leetcode,es热词更新和词频统计
777. 在LR字符串中交换相邻字符
我觉得这道题的题解是找规律。
XL->LX,RX->XR
如果X的右边是L,则x右移一位,L左移一位;如果x的左边是R,则R右移一位,x左移一位。除去x,start和end其他字符L、R的相对位置(顺序)不变。而且L在start的位置一定比end的位置大,R在start的位置一定比end的位置小。
RXXLRXRXL
XRLXXRRLX
“XLXRRXXRXX”
“LXXXXXXRRR”
“XXXXXLXXXX”
“LXXXXXXXXX”
“XXXLXXXXXX”
“XXXLXXXXXX”
“LXXLXRLXXL”
“XLLXRXLXLX”
跳过所有的x,看两个字符串是否满足这两条规律,满足则可以变化。
bool canTransform(string start, string end) {int m=start.size(),n=end.size(),i=0,j=0;if(m!=n){return false;}while(i<m&&j<n){while(start[i]=='X'&&i<m){i++;}while(end[j]=='X'&&j<n){j++;}if(i<m&&j<n){if(start[i]!=end[j]){return false;}else{if((start[i]=='L'&&i>=j)||(start[i]=='R'&&j>=i)){i++;j++;}else{return false;}} }}while(i<m){if(start[i]!='X'){return false;}i++;}while(j<n){if(end[j]!='X'){return false;}j++;}return true;}
热词更新
elasticsearch的ik分词器通过配置远程扩展词典和停用词典实现热更新,不用重启es。
首先在elasticsearch/config/analysis-ik/cat IKAnalyzer.cfg.xml配置远程词典,就是一个url地址,可以搭建一个项目访问静态文件,直接在服务器设置默认网站并在文件夹下创建词典也可以。
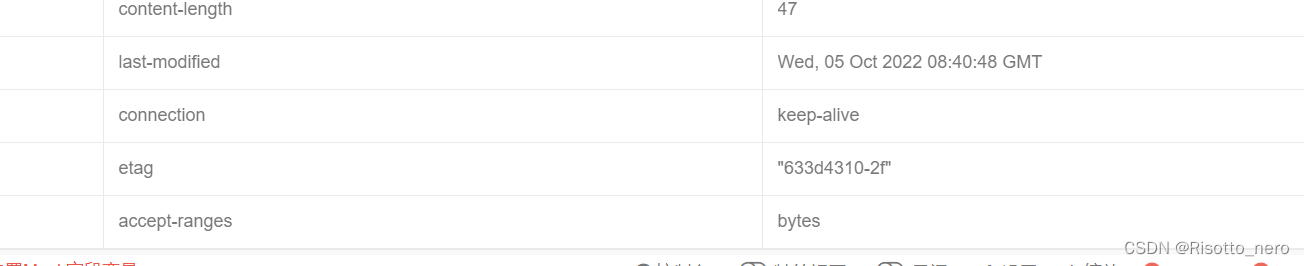
根据ik分词器的介绍,自动更新需要在header中设置两个标识。
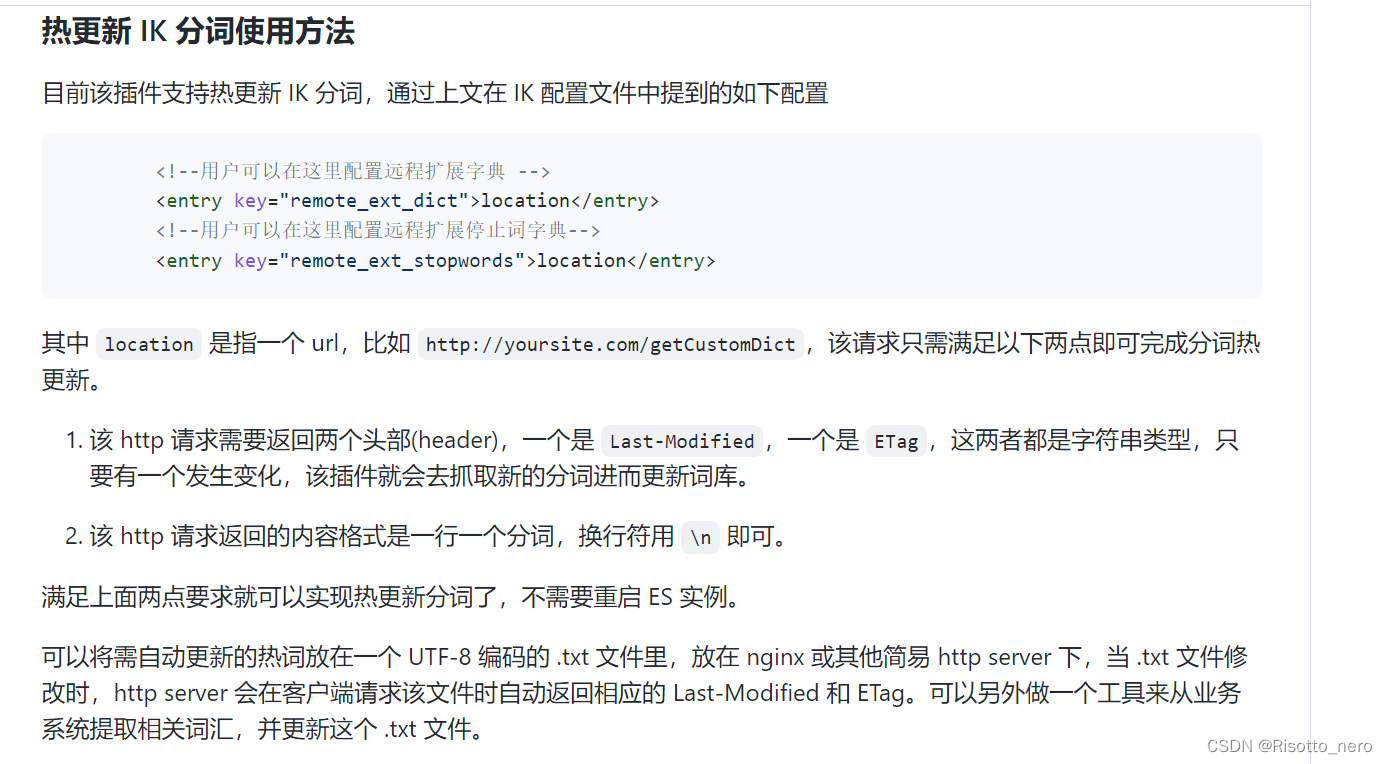
不过浏览器会自动添加,所以可以不做配置。

热词更新
重启es,看到命令行加载了词典里的词就可以。如果遇见乱码,可以看下面的博客。
es中文乱码
用GET http://xxxx:9200/_analyze测试
{"text":["蔡徐坤"],"analyzer":"ik_smart"
}

中文停用词库
因为ik分词词库更新之后,不会对历史数据重新构建索引,因此需要处理。
历史数据更新
因为数据有点多,所以我使用这条命令POST http://xxxx:9200/tieba/_update_by_query?slices=9&refresh&wait_for_completion=false
这样可以不用等待命令执行完毕。
es的词频统计
首先要开启字段的fielddata属性为true。
PUT http://xxxx:9200/tieba/_mapping
{"properties": {"res_content": { "type": "text","analyzer":"ik_smart","fielddata": true}}
}
然后就可以利用es的词频统计功能。
POST http://xxxx:9200/tieba/_search
{"size":0,"aggs":{"messages" : { "terms" : { "size" : 10,"field" : "res_content",} } }
}
返回前十个频率最高的词。
{"took": 155,"timed_out": false,"_shards": {"total": 3,"successful": 3,"skipped": 0,"failed": 0},"hits": {"total": {"value": 414,"relation": "eq"},"max_score": null,"hits": []},"aggregations": {"messages": {"doc_count_error_upper_bound": 24,"sum_other_doc_count": 13596,"buckets": [{"key": "捏","doc_count": 52},{"key": "想","doc_count": 43},{"key": "学校","doc_count": 42},{"key": "学","doc_count": 38},{"key": "专业","doc_count": 36},{"key": "校区","doc_count": 31},{"key": "赢","doc_count": 30},{"key": "专","doc_count": 26},{"key": "同学","doc_count": 25},{"key": "都是","doc_count": 25}]}}
}
可以看到还有许多停用词比如"都是",“捏”,“想”,而且很多单字,效果还是不佳。
leetcode
811. 子域名访问计数
这题不难,但是c++字符串的分割真不如python方便。
字符串转数字stoi
数字转字符串to_string
auto &&,auto &,const auto &
vector<string> subdomainVisits(vector<string>& cpdomains) {map<string,int> m;int n=cpdomains.size(),i=0;vector<string> v;while(i<n){string cur=cpdomains[i++];int space=cur.find(' ');string tmp=cur.substr(space+1);int count=stoi(cur.substr(0,space));m[tmp]+=count;for(int j=0;j<tmp.size();j++){if(tmp[j]=='.'){string t2=tmp.substr(j+1);m[t2]+=count;}}}for(auto p:m){v.push_back(to_string(p.second)+" "+p.first);}return v;}
Django静态文件访问
settings.py文件配置路径
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
MEDIA_URL = "/media/"
urls.py配置路由
from django.urls import path, include, re_path
from sentimentSys import settings
from django.views.static import serve
urlpatterns = [re_path('media/(?P.*)$' , serve, {"document_root": settings.MEDIA_ROOT})
]
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!