力扣刷题心得(设计类题目)
设计类题目基本考察的是你对现实事物的抽象能力,一般会遇到一些类的设计、字符串切分、集合的使用(list、map、set、stack、deque)等,结束后我会更新一些关于这些集合的常见使用方法和场景。设计模式其实考察的相对较少的。
一、设计文件系统
你需要设计一个能提供下面两个函数的文件系统:
create(path, value): 创建一个新的路径,并尽可能将值 value 与路径 path 关联,然后返回 True。如果路径已经存在或者路径的父路径不存在,则返回 False。
get(path): 返回与路径关联的值。如果路径不存在,则返回 -1。
“路径” 是由一个或多个符合下述格式的字符串连接起来形成的:在 / 后跟着一个或多个小写英文字母。例如 /leetcode 和 /leetcode/problems 都是有效的路径,但空字符串和 / 不是有效的路径。
输入:
["FileSystem","create","get"]
[[],["/a",1],["/a"]]
输出:
[null,true,1]
解释:
FileSystem fileSystem = new FileSystem();fileSystem.create("/a", 1); // 返回 true
fileSystem.get("/a"); // 返回 1
分析:首先系统中有两个实体:文件路径和文件的值,由于文件路径的唯一,我们可以考虑用hashmap这种数据结构来存储path和value的键值对。
接下来需要考虑一件事情,针对/leetcode/problems这种我们究竟应该创建几个路径?一般我们是创建两个/leetcode和/leetcode/problems,但是这里他有说明
如果父路径不存在我们就不需要直接返回False,所以我们需要做的事,把输入的路径的父路径一次遍历一遍。那么设计就涉及到字符串的分割,java我们可以使用split方法来分割字符串,然后对每一个层次依次进行判断是否存在。
class FileSystem {HashMap filePath;// 文件路径//在构造函数来初始化这个FileSystempublic FileSystem() {filePath= new HashMap<>();filePath.put("",-1);}public boolean createPath(String path, int value) {if(path!="/"){String [] paths = path.split("/");String temp ="/";//判断父路径和路径是否存在,不存在则返回falsefor (int i = 1; i 二、设计内存文件系统
那我们再来个难的
设计一个内存文件系统,模拟以下功能:
ls: 以字符串的格式输入一个路径。如果它是一个文件的路径,那么函数返回一个列表,仅包含这个文件的名字。如果它是一个文件夹的的路径,那么返回该 文件夹内 的所有文件和子文件夹的名字。你的返回结果(包括文件和子文件夹)应该按字典序排列。
mkdir:输入一个当前不存在的 文件夹路径 ,你需要根据路径名创建一个新的文件夹。如果有上层文件夹路径不存在,那么你也应该将它们全部创建。这个函数的返回类型为 void 。
addContentToFile: 输入字符串形式的 文件路径 和 文件内容 。如果文件不存在,你需要创建包含给定文件内容的文件。如果文件已经存在,那么你需要将给定的文件内容 追加 在原本内容的后面。这个函数的返回类型为 void 。
readContentFromFile: 输入 文件路径 ,以字符串形式返回该文件的 内容 。
输入:
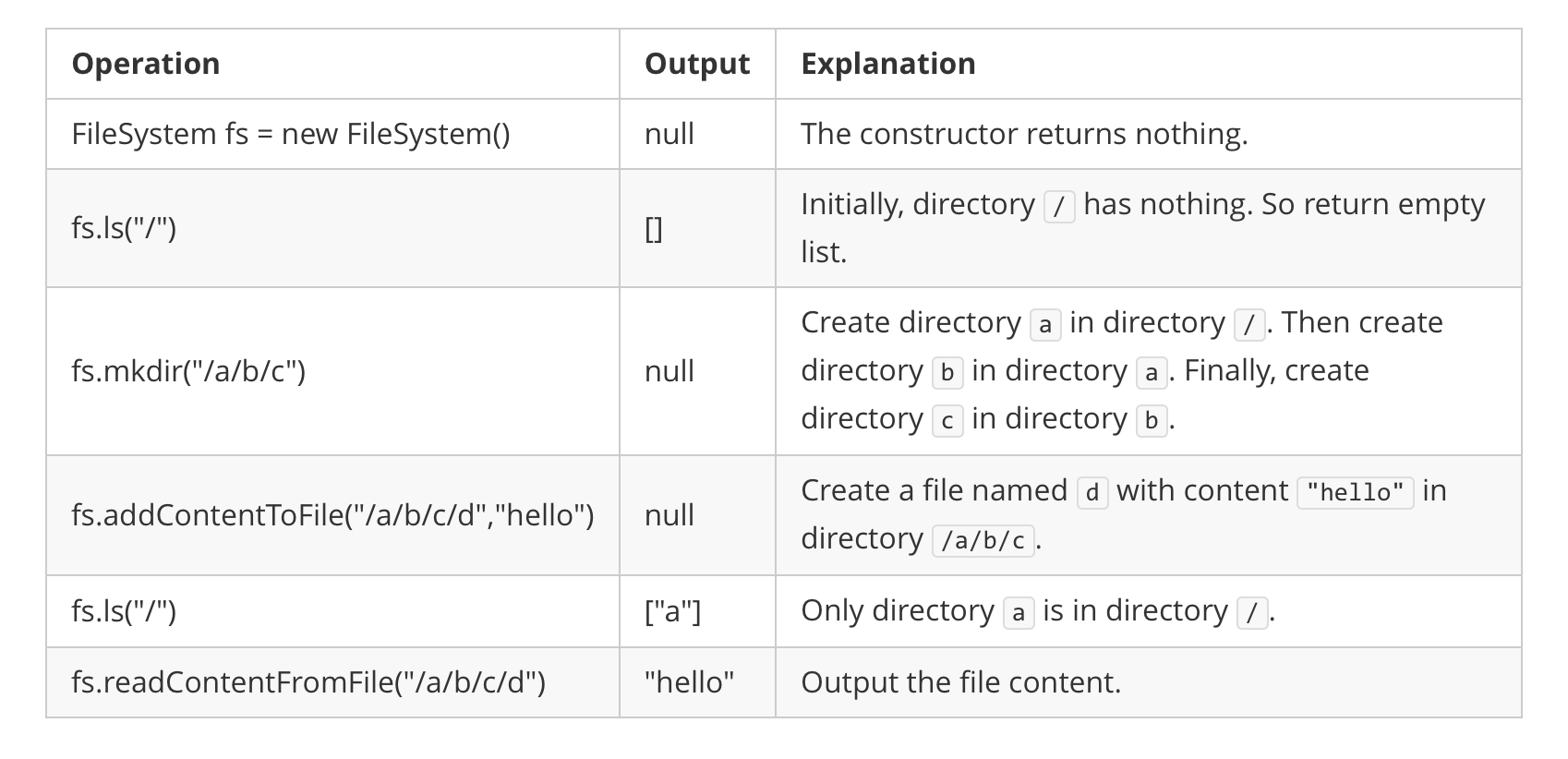
["FileSystem","ls","mkdir","addContentToFile","ls","readContentFromFile"]
[[],["/"],["/a/b/c"],["/a/b/c/d","hello"],["/"],["/a/b/c/d"]]输出:
[null,[],null,null,["a"],"hello"]解释:
注意:
你可以假定所有文件和文件夹的路径都是绝对路径,除非是根目录 / 自身,其他路径都是以 / 开头且 不 以 / 结束。
你可以假定所有操作的参数都是有效的,即用户不会获取不存在文件的内容,或者获取不存在文件夹和文件的列表。
你可以假定所有文件夹名字和文件名字都只包含小写字母,且同一文件夹下不会有相同名字的文件夹或文件。
分析:还是先来分析一下。比上道题我们的文件系统多了些什么呢?多了个ls:返回该文件路径下的所有文件夹或者文件;还有一个构造文件路径的mkdir,这个看起来和我们刚刚的create有点类似,但是好像有点不一样,我们需要根据路径名创建一个新的文件夹。如果有上层文件夹路径不存在,那么你也应该将它们全部创建。刚刚我们只是做了一个判断,二这里需要判断父路径是否存在,并且创建它。根据mkdir,似乎我们还是可以用一个map来存储它,路径为key,文件夹或者文件为value。但是这里注意到和我们刚刚的不同,也就是我们的value,可能是一个文件夹和文件的混合体。想想我们好像没有这样的数据结构来表现它。那么很自然的我们想到我们需要创建抽象出来一个新的数据接口(或者是类)来帮助我们,这个数据结构里面包含了:一个文件夹集合和一个文件集合。
那么这里又存在一个问题?文件夹里面又可能还有文件和文件夹,所以这是个嵌套结构。好,到这里我们的基本数据结构就确定下来了。
class Dirs {HashMap dirs = new HashMap<>();// 路径和文件夹映射HashMap file = new HashMap<>();//路径和文件值的映射} 继续开始写我们的mkdir
public void mkdir(String path) {Dir t = root; //从根目录开始遍历String[] paths = path.split("/");for (int i = 1; i 接下来是addContentToFile,这个比较简单,就是往路径下的文件夹放file
public void addContentToFile(String filePath, String content) {//一样需要从根开始遍历Dir t = root;String[] d = filePath.split("/");for (int i = 1; i < d.length - 1; i++) {t = t.dirs.get(d[i]); //拿到当前的上级目录}t.files.put(d[d.length - 1], t.files.getOrDefault(d[d.length - 1], "") + content);}ls这个就有点意思了,首先我们要分辨出它是文件还是文件夹,如果是文件夹还的再遍历其下的所有文件夹和文件。其次还要按照字典序(是基于字母顺序排列的单词按字母顺序排列的方法,刚开始看这个名词估计一下就懵了)进行输出。考虑到java中集合中的字符串已经有了排序的实现方法Collections.sort
public List ls(String path) {Dir t = root;List files =new ArrayList<>(); //最后返回的列表String [] d = path.split("/");for (int i = 1; i (t.dirs.keySet()));//如果是文件夹files.addAll(new ArrayList<>(t.files.keySet()));//如果是文件Collections.sort(files); //字典序列:return files;} 三、设计浏览器历史记录
你有一个只支持单个标签页的 浏览器 ,最开始你浏览的网页是 homepage ,你可以访问其他的网站 url ,也可以在浏览历史中后退 steps 步或前进 steps 步。
请你实现 BrowserHistory 类:
BrowserHistory(string homepage) ,用 homepage 初始化浏览器类。
void visit(string url) 从当前页跳转访问 url 对应的页面 。执行此操作会把浏览历史前进的记录全部删除。
string back(int steps) 在浏览历史中后退 steps 步。如果你只能在浏览历史中后退至多 x 步且 steps > x ,那么你只后退 x 步。请返回后退 至多 steps 步以后的 url 。
string forward(int steps) 在浏览历史中前进 steps 步。如果你只能在浏览历史中前进至多 x 步且 steps > x ,那么你只前进 x 步。请返回前进 至多 steps步以后的 url 。输入:
["BrowserHistory","visit","visit","visit","back","back","forward","visit","forward","back","back"]
[["leetcode.com"],["google.com"],["facebook.com"],["youtube.com"],[1],[1],[1],["linkedin.com"],[2],[2],[7]]
输出:
[null,null,null,null,"facebook.com","google.com","facebook.com",null,"linkedin.com","google.com","leetcode.com"]解释:
BrowserHistory browserHistory = new BrowserHistory("leetcode.com");
browserHistory.visit("google.com"); // 你原本在浏览 "leetcode.com" 。访问 "google.com"
browserHistory.visit("facebook.com"); // 你原本在浏览 "google.com" 。访问 "facebook.com"
browserHistory.visit("youtube.com"); // 你原本在浏览 "facebook.com" 。访问 "youtube.com"
browserHistory.back(1); // 你原本在浏览 "youtube.com" ,后退到 "facebook.com" 并返回 "facebook.com"
browserHistory.back(1); // 你原本在浏览 "facebook.com" ,后退到 "google.com" 并返回 "google.com"
browserHistory.forward(1); // 你原本在浏览 "google.com" ,前进到 "facebook.com" 并返回 "facebook.com"
browserHistory.visit("linkedin.com"); // 你原本在浏览 "facebook.com" 。 访问 "linkedin.com"
browserHistory.forward(2); // 你原本在浏览 "linkedin.com" ,你无法前进任何步数。
browserHistory.back(2); // 你原本在浏览 "linkedin.com" ,后退两步依次先到 "facebook.com" ,然后到 "google.com" ,并返回 "google.com"
browserHistory.back(7); // 你原本在浏览 "google.com", 你只能后退一步到 "leetcode.com" ,并返回 "leetcode.com"
分析:一看浏览器历史记录,我就想到了一个数据结构”栈“,我们可以用两个栈来实现这个功能吗?一个存我们访问过的页面(后退),一个存我们访问过但是回退了的页面(前进)。
public class BrowserHistory {//访问过到页面Deque visited = new LinkedList<>();//我们访问完之后,又回退的页面;同时它的深度也是我们可以前进多少步Deque backed = new LinkedList<>();public BrowserHistory(String homepage) {visited.push(homepage);}public void visit(String url) {visited.push(url);//我们注意到还有一个需求,就是执行这个操作到浏览器到前进记录要全部清空,也就是我们到back栈记录清空backed.clear();}public String back(int steps) {String url="";if(steps 还有一类的设计类题目会让给你一些常见的数据结构让你实现它,最常见的就是树、队列、链表等的特殊型号
四、设计前缀树
Tire(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie() 初始化前缀树对象。
void insert(String word) 向前缀树中插入字符串 word 。
boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。输入
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
分析:要实现前缀树,首先需要理解前缀树,前缀树还有一种叫法:字典树
Trie又被称为前缀树、字典树,所以当然是一棵树。上面这棵Trie树包含的字符串集合是{in, inn, int, tea, ten, to}。每个节点的编号是我们为了描述方便加上去的。树中的每一条边上都标识有一个字符。这些字符可以是任意一个字符集中的字符。比如对于都是小写字母的字符串,字符集就是’a’-‘z’;对于都是数字的字符串,字符集就是’0’-‘9’;对于二进制字符串,字符集就是0和1。
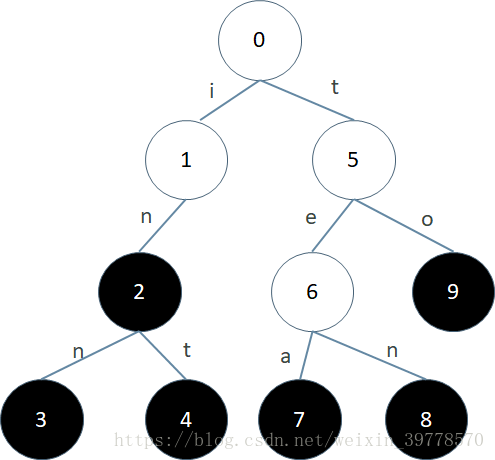
比如上图中3号节点对应的路径0123上的字符串是inn,8号节点对应的路径0568上的字符串是ten。终结点与集合中的字符串是一一对应的。
明白了概念,来看看我们需要什么?对于树中每个节点包含以下字段:
1、指向子节点的指针数组 children。由于不包含重复,我们考虑用一个map来存储,key为字母,value为子节点
2、布尔字段 isEnd,表示该节点是否为字符串的结点
结论有了,首先我们一个字典树(必须有根节点),然后我们有一个子类节点(包含了节点是否结束和子节点)
代码相对来说好理解:
//字典树的java实现public class Trie {public class TrieNode {Map childdren;boolean wordEnd;public TrieNode() {childdren = new HashMap();wordEnd = false;}}private TrieNode root;public Trie() {root = new TrieNode();root.wordEnd = false;}public void insert(String word) {TrieNode node = root;for (int i = 0; i < word.length(); i++) {Character c = new Character(word.charAt(i));if (!node.childdren.containsKey(c)) {node.childdren.put(c, new TrieNode());}node = node.childdren.get(c);}node.wordEnd = true;}public boolean search(String word) {TrieNode node = root;boolean found = true;for (int i = 0; i < word.length(); i++) {Character c = new Character(word.charAt(i));if (!node.childdren.containsKey(c)) {return false;}node = node.childdren.get(c);}return found && node.wordEnd;}public boolean startsWith(String prefix) {TrieNode node = root;boolean found = true;for (int i = 0; i < prefix.length(); i++) {Character c = new Character(prefix.charAt(i));if (!node.childdren.containsKey(c)) {return false;}node = node.childdren.get(c);}return found;}}}
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!