pandas中DataFrame如何去除重复值
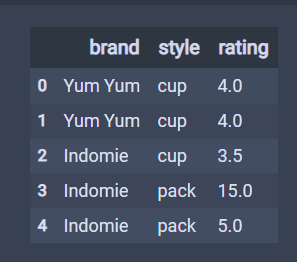
df = pd.DataFrame({'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],'style': ['cup', 'cup', 'cup', 'pack', 'pack'],'rating': [4, 4, 3.5, 15, 5]
})
df
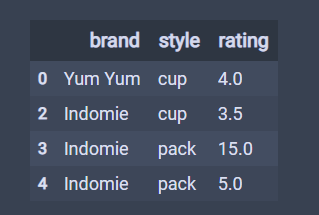
# 删除重复值后返回的是一个副本,也就是原来的数据不会改变。
df.drop_duplicates()
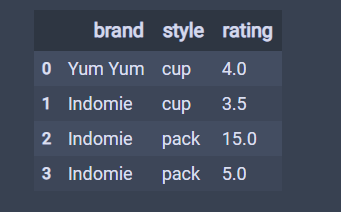
# ignore_index=True,会重新对index排序。
df.drop_duplicates(ignore_index=True)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!