【翻译】ZooKeeper内部细节
Introduction
This document contains information on the inner workings of ZooKeeper. It discusses the following topics:
- Atomic Broadcast
- Consistency Guarantees
- Quorums
- Logging
简介
这篇文档包含ZooKeeper的内部实现细节。它包括了如下部分:
- 原子广播
- 一致性保证
- 法定数量(Quoram值)
- 日志
Atomic Broadcast
原子广播
At the heart of ZooKeeper is an atomic messaging system that keeps all of the servers in sync.
ZooKeeper的核心是一个原子的消息系统,可以让所有服务器保持一致。
Guarantees, Properties, and Definitions
保证,属性,定义
The specific guarantees provided by the messaging system used by ZooKeeper are the following:
ZooKeeper消息系统提供的具体保证有:
-
Reliable delivery : If a message m, is delivered by one server, message m will be eventually delivered by all servers.
可靠的传递:如果消息m被传递到一台服务器上,那么m终将传递到所有的服务器上。 -
Total order : If a message a is delivered before message b by one server, message a will be delivered before b by all servers.
全局序:如果消息a在消息b之前抵达某台服务器,那么消息a在所有的服务器上都在b之前抵达。 -
Causal order : If a message b is sent after a message a has been delivered by the sender of b, message a must be ordered before b. If a sender sends c after sending b, c must be ordered after b.
因果关系:如果发送者先发送a再发送b,那么a排序在b之前;如果发送者先发送b,再发送c,那么b排序在c之前。
The ZooKeeper messaging system also needs to be efficient, reliable, and easy to implement and maintain. We make heavy use of messaging, so we need the system to be able to handle thousands of requests per second. Although we can require at least k+1 correct servers to send new messages, we must be able to recover from correlated failures such as power outages. When we implemented the system we had little time and few engineering resources, so we needed a protocol that is accessible to engineers and is easy to implement. We found that our protocol satisfied all of these goals.
ZooKeeper消息系统同样需要高效,稳定,易于实现和维护。我们对消息重度使用,因此我们需要该系统每秒可以处理数千条请求。尽管我们可以要求至少有K+1台好的服务器来发送新消息,我们必须有能力从类似于停电的故障中恢复回来。当我们实现系统时,我们的时间和资源都很有限,因此我们需要一个对于开发者来说都是可获得的且易于实现的协议。最终发现我们的协议满足了所有的上述要求。
Our protocol assumes that we can construct point-to-point FIFO channels between the servers. While similar services usually assume message delivery that can lose or reorder messages, our assumption of FIFO channels is very practical given that we use TCP for communication. Specifically we rely on the following property of TCP:
我们的协议假设我们可以在服务器间建立一个端到端的先进先出管道。虽然类似的服务通常假定消息传递会丢失或重排序消息,但由于我们采用TCP链接,因此对于FIFO管道的假定非常符合实际。尤其在于我们依赖于TCP的以下特点:
- Ordered delivery : Data is delivered in the same order it is sent and a message m is delivered only after all messages sent before m have been delivered. (The corollary to this is that if message m is lost all messages after m will be lost.)
顺序的传递:数据以什么样的顺序发送,就以什么样的顺序接收,消息m只有当所有在m之前发送的消息抵达之后才会抵达。(因此,若m丢失,那么其后发送的所有消息都会丢失。) - No message after close : Once a FIFO channel is closed, no messages will be received from it.
关闭之后不再有消息:一旦FIFO管道被关闭,将不再能从中接收到消息。
FLP proved that consensus cannot be achieved in asynchronous distributed systems if failures are possible. To ensure that we achieve consensus in the presence of failures we use timeouts. However, we rely on time for liveness not for correctness. So, if timeouts stop working (e.g., skewed clocks) the messaging system may hang, but it will not violate its guarantees.
FLP证明了在一个有故障存在的异步的分布式系统中,一致性将无法保证。为了容忍故障且保证一致性,我们采用超时机制。然而,我们依赖于存活的时间,而非正确的时间。因此,当超时机制不工作时(比如:skewed clocks)整个消息传递系统可能会hang,但它将不会违反一致性。
When describing the ZooKeeper messaging protocol we will talk of packets, proposals, and messages:
当描述ZooKeeper消息协议时,我们会谈到报文,提议和消息:
-
Packet : a sequence of bytes sent through a FIFO channel.
报文:在FIFO管道上传输的字节序列。 -
Proposal : a unit of agreement. Proposals are agreed upon by exchanging packets with a quorum of ZooKeeper servers. Most proposals contain messages, however the NEW_LEADER proposal is an example of a proposal that does not contain to a message.
提议:共识的单位。当达到Quorum量的ZooKeeper服务器相互交换报文,则提议通过。大部分的提议包含消息,然后NEW_LEADER提议则例外。 -
Message : a sequence of bytes to be atomically broadcast to all ZooKeeper servers. A message put into a proposal and agreed upon before it is delivered.
消息:自动广播到所有ZooKeeper服务器的字节序列。一个消息被放到提议中,然后在传递前获得同意。
As stated above, ZooKeeper guarantees a total order of messages, and it also guarantees a total order of proposals. ZooKeeper exposes the total ordering using a ZooKeeper transaction id (zxid). All proposals will be stamped with a zxid when it is proposed and exactly reflects the total ordering. Proposals are sent to all ZooKeeper servers and committed when a quorum of them acknowledge the proposal. If a proposal contains a message, the message will be delivered when the proposal is committed. Acknowledgement means the server has recorded the proposal to persistent storage. Our quorums have the requirement that any pair of quorum must have at least one server in common. We ensure this by requiring that all quorums have size (n/2+1) where n is the number of servers that make up a ZooKeeper service.
如上述,ZooKeeper保证了消息的全局顺序,它也保证了提议的全局顺序。ZooKeeper通过ZooKeeper日志号(zxid)来对外暴露全局序。所有的提议都打上zxid序号。提议被发送到所有的ZooKeeper服务器,并且当Quorum集合中的服务器都确认提议后得以提交。当一个提议包含消息,那么消息在提议被提交时被传递。
确认意味着服务器记录下了这个提议,并持久化到硬盘中。我们的Quorum设置要求任何一对Quorum集合必须有至少一台机器重叠。我们通过要求所有Quorum的大小为 n/2+1 来保证这一点,n是服务器的数量。
The zxid has two parts: the epoch and a counter. In our implementation the zxid is a 64-bit number. We use the high order 32-bits for the epoch and the low order 32-bits for the counter. Because zxid consists of two parts, zxid can be represented both as a number and as a pair of integers, (epoch, count). The epoch number represents a change in leadership. Each time a new leader comes into power it will have its own epoch number. We have a simple algorithm to assign a unique zxid to a proposal: the leader simply increments the zxid to obtain a unique zxid for each proposal. Leadership activation will ensure that only one leader uses a given epoch, so our simple algorithm guarantees that every proposal will have a unique id.
zxid有两部分组成:epoch和counter。在我们的视线中zxid是一个64-bit的值。我们使用高32位做epoch,低32位做counter。因为zxid包含两部分,zxid可以表示成数字,也可以表示成一对整数(epoch, counter)。epoch代表了leadership发生了变化。每当新的leader产生,它将拥有自己的epoch值。我们用一个简单的算法来保证每个提议的zxid都是唯一的:Leader只需要对counter加1来产生每一个提议唯一的zxid。Leader生效阶段可以保证只有一个leader使用给定的epoch,所以我们的简单算法保证了每个提议都有一个唯一id。
ZooKeeper messaging consists of two phases:
ZooKeeper消息包含两个阶段:
-
Leader activation : In this phase a leader establishes the correct state of the system and gets ready to start making proposals.
Leader生效阶段:在该阶段中,一个Leader建立了系统的正确状态,并且为开始发起新的提议做好准备。 -
Active messaging : In this phase a leader accepts messages to propose and coordinates message delivery.
有效的消息阶段:在这个阶段,Leader接收提议,并协调消息的传递。
ZooKeeper is a holistic protocol. We do not focus on individual proposals, rather look at the stream of proposals as a whole. Our strict ordering allows us to do this efficiently and greatly simplifies our protocol. Leadership activation embodies this holistic concept. A leader becomes active only when a quorum of followers (The leader counts as a follower as well. You can always vote for yourself ) has synced up with the leader, they have the same state. This state consists of all of the proposals that the leader believes have been committed and the proposal to follow the leader, the NEW_LEADER proposal. (Hopefully you are thinking to yourself, Does the set of proposals that the leader believes has been committed include all the proposals that really have been committed? The answer is yes. Below, we make clear why.)
ZooKeeper是一个整体的协议。我们并不集中在单个提议上,而是整体上去处理一系列提议。我们的严格序使得我们可以高效,简洁的实现该协议。Leader生效阶段就隐含了该整体性的思想。一个Leader只有当Quorum里的Follower(包括Leader自身)都同意了,并与之同步,并拥有同样的状态,才可以生效。这个状态包含了所有的Leader认为已提交的提议以及跟随该Leader的提议,即NEW_LEADER提议。
(希望你可以自己思考,Leader认为已经提交的提议是否包含了所有的已经提交的协议?答案是的。我们将解释为什么。)
Leader Activation
Leader生效阶段
Leader activation includes leader election (FastLeaderElection). ZooKeeper messaging doesn’t care about the exact method of electing a leader as long as the following holds:
Leader生效阶段包括Leader选举(快速Leader选举)。ZooKeeper消息机制并不关心选举一个Leader的确切方法,只要下述要求得到满足:
-
The leader has seen the highest zxid of all the followers.
一个Leader可以看到所有Follower中最大的zxid。 -
A quorum of servers have committed to following the leader.
Quorum数量的服务器提交了服从该Leader。
Of these two requirements only the first, the highest zxid among the followers needs to hold for correct operation. The second requirement, a quorum of followers, just needs to hold with high probability. We are going to recheck the second requirement, so if a failure happens during or after the leader election and quorum is lost, we will recover by abandoning leader activation and running another election.
上述两条要求中,只有第一个是为了保证正确操作必须要满足的。第二个,则需要尽可能的满足。我们将重新检查第二个条件,因此如果在Leader选举过程中或之后发生故障,或者失去了quorum数量的Follower,我们将抛弃本次Leader生效阶段,重新开始下一轮选举。
After leader election a single server will be designated as a leader and start waiting for followers to connect. The rest of the servers will try to connect to the leader. The leader will sync up with the followers by sending any proposals they are missing, or if a follower is missing too many proposals, it will send a full snapshot of the state to the follower.
Leader选举之后,只有一台服务器可以被指派为Leader,并开始等待Follower来连接。剩下的服务器都尝试连接Leader。Leader会与所有的Follower同步,并将它们缺失的提议发送给它们,或者当某个Follower缺失了太多提议的话,它将发送整个状态的快照给Follower。
There is a corner case in which a follower that has proposals, U, not seen by a leader arrives. Proposals are seen in order, so the proposals of U will have a zxids higher than zxids seen by the leader. The follower must have arrived after the leader election, otherwise the follower would have been elected leader given that it has seen a higher zxid. Since committed proposals must be seen by a quorum of servers, and a quorum of servers that elected the leader did not see U, the proposals of U have not been committed, so they can be discarded. When the follower connects to the leader, the leader will tell the follower to discard U.
有一个边界情况,当Follower在Leader之前接收到提议U。提议是按顺序被看见的,所以U的最大的zxid比Leader的更大。那么该Follower必然是在Leader选举之后进来的,要不然,这个Follower就会成为Leader,因为它看到了最大的zxid。因为提交的提议必须被Quorum数量的服务器看到,然而还没有Quorum数量的服务器看到U,那么提议U必然还没有提交,因此U可以被丢弃。当该Follower连接到Leader的时候,Leader会通知该Follower丢弃U。
A new leader establishes a zxid to start using for new proposals by getting the epoch, e, of the highest zxid it has seen and setting the next zxid to use to be (e+1, 0), after the leader syncs with a follower, it will propose a NEW_LEADER proposal. Once the NEW_LEADER proposal has been committed, the leader will activate and start receiving and issuing proposals.
新的Leader采用它看到的最大的zxid作为e,之后所有新的提议采用的新的zxid从(e+1,0)开始计数,在Leader和Follower同步之后,它会提议NEW_LEADER。一旦NEW_LEADER提议被提交,这个Leader就生效了,并且开始接受和发送提议。
It all sounds complicated but here are the basic rules of operation during leader activation:
听起来有点复杂,但在Leader选举中有一个基本的守则:
-
A follower will ACK the NEW_LEADER proposal after it has synced with the leader.
一个Follower在和Leader同步之后将会确认NEW_LEADER提议。 -
A follower will only ACK a NEW_LEADER proposal with a given zxid from a single server.
一个Follower只会确认来自一台服务器的拥有给定zxid的NEW_LEADER提议。 -
A new leader will COMMIT the NEW_LEADER proposal when a quorum of followers has ACKed it.
当收到Quorum数量的Follower确认后,一个新的Leader将会提交NEW_LEADER提议。 -
A follower will commit any state it received from the leader when the NEW_LEADER proposal is COMMIT.
当NEW_LEADER提议被提交后,Follower将会提交它从Leader接受的任何状态。 -
A new leader will not accept new proposals until the NEW_LEADER proposal has been COMMITTED.
新的Leader将不再接收新的提议,直到NEW_LEADER提议被提交。
If leader election terminates erroneously, we don’t have a problem since the NEW_LEADER proposal will not be committed since the leader will not have quorum. When this happens, the leader and any remaining followers will timeout and go back to leader election.
当Leader选举错误终止时,我们不会遇到问题,因为Leader还没有收到Quorum数量的确认,所以NEW_LEADER提议并没有被提交。当发生失败时,Leader和其他Follower都会超时,然后重新回到Leader选举。
Active Messaging
有效的消息阶段
Leader Activation does all the heavy lifting. Once the leader is coronated he can start blasting out proposals. As long as he remains the leader no other leader can emerge since no other leader will be able to get a quorum of followers. If a new leader does emerge, it means that the leader has lost quorum, and the new leader will clean up any mess left over during her leadership activation.
Leader生效阶段做了所有复杂的自举操作。一旦Leader加冕成功,它可以开始广播提议。只要它还是Leader,那么将不会有其他Leader出现,因为其他Leader无法得到Quorum的Follower。一旦新的Leader出现了,就意味着原Leader失去了Quorum数量的Follower,那么新的Leader就会清理之前的残余。
ZooKeeper messaging operates similar to a classic two-phase commit.
ZooKeeper消息操作类似于经典的两阶段提交。
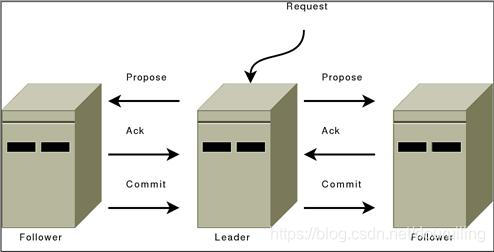
(左下的箭头方向反了)
-
All communication channels are FIFO, so everything is done in order. Specifically the following operating constraints are observed:
所有的通信管道都是先进先出的,因为消息都是按序进行的。尤其是,下列操作条件被观察到: -
The leader sends proposals to all followers using the same order. Moreover, this order follows the order in which requests have been received. Because we use FIFO channels this means that followers also receive proposals in order.
Leader按相同顺序发送提议给所有的Follower。并且,这个顺序和请求接收的顺序是一致的。因为我们使用FIFO管道,这意味着Follower可以按序接收提议。 -
Followers process messages in the order they are received. This means that messages will be ACKed in order and the leader will receive ACKs from followers in order, due to the FIFO channels. It also means that if message m has been written to non-volatile storage, all messages that were proposed before m have been written to non-volatile storage.
Follower按照消息接收的顺序处理消息(将其持久化)。这意味着消息将按序被确认,于是Leader可以按序从Follower获得确认。这也意味着,如果消息m被写入持久化存储,所有的m之前的提议也都写入持久化存储了。 -
The leader will issue a COMMIT to all followers as soon as a quorum of followers have ACKed a message. Since messages are ACKed in order, COMMITs will be sent by the leader as received by the followers in order.
于是当Leader收到得到Quorum量的Follower的确认消息之后,Leader发送提交给所有Follower。因为消息是按序确认的,因此Follower最终接收到的提交也是按序的。 -
COMMITs are processed in order. Followers deliver a proposal message when that proposal is committed.
Follower按序处理提交。当提议被提交之后,称该提议被传递。
Summary
总结
So there you go. Why does it work? Specifically, why does a set of proposals believed by a new leader always contain any proposal that has actually been committed? First, all proposals have a unique zxid, so unlike other protocols, we never have to worry about two different values being proposed for the same zxid; followers (a leader is also a follower) see and record proposals in order; proposals are committed in order; there is only one active leader at a time since followers only follow a single leader at a time; a new leader has seen all committed proposals from the previous epoch since it has seen the highest zxid from a quorum of servers; any uncommitted proposals from a previous epoch seen by a new leader will be committed by that leader before it becomes active.
你总算到这了。为什么它可以工作?或者具体来说,为什么新的Leader看到的提议总是包括所有已经提交的协议?首先,所有的提议都有一个唯一的zxid,所以不像其他协议,我们从不用担心两个提议用相同的zxid修改不同的值;Follower(Leader也是一个Follower)可以看到并把提议按序记录下来;提议按序被提交;同一时间只有一个有效的Leader,因为Follower一次只跟随一个Leader;一个新的Leader可以看到上一epoch的所有提交的提议,是因为它可以看见Quorum数量服务器中最大的zxid;任何上一epoch还没有提交的提议,如果被新的Leader看见的话,那么将由新的Leader在生效前提交。
Comparisons
比较
Isn’t this just Multi-Paxos? No, Multi-Paxos requires some way of assuring that there is only a single coordinator. We do not count on such assurances. Instead we use the leader activation to recover from leadership change or old leaders believing they are still active.
难道这不就是Multi-Paxos吗?不,Multi-Paxos要求仅仅有一个协调者。我们并不依赖于此。相反,我们采用Leader生效机制来从控制权切换或者旧的Leader相信它们仍然有效中的情形中恢复。
Isn’t this just Paxos? Your active messaging phase looks just like phase 2 of Paxos? Actually, to us active messaging looks just like 2 phase commit without the need to handle aborts. Active messaging is different from both in the sense that it has cross proposal ordering requirements. If we do not maintain strict FIFO ordering of all packets, it all falls apart. Also, our leader activation phase is different from both of them. In particular, our use of epochs allows us to skip blocks of uncommitted proposals and to not worry about duplicate proposals for a given zxid.
难道这不就是Paxos吗?你的有效的消息阶段确实看起来想Paxos阶段2?事实上,对我们来说有效消息阶段看起来更像两阶段提交,但不需要处理中止。有效消息阶段和两者都不同,在于它有提议间有序的需求。如果我们不在所有的报文间维持严格的FIFO顺序的话,它们就各自分散了。并且,我们的Leader生效阶段也与两者不同。特别地,我们采用epoch来使我们可以跳过对于未提交提议的阻塞,并且不需要担心给定一定zxid会出现重复的提议。
Consistency Guarantees
一致性保障
The consistency guarantees of ZooKeeper lie between sequential consistency and linearizability. In this section, we explain the exact consistency guarantees that ZooKeeper provides.
ZooKeeper的一致性保障介于顺序一致性和线性一致性之间。在该节中,我们将解释ZooKeeper提供哪种一致性。
Write operations in ZooKeeper are linearizable. In other words, each write will appear to take effect atomically at some point between when the client issues the request and receives the corresponding response. This means that the writes performed by all the clients in ZooKeeper can be totally ordered in such a way that respects the real-time ordering of these writes. However, merely stating that write operations are linearizable is meaningless unless we also talk about read operations.
ZooKeeper中的写操作是线性的。用其他话来说,每次写都仿佛在某个客户端发起请求和接收到响应之间的某个时间点生效。这意味着所有ZooKeeper的客户端的写操作都可以完全被串行化,并且串行顺序反映了实时顺序。但是,不谈读操作,仅仅说写操作是线性的是没有意义的。
Read operations in ZooKeeper are not linearizable since they can return potentially stale data. This is because a read in ZooKeeper is not a quorum operation and a server will respond immediately to a client that is performing a read. ZooKeeper does this because it prioritizes performance over consistency for the read use case. However, reads in ZooKeeper are sequentially consistent, because read operations will appear to take effect in some sequential order that furthermore respects the order of each client’s operations. A common pattern to work around this is to issue a sync before issuing a read. This too does not strictly guarantee up-to-date data because sync is not currently a quorum operation. To illustrate, consider a scenario where two servers simultaneously think they are the leader, something that could occur if the TCP connection timeout is smaller than syncLimit * tickTime. Note that this is unlikely to occur in practice, but should be kept in mind nevertheless when discussing strict theoretical guarantees. Under this scenario, it is possible that the sync is served by the “leader” with stale data, thereby allowing the following read to be stale as well. The stronger guarantee of linearizability is provided if an actual quorum operation (e.g., a write) is performed before a read.
ZooKeeper中的读操作不是线性一致的,因为它可能会返回旧的值。这是因为ZooKeeper的读并不需要quorum数量的结点来参与,服务器会立即响应客户端的读请求。ZooKeeper这么做,是因为相较于一致性,它更看重读的性能。然而,ZooKeeper中的读是顺序一致的,因为读操作会仿佛以某种和每个客户端操作顺序相关的顺序关系生效。一种常见的解决办法是在读之前发起一次同步。同步也并不严格保证实时数据,因为同步也不是一个Quorum操作。进一步解释,考虑一种场景,其中两个服务器同时认为它们自己是Leader,当TCP连接超时小于syncLimit*tickTime时会发生。?不过在实际场景中,这并不容易发生,但即便如此,在讨论严格理论保证时还是需要考虑该情况的。在这种场景下,同步很有可能被假的Leader提供旧的数据,因此导致接下来的读仍然是旧的。要严格保证线性一致性,则需要在读之前提供一个实际的Quorum操作,比如写操作。
Overall, the consistency guarantees of ZooKeeper are formally captured by the notion of ordered sequential consistency or OSC(U) to be exact, which lies between sequential consistency and linearizability.
总的来说,一致性保证了ZooKeeper是严格遵守顺序一致性模型的,介于顺序一致性和线性一致性之间。
Quorums
法定数量
Atomic broadcast and leader election use the notion of quorum to guarantee a consistent view of the system. By default, ZooKeeper uses majority quorums, which means that every voting that happens in one of these protocols requires a majority to vote on. One example is acknowledging a leader proposal: the leader can only commit once it receives an acknowledgement from a quorum of servers.
原子广播和Leader选举都使用了Quorum这个概念来保证系统的一致性视图。通常,ZooKeeper使用大多数Quorum,意味着每次投票要得到大多数的投票。一个例子是确认Leader提议:Leader必须拿到大多数服务器的Quorum才可以提交。
If we extract the properties that we really need from our use of majorities, we have that we only need to guarantee that groups of processes used to validate an operation by voting (e.g., acknowledging a leader proposal) pairwise intersect in at least one server. Using majorities guarantees such a property. However, there are other ways of constructing quorums different from majorities. For example, we can assign weights to the votes of servers, and say that the votes of some servers are more important. To obtain a quorum, we get enough votes so that the sum of weights of all votes is larger than half of the total sum of all weights.
当我们从大多数的使用中抽取出我们真正需要的特性,那就是我们需要大多数是因为我们仅仅需要保证可能的投票组之间至少有一台服务器的交集。采用大多数则保证了这一点。然而,仍然有其他方式可以构造Quorum,而不需要大多数。比如,我们可以给服务器设定权重,比如一些服务器的投票更重要。为了达到Quorum,我们必须争取到足够多的投票,使得所有投票的加权和大于所有加权和的一半。
A different construction that uses weights and is useful in wide-area deployments (co-locations) is a hierarchical one. With this construction, we split the servers into disjoint groups and assign weights to processes. To form a quorum, we have to get a hold of enough servers from a majority of groups G, such that for each group g in G, the sum of votes from g is larger than half of the sum of weights in g. Interestingly, this construction enables smaller quorums. If we have, for example, 9 servers, we split them into 3 groups, and assign a weight of 1 to each server, then we are able to form quorums of size 4. Note that two subsets of processes composed each of a majority of servers from each of a majority of groups necessarily have a non-empty intersection. It is reasonable to expect that a majority of co-locations will have a majority of servers available with high probability.
另一个基于权重的变异方式是结构化的投票,它在有相关性的部署场景下很管用。在这种投票方式下,我们把服务器分成不同的组,然后把权值再赋给服务器。为了拿到选票额度,我们必须要争取到大多数的组的投票(大多数组的集合称作G),因此对于G中的每一个组g,其中获得的投票要超过g的权重和的半数。有趣的是,这种方式下,Quorum值可能会偏小。比如,9台服务器,分3组,每台权重为1,那么我们只要能获得其中两组的选票,而每组的选票大于2即可,那么总的选票数只有4,是小于9的一半的。实际应用中,对于关联的部署来说,预期大部分的组有效是最有可能得到大部分服务器是有效的。
With ZooKeeper, we provide a user with the ability of configuring servers to use majority quorums, weights, or a hierarchy of groups.
ZooKeeper允许用户配置服务器采用哪种投票方式:大多数选票,权重,结构化组。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!