数据的分句向量化
数据的分句向量化
本节将进行数据读入和向量化,首先,使用read_cas读入考生答案文本(介于保密,此处不展示),然后使用bert和分词方法使句子向量化。最后通过互注意力机制实现考生答案的标准答案表达。
通过Bert产生的句子是768维的一个向量,我们使用互注意力机制,实现考生答案的标准答案表达。
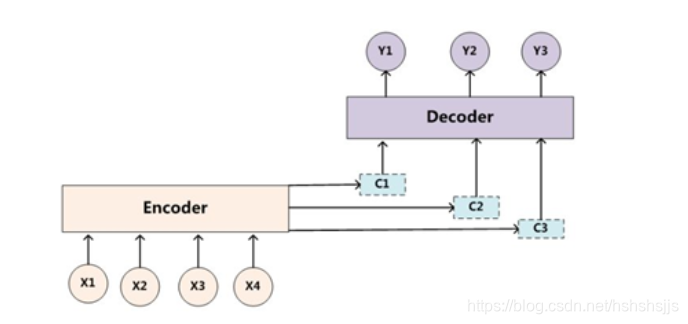
引入注意力使得模型可以同时参考标准答案和考生答案,我们的互注意力就是让每一个考生的答案可以用标准答案的向量进行表示,当然,此处采用的是线性组合的方式。
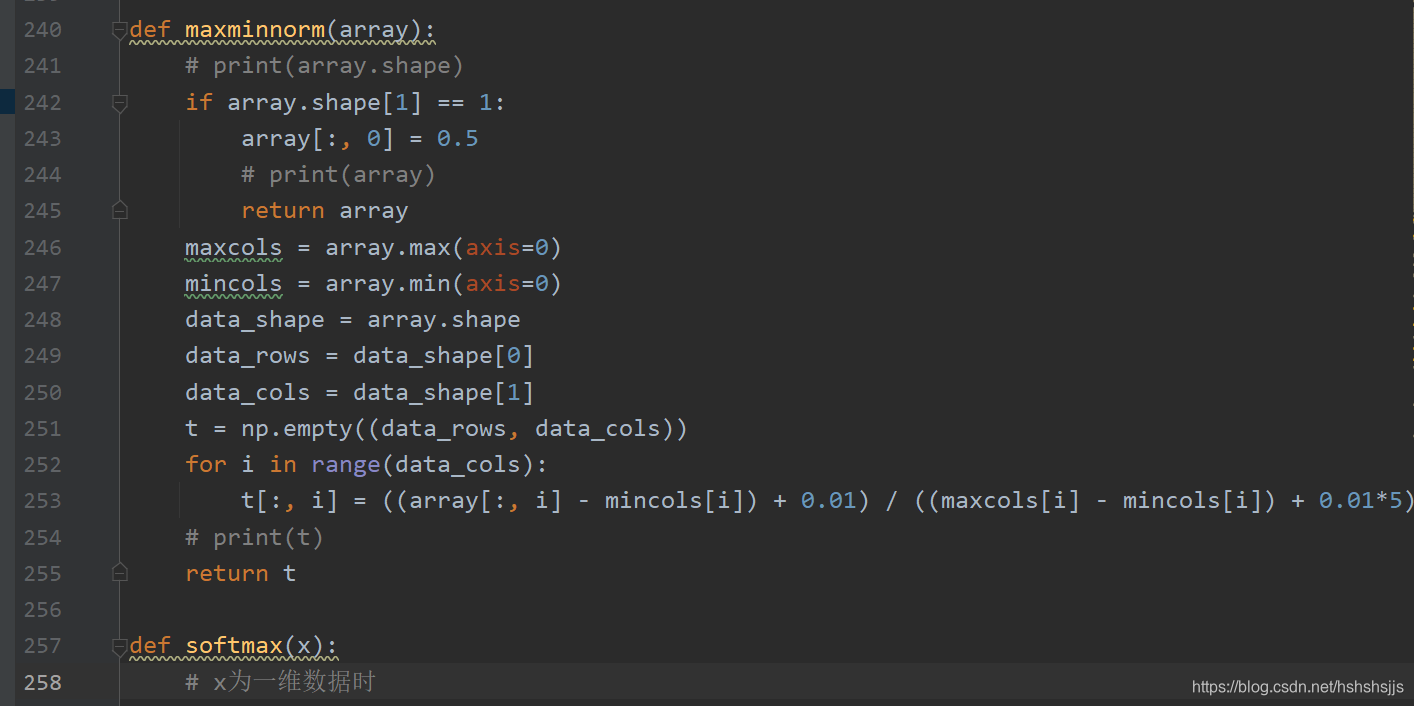
当得到了注意力向量过程中,值得注意的一点是,需要进行行归一化和列归一化。出于对数据更加合理同时利于下游任务的处理,我们采用了极值归一化方法。如下:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!