数据增强(一、Random-Erasing)
文章目录
- Random Erasing Data Augmentation(随机擦除数据增强)
- 优势
- 实验数据集
- Random Erasing
- Random Cropping(随机裁剪)
- 实验结果
- 代码
Random Erasing Data Augmentation(随机擦除数据增强)
优势
- 一种轻量级方法,不需要任何额外的参数或内存消耗,它可以在不改变学习策略的情况下与各种CNN模型集成
- 对于现有的数据增强和正则化方法的补充。两者结合使用,Random Erasing进一步提高了识别性能。
- 在图像分类、目标检测和行人重识别方面,提高了深度模型的性能
- 提高鲁棒性。
实验数据集
图像分类
CIFAR-10包含10个类的50000个训练图像和10000个测试图像(3232彩色图像).
CIFAR-100包含100个类的50000个训练图像和10000个测试图像(3232彩色图像)
Fashion-MNIST包含了10个类的60000个训练图像和10000个测试图像(28*28灰度图像)
目标检测
PASCAL VOC 2007包含24640个带注释对象的9963幅图像。
行人重识别
Market-1501包含32666个标记的边界框,其中包含6个不同摄像机捕获的1501个个体。数据集分成两部分:12963幅图像,751个个体用于训练;19732幅图像,750个个体用于测试。
DukeMTMC-reID包含8个高分辨率相机拍摄的1812个个体的36411幅图像。数据集分成两部分:16533个图像,702个个体用于训练;14096个图像,1467个个体用于测试
CUHK03包含1467个个体的14096幅图像。
Random Erasing
随机擦除随机选择图像中的一个矩形区域 I e I_e Ie,并用随机值擦除其像素。假设训练图像大小为 W ∗ H W*H W∗H,图像面积 S = W ∗ H S=W*H S=W∗H。随机初始化“擦除矩形”大小为 S e S_e Se,其中 S e S ∈ ( s l , s h ) \frac{S_e}{S}\in (s_l,s_h) SSe∈(sl,sh)。“擦除矩形”的纵横比 r e ∈ ( r 1 , r 2 ) r_e\in (r_1,r_2) re∈(r1,r2)。矩形 I e I_e Ie的高和宽分别为 H e = S e ∗ r e H_e=\sqrt[]{S_e*r_e} He=Se∗re和 W e = S e r e W_e=\sqrt[]{\frac{S_e}{r_e}} We=reSe。在图像中随机取一个点 P = ( x e , y e ) P=(x_e,y_e) P=(xe,ye),矩形区域以这个点展开 I e = ( x e , y e , x e + W e , y e + H e ) I_e=(x_e,y_e,x_e+W_e,y_e+H_e) Ie=(xe,ye,xe+We,ye+He),否则重复上述过程,知道取到合适的值。在选定的擦除区域内,每个像素都被分别制定为 [ 0 , 255 ] [0,255] [0,255]中一个随机值。

图像分类,根据图像的视觉内容对图像进行分类。一般来说,训练数据不会提供目标的位置,所以无法知道目标的位置。在文中,作者是根据alg1对整个图像进行随机擦除。
行人重识别,目前,人们通常在分类网络中对行人重识别模型进行训练,用于嵌入学习。在此任务中,由于行人被检测到的包围框所限制,人的位置大致相同,占据图像的大部分区域。在这个场景中,作者采用了与图像分类相同的策略,在实践中,行人可以被遮挡在任何位置。我们在整个行人图像上随机选择矩形区域并将其删除。随机擦除用于图像分类和行人重识别的实例如图所示。

目标检测旨在检测图像中某一类语义对象的实例。由于每个物体在训练图像中的位置是已知的,作者采用三种方案实现随机擦除:1)图像感知随机擦除:在整个图像上选择擦除区域,与图像分类和行人重识别相同;2)对象擦除:在每个对象的边界框中选择擦除区域。在后者中,如果图像中有多个对象,随机擦除将分别应用于每个对象。3)图像和对象感知随机擦除(I+ORE):在整个图像和每个对象边界框中选择擦除区域。下图显示了用三种方案进行物体检测的随机擦除的例子

Random Cropping(随机裁剪)
随机裁剪是一种有效的数据增强方法,他减少了背景在CNN训练中的贡献,并且可以基于对象部分的存在来建立学习模型,而不是关注整个对象。与随机裁剪相比,随机擦除保留了对象的整体结构,只遮挡了对象的某些部分。此外,擦除区域的像素被重新分配随机值,这可以被视为给图像添加噪声。下图为随机擦除、随机裁剪及其组合的示例。当结合这两种增强方法时,可以生成更多不同的图像。

实验结果
图像分类
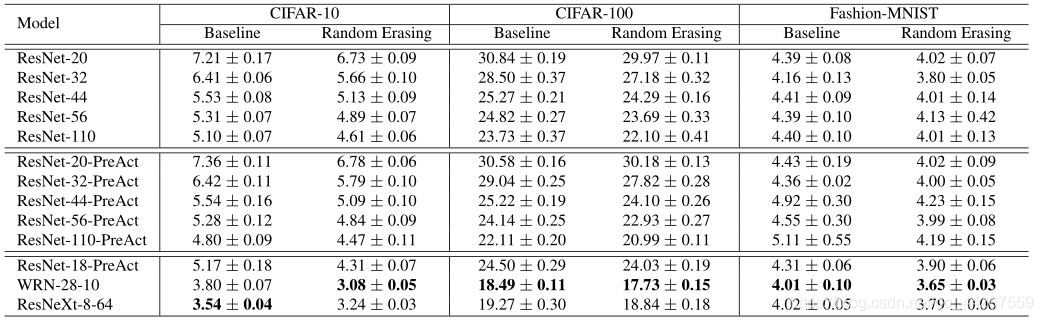
下表,在CIFAR-10、CIFAR-100和Fashion-MNIST上使用不同的体系结构测试错误率(%)
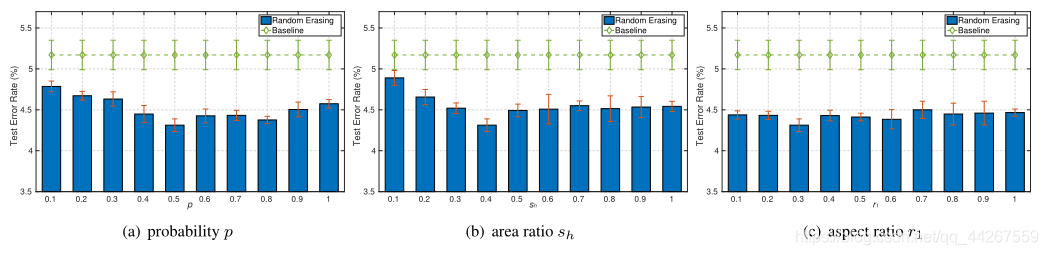
下图,使用ResNet18在CIFAR-10上的不同超参数下测试错误(%)(预作用)。
下图,擦除矩形像素赋值:1)每个像素被分配一个范围在[0,255]内的随机值,表示为RE-R;2)所有像素被赋予平均图像像素值,即[125,122,114],表示为RE-M;3)所有像素分配0,表示为RE-0;4)所有像素被分配255,表示为RE-255。下表显示了使用ResNet18在CIFAR10上擦除不同值的结果(预操作)。1)所有擦除方案都优于基线;2)RE-R实现了与RE-M近似相等的性能;3)RE-R和RE-M都优于RE-0和RE-255。

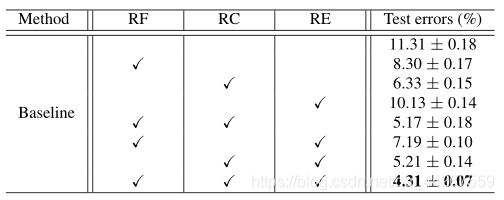
下图,比较了随机翻转,随机裁剪,随机擦除的关系;随机翻转单独应用时,**随机裁剪(6.33%)**优于其他两种方法。重要的是,随机擦除和两种竞争技术是互补的。特别是,将这三种方法结合起来,误差率达到4.31%,比基线提高了7%,没有任何增强。(数据集CIFAR-10,基线网络ResNet-18)
目标检测
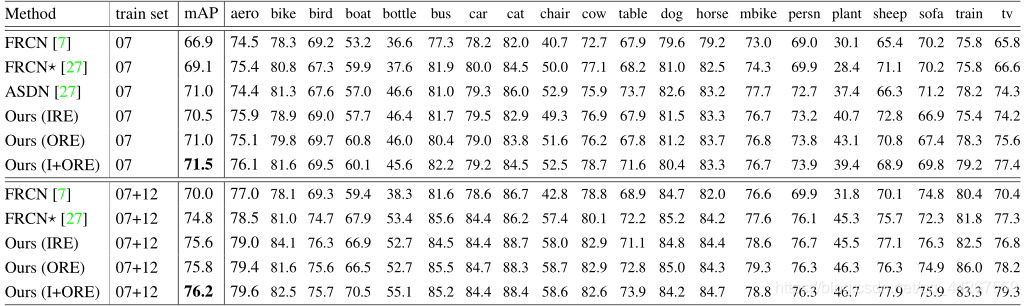
下图为VOC2007测试集上目标检测平均精度(%)
行人重识别
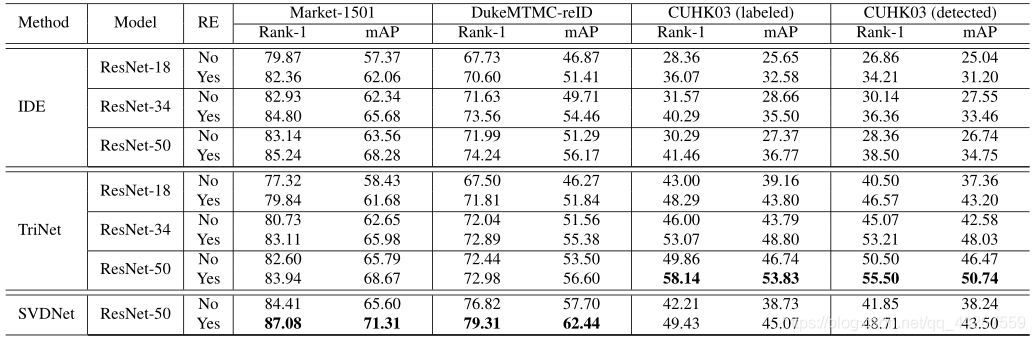
下图为随机擦除在个基线网络中应用,在各个数据集上的识别结果
代码
随机擦除
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!