MobileNet 进化史: 从 V1 到 V3(V3篇)
MobileNet 进化史: 从 V1 到 V3(V3篇)
这部分内容总共由如下 3 篇文章构成。
- MobileNet 进化史: 从 V1 到 V3(V1篇)
- MobileNet 进化史: 从 V1 到 V3(V2篇)
- MobileNet 进化史: 从 V1 到 V3(V3篇)
- MobileNet实战:基于 MobileNet 的人脸表情分类
1. 前言
V3 保持了一年一更的节奏,Andrew G. Howard 等于 2019 年又提出了 MobileNet V3。文中提出了两个网络模型, MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。具体可以参考原始论文 Searching for MobileNetV3。
这回的标题(Searching for MobileNetV3)说的不是 V3 里面有什么,而是说的 V3 是怎么来的。Searching 说的是网络架构搜索(NAS),即 V3 是通过搜索和网络优化而来。
这里我们并不讨论 V3 是如何得来的(其实这本来是论文的一大亮点,但是因为根本没有玩过。。。),仅仅是对 V3 网络本身进行总结。
2. 对 V2 最后几层的修改
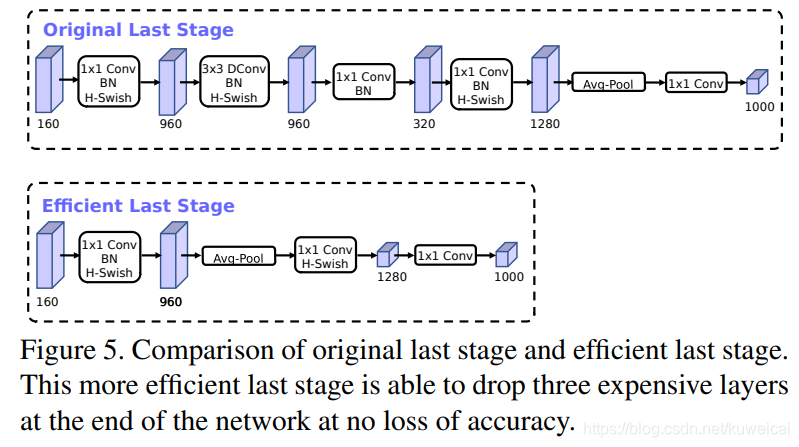
作者发现 V2 网络最后一部分,用 1x1 的网络来提供 feature 的维度,从而提高预测的精度,但是这一部分也会造成一定的延时,为了减少延时,作者把 average pooling 提前,这样的话,这样就提前把 feature 的 size 减下来了(pooling 之后 feature size 从 7x7 降到了 1x1)。这样一来延时减小了,但是试验证明精度却几乎没有降低。
3. h-swish
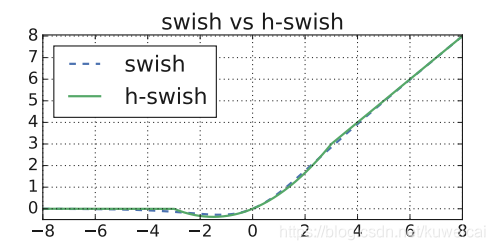
这个得先说说 swish(也是 google 自家人搞出来的),说是这个激活函数好用,替换 ReLU 可以提高精度,但是这个激活函数(主要是 σ ( x ) \sigma(x) σ(x) 部分)在移动端设备上显得太耗资源,所以作者又提出了一个新的 h-swish 激活函数来取代 swish,效果跟 swish 差不多,但是计算量却大大减少。
s w i s h x = x ∗ σ ( x ) h − s w i s h [ x ] = x R e L U 6 ( x + 3 ) 6 \begin{aligned} swish x &= x * \sigma(x) \\ h-swish[x] &= x \frac{ReLU6(x+3)}{6} \end{aligned} swishxh−swish[x]=x∗σ(x)=x6ReLU6(x+3)
4. squeeze-and-excite(SE)
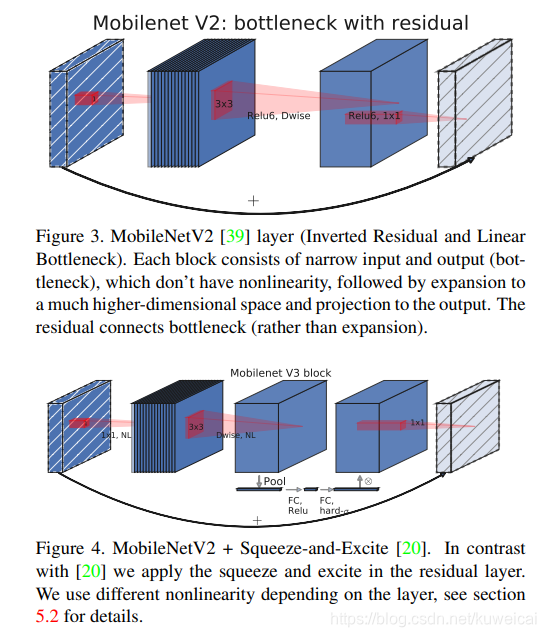
下面这张图可以看出 V3 中增加了 SE 结构(关于 SE 结构可以参考 CV 经典主干网络 (Backbone) 系列: SENet),并且将含有 SE 结构部分的 expand layer 的 channel 数减少(为原来的 1/4 以减少延迟,但是时间查看模型,貌似只是减少了1/2),试验发现这样不仅提高了模型精度,而且整体上延迟也并没有增加。
5. 减少 channel
对比 V3 和 V2 还可以发现模型开始的 conv2d 部分的输出 size 减少为原来的一般了,试验发现延迟有所降低,精度没有下降。
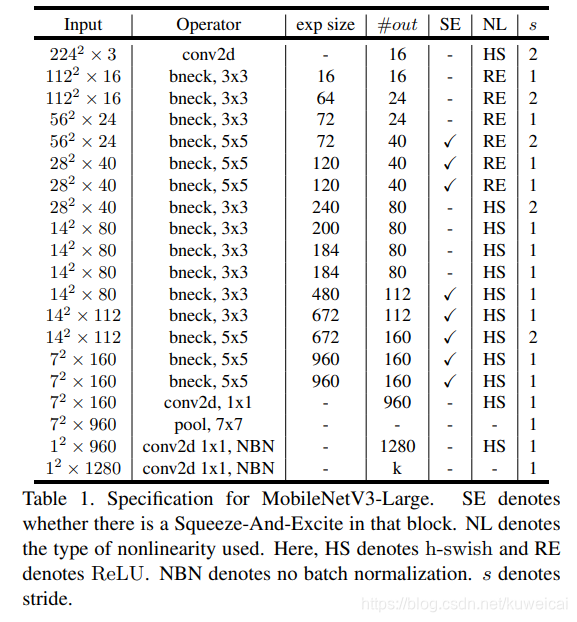
6. MobileNet V3
MobileNet V3 基于 caffe 的模型可以参考 caffe-mobilenet-v3.
下面分别是 small 和 large 版本的模型示意图。
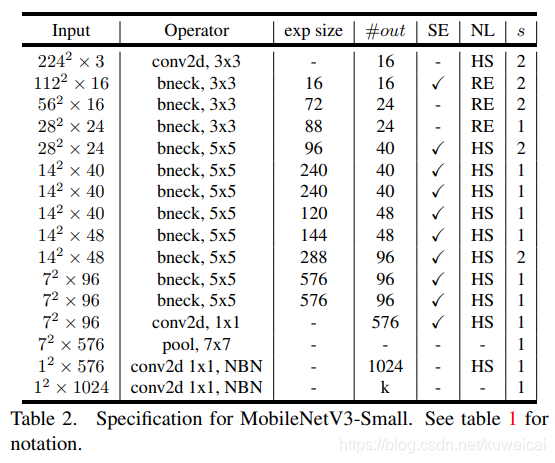
7. 效果
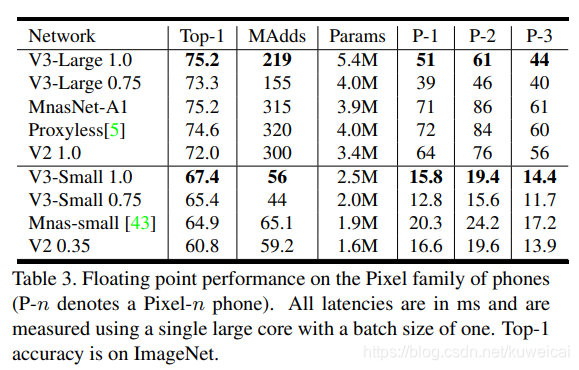
相比 V2 1.0 来说, V3-Small 和 V3-Large 在性能和精度上各有优势。但是在工程实际中,特别是在移动端上 V2 用的更为广泛,因为 V2 结构更简单,移植更方便,速度也更有优势。
参考
-轻量级神经网络MobileNet,从V1到V3
-mobilenet系列之又一新成员—mobilenet-v3
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!