uniapp小程序调用百度语音识别
文章目录
- 准备工作
- 步骤
- 百度示例
- 获取token
- 上传到百度接口,获取结果
- uniapp小程序实现
- 设置录音相关
- 设置请求相关
- 请求地址的拼接
- 读取文件,请求接口
- 极速版
准备工作
需要在百度创建应用,领取免费的语音识别功能。这个可以按照官方的提示一步一步来
接入指南


这里的appid,appkey 和 secretkey是后面要用到的
步骤
基本上三步:
1:获取token
2:录音
3:上传到百度接口,获取到结果
百度示例
获取token
注意地址要拼接的参数
后面要使用的token可以取access_token的值
上传到百度接口,获取结果
录音是需要我们自己的程序实现
官方的例子:
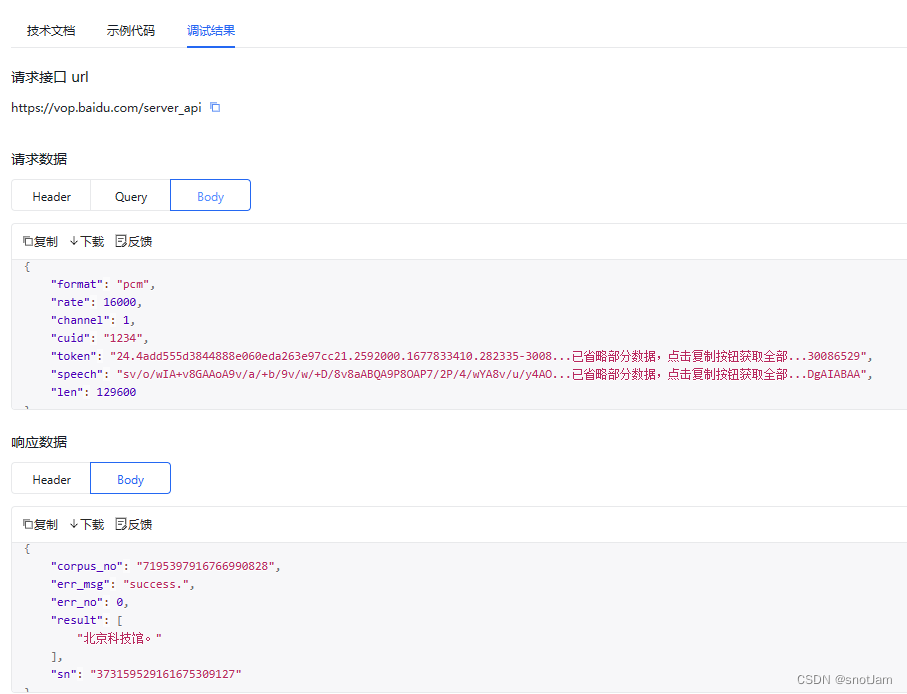
注意调用的接口和传参,其中的speech:
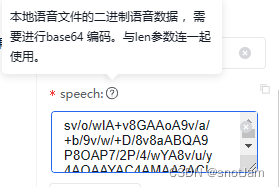
但是小程序和这个官方示例的不太相同,如果uni小程序也使用官方的流程,是拿不到结果的
uniapp小程序实现
设置录音相关
1: 通过uni.getRecorderManager()的来获取录音,设置其录音结束的监听
const recoderManager = uni.getRecorderManager()
const innerAudioContext = uni.createInnerAudioContext()
innerAudioContext.autoplay = true
在onload中设置结束监听
// 设置录音结束监听
recoderManager.onStop(function(res) {self.voicepath = res.tempFilePath // self.voicepath是获取到的录音后的音频文件地址if (self.voicepath != null || self.voicepath != "") {self.readFile(self.voicepath)}
})
设置请求相关
请求地址的拼接
百度示例的请求地址是:‘http://vop.baidu.com/server_api’,
baiduVoice: 'http://vop.baidu.com/server_api',
这里在请求到token后,进行了拼接:
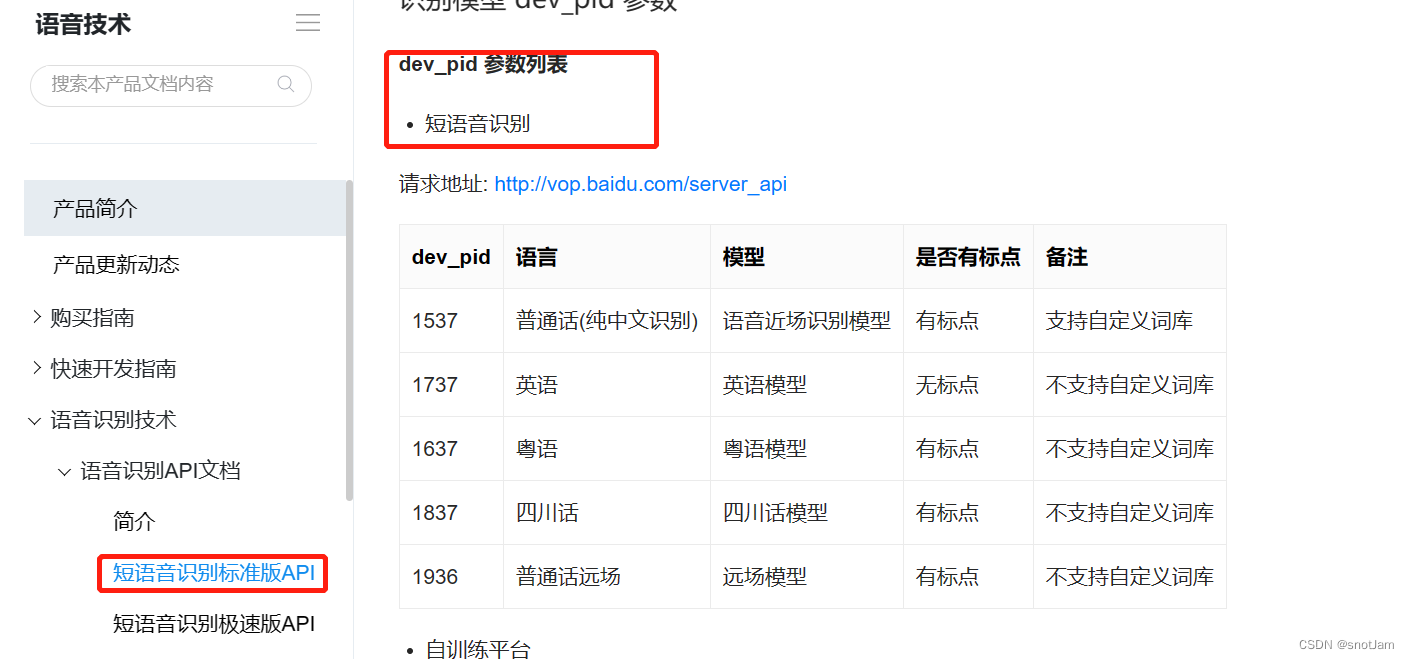
this.baiduVoice + '?cuid=' + this.appid + '&token=' + this.token + '&dev_pid=' + '1537'
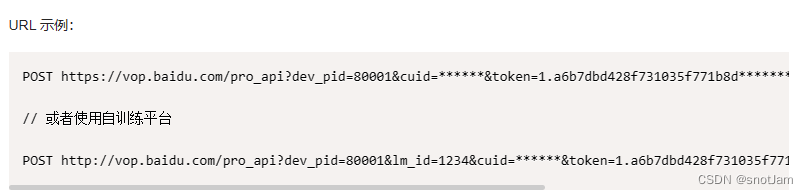
明显看出来,拼接了appid,token信息,最后的1537表示是普通话
读取文件,请求接口
// 读取文件,获取文件流
readFile(voiceFilepath) {uni.getFileSystemManager().readFile({filePath: voiceFilepath,success: (res) => {console.log(res.data)this.getRecognizeResult(res.data)},fail: (res) => {console.log('编码失败:' + res)}})
},/**
* 获取上传文件的结果*/
getRecognizeResult(speechResult) {uni.request({url: this.baiduVoice, // 这个地址是百度地址加了其他参数拼接method: "POST",header: {"Content-Type": "audio/pcm;rate=16000" // 主意这个header},data: speechResult,success: (res) => {console.log('请求成功')console.log(res.data.result[0])this.result = res.data.result[0]},fail: (res) => {console.log('请求失败')console.log(res)}})
}
至此,我们可以获取到想要的结果了
参考博文
极速版
基本与标准版一样,不同处
1:需要在百度应用领取相关的免费次数
2:url拼接的dev_pid为’80001’
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!