【阅读笔记】机器阅读理解书阅读(上)——基础篇
机器阅读理解书阅读(上)——基础篇
书本来自朱晨光的《机器阅读理解:算法与时间》
文章目录
- 机器阅读理解书阅读(上)——基础篇
- 数据集
- 设计高质量的数据集
- 自然语言处理基础
- 分词
- 中文分词
- 英文分词
- 字节对编码BPE
- 词向量
- 命名实体、词性标注
- 命名实体识别
- 词性标注
- 语言模型
- NLP中的深度学习
- 词向量到文本向量
- 自然语言理解
- 自然语言生成 (NLG)
- 注意力机制
数据集
设计高质量的数据集
-
区分基于理解和匹配的模型
SQuAD也基本是依赖文章和问题中文字匹配的,并非基于真正理解文章和问题的意思。所以SQuAD每篇文章后添加依据包含问题中关键词但与问题毫无关系的迷惑性语句,所有算法的F1指标会下降很多。
也正是因此,SQuAD2.0也设置了利用文章中的关键词组合生成“无法回答”的问题,有效降低了依赖关键词匹配的模型的得分。
-
考察模型的推理能力
人类阅读理解的一个能力就是归纳和推理,就是根据文章中提到的多处线索进行总结最终得到答案。
多步推理也是MRC数据集应该重点考察的指标之一。
但是HotpotQA这种数据集(先有多个段落信息然后再生成问题,这种生成方式可能导致问题不太自然,和现实生活中用户提出问题有明显差别),所以另一种可行的方式是从用户问题中筛选出需要推理的问题,检索得到相关文档,然后将文本信息按照图例的每一步分成多个段落or部分。
-
考察模型的常识能力
常识common sense。常识规模很大、难定义、难完整总结、难进行有效表示和应用。
常识推理的问答在实际应用中十分常见,但是这方面MRC数据集还很少见。
常识问答数据集commonsenseQA,来考察模型对结构化知识的理解能力。
-
其他理解技能
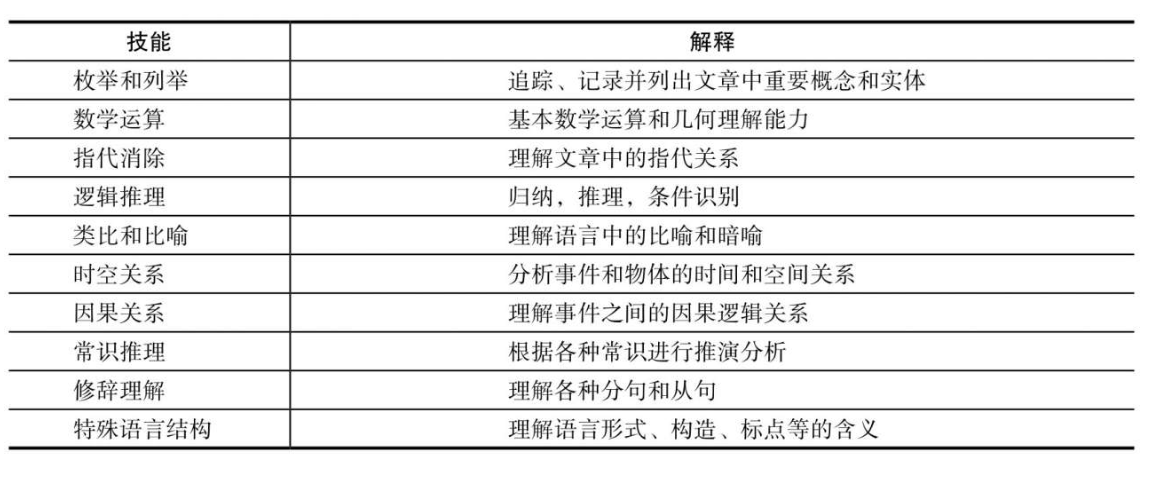
这些阅读理解技能涵盖了人类所掌握的阅读理解能力,即包括对语言和修辞等方面的理解,也包括对数学、常识等外部知识的掌握。
因此阅读理解任务应设置相应的测评,从各方面考察模型的技能。
当前MRC研究很大程度上还依赖于统计层面的模式识别和匹配,缺乏许多人类阅读理解必备点技能,并且很难对答案给出合理的解释,这些都是需要解决的课题。
自然语言处理基础
分词
在MRC中,模型通常需要首先对语句和文本进行单词分拆和解析。
解决歧义性是分词任务中的一个挑战,不同的拆分方式可能表示完全不同的语义。比如:“南京市|长江大桥”、“南京|市长|江大桥”
中文分词
PS:关于中文分词的必要性与中文MRC以字为单位的讨论,可以看我之前的论文笔记。
中文分词有很大挑战。分词的第一步是获得词汇表。因为许多中文词汇存在部分重叠现象,词汇表越大分词歧义性出现的可能性就越大,因此需要在 词汇表的规模和最终分词质量之间寻找一个平衡点。一种主流的中文分词方式——基于匹配的分词。
这种匹配方式采用固定的匹配规则对输入文本进行分割,是的每部分都是一个词表中的单词。正向最大匹配算法就是其中一种常用算法。改进的有:从后往前最大匹配。
```
逆向最大匹配算法
例子:
输入:s='今天天气真不错', vocab=['天气','今天','昨天','真','不错','真实','天天']
输出: ['今天','天气','真','不错']
```def backward_maxmal_matching(s, vocab):result = []end_pos = len(s)while end_pos > 0:found = Falsefor start_pos in range(end_pos):if s[start_pos:end_pos] in vocab:result = [s[start_pos:end_pos]] + resultfound = Truebreakif found:end_pos = start_poselse:# 为找到匹配单词,将单字作为词分出result = [s[end_pos-1]] + resultend_pos -= 1return result
以上的中文分词方式依赖预先准备的词表,基于统计的中文分词方法后面会说。
英文分词
英文分词简单的多,但是简单粗暴的去掉符号和按空格分词方式也有弊端:比如 ph.D这样的标点符号要作为词的一部分保留、123.78这样的千分位逗号表示、you’re这样的缩写需要展开、一些专有名词需要空格比如New York。
这些特例,可以使用正则表达式来识别和特殊处理。
还有一些词的变体比如-ed, -s, -es,一般需要对分词结果提取词干,即提取出单词的基本形式。比如do, does, done这3个词统一转化为词干do。提取词干也可以利用规则处理。
中文分词工具常用jieba,英文分词工具常用spaCy。
字节对编码BPE
以上的分词方法都依赖预先准备的词表,词表规模太大会分词效率会下降,而词表也会用OOV问题,如果遇到OOV词全部以特殊符号代替会导致重要信息的丢失,丢失相关信息。采取不依赖于词表的分词,可以最大程度保留原有单词信息。
字节对编码(Byte Pair Encoder, BPE)就是一种常用的不依赖于词表的分词方法。这就涉及到我之前一直不了解的子词(subword,常见的可以组成单词的子字符串),最基本的子词就是所有字符的集合,如{a,…z,A,B…,Z}。详细算法见书本。
BPE算法子词经过若干次合并之后,得到常见的子词集合,从而得到一个新词的BPE表示。BERT就使用了BPE作为分词单元。
- 优点:没有OOV问题,可通过调整合并次数动态控制词表大小;
- 缺点:不同训练文本上可能得到不一样的子词表,使得对应模型无法对接、子词基于频率生成,可能不符合语言中词根的划分。
实际应用:
- 需要生成自然语言(如生成阅读理解问题的答案文本),推荐使用BPE等不依赖于词表的分词方法
- 任务不涉及文本生成,可以用既有词表,比如GloVe或Word2vec等
词向量
在MRC工程应用中,单词词向量有两种处理方式:
- 词向量作为常数不断更新,这样训练速度快,模型规模相对较小
- 词向量作为模型参数的一部分计算导数并更新,这样在具体任务中有时可提高模型的准确度,但速度相对前者较慢
命名实体、词性标注
在MRC中,关于单词的类别信息可以提高回答准确度。比如“居里夫人什么时候出生”,文章中与时间相关的单词和短语就应成为关注点,如果问题是“这篇文章中提到了哪些药物”,那么文章中的名词实体就更可能成为答案。MRC中常用的单词标注有两种:命名实体识别、词性标注,两者都能有效提高MRC QA的准确度。
值得注意的是:两种编码都是以单词为基本单元,如果采用非词表分词,如子词BPE,需要将NER和POS信息与单词对齐,即若一个单词分为多个子词,每个子词均使用这个单词的NER和POS编码。
命名实体识别
命名实体识别:对分析语句结构、信息抽取、语义理解都有重要作用。一般为人名、地名、组织机构三大类,也有拓展分类包括时间日期等。命名实体的识别一般有以下几种方式。
-
基于规则
基于规则NER精度较高,但召回率很低,因为不可能穷举所有语言样式。但是在特定语言环境下(比如公司财报、法律条文),如果对语言的格式有很强的限定,那么基于规则的NER是可行方法。
-
基于特征
可以作为有监督的机器学习问题(在已有标注数据情况下对单词分类)加以解决,这种标注也叫做序列标注。序列标注的特点是,下一个词的标注结果取决于之前单词的标注和相关特征。
单词的特征内涵,见书本。每个单词得到特征后(f1,f2,…fn),可以独立建模(如逻辑回归)来学习NER,也可以利用CRF与所有语句中的单词一起学习标注。
也就是说,会有多个步骤的流水线操作:收集特征->调整特征个数->序列标注。
-
基于深度学习
基于 单词词向量 和 字符级别的信息,建立各种形态的神经网络,最终在输出层设置给每一个单词分配一个分类器,为每个单词是每种命名实体的可能性打分。
词性标注
词性是语言学中的概念,是以语法分类为依据并兼顾词汇意义对词进行分类的。语言中的同一个词具有多个词性的现象非常普遍,这种词也叫作兼类词。比如“我花了一个小时作文作业”,“这朵花真好看”。因此词性的标注和上下文有很大关系。
词性标注本质上也是序列标注。现流行并且效果比较好的词性标注方法为HMM。
中文NER和中文POS都可以用jieba实现。英文可以用spaCy。
语言模型
语言模型,就是给那些合法语句赋予较大的概率,给罕见或者不可能出现的句子赋予很小的概率。概率分配得当,计算机就可以像人类一样识别与生成合乎语法、符合正常思维的语句。任何需要生成答案语句的MRC算法都必须建立语言模型,给语言赋予合适的概率。
获取语言模型的概率的方法,可以用HMM条件概率。
在实际计算中,N元模型需要在每个句子前后加上开始和结束标识符。如“< s >我们|今天|来|吃饭| < \ s>”,< s >, <\s>也作为词汇表的一部分,从而所有长度的句子语言模型综合概率总和等于1。(具体见书)
有些合法的句子在文本中没有出现过,会有问题。比如:“今天天气”这样的组合如果没有出现过,但“今天天气真好”是一个合法的句子,从而导致P(天气|今天)=0,或者有未出现过的词,作为分母频率也会变成0,要解决这个问题,就用到了 拉普拉斯平滑, 从而获得>0的概率。
语言模型的评测:一个参考是Perplexity(困惑度)分值,而也经常要将语言模型作为NLP任务的一部分来检测是否对任务结果有帮助。
NLP中的深度学习
词向量到文本向量
若最终目标是对整个文本进行判断或分类,必须要将这n个向量变成一个表示整个文本的向量。此外,如果希望用一个向量表示一个句子,也需要将若干个词向量变为一个向量。
比如batch里的词向量维度是维度:batch * seg_len * word_dim 表示(一个三维矩阵),希望输出维度是 doc_dim的文本向量,即获得batch * doc_dim的tensor。
注意:使用普通的全连接网络无法将不定个数的词向量浓缩为一个向量。因为每个句子词向量个数、每个batch里的最长句子长度seq_len都不固定,所以无法预先设立将词向量变成一个向量的seq_len*1的全连接层。
方法有:
-
利用RNN最终状态
文本向量的维度就是RNN的状态维度。
-
利用CNN词化
每个batch里,用window_size * word_dim的过滤器一次扫过每连续window_size+1个词,这样对于一个文本,一个过滤器可以得出一个长度为(seg_len - win_size + 1)的向量。如果有m个过滤器(m个输出通道),则每段窗口产生m个卷积值。所以CNN结果维度为
batch * (seg_len - window_size + 1)*m。但是每个文本仍有
L=seg_len-window_size+1个向量,-
用平均池化的方式(第j维是L个向量第j维的平均値),产生向量维度为batch*m。
-
用最大池化(第j维向量是L个向量第j维的最大值),最后产生维度是 batch * out_channels
优点:平移不变性(translation invariance),能保留重要单词的信息。
CNN和最大池化另一个用途是字符级CNN,在CNN过滤器移动的过程中,每次窗口里包含若干个连续的字符,称为 子词。字符CNN能有效应对拼写错误,实际应用中,常将字典中的词向量和字符CNN的输出向量拼接成新的词向量。
-
-
利用含参加权和
输入为n个向量,每个向量都有自己的权重wi,希望权重能根据向量的关系确定,并且可以优化,这就是含参加权和(parametrized weighted sum),平均池化可以看做每个wi都是1/n。
s为分数,ai为词向量,b为参数向量,则si = bTai ,b是可优化参数,si范围可能很大不能直接作为权重,所以要softmax一下,最后利用权重得到所有向量的加权和,即所求文本向量:a = Σwiai。

b是可优化参数,在优化过程中,参数会自动调整到对目标任务结果有所提升的取值。
以下的这种含参加权和其实是一种自注意力机制!
import torch
import torch.nn as nn
import torch.nn.functional as F
class WeightedSum(nn.Module):def __init__(self, word_dim):super(WeightedSum, self).__init__()self.b = nn.Linear(word_dim, 1) # 参数张量def forward(slef, x):scores = self.b(x) # 内积得分weights = F.softmax(scores, dim=1) # 结果是batch x seg_len x 1res = torch.bmm(x.transpose(1,2), weights) # batch x word_dim x 1res = res.squeeze(2) # 删除最后一个维度,得到batch x word_dimreturn res自然语言理解
用于分类的深度学习网络也被称为 判定模型(discriminative model),而自然语言中与分类相关的任务称为自然语言理解(NLU)。
如果系统需要输出“不属于任何一类”的情况,有两种解决办法:
- 在验证数据上枚举得到最合适的阈值,当所有类别得分都低于这个阈值的时候,输出“不属于任何一类”
- 将“不属于任何一类”作为第K+1类处理。
多标签分类(multilabel classification)任务中,一段文本可能同时有几个正确分类,比如财经和政治的新闻。可以对K个类建立K个二分类器,判断文本是否属于每个类,最后根据验证数据设置合理的阈值,并对一段文本同时输出多个标签。
自然语言生成 (NLG)
可以实现生成功能的深度学习网络称为 生成模型(generative model)。像机器翻译、自然语言回答形式的MRC、生成文章总结、自动补全、创作文章等都算文本生成。
解码的时候,必须使用从左向用的结构比如RNN,否则会偷看这样训练出来的参数没有意义。
在训练解码的时候,一开始因为生成的单词是错的会导致错误累积,所以一个常用的技巧为 teacher forcing(强制教学),teacher forcing策略在训练的时候不会将解码器生成的单词输入下一个RNN模块,而是直接使用真值答案输入到RNN模块,这样可以有效缓解解码器训练困难的问题。实际应用中可以采用teacher forcing和非teacher forcing交叉使用的策略。在测试阶段,一律采用非teacher forcing的策略。
语言生成模型大部分采用encoder-decoder架构。
集束搜索
所有可能的单词序列个数是指数级别的,即Vn,要快速找出最优单词序列的话,一个是可以用Viterbi动态规划算法、还能用贪心算法,但是会有局部最优不是全局最优问题。Beam Search是一个好方法。
Beam Search每一步并不只选择当前概率最大的下一个词,而是选择B个,在第2步的时候从这B个单词分别寻找最有可能的B个下一个单词,这样获得了B^2个双词序列。在这些双词序列中选取当前概率最大的B个保留下来,从而再继续第3、4步…因此,beam search每一步都有保留B个当前保留下来的最优序列!然后经过RNN拓展下一个单词,并保留其中的最优的B个。示意如下图:
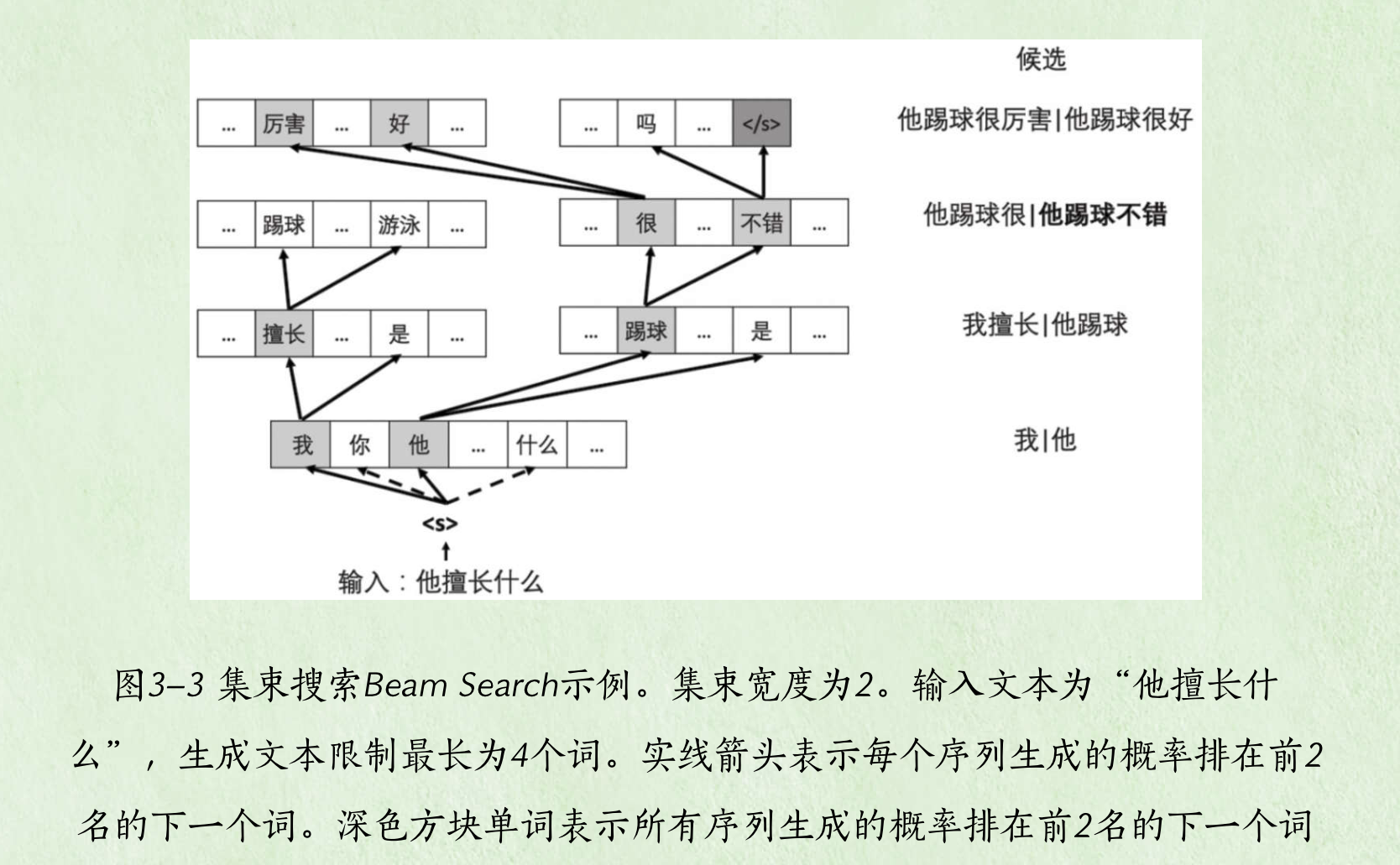
beam search由于全局概率是所有单词条件概率的乘积,所有会出现越长的句子全局概率越小的情况。这导致算法倾向于挑出很短的句子,因此用长度归一化(length normalization)来解决这一问题,即使用平均全局概率(见书)。
注意力机制
注意力极值的输入包括两个部分:
- 被注意的对象,为一组向量{a1,a2,…,n},如输入文本的词向量
- 一个进行注意的对象,为一个向量x。
向量x需要对{a1,…an}进行总结,但是x对每个ai的注意力不一样。注意力取决于从向量x的角度给被注意的对象打分,然后用softmax归一化后并对{a1,…,an}计算加权和,得到最终的注意力向量c。即向量c是{a1,…an}的线性组合,但是权重来自x和每个ai的交互,即注意力的计算。
当在多个向量x的时候,可以分别进行注意力操作。用xj来表示。

def attention(a,x):scores = x.bmm(a.transpose(1,2))alpha = F.softmax(scores, dim=-1)attended = alpha.bmm(a) # 与向量a计算加权和得注意力向量,结果维度为batch x n x dimreturn attended
上代码结果,每个x中的向量x[i,j]都得到了一个对应的dim维注意力向量attended[i,j]。
在seq2seq中,计算的注意力向量是:Attention({a1,a2,…an}; ht-1)=ct
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!