机器学习之决策树算法后期(预剪枝后剪枝)
1.在进行决策树剪枝操作之前,我们先来看看为什么要进行决策树的剪枝操作?
那是因为决策树的过拟合的风险很大。因为理论上来说可以将数据完全分的开,如果树足够大,每个叶子节点就剩下了一个数据。那么,这就会造成模型在训练集上的拟合效果很好,但是泛化能力很差,对新样本的适应能力不足。所以,对决策树进行剪枝,可以降低过拟合的风险。
2.决策树的剪枝策略(预剪枝/后剪枝)
- 预剪枝
预剪枝在决策树生成过程中对每个节点先进行估计,如果划分能带来准确率上升则划分,否者不划分节点;后剪枝则是先使用训练集生成一棵决策树,再使用测试集对其节点进行评估,若将子树替换为叶子结点能带来准确率的提升则替换。
预剪枝优点:限制树的深度,叶子节点个数,叶子节点的样本数,信息增益量
- 后剪枝
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
后剪枝和前剪枝的不同在于后剪枝是在生成决策树后再进行剪枝。顺序是由下到上
代码实现:
训练集:

测试集:

则后剪枝代码为:
# 后剪枝
def post_prunning(tree , test_data , test_label , names):newTree = tree.copy() #copy是浅拷贝names = np.asarray(names)# 取决策节点的名称 即特征的名称featName = list(tree.keys())[0]# 取特征的列featCol = np.argwhere(names == featName)[0][0]names = np.delete(names, [featCol]) #删掉使用过的特征newTree[featName] = tree[featName].copy() #取值featValueDict = newTree[featName] #当前特征下面的取值情况featPreLabel = featValueDict.pop("prun_label") #如果当前节点剪枝的话是什么标签,并删除_vpdl# 分割测试数据 如果有数据 则进行测试或递归调用:split_data = drop_exist_feature(test_data,featName) #删除该特征,按照该特征的取值重新划分数据split_data = dict(split_data)for featValue in featValueDict.keys(): #每个特征的值if type(featValueDict[featValue]) == dict: #如果下一层还是字典,说明还是子树split_data_feature = split_data[featValue] #特征某个取值的数据,如“脐部”特征值为“凹陷”的数据split_data_lable = split_data[featValue].iloc[:, -1].values# 递归到下一个节点newTree[featName][featValue] = post_prunning(featValueDict[featValue],split_data_feature,split_data_lable,split_data_feature.columns)# 根据准确率判断是否剪枝,注意这里的准确率是到达该节点数据预测正确的准确率,而不是整体数据集的准确率# 因为在修改当前节点时,走到其他节点的数据的预测结果是不变的,所以只需要计算走到当前节点的数据预测对了没有即可ratioPreDivision = equalNums(test_label, featPreLabel) / test_label.size #判断测试集的数据如果剪枝的准确率#计算如果该节点不剪枝的准确率ratioAfterDivision = predict_more(newTree, test_data, test_label)if ratioAfterDivision < ratioPreDivision:newTree = featPreLabel # 返回剪枝结果,其实也就是走到当前节点的数据最多的那一类return newTreeif __name__ == '__main__':#读取数据train_data = pd.read_csv('./train_data.csv')test_data = pd.read_csv('./test_data.csv')test_data_label = test_data.iloc[:, -1].valuesnames = test_data.columnsdicision_Tree = {"脐部": {"prun_label": 1, '凹陷': {'色泽':{"prun_label": 1, '青绿': 1, '乌黑': 1, '浅白': 0}}, '稍凹': {'根蒂':{"prun_label": 1, '稍蜷': {'色泽': {"prun_label": 1, '青绿': 1, '乌黑': {'纹理': {"prun_label": 1, '稍糊': 1, '清晰': 0, '模糊': 1}}, '浅白': 1}}, '蜷缩': 0, '硬挺': 1}}, '平坦': 0}}print('剪枝前的决策树:')print(dicision_Tree)print('剪枝前的测试集准确率: {}'.format(predict_more(dicision_Tree, test_data, test_data_label)))print('-'*20 + '剪枝' + '-'*20)new_tree = post_prunning(dicision_Tree,test_data , test_data_label , names)print('剪枝后的决策树:')print(new_tree)print('剪枝后的测试集准确率: {}'.format(predict_more(new_tree, test_data, test_data_label)))运行结果:
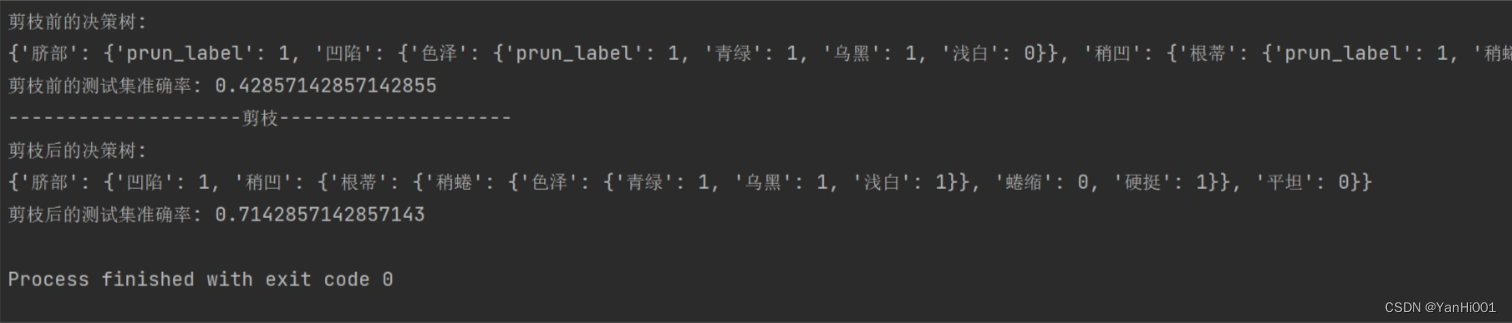
剪枝后决策树不仅更加轻量,而且对于测试集的预测准确率从0.428提升到了0.714
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!