1、spark-submit脚本的使用及理解
2019独角兽企业重金招聘Python工程师标准>>> 
一、介绍
-
1、安装省略,因为现在基本上都用大数据集成平台:cdh,hdp等
-
2、spark-submit脚本是spark提供的一个用于提交任务的脚本,通过它的--master 参数可以很方便的将任务提交到对应的平台去执行,比如yarn、standalone、mesos等。
-
3、spark-submit会在提交任务时,把集群大部分的配置文件都打包在__spark_conf__.zip中,包括core-site.xml、hdfs-site.xml、yarn-site.xml、mapreduce-site.xml、hbase-site.xml、hive-site.xml等。然后将其和工程依赖的第三方jar(flume、kafka、以及com.apache.org.lang3等)一同发送到spark的资源存放目录下,默认是:/user/root/.sparkStaging/xxxId/。
-
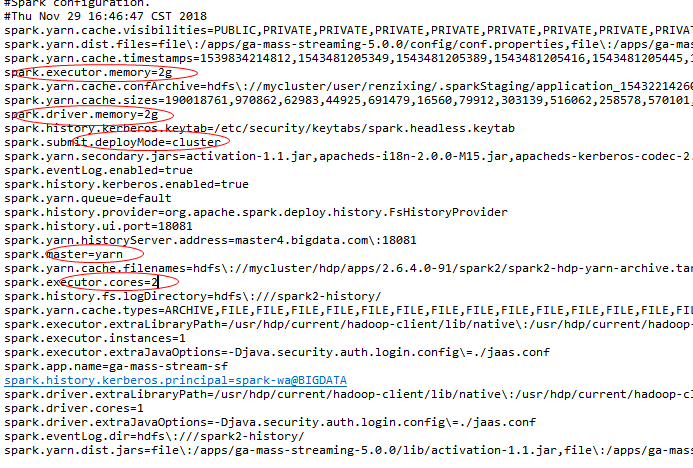
4、上述的__spark_conf__.zip还包含一个重要的配置文件__spark_conf__.properties,里面包含着spark-submit脚本的启动参数
在main类中SparkConf conf = new SparkConf();时会加载这个配置文件,所以不再需要执行conf.setMaster("yarn");
如图:
-
5、有了上面配置文件和jar,就可以很方便的访问
hive(hiveContext)
hbase(Configuration conf = HBaseConfiguration.create())
hdfs等组件
二、submit-submit参数说明
spark-submit \--master yarn \ 运行的模式--deploy-mode cluster \--name spark-test \ 在yarn界面看到的名字,如果不设置,那就是下面--class的值--driver-memory 1g \ driver的内存--executor-memory 1g \ 每一个executor的内存--executor-cores 1 \ executor数量--jars xxx.jar, xxx.jar, xxx.jar 第三方jar,比如hbase,flume、apache的一些工具jar--conf mysql.url=jdbc:mysql://localhost:3306/hive?xxxx \ 只能设置spark内定的参数(这个无效)--files /conf.properties \ 发送到集群的配置文件,可以直接new fileInputstream("conf.properties")来获取--class com.bigdata.spark.core.SparkRunTest \ 主类/study-spark-core-4.0.0.jar \ 自己工程的jar10
三、spark-submit提交任务的流程
不管是什么脚本,只要是java写的工程,他的启动脚本最终都会调用某个类,然后在通过这个类来启动工程,或者提交任务到集群再起动,spark-submit也是同样的道理,他的流程如下:
/usr/bin/spark-submit
==> /appslog/cloudera/parcels/CDH-5.7.0-1.cdh5.7.0.p0.45/lib/spark/bin/spark-submit
==> 执行spark-core-XXx.jar里面的 org.apache.spark.deploy.SparkSubmit (进程的形式)
==> 直接执行org.apache.spark.deploy.SparkSubmit$.main(args) (普通方法的形式)
==> 通过--master参数值来判断到底调用那个类来提交到对应的集群,对应如下
--master yarn ==> org.apache.spark.deploy.yarn.Client
--master spark://XX ==> org.apache.spark.deploy.Client
--master mesos ==> org.apache.spark.deploy.rest.RestSubmissionClient
--master local
流程查看:
-
1、sh -x /usr/bin/spark-submit 里面会有一句

-
2、sh -x /opt/cloudera/parcels/CDH-5.7.0-1.cdh5.7.0.p0.45/bin/../lib/spark/bin/spark-submit

-
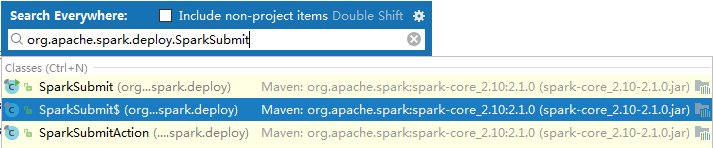
3、进入ide查看org.apache.spark.deploy.SparkSubmit源码(main方法,很长)


四、总结
-
1、--files发送过来的文件,可以直接读取,不需要路径。比如上述将配置文件发送到.sparkStaging/XXXID/下,可以直接通过如下方式获取,这样参数就不需要再spark-submit最后那里一个个繁琐的添加进去
Properties pros = new Properties();pros.load(new FileInputStream("conf.properties")); -
2、--jars 和 --files后面都不能是文件夹,需要将所有的jar的绝对路劲,通过“逗号”拼接,但是开头不能是逗号,优先发送--jars的jar,如果系统的jar有冲突,那么不会再发送,也就是以用户lib文件夹下的为准

-
3、new SparkConf()时会加载__spark_conf__.properties,所以不需要再设置master、depoly-mode等参数
转载于:https://my.oschina.net/liufukin/blog/795540
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!