GLADNet 代码解释
在看图像增强的论文,解析大佬的代码,一行一行死磕,先上完整的主函数代码。
main.py
from __future__ import print_function
import os
from glob import globimport tensorflow.compat.v1 as tffrom model import lowlight_enhance
from utils import load_images# 参数配置
# 运行前一定确定参数配置正确
use_gpu = 0 # 固定数值,不要修改
# gpu_idx = 0
# gpu_mem = 1.5
phase = "test" # 固定数值,不要修改
save_dir = "./result" # 想要保存结果的目录,按需修改
test_dir = "./pic" # 想要进行图片增强处理的图片位置,按需修改def lowlight_train(lowlight_enhance):if not os.path.exists(ckpt_dir):os.makedirs(ckpt_dir)if not os.path.exists(sample_dir):os.makedirs(sample_dir)train_low_data = []train_high_data = []train_low_data_names = glob('/mnt/hdd/wangwenjing/FGtraining/low/*.png') # ./data/train/low/*.png')train_low_data_names.sort()train_high_data_names = glob('/mnt/hdd/wangwenjing/FGtraining/normal/*.png') # ./data/train/normal/*.png')train_high_data_names.sort()assert len(train_low_data_names) == len(train_high_data_names)print('[*] Number of training data: %d' % len(train_low_data_names))for idx in range(len(train_low_data_names)):if (idx + 1) % 1000 == 0:print(idx + 1)low_im = load_images(train_low_data_names[idx])train_low_data.append(low_im)high_im = load_images(train_high_data_names[idx])train_high_data.append(high_im)eval_low_data = []eval_high_data = []eval_low_data_name = glob('./data/eval/low/*.*')for idx in range(len(eval_low_data_name)):eval_low_im = load_images(eval_low_data_name[idx])eval_low_data.append(eval_low_im)lowlight_enhance.train(train_low_data, train_high_data, eval_low_data, batch_size=batch_size, patch_size=patch_size,epoch=epoch, sample_dir=sample_dir, ckpt_dir=ckpt_dir, eval_every_epoch=eval_every_epoch)def lowlight_test(lowlight_enhance):if not test_dir:print("[!] please provide --test_dir")exit(0)if not os.path.exists(save_dir):os.makedirs(save_dir)test_low_data_name = glob(os.path.join(test_dir) + '/*.*')test_low_data = []test_high_data = []for idx in range(len(test_low_data_name)):test_low_im = load_images(test_low_data_name[idx])test_low_data.append(test_low_im)lowlight_enhance.test(test_low_data, test_high_data, test_low_data_name, save_dir=save_dir)def main(_):if use_gpu:print("[*] GPU\n")# os.environ["CUDA_VISIBLE_DEVICES"] = gpu_idxgpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_mem)with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:model = lowlight_enhance(sess)if phase == 'train':lowlight_train(model)elif phase == 'test':lowlight_test(model)else:print('[!] Unknown phase')exit(0)else:print("[*] CPU\n")with tf.Session() as sess:model = lowlight_enhance(sess)if phase == 'train':lowlight_train(model)elif phase == 'test':lowlight_test(model)else:print('[!] Unknown phase')exit(0)if __name__ == '__main__':tf.app.run()
- 开始解析
from __future__ import print_function
在开头加上这句之后,即使在python2.X,使用print就得像python3.X那样加括号使用。python2.X中print不需要括号,而在python3.X中则需加括号。如果某个版本中出现了某个新的功能特性,而且这个特性和当前版本中使用的不兼容,也就是它在该版本中不是语言标准,那么我如果想要使用的话就需要从future模块导入。
import os
os是一种常用模块
python import os模块常用函数感谢🥳
from glob import glob
glob是检索文件的函数,有三种用法。
- 1检索当前目录下所有文件、文件夹
from glob import glob
glob('./*')
Output: ['./0a.wav', './aaa', './1b.wav', './1a.wav', './0b.wav']#返回一个list
- 2检索当前目录下指定后缀名文件
from glob import glob
glob('./*.wav')
Output: ['./0a.wav', './1b.wav', './1a.wav', './0b.wav'] #返回一个包含".wav"文件路径的list
- 3检索当前目录下包含指定字符文件
from glob import glob
glob('./*a*.wav')
Output: ['./0a.wav', './1a.wav'] #返回一个包含".wav"文件路径的list
import tensorflow.compat.v1 as tf
引入tensorflow吧应该是的
from model import lowlight_enhance
from 模块名 import 方法1,方法2…:从模块中导入部分工具,调用模块方法不需要模块名,直接调用方法.那就是从model中调用lowlight_enhance的方法。
from utils import load_images
从utils调用 load_images的方法
phase = "test"
不太明白大概是一个地址
save_dir = "./result" # 想要保存结果的目录,按需修改
test_dir = "./pic" # 想要进行图片增强处理的图片位置,按需修改
需要保存的图像地址和需要测试的图像地址
- 定义lowlight_train函数
def lowlight_train(lowlight_enhance):if not os.path.exists(ckpt_dir):os.makedirs(ckpt_dir)if not os.path.exists(sample_dir):os.makedirs(sample_dir)
定义lowlight_train这个函数,os.path.exists(path)
如果path存在,返回True;如果path不存在,返回False;if not 就是if取反,如果不存在,则返回true,否则返回false。如果ckpt_dir不存在,就生成ckpt_dir.
train_low_data = []train_high_data = []
建两个空白list
train_low_data_names = glob('/mnt/hdd/wangwenjing/FGtraining/low/*.png') # ./data/train/low/*.png')train_low_data_names.sort()train_high_data_names = glob('/mnt/hdd/wangwenjing/FGtraining/normal/*.png') # ./data/train/normal/*.png')train_high_data_names.sort()assert len(train_low_data_names) == len(train_high_data_names)print('[*] Number of training data: %d' % len(train_low_data_names))
把路径下的.png图片存储在train_low_data_names和train_high_data_names中,并进行排序。
assert是断言函数,满足条件则直接触发异常,不必执行接下来的代码,train_low_data_names和train_high_data_names项目个数必须相等,否则不执行下面的。
[*]的意思是所有值放在一个元祖里面Python中的*(星号)和**(双星号)完全详解
%s 格式化字符串,%d是整型,%f是浮点型
for idx in range(len(train_low_data_names)):if (idx + 1) % 1000 == 0:print(idx + 1)low_im = load_images(train_low_data_names[idx])train_low_data.append(low_im)high_im = load_images(train_high_data_names[idx])train_high_data.append(high_im)
for i in range() 是用来给i赋值
range函数原型:range(start,end,scan)
start:计数开始的位置,默认是从0开始
end:计数结束的位置
scan:每次跳跃的间距,默认为1
(idx+1)%1000==0表示括号内的数字对1000取余数等于0,则print(idx+1)
append() 追加单个元素到List的尾部,只接受一个参数,参数可以是任何数据类型,被追加的元素在List中保持着原结构类型。
这段代码的大意是:先数一下train_low_data_names的图像数量,然后按顺序load到各自的data里面,但是我不太明白为什么要print(idx+1)🤔🤔🤔🤔🤔🤔🤔🤔
eval_low_data = []eval_high_data = []eval_low_data_name = glob('./data/eval/low/*.*')for idx in range(len(eval_low_data_name)):eval_low_im = load_images(eval_low_data_name[idx])eval_low_data.append(eval_low_im)
建两个空白测试的data list,在指定文件夹下检索文件放到eval_low_data_name里,还是按顺序来load到data中。
lowlight_enhance.train(train_low_data, train_high_data, eval_low_data, batch_size=batch_size, patch_size=patch_size,epoch=epoch, sample_dir=sample_dir, ckpt_dir=ckpt_dir, eval_every_epoch=eval_every_epoch)
定义训练的options 训练集、测试集、batch size 、patch size、epoch、路径、测试每个epoch
- 定义lowlight_test函数
def lowlight_test(lowlight_enhance):if not test_dir:print("[!] please provide --test_dir")exit(0)if not os.path.exists(save_dir):os.makedirs(save_dir)test_low_data_name = glob(os.path.join(test_dir) + '/*.*')test_low_data = []test_high_data = []for idx in range(len(test_low_data_name)):test_low_im = load_images(test_low_data_name[idx])test_low_data.append(test_low_im)lowlight_enhance.test(test_low_data, test_high_data, test_low_data_name, save_dir=save_dir)
如果test_dirl不存在,就print [!] please provide --test_dir 查了半天[!]啥意思,后来在pycharm试了下,没有意思🙄
exit(0):无错误退出
exit(1):有错误退出
如果save_dir不存在,就创建路径
检索test_dir下的文件放到test_low_data_name中,创建两个空白测试list,并加载到test_low_data中,定义测试的options,这里具体不是很懂🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔
- 定义main函数
def main(_):if use_gpu:print("[*] GPU\n")# os.environ["CUDA_VISIBLE_DEVICES"] = gpu_idxgpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_mem)with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:model = lowlight_enhance(sess)if phase == 'train':lowlight_train(model)elif phase == 'test':lowlight_test(model)else:print('[!] Unknown phase')exit(0)else:print("[*] CPU\n")with tf.Session() as sess:model = lowlight_enhance(sess)if phase == 'train':lowlight_train(model)elif phase == 'test':lowlight_test(model)else:print('[!] Unknown phase')exit(0)
如果用GPU的话,print [] GPU,定义一写GPU的options
如果路径是train的话就执行lowlight_train(model),test的话就执行lowlight_test(model),否则print [!] Unknown phase
使用with tf.Session()创建上下文(Context)来执行,当上下文退出时自动释放
如果用CPU的话,print[] CPU,
tf.Session()理解:
TensorFlow的所有运行操作,都必须在打开的Seesion下执行,Session就像一个操作台,所有的操作都在这个操作台上运行。
我薛微总结了一下TensorFlow的机制,大致是这样的
做一堆变量声明
做一堆操作声明(通过中间操作名来传递操作,假设为有一个operate())
做一个变量初始化的操作声明(init() # 在本例中没有体现这一步)创建sess = Session()在Session下执行初始化(sess.init() # # 在本例中没有体现这一步)
在Session下执行操作(sess.operate(),这时候就会一步一步去追溯你声明好的操作流程,完成操作)
在创建Session之前,所有的操作都是在声明,就像编程的时候在mian()函数之前定义了很多函数(我上面说道的操作),但都是放在那,只是定义了数据处理规则,并不真正的执行,直到main()函数(Session)时,才调用函数完成操作。
import tensorflow as tf# session拥有并管理TensorFlow程序运行时的所有资源,所有计算完成之后会话来帮助系统回收资源,以免资源泄露matrix1 = tf.constant([[3, 3]]) # 声明tf常量
matrix2 = tf.constant([[2], [2]])product = tf.matmul(matrix1, matrix2) # 矩阵乘法np.dot(m1, m2)# Session写法 1
sess = tf.Session()
result = sess.run(product)
print(result) # [[12]]
sess.close()# Session写法 2
with tf.Session() as sess:result = sess.run(product)print(result) # [[12]]
# with控制范围结束自动.close()
转载tf.Session()理解
if __name__ == '__main__':tf.app.run()
通俗的理解__name__ == ‘main’:假如你叫小明.py,在朋友眼中,你是小明(name == ‘小明’);在你自己眼中,你是你自己(name == ‘main’)。
if name == 'main’的意思是:当.py文件被直接运行时,if name == 'main’之下的代码块将被运行;当.py文件以模块形式被导入时,if name == 'main’之下的代码块不被运行。
说白了,有两种情况:
如果你的代码中的入口函数不叫main(),而是一个其他名字的函数,如test(),则你应该这样写入口tf.app.run(test)
如果你的代码中的入口函数叫main(),则你就可以把入口写成tf.app.run()
model.py
from __future__ import print_functionimport os
import time
import randomfrom PIL import Image
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()import numpy as npfrom utils import *def FG(input_im):with tf.variable_scope('FG'):input_rs = tf.image.resize_nearest_neighbor(input_im, (96, 96))p_conv1 = tf.layers.conv2d(input_rs, 64, 3, 2, padding='same', activation=tf.nn.relu) # 48p_conv2 = tf.layers.conv2d(p_conv1, 64, 3, 2, padding='same', activation=tf.nn.relu) # 24p_conv3 = tf.layers.conv2d(p_conv2, 64, 3, 2, padding='same', activation=tf.nn.relu) # 12p_conv4 = tf.layers.conv2d(p_conv3, 64, 3, 2, padding='same', activation=tf.nn.relu) # 6p_conv5 = tf.layers.conv2d(p_conv4, 64, 3, 2, padding='same', activation=tf.nn.relu) # 3p_conv6 = tf.layers.conv2d(p_conv5, 64, 3, 2, padding='same', activation=tf.nn.relu) # 1p_deconv1 = tf.image.resize_nearest_neighbor(p_conv6, (3, 3))p_deconv1 = tf.layers.conv2d(p_deconv1, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv1 = p_deconv1 + p_conv5p_deconv2 = tf.image.resize_nearest_neighbor(p_deconv1, (6, 6))p_deconv2 = tf.layers.conv2d(p_deconv2, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv2 = p_deconv2 + p_conv4p_deconv3 = tf.image.resize_nearest_neighbor(p_deconv2, (12, 12))p_deconv3 = tf.layers.conv2d(p_deconv3, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv3 = p_deconv3 + p_conv3p_deconv4 = tf.image.resize_nearest_neighbor(p_deconv3, (24, 24))p_deconv4 = tf.layers.conv2d(p_deconv4, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv4 = p_deconv4 + p_conv2p_deconv5 = tf.image.resize_nearest_neighbor(p_deconv4, (48, 48))p_deconv5 = tf.layers.conv2d(p_deconv5, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv5 = p_deconv5 + p_conv1p_deconv6 = tf.image.resize_nearest_neighbor(p_deconv5, (96, 96))p_deconv6 = tf.layers.conv2d(p_deconv6, 64, 3, 1, padding='same', activation=tf.nn.relu)p_output = tf.image.resize_nearest_neighbor(p_deconv6, (tf.shape(input_im)[1], tf.shape(input_im)[2]))a_input = tf.concat([p_output, input_im], axis=3)a_conv1 = tf.layers.conv2d(a_input, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv2 = tf.layers.conv2d(a_conv1, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv3 = tf.layers.conv2d(a_conv2, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv4 = tf.layers.conv2d(a_conv3, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv5 = tf.layers.conv2d(a_conv4, 3, 3, 1, padding='same', activation=tf.nn.relu)return a_conv5class lowlight_enhance(object):def __init__(self, sess):self.sess = sessself.base_lr = 0.001self.input_low = tf.placeholder(tf.float32, [None, None, None, 3], name='input_low')self.input_high = tf.placeholder(tf.float32, [None, None, None, 3], name='input_high')self.output = FG(self.input_low)self.loss = tf.reduce_mean(tf.abs((self.output - self.input_high) * [[[[0.11448, 0.58661, 0.29891]]]]))self.global_step = tf.Variable(0, trainable=False)self.lr = tf.train.exponential_decay(self.base_lr, self.global_step, 100, 0.96)optimizer = tf.train.AdamOptimizer(self.lr, name='AdamOptimizer')self.train_op = optimizer.minimize(self.loss, global_step=self.global_step)self.sess.run(tf.global_variables_initializer())self.saver = tf.train.Saver()print("[*] Initialize model successfully...")def evaluate(self, epoch_num, eval_low_data, sample_dir):print("[*] Evaluating for epoch %d..." % (epoch_num))for idx in range(len(eval_low_data)):input_low_eval = np.expand_dims(eval_low_data[idx], axis=0)result = self.sess.run(self.output, feed_dict={self.input_low: input_low_eval})save_images(os.path.join(sample_dir, 'eval_%d_%d.png' % (idx + 1, epoch_num)), input_low_eval, result)def train(self, train_low_data, train_high_data, eval_low_data, batch_size, patch_size, epoch, sample_dir, ckpt_dir, eval_every_epoch):assert len(train_low_data) == len(train_high_data)numBatch = len(train_low_data) // int(batch_size)load_model_status, global_step = self.load(self.saver, ckpt_dir)if load_model_status:iter_num = global_stepstart_epoch = global_step // numBatchstart_step = global_step % numBatchprint("[*] Model restore success!")else:iter_num = 0start_epoch = 0start_step = 0print("[*] Not find pretrained model!")print("[*] Start training with start epoch %d start iter %d : " % (start_epoch, iter_num))start_time = time.time()image_id = 0for epoch in range(start_epoch, epoch):for batch_id in range(start_step, numBatch):# generate data for a batchbatch_input_low = np.zeros((batch_size, patch_size, patch_size, 3), dtype="float32")batch_input_high = np.zeros((batch_size, patch_size, patch_size, 3), dtype="float32")for patch_id in range(batch_size):h, w, _ = train_low_data[image_id].shapex = random.randint(0, h - patch_size)y = random.randint(0, w - patch_size)rand_mode = random.randint(0, 7)batch_input_low[patch_id, :, :, :] = data_augmentation(train_low_data[image_id][x : x+patch_size, y : y+patch_size, :], rand_mode)batch_input_high[patch_id, :, :, :] = data_augmentation(train_high_data[image_id][x : x+patch_size, y : y+patch_size, :], rand_mode)image_id = (image_id + 1) % len(train_low_data)if image_id == 0:tmp = list(zip(train_low_data, train_high_data))random.shuffle(list(tmp))train_low_data, train_high_data = zip(*tmp)# train_, loss = self.sess.run([self.train_op, self.loss], feed_dict={self.input_low: batch_input_low, \self.input_high: batch_input_high})print("Epoch: [%2d] [%4d/%4d] time: %4.4f, loss: %.6f" \% (epoch + 1, batch_id + 1, numBatch, time.time() - start_time, loss))iter_num += 1# evalutate the model and save a checkpoint file for itif (epoch + 1) % eval_every_epoch == 0:self.evaluate(epoch + 1, eval_low_data, sample_dir=sample_dir)self.save(self.saver, iter_num, ckpt_dir, "GLADNet")print("[*] Finish training")def save(self, saver, iter_num, ckpt_dir, model_name):if not os.path.exists(ckpt_dir):os.makedirs(ckpt_dir)print("[*] Saving model %s" % model_name)saver.save(self.sess, os.path.join(ckpt_dir, model_name), global_step=iter_num)def load(self, saver, ckpt_dir):ckpt = tf.train.get_checkpoint_state(ckpt_dir)if ckpt and ckpt.model_checkpoint_path:full_path = tf.train.latest_checkpoint(ckpt_dir)try:global_step = int(full_path.split('/')[-1].split('-')[-1])except ValueError:global_step = Nonesaver.restore(self.sess, full_path)return True, global_stepelse:print("[*] Failed to load model from %s" % ckpt_dir)return False, 0def test(self, test_low_data, test_high_data, test_low_data_names, save_dir):tf.global_variables_initializer().run()print("[*] Reading checkpoint...")load_model_status, _ = self.load(self.saver, './model/')if load_model_status:print("[*] Load weights successfully...")print("[*] Testing...")total_run_time = 0.0for idx in range(len(test_low_data)):print(test_low_data_names[idx])[_, name] = os.path.split(test_low_data_names[idx])suffix = name[name.find('.') + 1:]name = name[:name.find('.')]input_low_test = np.expand_dims(test_low_data[idx], axis=0)start_time = time.time()result = self.sess.run(self.output, feed_dict={self.input_low: input_low_test})total_run_time += time.time() - start_timesave_images(os.path.join(save_dir, name + "_glad." + suffix), result)ave_run_time = total_run_time / float(len(test_low_data))print("[*] Average run time: %.4f" % ave_run_time)
- import
from __future__ import print_functionimport os
import time
import randomfrom PIL import Image
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()import numpy as npfrom utils import *
import time时间模块
import random随机模块
PIL的Image模块
Image模块是在Python PIL图像处理中常见的模块,对图像进行基础操作的功能基本都包含于此模块内。如open、save、conver、show…等功能。
import numpy as np
为什么要用numpy
Python中提供了list容器,可以当作数组使用。但列表中的元素可以是任何对象,因此列表中保存的是对象的指针,这样一来,为了保存一个简单的列表[1,2,3]。就需要三个指针和三个整数对象。对于数值运算来说,这种结构显然不够高效。
Python虽然也提供了array模块,但其只支持一维数组,不支持多维数组(在TensorFlow里面偏向于矩阵理解),也没有各种运算函数。因而不适合数值运算。
NumPy的出现弥补了这些不足。
导入模块中的属性、方法和类,星号代表可以导入的所有属性、方法和类。
- 定义FG函数
def FG(input_im):with tf.variable_scope('FG'):input_rs = tf.image.resize_nearest_neighbor(input_im, (96, 96))p_conv1 = tf.layers.conv2d(input_rs, 64, 3, 2, padding='same', activation=tf.nn.relu) # 48p_conv2 = tf.layers.conv2d(p_conv1, 64, 3, 2, padding='same', activation=tf.nn.relu) # 24p_conv3 = tf.layers.conv2d(p_conv2, 64, 3, 2, padding='same', activation=tf.nn.relu) # 12p_conv4 = tf.layers.conv2d(p_conv3, 64, 3, 2, padding='same', activation=tf.nn.relu) # 6p_conv5 = tf.layers.conv2d(p_conv4, 64, 3, 2, padding='same', activation=tf.nn.relu) # 3p_conv6 = tf.layers.conv2d(p_conv5, 64, 3, 2, padding='same', activation=tf.nn.relu) # 1p_deconv1 = tf.image.resize_nearest_neighbor(p_conv6, (3, 3))p_deconv1 = tf.layers.conv2d(p_deconv1, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv1 = p_deconv1 + p_conv5p_deconv2 = tf.image.resize_nearest_neighbor(p_deconv1, (6, 6))p_deconv2 = tf.layers.conv2d(p_deconv2, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv2 = p_deconv2 + p_conv4p_deconv3 = tf.image.resize_nearest_neighbor(p_deconv2, (12, 12))p_deconv3 = tf.layers.conv2d(p_deconv3, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv3 = p_deconv3 + p_conv3p_deconv4 = tf.image.resize_nearest_neighbor(p_deconv3, (24, 24))p_deconv4 = tf.layers.conv2d(p_deconv4, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv4 = p_deconv4 + p_conv2p_deconv5 = tf.image.resize_nearest_neighbor(p_deconv4, (48, 48))p_deconv5 = tf.layers.conv2d(p_deconv5, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv5 = p_deconv5 + p_conv1p_deconv6 = tf.image.resize_nearest_neighbor(p_deconv5, (96, 96))p_deconv6 = tf.layers.conv2d(p_deconv6, 64, 3, 1, padding='same', activation=tf.nn.relu)p_output = tf.image.resize_nearest_neighbor(p_deconv6, (tf.shape(input_im)[1], tf.shape(input_im)[2]))a_input = tf.concat([p_output, input_im], axis=3)a_conv1 = tf.layers.conv2d(a_input, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv2 = tf.layers.conv2d(a_conv1, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv3 = tf.layers.conv2d(a_conv2, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv4 = tf.layers.conv2d(a_conv3, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv5 = tf.layers.conv2d(a_conv4, 3, 3, 1, padding='same', activation=tf.nn.relu)return a_conv5
with tf.variable_scope(‘FG’): 创建一个新变量‘FG’
input_rs = tf.image.resize_nearest_neighbor(input_im, (96, 96))
tf.image.resize_nearest_neighbor(images,size,align_corners=False,name=None
)
使用最近邻插值调整images为size.
参数: images:一个Tensor,必须是下列类型之一: int8,uint8,int16,uint16,int32,int64,half,float32,float64.4-D与形状[batch, height, width, channels].
size:2个元素(new_height, new_width)的1维int32张量,表示图像的新大小.
align_corners:可选的bool,默认为False,如果为True,则输入和输出张量的4个角像素的中心对齐,并保留角落像素处的值.
name:操作的名称(可选).
返回:该函数与images具有相同类型的Tensor.
把图像调整为96乘96乘8
p_conv1 = tf.layers.conv2d(input_rs, 64, 3, 2, padding='same', activation=tf.nn.relu) # 48p_conv2 = tf.layers.conv2d(p_conv1, 64, 3, 2, padding='same', activation=tf.nn.relu) # 24p_conv3 = tf.layers.conv2d(p_conv2, 64, 3, 2, padding='same', activation=tf.nn.relu) # 12p_conv4 = tf.layers.conv2d(p_conv3, 64, 3, 2, padding='same', activation=tf.nn.relu) # 6p_conv5 = tf.layers.conv2d(p_conv4, 64, 3, 2, padding='same', activation=tf.nn.relu) # 3p_conv6 = tf.layers.conv2d(p_conv5, 64, 3, 2, padding='same', activation=tf.nn.relu) # 1
TensorFlow定义的二维卷积有三种,分别是tf.nn.conv2d、tf.layers.conv2d、tf.contrib.layers.conv2d,个人认为tf.layers.conv2d使用起来更为方便简单,所以就记录下tf.layers.conv2d的使用方法。
tf.layers.conv2d(inputs, filters, kernel_size, strides, padding,activation)
p_deconv1 = tf.image.resize_nearest_neighbor(p_conv6, (3, 3))p_deconv1 = tf.layers.conv2d(p_deconv1, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv1 = p_deconv1 + p_conv5p_deconv2 = tf.image.resize_nearest_neighbor(p_deconv1, (6, 6))p_deconv2 = tf.layers.conv2d(p_deconv2, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv2 = p_deconv2 + p_conv4p_deconv3 = tf.image.resize_nearest_neighbor(p_deconv2, (12, 12))p_deconv3 = tf.layers.conv2d(p_deconv3, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv3 = p_deconv3 + p_conv3p_deconv4 = tf.image.resize_nearest_neighbor(p_deconv3, (24, 24))p_deconv4 = tf.layers.conv2d(p_deconv4, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv4 = p_deconv4 + p_conv2p_deconv5 = tf.image.resize_nearest_neighbor(p_deconv4, (48, 48))p_deconv5 = tf.layers.conv2d(p_deconv5, 64, 3, 1, padding='same', activation=tf.nn.relu)p_deconv5 = p_deconv5 + p_conv1p_deconv6 = tf.image.resize_nearest_neighbor(p_deconv5, (96, 96))p_deconv6 = tf.layers.conv2d(p_deconv6, 64, 3, 1, padding='same', activation=tf.nn.relu)
p_conv6调整为3✖️3✖️8 储存到p_deconv1
这里赵一下反卷积的文章看了一下,大概是这样:
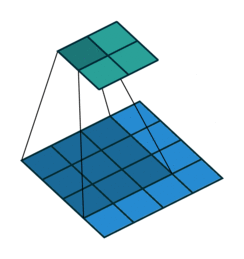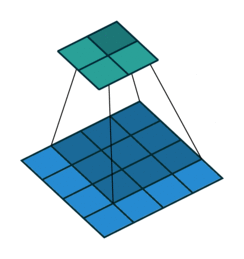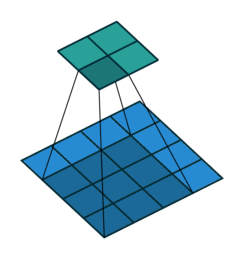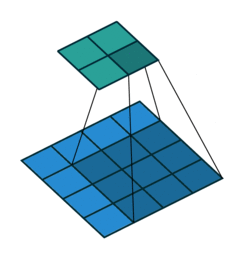
这是卷积的工作原理
如上图:4x4的输入,卷积Kernel为3x3, ,输出为2x2。其计算可以理解为:
输入矩阵展开为44=16维向量,记作x
输出矩阵展开为22=4维向量,记作y
卷积核C为如下矩阵: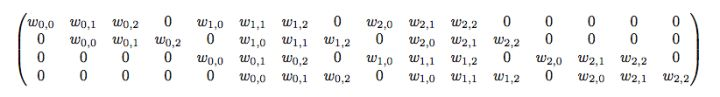 卷积运算可表示为y = Cx(可以对照动图理解)
卷积运算可表示为y = Cx(可以对照动图理解)
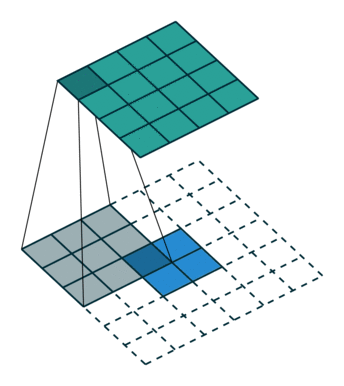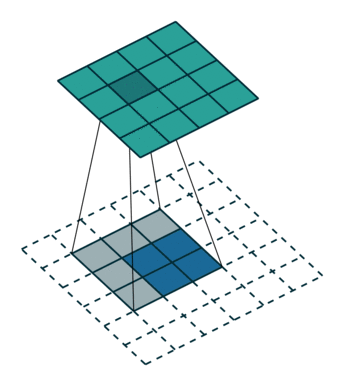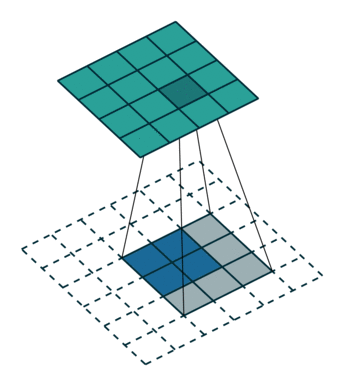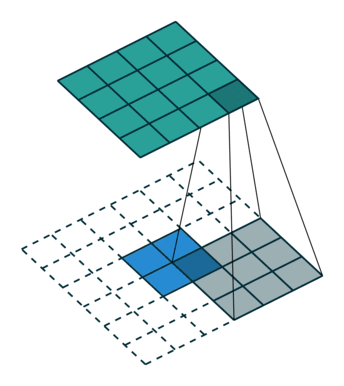
如上图:2x2的输入,卷积Kernel为3x3, ,输出为4x4。
如果按照正常卷积,生成的feature map尺寸应该减小,但是我们现在想要生成尺寸变大,就可以对输入进行padding。但与正常卷积padding不同的是:反卷积卷积运算的起点不一定在原feature map上,而是从padding区域开始。仔细看上面动图,可以看到第一个运算卷积核的中点在padding区域上。
反卷积相对于卷积在神经网络结构的正向和反向传播中做相反的运算
上采样➕下采样
转载关于反卷积的解释
讲的比较全面的文章 卷积神经网络CNN(1)——图像卷积与反卷积(后卷积,转置卷积)
p_output = tf.image.resize_nearest_neighbor(p_deconv6, (tf.shape(input_im)[1], tf.shape(input_im)[2]))a_input = tf.concat([p_output, input_im], axis=3)a_conv1 = tf.layers.conv2d(a_input, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv2 = tf.layers.conv2d(a_conv1, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv3 = tf.layers.conv2d(a_conv2, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv4 = tf.layers.conv2d(a_conv3, 128, 3, 1, padding='same', activation=tf.nn.relu)a_conv5 = tf.layers.conv2d(a_conv4, 3, 3, 1, padding='same', activation=tf.nn.relu)return a_conv5
shape参数的个数应为维度数,每一个参数的值代表该维度上的长度。
(tf.shape(input_im)[1]得到tensor imput_im 的尺寸第二维,tf.shape(input_im)[2]得到tensor imput_im 的尺寸第三维,重新调整p_deconv6的尺寸为input_im的第二维第三维。
tensorflow中用来拼接张量的函数tf.concat(),用法:
tf.concat([tensor1, tensor2, tensor3,...], axis)
源代码解释
t1 = [[1, 2, 3], [4, 5, 6]]t2 = [[7, 8, 9], [10, 11, 12]]tf.concat([t1, t2], 0) # [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]tf.concat([t1, t2], 1) # [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]]# tensor t3 with shape [2, 3]# tensor t4 with shape [2, 3]tf.shape(tf.concat([t3, t4], 0)) # [4, 3]tf.shape(tf.concat([t3, t4], 1)) # [2, 6]
axis=0 代表在第0个维度拼接
axis=1 代表在第1个维度拼接
axis=3 代表····我也不知道了,没有查到,🤔🤔🤔🤔🤔🤔,大概就是把output input连起来???
然后又开始创建卷积层,return返回函数的返回值,return a_conv5
- ##lowlight_enhance 类
class lowlight_enhance(object):
python的class(类)相当于一个多个函数组成的家族,如果在这个Myclass大家族里有一个人叫f,假如这个f具有print天气的作用,那么如果有一天我需要这个f来print一下今天的天气,那么我必须叫他的全名MyClass.f才可以让他给我print,即在调用他的时候需要带上他的家族名称+他的名称。
- 定义init函数
def __init__(self, sess):self.sess = sessself.base_lr = 0.001self.input_low = tf.placeholder(tf.float32, [None, None, None, 3], name='input_low')self.input_high = tf.placeholder(tf.float32, [None, None, None, 3], name='input_high')self.output = FG(self.input_low)self.loss = tf.reduce_mean(tf.abs((self.output - self.input_high) * [[[[0.11448, 0.58661, 0.29891]]]]))self.global_step = tf.Variable(0, trainable=False)self.lr = tf.train.exponential_decay(self.base_lr, self.global_step, 100, 0.96)optimizer = tf.train.AdamOptimizer(self.lr, name='AdamOptimizer')self.train_op = optimizer.minimize(self.loss, global_step=self.global_step)self.sess.run(tf.global_variables_initializer())self.saver = tf.train.Saver()print("[*] Initialize model successfully...")
初始化self,属性值sess
tf.placeholder(dtype, shape=None, name=None)存放数据的一个函数
此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
shape:数据形状。默认是None,就是一维值,也可以是多维,比如[2,3], [None, 3]表示列是3,行不定
name:名称。
损失函数的定义
tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
reduce_mean(input_tensor,
axis=None,
keepdims=None,
name=None,
reduction_indices=None,
keep_dims=None)
第一个参数input_tensor: 输入的待降维的tensor;
第二个参数axis: 指定的轴,如果不指定,则计算所有元素的均值;
第三个参数keepdims:是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度;
第四个参数name: 操作的名称;
第五个参数 reduction_indices:在以前版本中用来指定轴,已弃用;
第六个参数 keep_dims:keepdims参数的别名,已弃用。
tf.Variable(initializer, name)
功能:保存和更新神经网络中的参数。
参数:(1)initializer:初始化参数(2)name:变量名
decayed_learning_rate=learining_rate*decay_rate^(global_step/decay_steps)
其中,decayed_learning_rate为每一轮优化时使用的学习率;
learning_rate为事先设定的初始学习率;
decay_rate为衰减系数;
decay_steps为衰减速度。
tf.train.AdamOptimizer()函数是Adam优化算法:是一个寻找全局最优点的优化算法
tf.train.AdamOptimizer.__init__(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name='Adam'
)
初始化一个optimizer之后,通过minimize函数,最小化损失函数
一步步看源代码:(代码在后面)
tensorflow讲堂 sess.run(tf.global_variables_initializer()) 做了什么?
global_variables_initializer 返回一个用来初始化 计算图中 所有global variable的 op。
这个op 到底是啥,还不清楚。
函数中调用了 variable_initializer() 和 global_variables()
global_variables() 返回一个 Variable list ,里面保存的是 gloabal variables。
variable_initializer() 将 Variable list 中的所有 Variable 取出来,将其 variable.initializer 属性做成一个 op group。
然后看 Variable 类的源码可以发现, variable.initializer 就是一个 assign op。
所以: sess.run(tf.global_variables_initializer()) 就是 run了 所有global Variable 的 assign op,这就是初始化参数的本来面目。
保存
print("[*] Initialize model successfully…")
def evaluate(self, epoch_num, eval_low_data, sample_dir):print("[*] Evaluating for epoch %d..." % (epoch_num))for idx in range(len(eval_low_data)):input_low_eval = np.expand_dims(eval_low_data[idx], axis=0)result = self.sess.run(self.output, feed_dict={self.input_low: input_low_eval})save_images(os.path.join(sample_dir, 'eval_%d_%d.png' % (idx + 1, epoch_num)), input_low_eval, result)
定义测试函数,每轮print一下
测试data的长度,range
np.expand_dims(a, axis=0)表示在0位置添加数据
sess.run():参数 feed_dict等作用,替换图中的某个tensor的值,用测试图换原图
save
- 定义train函数
def train(self, train_low_data, train_high_data, eval_low_data, batch_size, patch_size, epoch, sample_dir, ckpt_dir, eval_every_epoch):assert len(train_low_data) == len(train_high_data)numBatch = len(train_low_data) // int(batch_size)load_model_status, global_step = self.load(self.saver, ckpt_dir)if load_model_status:iter_num = global_stepstart_epoch = global_step // numBatchstart_step = global_step % numBatchprint("[*] Model restore success!")else:iter_num = 0start_epoch = 0start_step = 0print("[*] Not find pretrained model!")print("[*] Start training with start epoch %d start iter %d : " % (start_epoch, iter_num))start_time = time.time()image_id = 0for epoch in range(start_epoch, epoch):for batch_id in range(start_step, numBatch):# generate data for a batchbatch_input_low = np.zeros((batch_size, patch_size, patch_size, 3), dtype="float32")batch_input_high = np.zeros((batch_size, patch_size, patch_size, 3), dtype="float32")for patch_id in range(batch_size):h, w, _ = train_low_data[image_id].shapex = random.randint(0, h - patch_size)y = random.randint(0, w - patch_size)rand_mode = random.randint(0, 7)batch_input_low[patch_id, :, :, :] = data_augmentation(train_low_data[image_id][x : x+patch_size, y : y+patch_size, :], rand_mode)batch_input_high[patch_id, :, :, :] = data_augmentation(train_high_data[image_id][x : x+patch_size, y : y+patch_size, :], rand_mode)image_id = (image_id + 1) % len(train_low_data)if image_id == 0:tmp = list(zip(train_low_data, train_high_data))random.shuffle(list(tmp))train_low_data, train_high_data = zip(*tmp)# train_, loss = self.sess.run([self.train_op, self.loss], feed_dict={self.input_low: batch_input_low, \self.input_high: batch_input_high})print("Epoch: [%2d] [%4d/%4d] time: %4.4f, loss: %.6f" \% (epoch + 1, batch_id + 1, numBatch, time.time() - start_time, loss))iter_num += 1# evalutate the model and save a checkpoint file for itif (epoch + 1) % eval_every_epoch == 0:self.evaluate(epoch + 1, eval_low_data, sample_dir=sample_dir)self.save(self.saver, iter_num, ckpt_dir, "GLADNet")print("[*] Finish training")
int() 函数用于将一个字符串或数字转换为整型。
" // "来表示整数除法
- 定义save函数
def save(self, saver, iter_num, ckpt_dir, model_name):if not os.path.exists(ckpt_dir):os.makedirs(ckpt_dir)print("[*] Saving model %s" % model_name)saver.save(self.sess, os.path.join(ckpt_dir, model_name), global_step=iter_num)
创建saver 如果path不存在就创建 ,print ,用saver保存
- 定义load函数
def load(self, saver, ckpt_dir):ckpt = tf.train.get_checkpoint_state(ckpt_dir)if ckpt and ckpt.model_checkpoint_path:full_path = tf.train.latest_checkpoint(ckpt_dir)try:global_step = int(full_path.split('/')[-1].split('-')[-1])except ValueError:global_step = Nonesaver.restore(self.sess, full_path)return True, global_stepelse:print("[*] Failed to load model from %s" % ckpt_dir)return False, 0
xxx.ckpt文件保存了TensorFlow程序中每一个变量的取值,checkpoint文件保存了一个目录下所有的模型文件列表。checkpoint文件的用途:可以记录模型训练的过程中的数据,并且可以实现在之前的训练基础上继续训练。
- 定义test函数
def test(self, test_low_data, test_high_data, test_low_data_names, save_dir):tf.global_variables_initializer().run()print("[*] Reading checkpoint...")load_model_status, _ = self.load(self.saver, './model/')if load_model_status:print("[*] Load weights successfully...")print("[*] Testing...")total_run_time = 0.0for idx in range(len(test_low_data)):print(test_low_data_names[idx])[_, name] = os.path.split(test_low_data_names[idx])suffix = name[name.find('.') + 1:]name = name[:name.find('.')]input_low_test = np.expand_dims(test_low_data[idx], axis=0)start_time = time.time()result = self.sess.run(self.output, feed_dict={self.input_low: input_low_test})total_run_time += time.time() - start_timesave_images(os.path.join(save_dir, name + "_glad." + suffix), result)ave_run_time = total_run_time / float(len(test_low_data))print("[*] Average run time: %.4f" % ave_run_time)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!