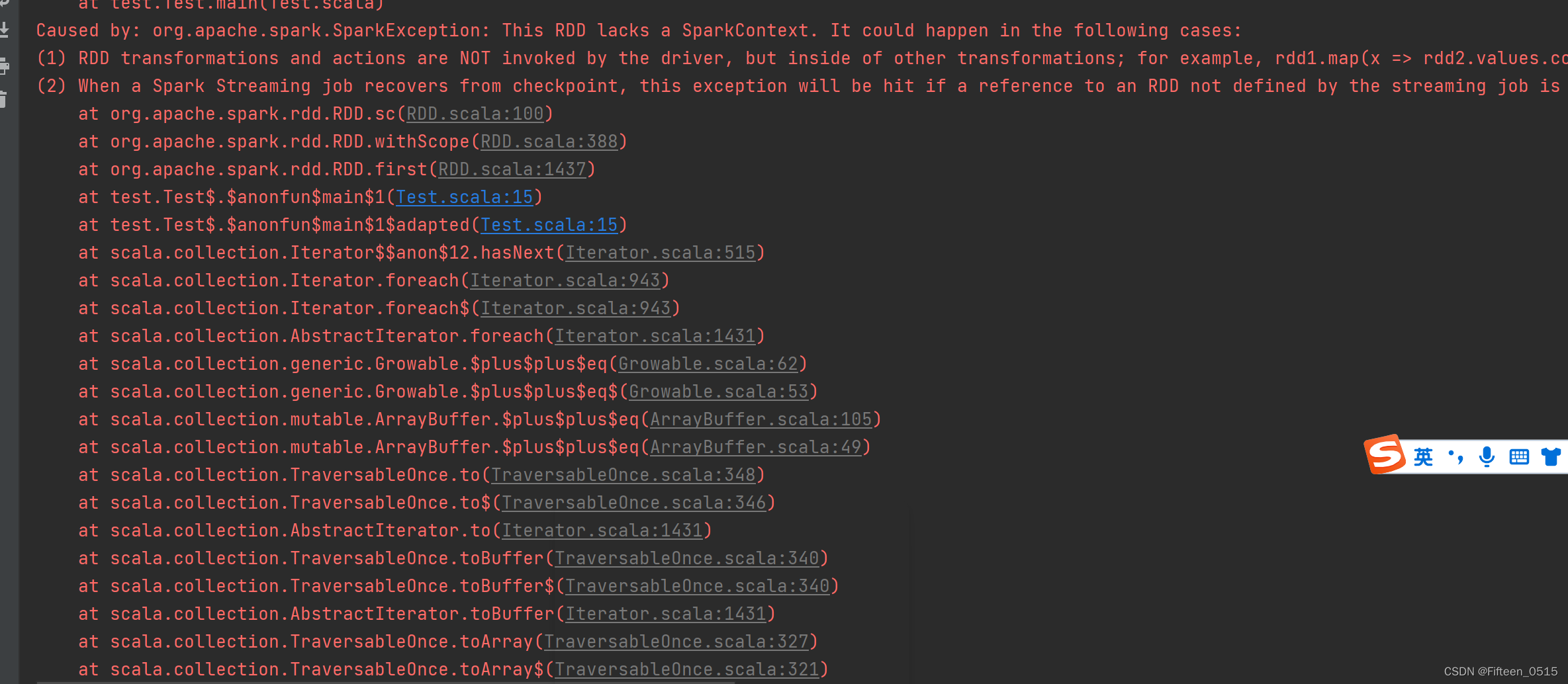
错误描述如下:
Caused by: org.apache.spark.SparkException: This RDD lacks a SparkContext. It could happen in the following cases:
(1) RDD transformations and actions are NOT invoked by the driver, but inside of other transformations; for example, rdd1.map(x => rdd2.values.count() * x) is invalid because the values transformation and count action cannot be performed inside of the rdd1.map transformation. For more information, see SPARK-5063.
(2) When a Spark Streaming job recovers from checkpoint, this exception will be hit if a reference to an RDD not defined by the streaming job is used in DStream operations. For more information, See SPARK-13758.
大致意思为:RDD转换和操作不是由驱动程序调用的,而是在其他转换内部调用的。
rdd1.map(x => rdd2.values.count() * x)
上述例子是无效的,因为值转换和计数操作不能在rdd1内部执行
如何解决
只需要将步骤拆分开来就可以了
代码如下
object Test {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("demo").setMaster("local")val sc = new SparkContext(conf)val dis = sc.textFile("D:\\BigDate\\spark-core\\src\\main\\resources\\datas\\district.txt")val head = dis.first()dis.filter(_!=head).collect().foreach(println)sc.stop()}}
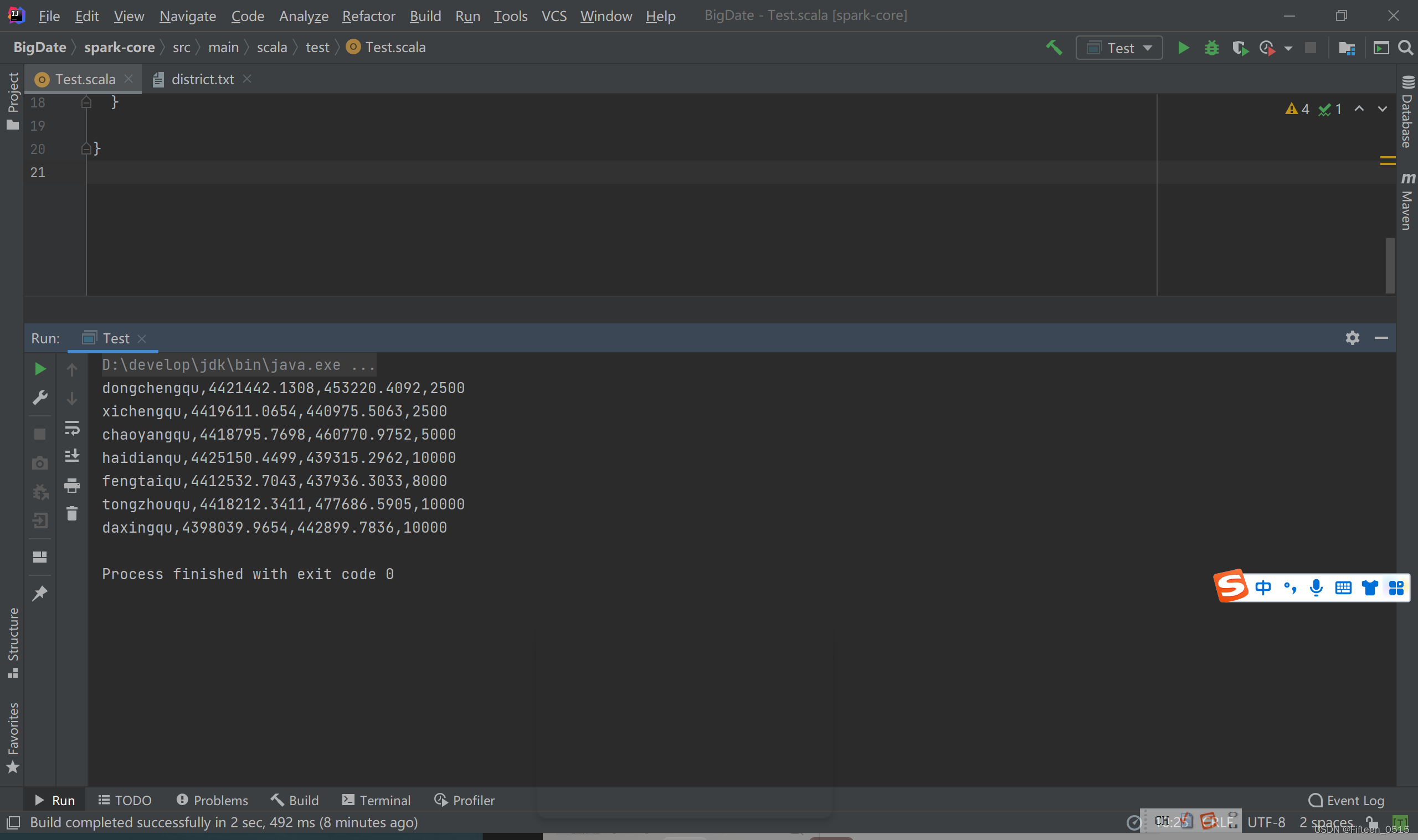
就可以看到没有报错啦
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!