游戏性能新手测试入门指北
一、初识游戏性能
1.1 游戏性能测试是做什么的
游戏性能测试,见其名思其意,就是对游戏进行测试,发现性能问题,分析问题的原因。
什么是性能问题呢?
我们平时玩游戏,发现玩一会游戏手机就开始烫手了,或者某一款大型游戏在手机上玩起来特别的卡顿。这些都属于游戏性能问题。一局话来总结,游戏对性能的需求超过了设备提供的性能(算力)。性能问题包括但不限于卡顿、内存、发热、画质表现。这里的设备包括且不限于手机、PC、VR、switch、AR设备等等。
那么为什么要进行游戏测试,去发现性能问题呢,并推动程序去解决性能问题呢?
做好游戏的性能优化,可以有以下好处:
- 让游戏玩起来更流畅。这关乎到玩家的体验感。
- 更好的画质表现空间,游戏的CPU、GPU、内存优化应该是相辅相成的,如果可以在优化程序上多下功夫,给美术留下更高的空间,会使得画面表现更好,能够极大的提升玩家的体验。
- 提升机型覆盖率 这一点不难理解,我们经常听到某一款3A大作出现,玩家显卡太差玩不了游戏的情况,如果可以做好设备分析,做好性能优化和性能下探,能让更多换不起显卡的玩家也能进行游戏,这与游戏的营收强相关。
1.2 游戏性能测试基本指标
“设备烫手”、“画面太卡”、“玩起来不流畅”等词汇对性能问题的描述过于笼统。我们需要将性能问题进行量化,这就引申出了大量描述性能问题的指标。接下来我们会一一介绍这些指标。
各大游戏公司基本都有自己做的基础性能指标采集工具。腾讯有perfdog、网易有Airperf、字节有Gameperf、华为有System Profiler。本文主要以面向市场的perfdog为例,对基础性能指标做一个简单的介绍。
- 帧率
定义:一定时间内屏幕显示画面的数量,是衡量流畅性的重要指标。
这里的画面也可以直接理解为图片。当物体快速运动时,人眼看到的影像消失后迷人眼仍能继续保留其影像1/24S左右的图像,这就是电影都是24帧/S的原因。
- 帧耗时
定义:帧耗时就是每一帧的耗时。是衡量卡顿的重要指标。对于60帧/S的画面,1S=1000ms/60=16.66ms。60帧/S的情况下帧耗时就是16.66ms。
- CPU占用率
CPU:Central Processing Unit(中央处理单元)。主要用于复杂的逻辑计算以及提交渲染任给GPU。
CPU占用率。即在实际工作频率下,CPU执行任务的总时间/CPU总时间。
- CPU频率
CPU频率是指CPU的时钟速度,以赫兹(Hz)为单位。
时钟速度(Clock Speed)是计算机处理器内部的时钟在一秒内发出的信号次数,通常与处理器的性能有关。
在计算机中,CPU执行的每条指令都会有一个预定的时间间隔,这个时间间隔被称为CPU的“时钟周期”(Clock Cycle),或者“时钟频率”(Clock Frequency)。CPU的时钟速度就是以这个频率来度量的。
CPU频率的高低,对计算机性能的影响很大,越高的时钟速度意味着计算机可以在同样的时间内执行更多的指令。即CPU频率越高性能越好。但是,并非所有的CPU都在相同的时钟频率下工作,例如,有些CPU(如服务器CPU)的工作频率远低于消费级CPU,但是这些服务器CPU会利用大量的超标量(Superscalar)、超线程(Hyper-Threading)等技术,来实现更高的处理能力。
- GPU占用率
即在实际工作频率下,GPU执行任务的时间/GPU总时间。
- GPU频率
GPU频率是指GPU核心(图形处理器)的运行频率。它是GPU的核心频率,用于衡量GPU处理数据的速度。GPU频率越快,性能越强。就像CPU的主频一样,
- CPU/GPU占用率与频率之间的关系
硬件的频率大小决定了硬件的性能和运算速度,那么我们可以把频率进行拟人。
某个施工队每次施工可以使用的人力为50~100人,对应硬件频率的0.5~1GHz。
某次施工任务,施工队实际到施工现场的人数70人,对应硬件频率的0.7GHz。
施工时,发现工程量较小,到场70人过多,实际上进行施工的人数为35人,占用了到场人数的50%,对应硬件的CPU/GPU占用率:50%。
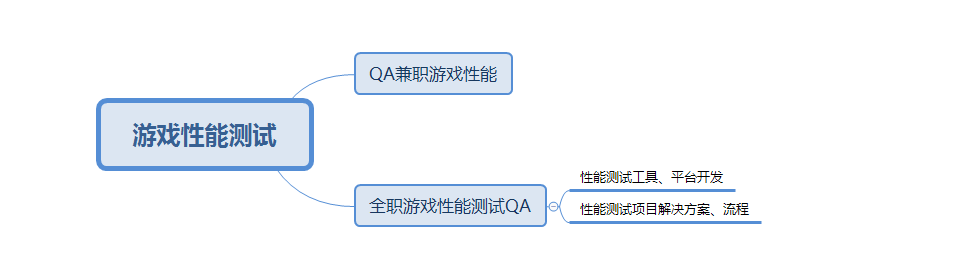
1.3 游戏性能测试岗位的工作内容及发展
先说结论,不建议做全职的游戏性能测试。
目前国内除了少数几个公司存在全职游戏性能测试岗位外。大部分公司都是QA兼职执行数据采集,程序来研究数据并进行优化。
目前全职的游戏性能测试QA除网易腾讯等几个大厂外,基本都是外包。工作内容大多是执行性工作,没有太大的职业发展和技能提升。
少数公司存在程序转行的性能优化岗,主要是做性能测试工具开发,性能测试监控流程建设,性能测试综合平台开发。
性能测试是一个综合性要求很高的岗位,你需要懂引擎原理,懂美术资源,懂渲染,懂gameplay。除非你是程序转行来做解决方案的专家,如果从游戏性能测试入行,只会杂而不精,投入到事务性的执行中去,很难有更多的提升。
1.4.游戏性能测试工具链简单介绍
| 工具名称 | 工具作用 | 适用设备 | 下载链接 | 备注 |
| Renderdoc | 分析渲染流程、定位渲染瓶颈 | windows、Android | Renderdoc | |
| Frame Profiler | 分析渲染流程、定位渲染瓶颈 | windows、Android | Frame Profiler | 华为版renderdoc,在Renderdoc上进行二次开发 |
| Snapdragon Profiler | 高通官方移动设备性能分析工具 | 高通芯片的Android设备 | Snapdragon Profiler | |
| Intel GraphicsPerformance Analyzer | Inter官方性能分析工具 | Inter芯片的Windows设备 | GPA | |
| NVIDIA Nsight Systems | 类似于PC版的systrace | PC | NVIDIA Nsight Systems | NVIDIA 开发者 | |
| NVIDIA Nsight Graphics | PC截帧工具 | PC | NVIDIA Nsight Graphics User Guide | |
| Arm MS Graphics Analyzer | Arm GPU设备截帧工具 | Arm GPU的设备 | Graphics Analyzer | Arm Learning Paths | |
| System Profiler | 华为出品的基础数据采集工具 | 华为系Android设备 | UI Elements-Offline Tracing with System Profiler-Graphics Profiler | HUAWEI Developers | |
| systrace | 用于检查CPU线程调度,初步判性能瓶颈是在CPU还是GPU上的工具 | Anroid设备 | https://developer.android.com/topic/performance/tracing?hl=zh-cn | |
| Unreal Insight | UE引擎官方的性能Profiler工具 | UE引擎游戏 | Unreal Insights介绍 | 虚幻引擎文档 (unrealengine.com) | |
| Unity Profiler | Unity引擎官方的性能Profiler工具 | unity引擎游戏 | Unity - Manual: The Profiler window | |
| Unity Memoryprofiler | Unity官方的内存镜像采集工具 | unity引擎游戏 | Memory Profiler 模块 - Unity 手册 | |
| UPR | unity官方的性能测试监控平台 | unity引擎游戏 | UPR - Unity专业性能优化工具 | |
| Xcode | 苹果官方开发工具,可用于截帧、内存Alloc采集、CPUGPU消耗分析、带宽采集等等。 | ios | Xcode 15 - Apple Developer | |
| PerfDog/AirPerf/GamePerf | 基础性能数据采集工具 | 通用 | PerfDog | 全平台性能测试分析专家 (qq.com) | |
| Simpleperf | Android 官方CPU性能采集工具 | Anroid设备 | https://developer.android.com/ndk/guides/simpleperf?hl=zh-cn | |
| Loli Profiler | Android Native内存Profile工具 | Anroid设备 | GitHub - Tencent/loli_profiler: Memory instrumentation tool for android app&game developers. | |
| Wwise客户端 | 用wwise的官方Profile工具 | 通用 | https://www.audiokinetic.com/zh/products/wwise/ |
二、游戏渲染基础知识
Arm GPU 架构介绍
1.1、TB(D)R架构
1.1.1 IMR架构(Immediate Mode Rendering)
IMR架构就是桌面端的GPU架构,每一个绘图的指令来到显卡,每一次渲染API的调用,都会直接绘制图像对象,从头到尾跑完整个渲染管线,最终将结果输入到Frame Buffer中。因此,每一次物体颜色和深度的渲染,都要读写Frame Buffer和Depth Buffer。

下图为IMR架构渲染流程。
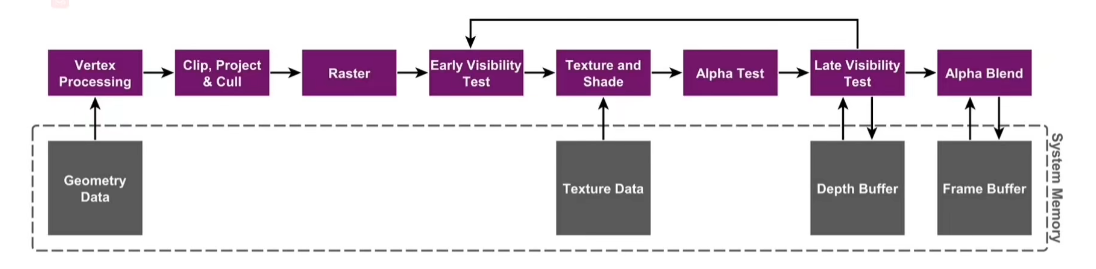
上半部分为Render pipeline(渲染管线)。
下半部分为显存的数据:几何数据,纹理贴图数据、Depth Buffer(深度缓冲)、Frame Buffer。
IMR架构存在一个问题,在开启深度测试后每一个Fragment的输出都需要和Depth Buffer中的深度值进行深度测试,通过测试则需要更新Depth Buffer和Frame Buffer。
整个过程包含对System Memory的一次读取和两次写入,然而Fragment数量巨大,这就带来了很大的访问System Memory的压力。IMR的解决办法是给GPU配备足够大的缓存和足够大的带宽。
为了容下更多的缓存就需要越来越大的主板,而频繁的带宽访问会造成功耗大量增加导致发热。
然而,在规格尺寸及功耗较低的移动端,IMR架构的功耗显然不是能够被接受的。
因此,为了降低移动端的带宽,减少功耗,TB(D)R架构应运而生。
1.1.2 TBR架构
TB(D)R(Tile-Based(Deferred)Rendering)是目前主流的移动GPU渲染架构。
简单理解TB(D)R:屏幕被分块(16×16或者32×32)渲染:
TBR:VS-Defer-RS-PS
TBDR:VS-Defer-RS-Defer-PS
Defer:字面意思为延迟,从渲染数据的角度来看,defer就是“阻塞+批处理”GPU的“一帧”的多个数据,然后一起处理。
在渲染时,直接渲染对象不再是当前的Frame Buffer和Depth Buffer(深度缓冲),而是Tile Buffer的高速缓存。从而将IMR中对Color/Depth Buffer进行的读写操作改为对GPU中告诉内存的读写操作。如下图所示:
最上面一层:Render Pipeline(渲染管线)
中间一层:On-Chip Buffer(片上内存,Tiled Frame Buffer &Tiled Depth Buffer)
最下一层:系统内存,CPU、GPU共享。
Primitive List:
固定长度数组,长度为tile的数量
数组中,每个元素是一个linked list,存的是和当前tile香蕉的所有三角形的指针,指针指向Vertex Date。
Vertex Date:
存放顶点和顶点属性数据。

TBR渲染流程:
第一阶段:几何处理阶段:
首先,从内存中读取Geometry date,经过Vertex shading阶段先将顶点信息进行着色。
接下来将整个大的画面切成一个个的Tile/bin,在此阶段会判断每个Tile与哪些三角面有关。确定好后将信息存回到内存中。当所有Primitives分类储存后,fragment shading才会启动。
第二阶段Resterization(光栅化),以Tile为单位执行
Rasterization(光栅化)会等所有的三角形完成第一阶段(几何处理阶段),才会进入第二阶段。它会从Primitive quchu tile的三角形列表,然后根据列表对当前tile的所有三角形进行光栅化以及顶点属性的插值。
第三阶段:像素着色,以Tile为单位执行。因为Deferred Rendering只需要读取当前像素的几何信息进行着色,因此场景仍可以使用deferred(延迟渲染)一个Tile一个Tile的处理其中的像素。
1.1.3 TBDR架构
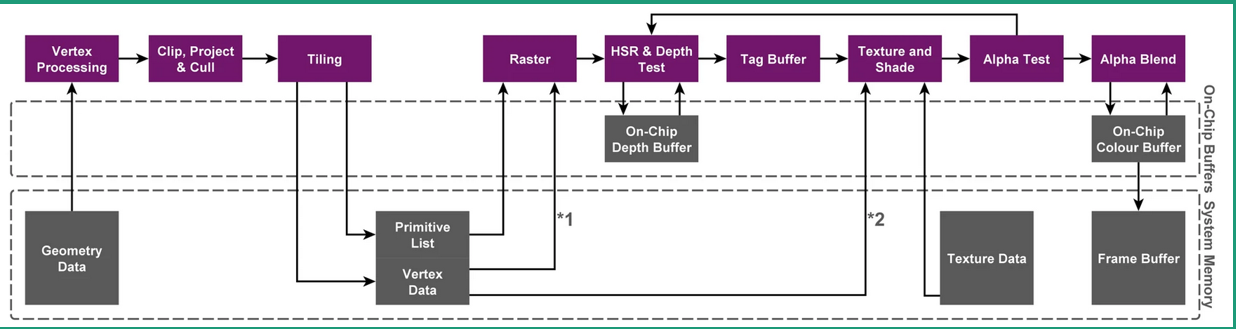
TB(D)R架构的两个渲染阶段:
TBDR再TBR的基础上,通过硬件层面的特性HSR(隐藏面消除)解决了Overdraw问题。
如上图所示,相比TBR,TBDR 多了一个HSR和TagBuffer,HSR为PowerVR独有的特性,再硬件上减少Overdraw。
HSR原理:
每个fragment,通过了Early Z Test后,先不绘制,而是HSR阶段读取primitive list,标记该像素由哪个图元绘制。
HSR(隐藏面消除)读取片上的Depth Buffer(深度缓冲),以判断该由哪个图元绘制。等这个Tile上所有的图元处理完成,只记录通过Early Z Test的那个图元。
在Fragment Shader(偏远着色器)绘制时,只绘制标记这个像素点,最终通过Early Z Test的那个fragment
可以理解为:虚拟出一个射线,遇到第一个不透明的三角形停下,只渲染最近的不透明和最近的透明对象,余下的偏远会被剔除不进行渲染。
1.1.4 TBDR架构的优缺点
TBDR架构的deferred,给消除Overdraw提供了机会,
TBDR核心是为了降低带宽、减少功耗。实际渲染帧率并不快。
TBDR优点:
(1)TBR给消除Overdraw提供了机会,Power使用了HSR技术,Mail使用了Forward Pixel Killing技术,目标一样,就是要最大限度减少被遮挡Pixel的Texturing和shading。
(2)TBR主要是Catched friendly,在cache里头的速度要比全局内存的速度快的多,以降低帧率的代价,降低带宽,省电。
缺点:
(1)Binning操作需要在vertex阶段之后,将输出的几何数据写入到DDR,然后才被fragment shader 读取。几何数据过多的管线,容易在此处出现性能瓶颈。
(2)如果某些三角形叠加在数个图块(Overdraw),则需要绘制数次,这意味着总渲染时间会高于即时渲染模式。
不同GPU的Early-DT/第二个defer
Android:
高通采用外置模块LRZ。在正常渲染管钱前,先多执行一次VS生成低精度depth texture,以剔除之前不可见的三角形。就是直接用硬件做occlusion culling,功能类似于软光栅遮挡剔除。
Arm Mail采用 Forward Pixel Kill技术来剔除远处物体。
iOS:
PowerVR 采用内置模块HSR(隐形面剔除)。修改原渲染管线架构,增强rasterizer硬件模块为HSR。
虚拟出一个射线,遇到第一个不透明的三角形停下,只渲染最近的不透明和最近的透明对象,余下的偏远会被剔除不进行渲染。
1.2.以Mali GPU为例解读GPU指标
1.2.1 Mail GPU performance counters
Job:=GPU实际执行的单位,存在两种类型:
Non-fragment job:vertex shading,tiling,compute shading
Fragment job:fragment shading
Job manager有两个job slots:可以同时处理non-fragment & fragment job
GPU active即GPU time。
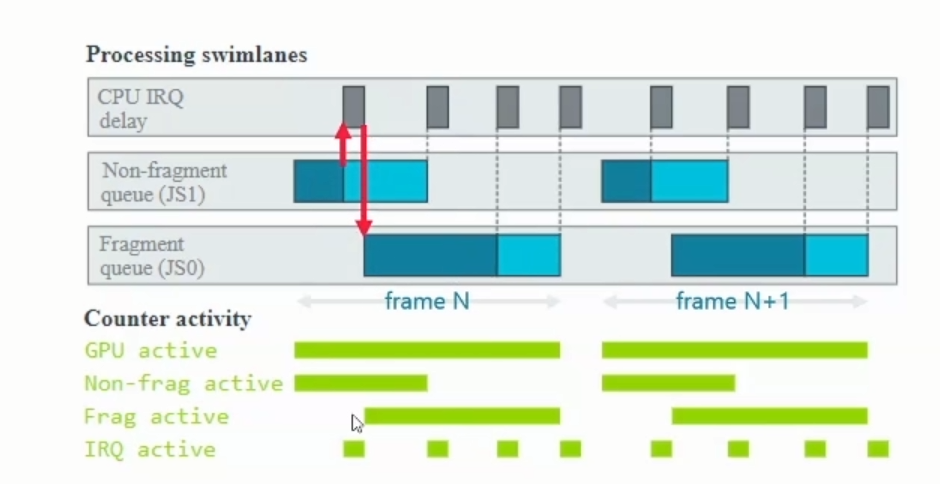
GPU performence指标解读:
下图为Mali-G77 perf.counter
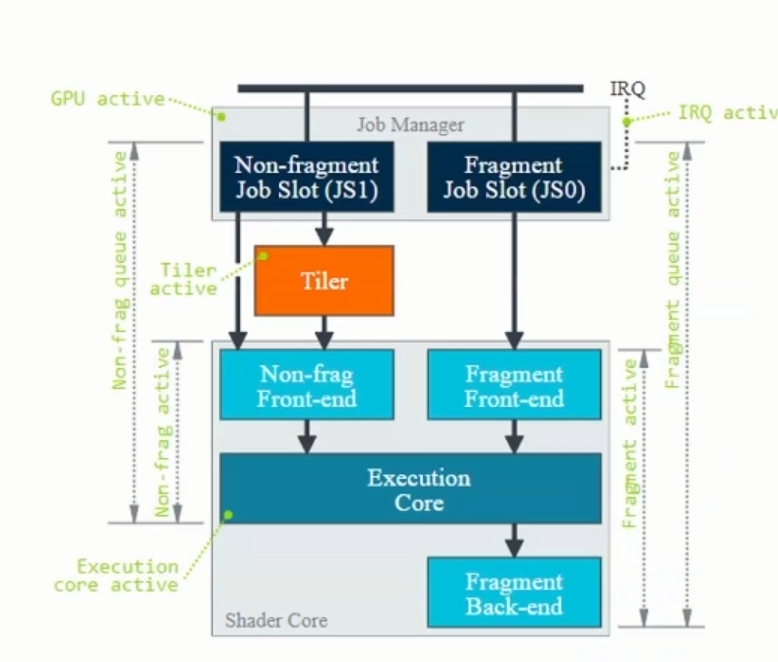
Fragment Front-end
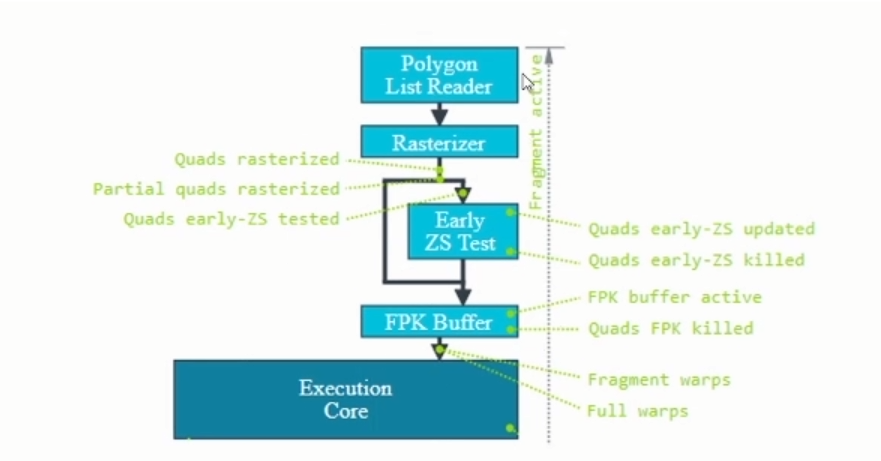
当Primitive rasterize后,会产生许多以2*2fragment为单位的Quads。
shader内dFdx,dFdy的计算便是依赖quad的结构
partial quad:=该quad有人一个fragment不在primitive内部。在符合某些条件下(no discard:alpha to coverage,no depth write in shader,no blending)。

FPK(mali架构特有):Forward Pixel Kill
在render opaque fragments的情况下,当quad在FPK buffer排队等待进入Execution core执行时,会再根据新进quad的ZS状态剔除前面排队的quad。(类似于HSR,即不透明绘制时绘制最后进入quad的内容。)
接着每4个quads(数量依架构不同),会在组成一个warp,排进queque等待执行。此时一个warp内有16个单元会进行平行运算,概念上可视为16 threads,每个thread在同一时间是执行一样的指令,但是处理的资料会不同。
在执行fragment shader时,每个thread对应一个fragment,且同一warp内的fragments不一定都来自于同一个primitive,在执行vertex shader时,每个thread则是对应于一个vertex。

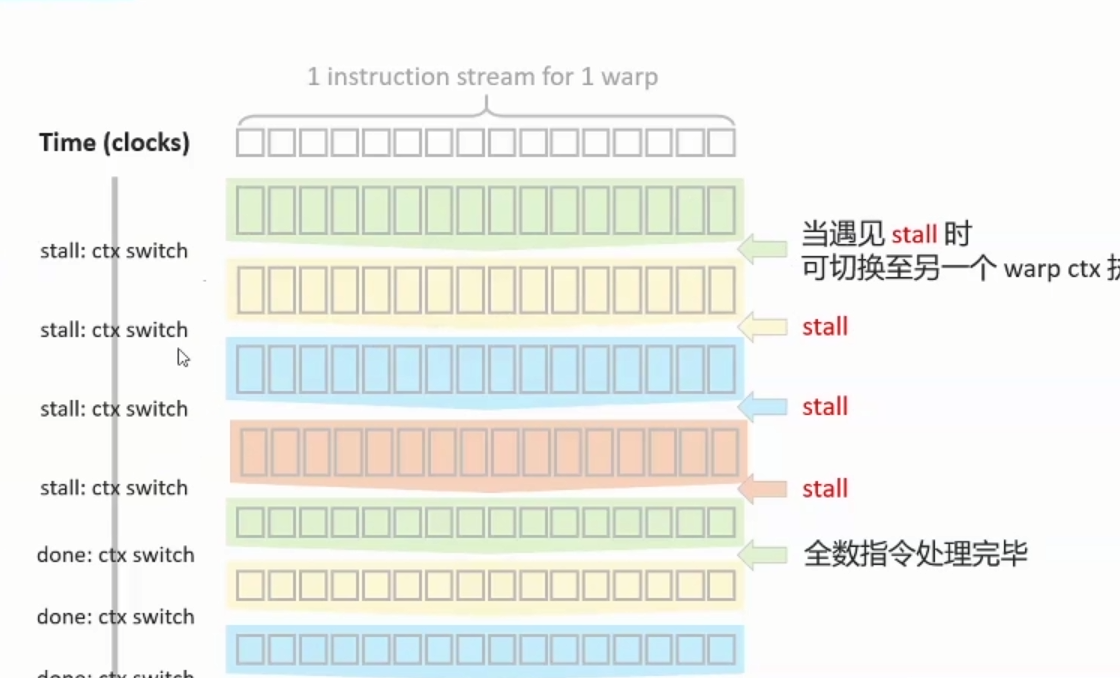
Warp的排程与执行:
假设
1.我们一次只能执行一个instruction stream
2.根据shader registers的用量,目前只能分配给4 active warps使用,
若shader使用过多registers,能同时执行的thread数量会降低,active warps数量会降低,遇到stall时,可替换的选择性变少,hide latency能力降低
(若Mail-G77shader使用超过32registers,thread数量会从1024降成512(64to32warps)。
Execution core:
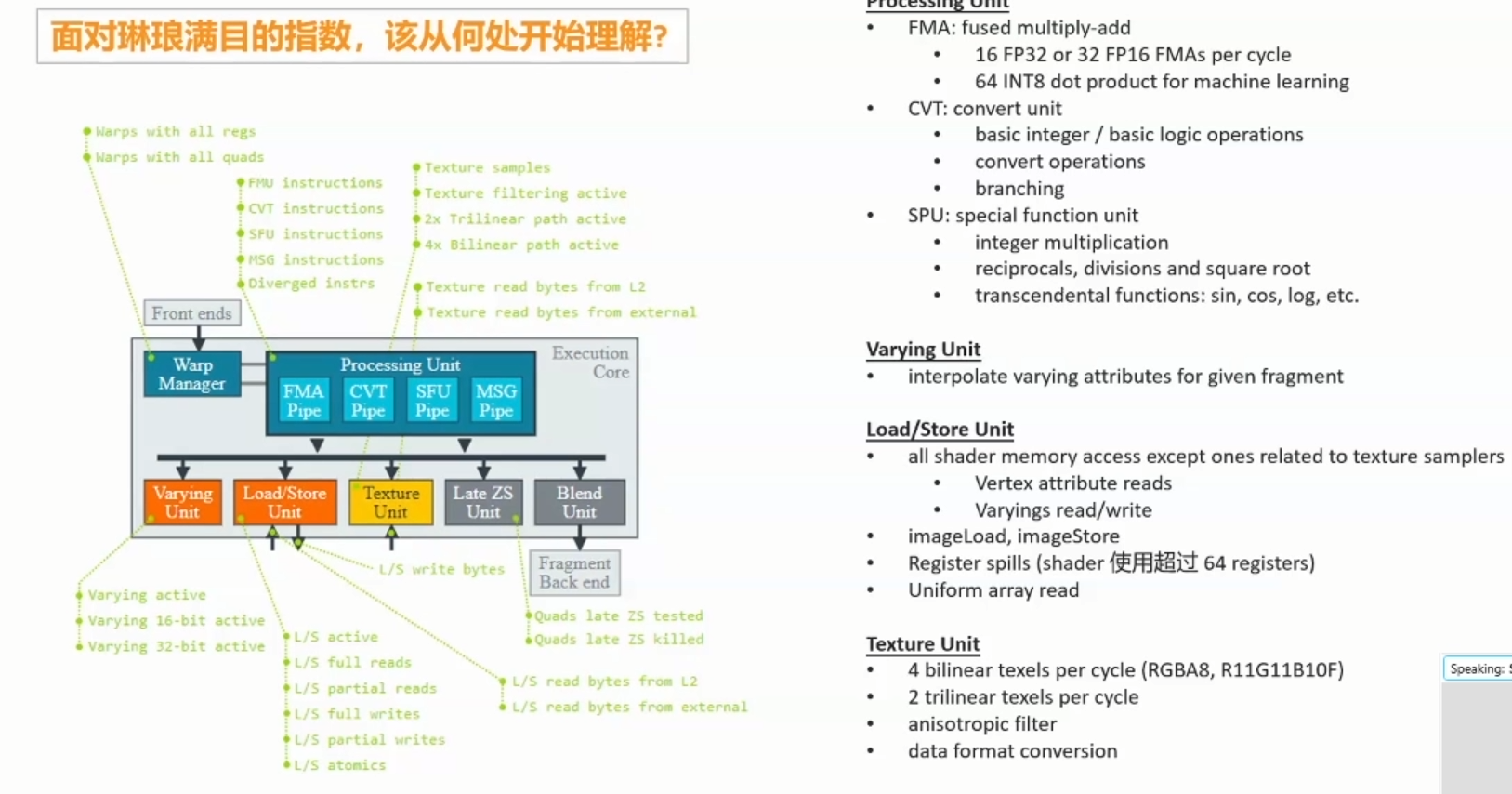
1.2.2 Fragment指标
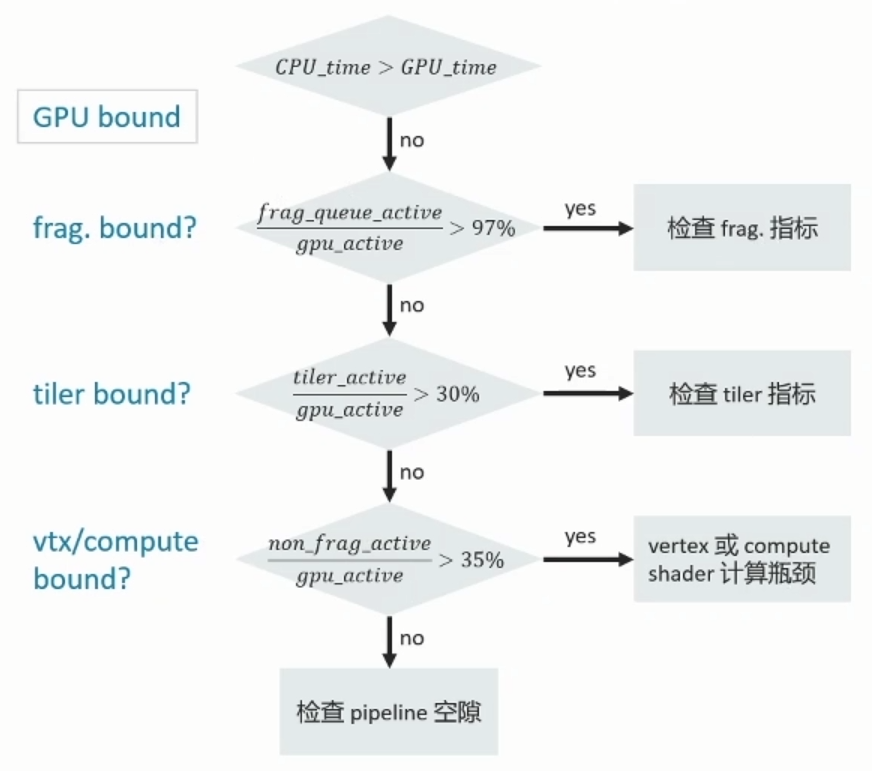
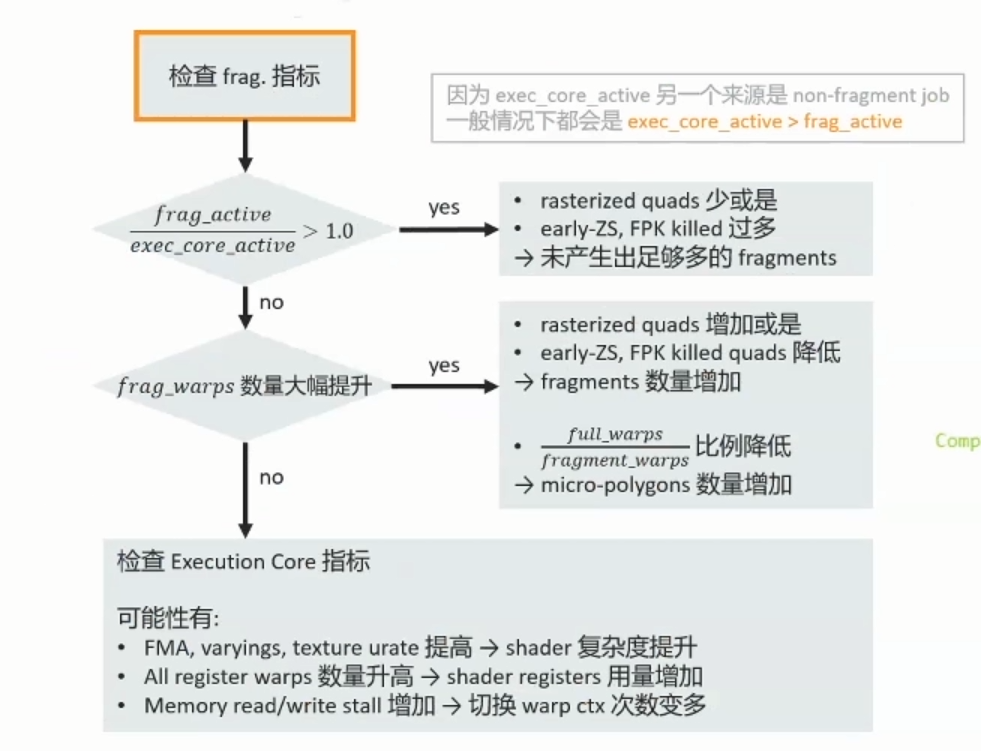
1.2.3 Tiling指标
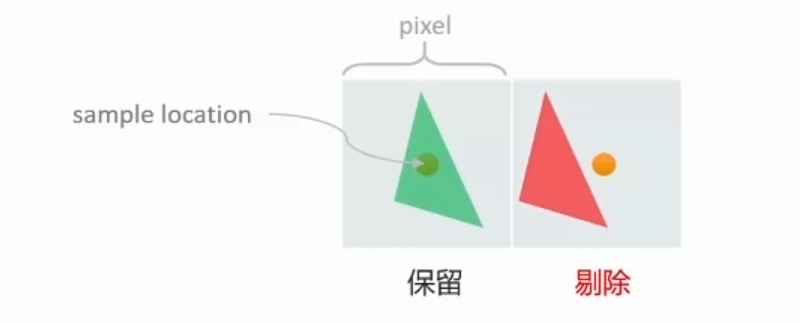
Tiler culling的单位是Primitive
Facing test culling在一般3D rendering大约会在50%。
Micro geotmetry problem:sample_test_culled rate 超过10%
当primitive在image Plane所投影之范围未包含任何一个Pixel sample时,会遭到剔除。
当此问题发生时,建议制作geometry LOD 或是CPU software object culling。
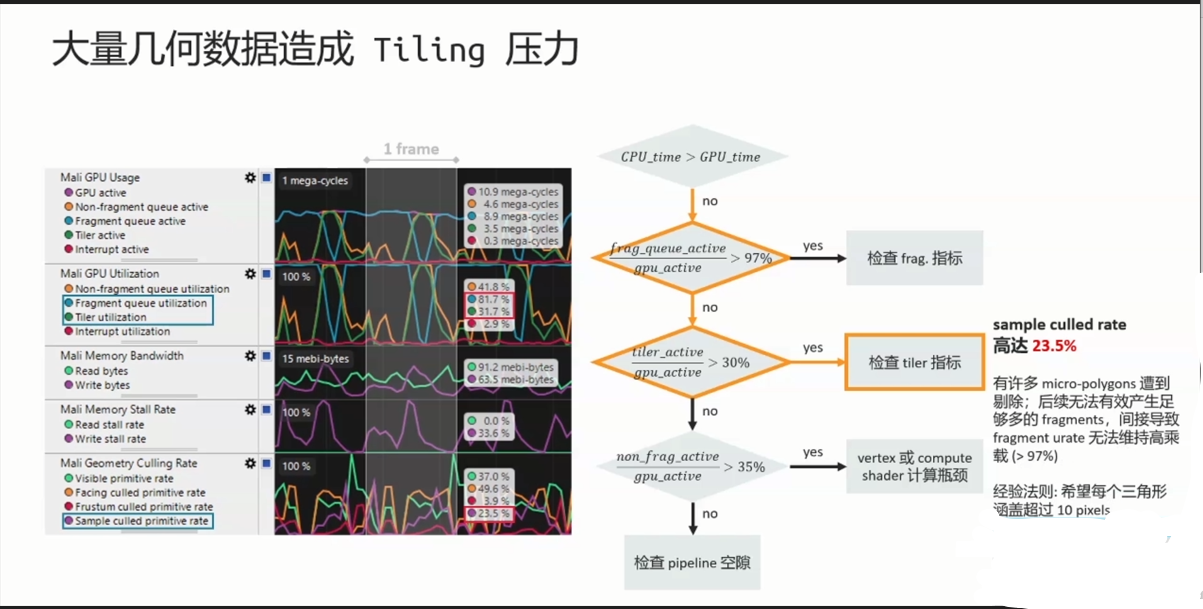
注意:请留意每个pipeline stage处理单位:Tiler culling:primitive;Early-ZS culling:quad;Execution core:warp
渲染管线
帧渲染流程
三、游戏美术资源基础
四、游戏开发基础
五、游戏引擎基础
待续......
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!