将两个文件student.txt和student_score.txt上传到hdfs上。使用Map/Reduce框架完成题目。
现有student.txt和student_score.txt。将两个文件上传到hdfs上。使用Map/Reduce框架完成下面的题目。
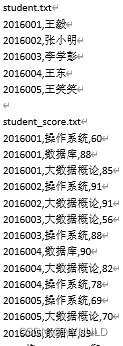
1.将stduent.txt和student_score.txt连接,输出学号、姓名、课程、分数字段。如下所示
为输出的前2行:
2016001,王毅,操作系统,60
2016001,王毅,数据库,88
package b;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
import java.util.List;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.commons.beanutils.BeanUtils;public class MapReduceConnect1{public static void main(String[] args)throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");Job job = Job.getInstance(conf,"MapReduceConnect1");job.setJarByClass(MapReduceConnect1.class);job.setMapperClass(MapReduceConnectMapper.class);job.setReducerClass(MapReduceConnectReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(SCC.class);//reducejob.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);Path output=new Path("/output");FileSystem fs=FileSystem.get(conf);//如果存在output目录则删除outputif(fs.exists(output)){fs.delete(output,true);}fs.close();//输入文件目录:FileInputFormat.addInputPath(job, new Path("/usr/stu/input"));FileOutputFormat.setOutputPath(job, output);System.exit(job.waitForCompletion(true) ? 0 : 1);}//Map端public static class MapReduceConnectMapper extends Mapper<Object, Text, Text, SCC> {protected void map(Object key, Text value, Mapper<Object, Text, Text, SCC>.Context context)throws IOException, InterruptedException {//将数据以逗号进行切分SCC scc=new SCC();String[] stus = value.toString().split(",");if (stus.length==2) { scc.setId(stus[0]);scc.setName(stus[1]);scc.setTable("student"); }else{scc.setId(stus[0]);scc.setCourse(stus[1]);scc.setScore(Integer.parseInt(stus[2]));scc.setTable("student_score");}//以学号作为key ,scc对象作为valuecontext.write(new Text(stus[0]), scc);}}//Reduce 端public static class MapReduceConnectReducer extends Reducer<Text, SCC, Text, NullWritable> {protected void reduce(Text key, Iterable<SCC> values,Reducer<Text,SCC, Text, NullWritable>.Context context)throws IOException, InterruptedException {String name = "";List<SCC> list = new ArrayList<SCC>();for (SCC value : values) {if("student".equals(value.getTable())){name=value.getName();}else{SCC sc=new SCC();try {BeanUtils.copyProperties(sc, value);} catch (IllegalAccessException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (InvocationTargetException e) {// TODO Auto-generated catch blocke.printStackTrace();}list.add(sc);}}for(SCC result:list){result.setName(name);context.write(new Text(result.toString()), NullWritable.get());}}} //implements Writablepublic static class SCC implements Writable{String id="";String name="";String course="";int score=0;String table="";public String getId() {return id;}public void setId(String id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getCourse() {return course;}public void setCourse(String course) {this.course = course;}public int getScore() {return score;}public void setScore(int score) {this.score = score;}public String getTable() {return table;}public void setTable(String table) {this.table = table;}@Overridepublic String toString() {return id + "," + name + "," + course + "," + score;}public SCC(String id, String name, String course, int score,String table) {super();this.id = id;this.name = name;this.course = course;this.score = score;this.table = table;}public SCC(){super();}@Overridepublic void readFields(DataInput in) throws IOException {// TODO Auto-generated method stubthis.id=in.readUTF();this.name=in.readUTF();this.course=in.readUTF();this.score=in.readInt();this.table=in.readUTF();}@Overridepublic void write(DataOutput out) throws IOException {// TODO Auto-generated method stubout.writeUTF(id);out.writeUTF(name);out.writeUTF(course);out.writeInt(score);out.writeUTF(table);}public int compareTo(SCC o) {return this.compareTo(o);}}
}
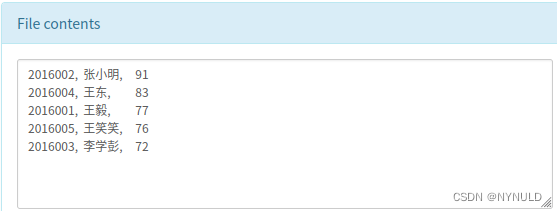
2.统计每个同学的平均成绩,显示学号、姓名和平均成绩,并按照成绩高低降序排序。如下所示为输出结果:
2016002, 张小明, 912016004, 王东, 832016001, 王毅, 772016005, 王笑笑, 762016003, 李学彭, 72
package b;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;//输入的是来自第一题MapReduceConnect1的结果:
//2016001,王毅,操作系统,60
//2016001,王毅,数据库,88
//2016001,王毅,大数据概论,85
//2016002,张小明,操作系统,91//此方法输出的是未排过序的结果,MRConnectMethod2方法是对此方法的输出结果进行排序:
/*2016001, 王毅, 772016002, 张小明, 912016003, 李学彭, 722016004, 王东, 832016005, 王笑笑, 76
*/
public class MRConnectMethod {public static void main(String[] args) throws IllegalArgumentException,IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");Job job = Job.getInstance(conf, "MRConnectMethod");job.setJarByClass(MapReduceConnect2.class);job.setMapperClass(MapReduceConnectMapper2.class);job.setReducerClass(Average2Reduce.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//reducejob.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//输出文件;目录Path output = new Path("/output2");FileSystem fs = FileSystem.get(conf);if (fs.exists(output)) {fs.delete(output, true);}fs.close();// 输入文件目录:FileInputFormat.addInputPath(job, new Path("/output"));// 输出文件目录:FileOutputFormat.setOutputPath(job, output);System.exit(job.waitForCompletion(true) ? 0 : 1);}// Map端public static class MapReduceConnectMapper2 extendsMapper<Object, Text, Text, IntWritable> {protected void map(Object key, Text value,Mapper<Object, Text, Text, IntWritable>.Context context)throws IOException, InterruptedException {// 将数据以逗号进行切分String[] stus = value.toString().split(",");List<String> scoreList = new ArrayList<>();scoreList.clear();scoreList.add(stus[0]);scoreList.add(stus[1]);//多加一个空格是为了输出结果美观,但是注意在下一个类操作时要删除空格scoreList.add("");// 以新列表作为key ,成绩作为valuecontext.write(new Text(StringUtils.strip(scoreList.toString(), "[]")),new IntWritable(Integer.valueOf(stus[3])));}}// Reduce 端public static class Average2Reduce extendsReducer<Text, IntWritable, Text, IntWritable> {protected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException {int sumscore = 0;int num = 0;for (IntWritable value : values) {num++;sumscore = sumscore + value.get();}// 计算平均成绩Integer avg = sumscore / num;context.write(new Text(key), new IntWritable(avg));}}
}
注意,上面的类(MRConnectMethod)只进行求平均成绩,而不进行排序:
2016001, 王毅, 77
2016002, 张小明, 91
2016003, 李学彭, 72
2016004, 王东, 83
2016005, 王笑笑, 76
这个类才是排序类:
package b;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;//对来自MRConnectMethod的未被排序过的结果进行排序:
/*2016002, 张小明, 912016004, 王东, 832016001, 王毅, 772016005, 王笑笑, 762016003, 李学彭, 72
*/
public class MRConnectMethod2{public static void main(String[] args) throws IllegalArgumentException,IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");Job job = Job.getInstance(conf, "MRConnectMethod2");job.setJarByClass(MRConnectMethod2.class);job.setMapperClass(TestMapper2.class);job.setReducerClass(TestReduce.class);job.setMapOutputKeyClass(IntWritable.class);job.setMapOutputValueClass(Text.class);// reducejob.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);// 指定特定的比较类job.setSortComparatorClass(NumberComparator .class);// 输出文件;目录Path output = new Path("/output3");FileSystem fs = FileSystem.get(conf);//如果存在output3目录则删除output3if (fs.exists(output)) {fs.delete(output, true);}fs.close();// 输入文件目录:FileInputFormat.addInputPath(job, new Path("/output2"));// 输出文件目录:FileOutputFormat.setOutputPath(job, output);System.exit(job.waitForCompletion(true) ? 0 : 1);}// Map端public static class TestMapper2 extendsMapper<Object, Text, IntWritable, Text> {protected void map(Object key, Text value,Mapper<Object, Text, IntWritable, Text>.Context context)throws IOException, InterruptedException {// 将数据以逗号进行切分String[] stus = value.toString().split(",");List<String> scoreList = new ArrayList<>();scoreList.clear();scoreList.add(stus[0]);scoreList.add(stus[1]);scoreList.add(stus[2]);// "2016002","张小明"," 91" 此处为3个字符串//成绩字符串前面有空格,所以把空格去掉后作为key// 以成绩作为key ,text作为value key:91 value:2016002,张小明,91context.write(new IntWritable(Integer.valueOf(stus[2].trim())),new Text(StringUtils.strip(scoreList.toString(), "[]")));}}// Reduce 端public static class TestReduce extendsReducer<IntWritable, Text, Text, NullWritable> {protected void reduce(IntWritable key, Iterable<Text> values,Reducer<IntWritable, Text, Text, NullWritable>.Context context)throws IOException, InterruptedException {for (Text value : values)context.write(new Text(value.toString()), NullWritable.get());}}//比较类public static class NumberComparator extends IntWritable.Comparator {@Overridepublic int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {return -super.compare(b1, s1, l1, b2, s2, l2);}}
}
hdfs集群查看:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!