利用hive中的行转列列转行处理字段中逗号分隔的重复数据
今天同事问了我个问题,想对表中字段为’,'分隔组成的数据进行去重,例如一个数据列中存的是“宋小宝,宋小宝,田野,宋晓峰,宋晓峰”,处理后的展示结果为“宋小宝,田野,宋晓峰”。当时时间比较着急,我就用行转列 再转行处理了,不知道有没有更优化的写法,先记录下来吧!有简单方法的同学可以评论一下让我学习学习,非常感谢!
直接上代码展示
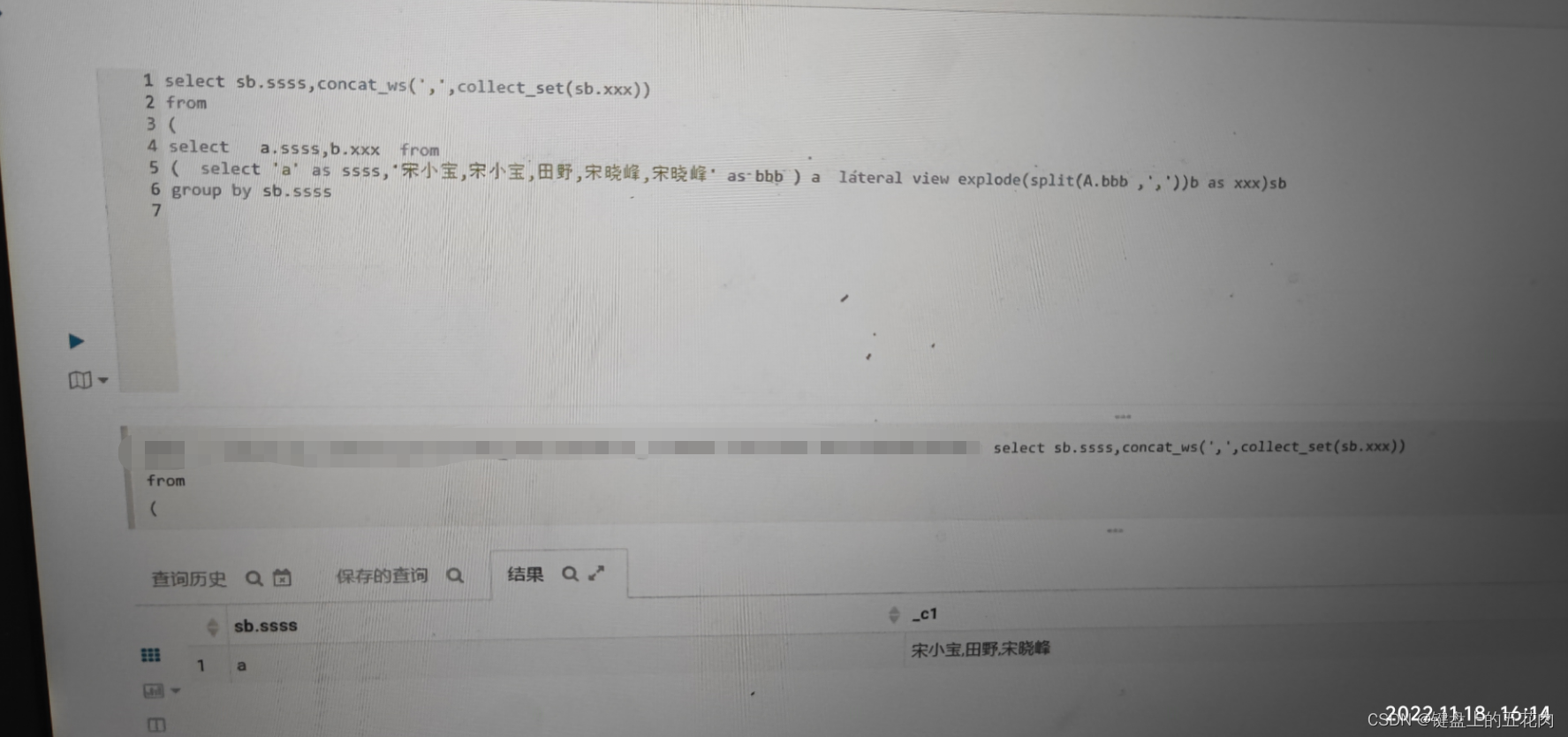
select sb.ssss,concat_ws(',',collect_set(sb.xxx))
from
(
select a.ssss,b.xxx from
( select 'a' as ssss,'宋小宝,宋小宝,田野,宋晓峰,宋晓峰' as bbb ) a lateral view explode(split(A.bbb ,','))b as xxx)sb
group by sb.ssss
我这晚上回家进行记录的,当时只给他拍了个照片发过去了,所以没法截图了,你们可以看下最后的展示结果。
结果
临时通知明天要去加班一天,各位晚安。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!