深入理解MapReduce
目录
- MapReduce概述(是一个做计算的程序)
- MapReduce原理
- Shuffle过程
- MapReduce执行过程-map阶段
- MapReduce执行过程-reduce阶段
- shell端实现mapreduce
- 准备数据
- 实现mapreduce
- 开始执行
- 查看结果
- Java操作mapreduce
- Java操作mapreduce,指定reduce任务数
- mapreduce程序关联两张表(实现join操作)
- 介于map端与reduce端之间的Combine
- mapreduce程序实现combinue预聚合
MapReduce概述(是一个做计算的程序)
- MapReduce是一种分布式(一个计算逻辑,多个机器去实现)计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
- MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。
- MapReduce框架都有默认实现,用户只需要覆盖(重写)map()和reduce()两个函数,即可实现分布式计算,非常简单。
- 这两个函数的形参和返回值都是
,使用的时候一定要注意构造
MapReduce原理
这里map阶段和reduce阶段的数据格式都有四个
map的前两个保证了数据进来的格式,后两个保证了数据出去的格式(也就是进到reduce的格式)
reduce的前两个保证了数据进来的格式,后两个保证了数据出去的格式(出去到hdfs中)
block块的切分是hdfs切分的
split是mapreduce切分的(默认情况下,两个的大小一致,都是128MB,允许溢出1.1)
一个split就对应这一个Mapper Task
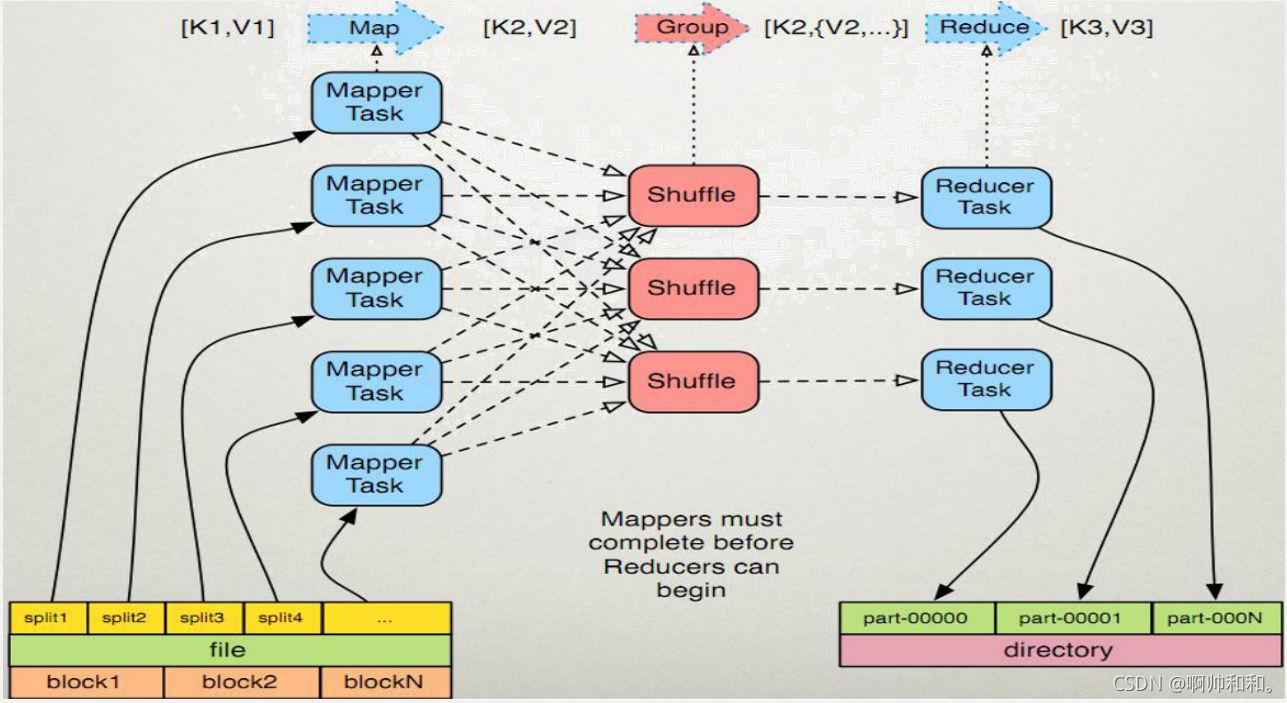
先抛开中间的shuffle不看,过程大致是这样的:(这里面读取数据用的是偏移量,是因为从hdfs读取的是文件,文本形式存储的,key指的就是变量,value指的就是一行一行的数据)
先切分,
再传到map阶段,一个block块对应一个map,
map里面先做一个简单的计算,给需要做计数的单词打上标记
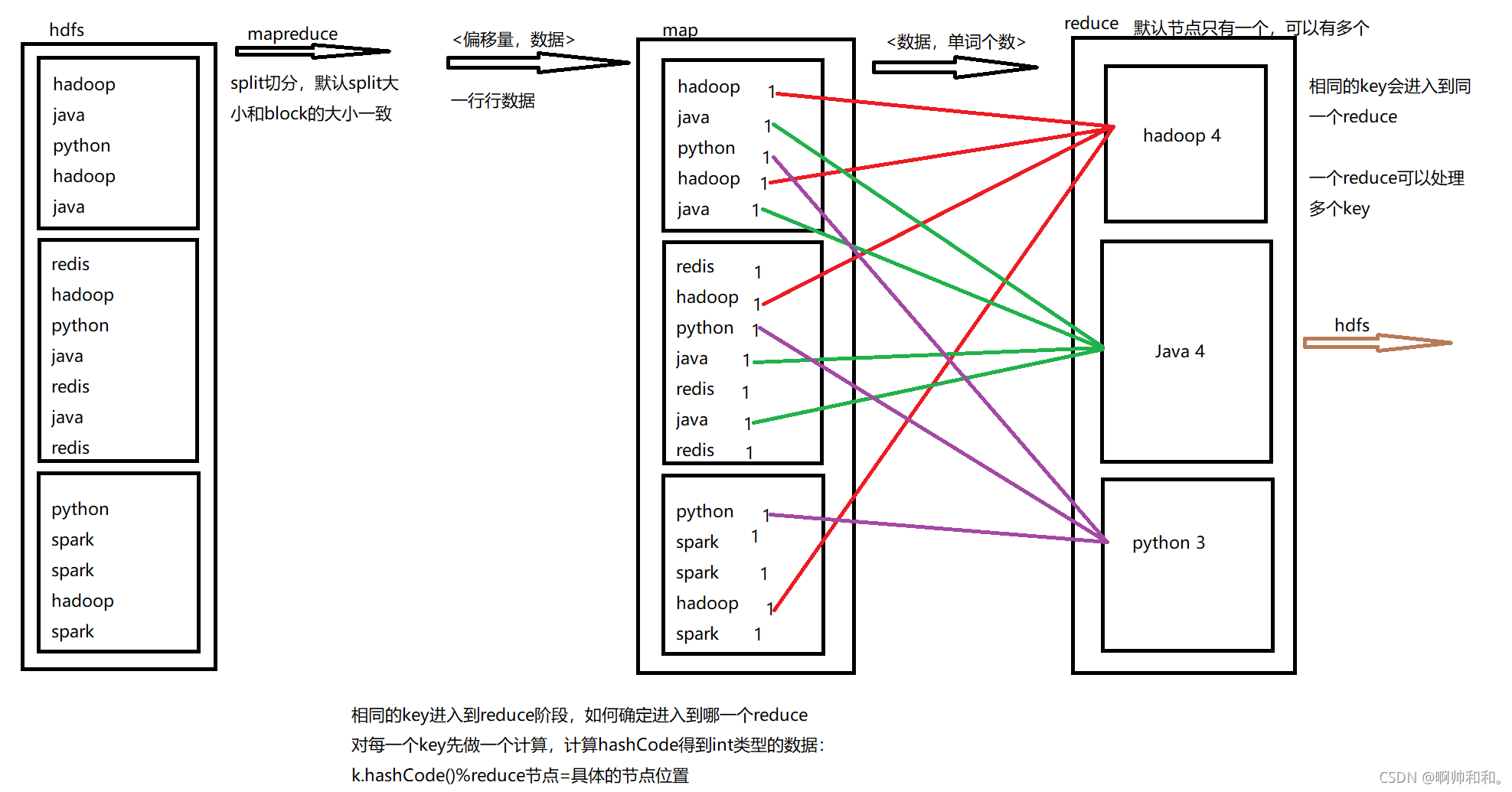
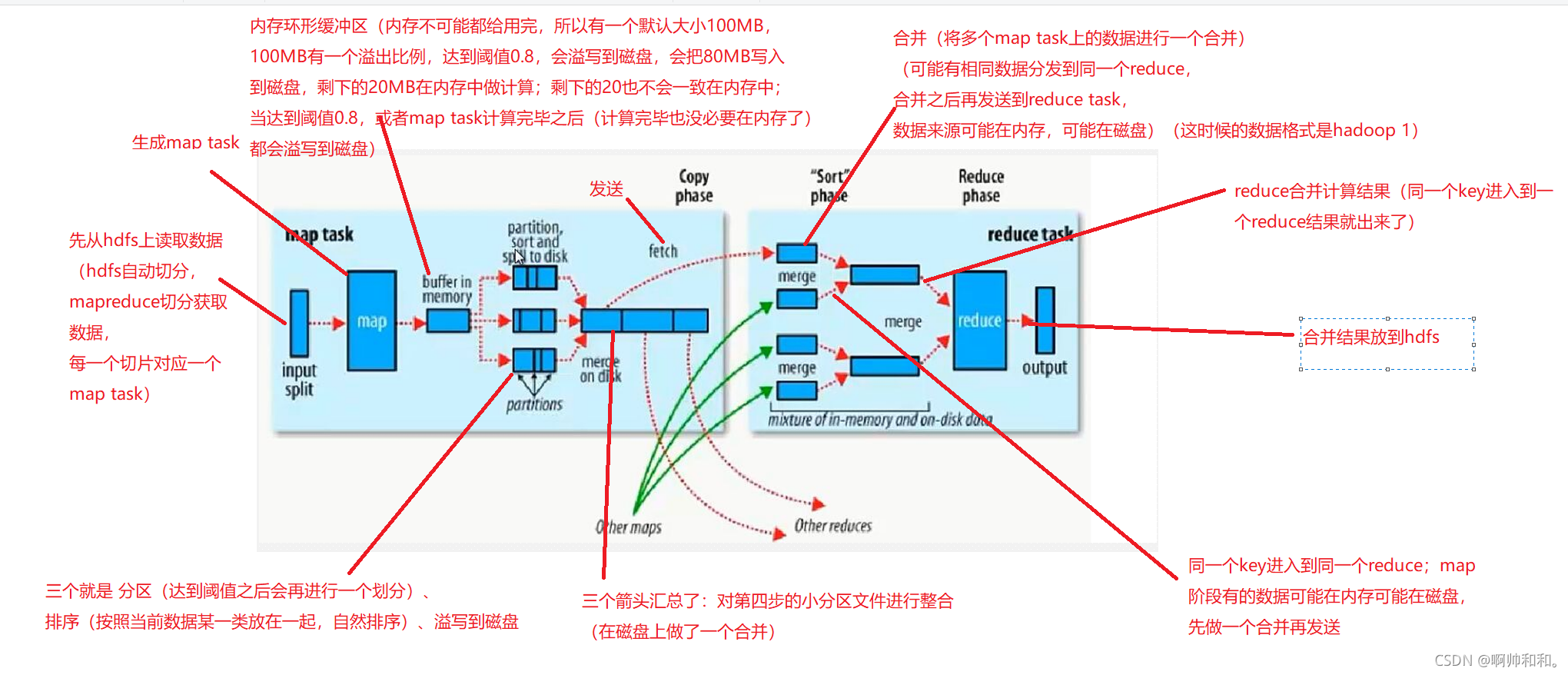
Shuffle过程
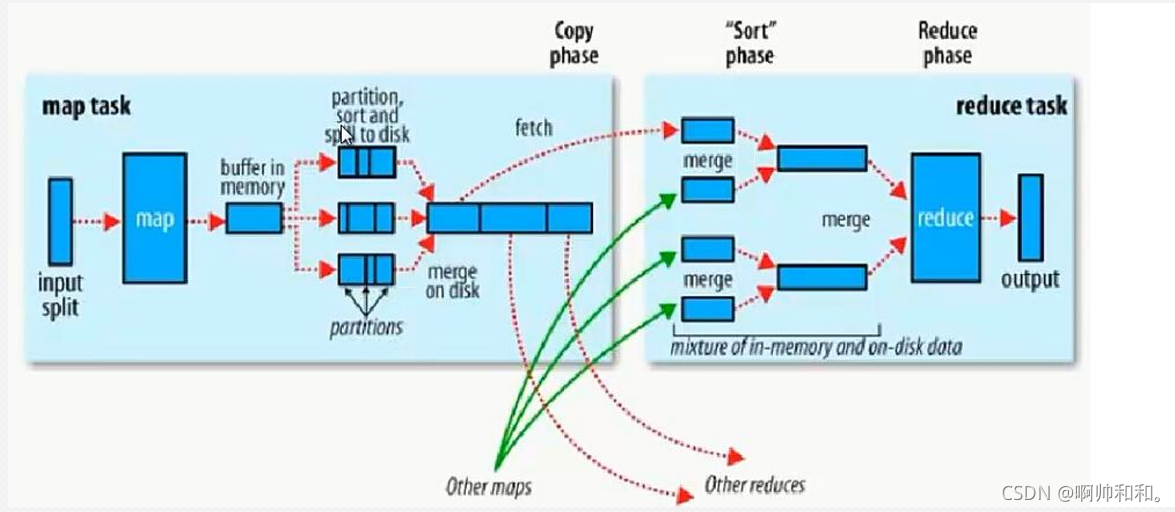
在内存中做计算
map阶段的shuffle
1.先从hdfs上读取数据(hdfs自动切分,mapreduce切分获取数据
每一个切片对应一个map task)

2.生成map task
3.内存环形缓冲区(内存不可能都给用完,所以有一个默认大小100MB
100MB有一个溢出比例,达到阈值0.8,会溢写到磁盘,会把80MB写入
到磁盘,剩下的20MB在内存中做计算;剩下的20也不会一致在内存中;
当达到阈值0.8,或者map task计算完毕之后(计算完毕也没必要在内存了)
都会溢写到磁盘)

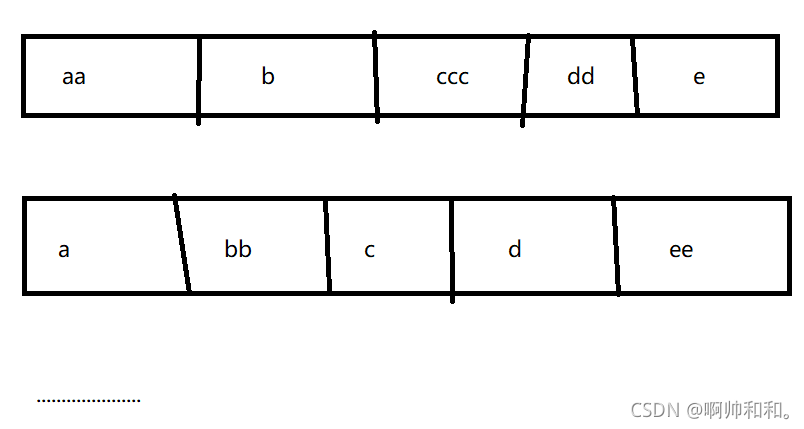
4.三个就是 分区(达到阈值之后会再进行一个划分)、
排序(按照当前数据某一类放在一起)、溢写到磁盘
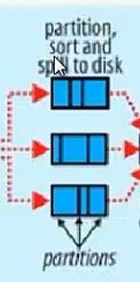
5.三个箭头汇总了:对第四步的小分区文件进行整合
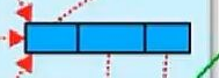
比方说这里有许多小分区的数据,对这些小分区的数据做一个聚合,方便后面的计算
6.发送,数据发送到reduce

reduce阶段的shuffle
7.合并(将多个map task上的数据进行一个合并)
(可能有相同数据分发到同一个reduce,
合并之后再发送到reduce task,
数据来源可能在内存,可能在磁盘)(这时候的数据格式是hadoop 1)
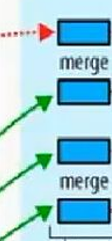
8.同一个key进入到同一个reduce;map阶段有的数据可能在内存可能在磁盘,先做一个合并再发送

9.reduce合并计算结果(同一个key进入到一个reduce结果就出来了)
10.合并结果放到hdfs
汇总
MapReduce执行过程-map阶段
- 1.1 框架使用InputFormat类的子类把输入文件(夹)划分为很多InputSplit,默认,每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个
- 1.2 框架调用Mapper类中的map(…)函数,map函数的形参是
- 1.3(假设reduce存在)框架对map输出的
(假设reduce不存在)框架对map结果直接输出到HDFS中。 - 1.4 (假设reduce存在)框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。注意:分组不会减少
- 1.5 (假设reduce存在,可选)在map节点,框架可以执行reduce归约。
- 1.6 (假设reduce存在)框架会对map task输出的
至此,整个map阶段结束
MapReduce执行过程-reduce阶段
- 2.1 框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle。
- 2.2 框架对reduce端接收的[map任务输出的]相同分区的
- 2.3 框架调用Reducer类中的reduce方法,reduce方法的形参是
- 2.4 框架把reduce的输出保存到HDFS中。
shell端实现mapreduce
准备数据
由于mapreduce处理的数据应该来源于hdfs,所以在hdfs上创建数据传入的路径,也就是将刚才的数据传到hdfs中

实现mapreduce
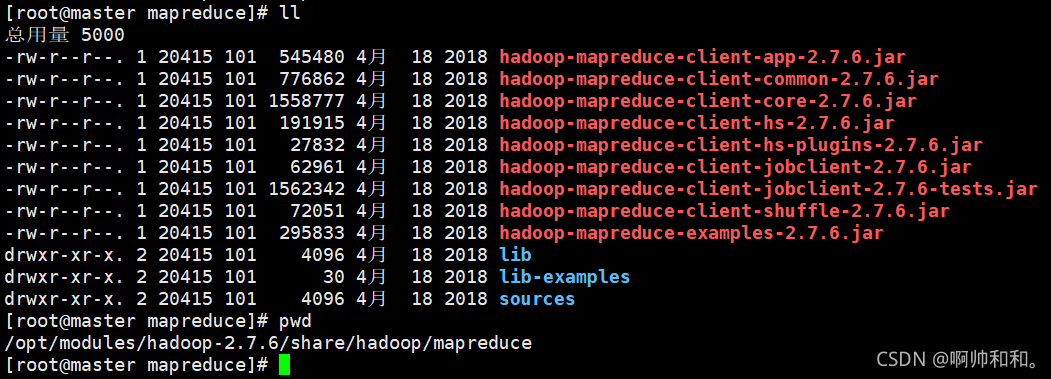

值得注意的是这里的wordcount是自己取的名字,/word是hdfs已经存在的路径,/output是hdfs中不存在的路径
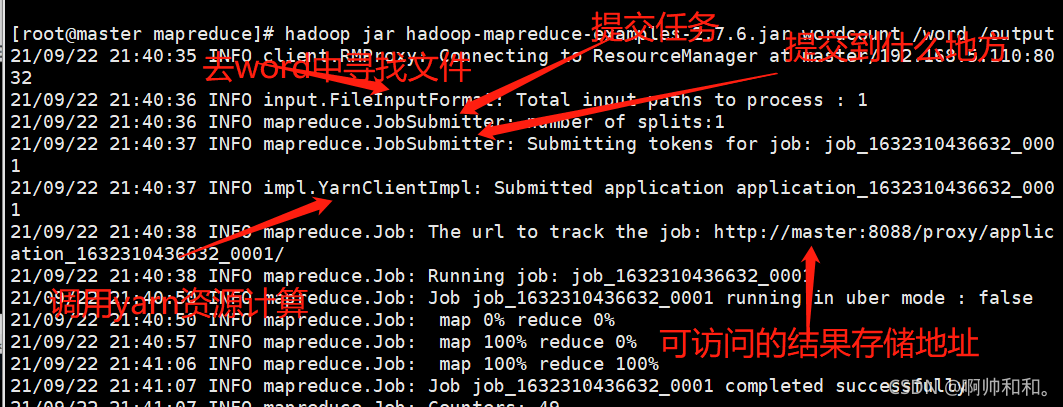
开始执行
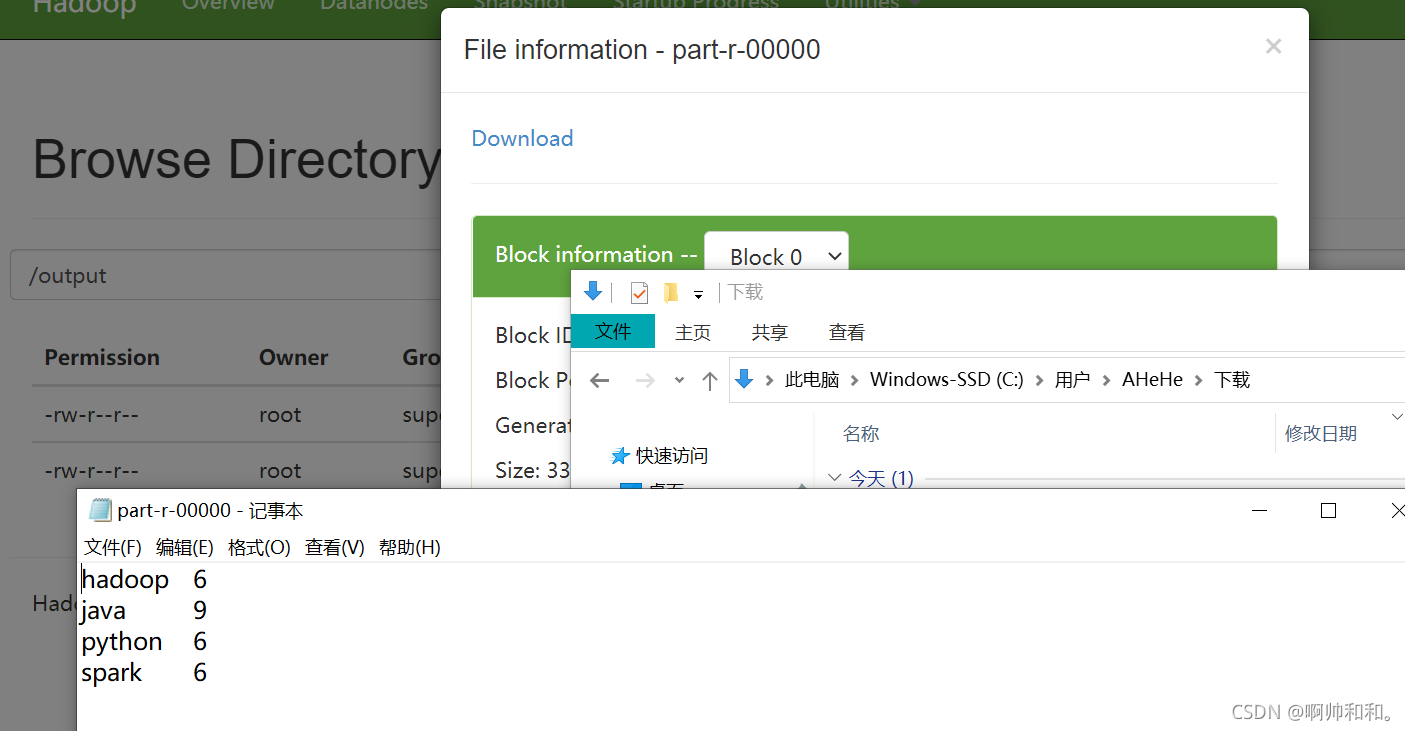
查看结果
Java操作mapreduce
package com.shujia.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class Demo01WordCount {//统计文件中单词的个数
//重写(覆盖)mapreduce中的map()和reduce()方法
//map类;第一对kv是决定数据输入的格式,第二对kv决定数据输出的格式
//第一个参数指的是偏移量,第二个参数指的是String类型,用的是文本形式
//后面两个参数就是(hadoop,1)这样的形式,最后一个参数用Integer也行public static class WCMapper extends Mapper {/*map阶段数据是一行一行过来的每一行数据都需要执行代码*/@Override//这里面三个参数,前面两个参数可以理解为输入的格式,第三个参数是输出的数据(出去和进来的格式一模一样)protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//通过context输出Text 格式:(一整行数据,1)String line = value.toString();context.write(new Text(line),new LongWritable(1));}}//前两个参数是map阶段传入的数据格式,后面两个参数是输出的格式public static class WCReduce extends Reducer{//这里面的值变成了一个迭代器(因为数据传来的时候是【hadoop,1】,【hadoop,1】这样的形式,但是只要一个hadoop就行了)//迭代器里面就是传入的所有v的值/*reduce 聚合程序(有几个key就跑几次,意思就是文件里面假如有一个hadoop,一个java,一个spark,那就需要跑三次)默认是一个节点key:每一个单词values:map端 当前k所对应的所有v*///这里面要做的就是整合最后的结果(将迭代器中的数据相加)@Overrideprotected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {long sum = 0L;for (LongWritable value : values) {sum+=value.get();}//把计算结果输出到hdfscontext.write(key,new LongWritable(sum));}}/*是当前mapreduce的入口用来构建mapreduce程序(数据从哪来等等)*/public static void main(String[] args) throws Exception {Job job = Job.getInstance();//指定job名称job.setJobName("单词统计");//构建mr,指定当前main所在类名(识别具体的类)job.setJarByClass(Demo01WordCount.class);//指定map端类job.setMapperClass(WCMapper.class);//指定输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);//指定reduce端类job.setReducerClass(WCReduce.class);//指定输出的kv类型job.setReducerClass(WCReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//指定输入路径Path in = new Path("/word");FileInputFormat.addInputPath(job,in);//指定输出路径Path out = new Path("/output");//如果路径存在,删除FileSystem fs = FileSystem.get(new Configuration());if(fs.exists(out)){fs.delete(out,true);}FileOutputFormat.setOutputPath(job,out);//启动任务job.waitForCompletion(true);System.out.println("mr正在执行");//hadoop jar hadoop-1.0-SNAPSHOT.jar com/shujia/hadoop/Demo01WordCount /word /output}
} 执行并获得结果

Java操作mapreduce,指定reduce任务数
在运行mr任务的时候,默认reduce执行一个,可以通过参数进行修改
job.setNumReduceTasks(2)
package com.shujia.hadoop;import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.logaggregation.AggregatedLogFormat;import javax.security.auth.login.Configuration;
import java.io.FilterOutputStream;
import java.io.IOException;public class Demo03SexSum {public static class WCMapper extends Mapper{@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] split = line.split(",");String sex = split[3];context.write(new Text(sex),new LongWritable(1));}}public static class WCReduce extends Reducer{@Overrideprotected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {long sum=0L;for (LongWritable value : values) {sum+=value.get();}context.write(key,new LongWritable(sum));}}public static void main(String[] args) throws Exception{Job job = Job.getInstance();job.setNumReduceTasks(2);job.setJobName("统计不同性别人数");job.setJarByClass(Demo03SexSum.class);job.setMapperClass(WCMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);job.setReducerClass(WCReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);FileInputFormat.addInputPath(job,new Path("/word"));Path out = new Path("/out");FileSystem fs = FileSystem.get(new org.apache.hadoop.conf.Configuration());if(fs.exists(out)){fs.delete(out,true);}FileOutputFormat.setOutputPath(job,out);job.waitForCompletion(true);//com.shujia.hadoop.Demo03SexSum}
} mapreduce程序关联两张表(实现join操作)
package com.shujia.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
//import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.util.ArrayList;/*
students.txt
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科六班
1500100003,单乐蕊,22,女,理科六班
1500100004,葛德曜,24,男,理科三班
1500100005,宣谷芹,22,女,理科五班score.txt
1500100001,1000001,98
1500100001,1000002,5
1500100001,1000003,137
1500100001,1000004,29
1500100001,1000005,85*/
public class Demo05Join {public static class JoinMapper extends Mapper{@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1.获取数据的路径InputSplit//context上面是hdfs,下面如果有reduce就是reduce,没有就是hdfsInputSplit inputSplit = context.getInputSplit();FileSplit fs = (FileSplit)inputSplit;String url = fs.getPath().toString();//2.判断if (url.contains("students")){//true:当前的数据为students.txtString id = value.toString().split(",")[0];//为了方便reduce数据的操作,针对不同的数据 打上一个标签String line = "*"+value.toString();context.write(new Text(id),new Text(line));}else {//学号作为key,是两张表的关联条件String id = value.toString().split(",")[0];String line = "#"+value.toString();context.write(new Text(id),new Text(line));}}}public static class JoinReduce extends Reducer{@Overrideprotected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {ArrayList scores = new ArrayList();String stuinfo = "";for (Text value : values) {String line = value.toString();if (line.startsWith("*")){stuinfo = line.substring(1);}else {scores.add(line.substring(1));}}//数据拼接,两张表的拼接
// for (String score : scores) {
// String subject = score.split(",")[1];
// String sc = score.split(",")[2];
// String info = stuinfo+","+subject+","+sc;
// context.write(new Text(info),NullWritable.get());
// }//成绩求和,两张表的拼接long sum = 0L;for (String score : scores) {Integer sc = Integer.parseInt(score.split(",")[2]);sum+=sc;}String end=stuinfo+","+sum;context.write(new Text(end),NullWritable.get());}}public static void main(String[] args) throws Exception{Job job = Job.getInstance();job.setJarByClass(Demo05Join.class);job.setJobName("Join操作");job.setMapperClass(JoinMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);job.setReducerClass(JoinReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);//路径FileInputFormat.addInputPath(job,new Path("/word"));Path out = new Path("/out");FileSystem fs = FileSystem.get(new Configuration());if (fs.exists(out)){fs.delete(out,true);}FileOutputFormat.setOutputPath(job,out);job.waitForCompletion(true);System.out.println("程序正在执行");}
} 介于map端与reduce端之间的Combine
- combiner发生在map端的reduce操作。
作用是减少map端的输出,减少shuffle过程中网络传输的数据量,提高作业的执行效率。 - combiner仅仅是单个map task的reduce,没有对全部map的输出做reduce。
如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以,Combine适合于等幂操作,比如累加,最大值等。求平均数不适合
如图,中间的这一部分就是combine,提高效率一眼可见

mapreduce程序实现combinue预聚合
package com.shujia.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;//LongWritable 偏移量 long,表示该行在文件中的位置
public class Demo06Combine {public static class CombineMapper extends Mapper{@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String sex = line.split(",")[3];context.write(new Text(sex),new IntWritable(1));}}//预聚合在reduce之前 map端之后public static class Combine extends Reducer{@Overrideprotected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {Integer sum=0;for (IntWritable value : values) {sum+=value.get();}context.write(key,new IntWritable(sum));}}public static class CombineReduce extends Reducer{@Overrideprotected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {Integer sum=0;for (IntWritable value : values) {sum+=value.get();}context.write(key,new IntWritable(sum));}}public static void main(String[] args) throws Exception{Job job = Job.getInstance();job.setNumReduceTasks(2);job.setJobName("假如Combine做性别统计");job.setJarByClass(Demo06Combine.class);job.setMapperClass(CombineMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setReducerClass(CombineReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job,new Path("/word"));Path path = new Path("/out");FileSystem fs = FileSystem.get(new Configuration());if (fs.exists(path)){fs.delete(path,true);}FileOutputFormat.setOutputPath(job,path);job.waitForCompletion(true);}
} 感谢阅读,我是啊帅和和,一位大数据专业大四学生,祝你快乐。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!