Spark VS Flink,大数据该学什么
Spark VS Flink:功能比较
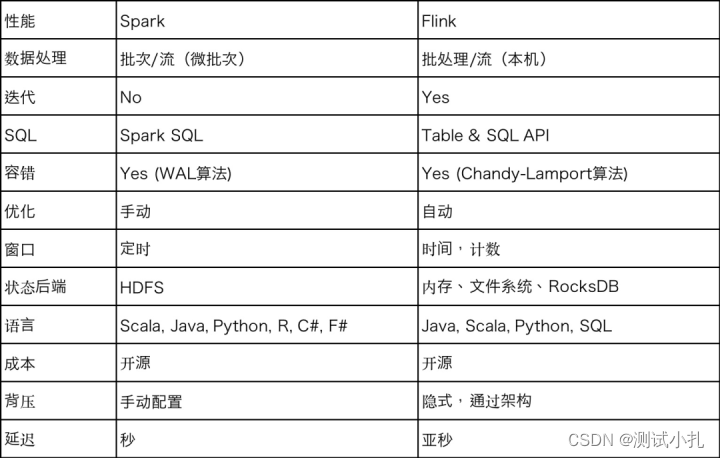
Spark和Flink中的功能集在很多方面都不同,如下表所示:
Flink特点
-
支持高吞吐、低延迟、高性能的流处理
-
有状态计算的Exactly-once语义,对于一条message,receiver确保只收到一次
-
支持带有事件时间(event time)的流处理和窗口处理。事件时间的语义使流计算的结果更加精确,尤其在事件到达无序或者延迟的情况下。
-
支持高度灵活的窗口(window)操作。支持基于time、count、session,以及data-driven的窗口操作,能很好的对现实环境中的创建的数据进行建模。
-
轻量的容错处理( fault tolerance)。它使得系统既能保持高的吞吐率又能保证exactly-once的一致性。通过轻量的state snapshots实现
-
支持机器学习(FlinkML)、图分析(Gelly)、关系数据处理(Table)、复杂事件处理(CEP)
-
支持savepoints 机制(一般手动触发)。即可以将应用的运行状态保存下来;在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间。
-
支持大规模的集群模式,支持yarn、Mesos。可运行在成千上万的节点上
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!