Python+selenium获取BOSS招聘信息最新
久了没有动,感觉挺难受的,听过各大网站都加强了反爬措施,今天来试试BOSS
直接selenium搞起,这不还真遇到了问题
一经查看原来是增加了selenium检测啊
还难不倒我,配置浏览器设置参数即可解决
直接上代码
# -*- coding:utf-8 -*-
'''
BOSS招聘爬取
'''from selenium import webdriver
import csv
import requests
from lxml import etreeclass BossSpider:def __init__(self):self.options = webdriver.ChromeOptions()# 绕过网站检测爬虫self.options.add_experimental_option('excludeSwitches', ['enable-automation'])# 不加载图片self.options.add_argument('blink-settings=imagesEnabled=false')self.driver = webdriver.Chrome(options=self.options)self.url = 'https://www.zhipin.com/job_detail/?query=Python&city=101270100&industry=&position='def Save_csv(self,data):if data:with open('position.csv', 'a', newline='') as f:f_csv = csv.writer(f)f_csv.writerow(data)def Parse_html(self, html):# with open('html.txt', 'a', encoding='utf-8') as f:# f.write(html)source = etree.HTML(html)for i in range(1,31,1):link = source.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]//div[@class="info-primary"]//a/@href'.format(i))salary = source.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]//div[@class="job-limit clearfix"]/span/text()'.format(i))education = source.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]//div[@class="job-limit clearfix"]/p/text()'.format(i))company = source.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]//div[@class="company-text"]/h3/a/text()'.format(i))title = source.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[1]/div[1]/div/div[1]/span[1]/a/@title'.format(i))position =company+title+salary+educationprint(position)self.Save_csv(position)def run(self):for i in range(1,10,1):self.url = 'https://www.zhipin.com/c101270100/?query=C语言&page={}'.format(i)self.driver.get(self.url)html = self.driver.page_source# html = open('html.txt', 'r', encoding='utf-8').read()self.Parse_html(html)# self.driver.close()def __del__(self):self.driver.close()if __name__ == '__main__':spider = BossSpider()spider.run()大功告成
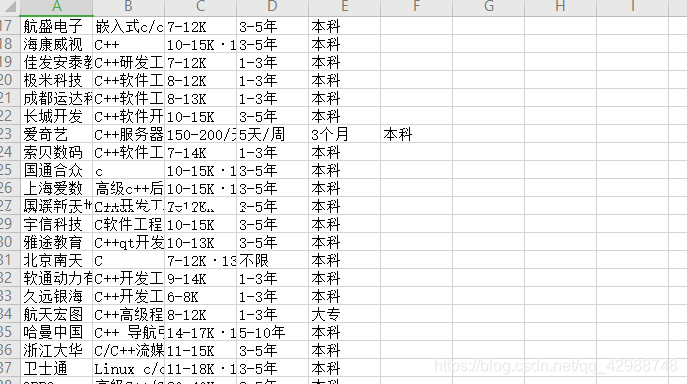
最终保存CSV本地
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!