视觉追踪论文:基于孪生、生成对抗和分割
这篇博客是五篇论文的翻译和大概理解:
Fast Online Object Tracking and Segmentation: A Unifying Approach
VITAL: VIsual Tracking via Adversarial Learning
Learning Discriminative Model Prediction for Tracking(DIMP)
SPM-Tracker: Series-Parallel Matching for Real-Time Visual Object Tracking
UpdateNet: Learning the Model Update for Siamese Trackers
论文一:Fast Online Object Tracking and Segmentation: A Unifying Approach(SiamMask)
论文阐述如何进行实时且单阶段的目标追踪和视频中的物体分割。SiamMask用一个二元分割任务增强损失函数,优化目前流行的全卷积Siamese方法的线下训练。
在视频上进行物体追踪是一个很基础的任务,它需要在不同帧之间建立物体的联系以进行物体追踪。视觉物体追踪追踪的目标是特定的单目标物体,基本工作就是:给定第一帧中某物体的位置和边框,它需要在接下来所有帧上进行位置预测和边框预测。
视觉追踪和视频物体分割的共同目标是需要预测第一帧中选定的任意物体的位置,但是视觉追踪通过边框坐标来表现目标物体;视频物体分割(VOS)中物体的呈现是由一个二元分割mask构成,也就是某个像素点是否属于目标物体。相比视觉追踪来说,视频物体分割是像素级上的预测,更加关注的是准确的物体表现,但实际上计算资源大且耗时。视觉追踪总的目的就是怎么用更好的 Bounding Box 框柱物体,以适应物体的形变等导致的跟踪不准确问题,这篇文章将视觉追踪和物体分割结合起来进行追踪,是一个多任务学习方法,只需要初始化一个物体边框,就可以进行预测,相当于一定程度上解决了目标尺度变化的问题。如下图,篮框为初始框,绿色框为SiamMask运行效果,红色为ECO算法运行结果

基于全卷积孪生网络在目标追踪上表现出的优势,文章在三个任务上优化线下训练的全卷积孪生网络,每一个任务对应不同的策略,第一个任务是以滑动窗口的方式,学习目标物体和候选区的相似度,然后输出一个 dense response map,它表明物体的位置而没有提供任何的空间范围信息。为了优化此信息,同时学习两个额外的任务:利用RPN进行的边框回归,以及二元分割。当然,为了保证追踪的实时性,二元标签只在线下训练的时候用到,用于计算分割损失,而在追踪时候没有使用。
全卷积孪生网络的典型代表是SiamFC和SiamRPN:
①对于SiamFC,将一个模板图片z和一个搜索图片x的特征进行比较输出一个dense response map,而response map 上的最大值就对应着目标物体在搜索区域x上的位置。文中将response map上的每个空间元素称作 response of a candidate window(RoW),为了让每一个RoW都能包含目标物体的丰富信息,将特征比较操作simple cross-correlation替换为depth-wise cross correlation,产生一个多通道的 response map。SiamFC 在几百万个视频画面上进行线下训练,用了 Logistic 损失 :
②对于SiamRPN,RPN操作能通过高宽比变动的边框来预测目标物体的位置。在SiamRPN中,每一个RoW都编码着一组k个 anchor box候选区以及对应的物体/背景置信度。因而,SiamRPN输出边框预测以及分类置信度。这两个输出分支通过 Smooth L1 和交叉熵损失来训练:和
。
给每一帧添加二元分割mask,因为利用全卷积Siamese网络的RoW能对必要的信息进行编码,产生像素级的二元mask。可以用一个额外的分支和损失函数扩展现有的Siamese跟踪器。通过一个简单的两层神经网络和学习参数
来预测w×h的二元masks(每个RoW都有一个)。用
表示预测的mask,对应第n个RoW:
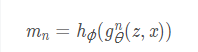
由公式可知:mask的预测是一个函数,此函数由用于x的图像和z中的目标物体组成,因此,给定一个图像z,网络就可对x生成一个不同的分割mask。
关于mask分支的损失函数:在训练过程中,每一个RoW都标注有一个真值二元预测标签: ,以及一个像素级的真值 mask :
,其大小也是w×h。损失函数
是一个覆盖所有RoWs的二元logistic回归损失:
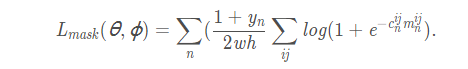
因此,的分类层有w×h个分类器,每一个分类器表示某像素点是否属于候选框内的物体(需要注意的是:
仅仅对正的RoWs进行考虑,即
=1时才有损失进行叠加)
masks由一个平面的物体特征来产生,这个特征对应着一个1×1×256的RoW,此RoW由和
之间进行depth-wise cross-correlation 产生。分割任务中的
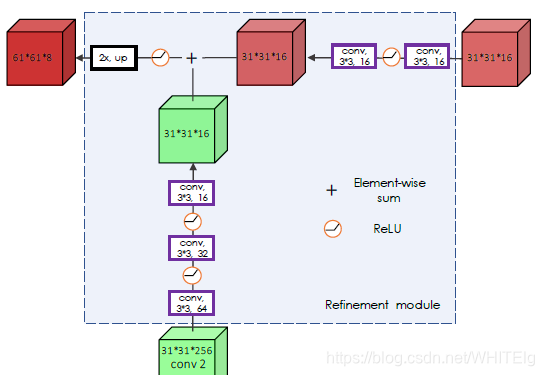
人工神经网络由两个1×1的卷积层组成,一个有256个通道,一个有63*63个通道。这里对于每个像素的分类都利用到了整个RoW内的信息,消除了那些与目标物体类似的对象造成的影响。同时,将低层特征和高层特征融合起来以产生更加准确的masks。这个过程为:多个上采样层和 skip connections构成的 refinement 模块实现。
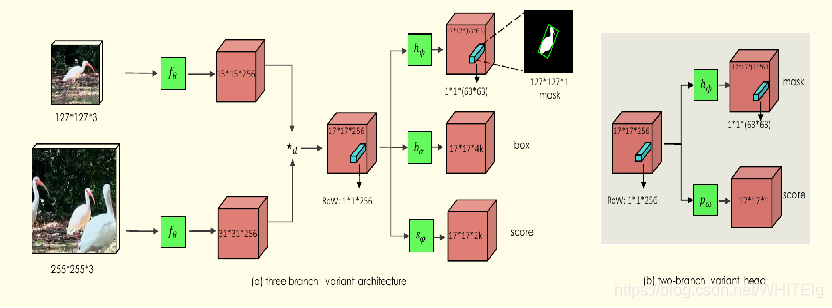
两分支和三分支变体:
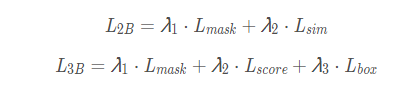
在追踪时,SiamMask 每一帧评估一次,不作任何改变。在两个分支的变体上,把score分支上的最高得分对应的mask输出。然后,逐个像素点对mask进行 sigmoid计算,对mask 分支的输出进行二值化,阈值设为0.5。对于two-branch变体,在第一帧后的每一帧,我们将输出mask用Min-max边框(Min-max边框是一种从二元mask上产生物体边框的方法)进行调节,然后用它来裁剪下一帧的搜索区域。然而,在three-branch变体,利用box分支上最高置信度的输出进行裁剪下一帧搜索区域是最有效的。
分割网络的具体结构为:
RoW经过反卷积并结合高级特征得到目标分割掩码,其中U的结构如下图:
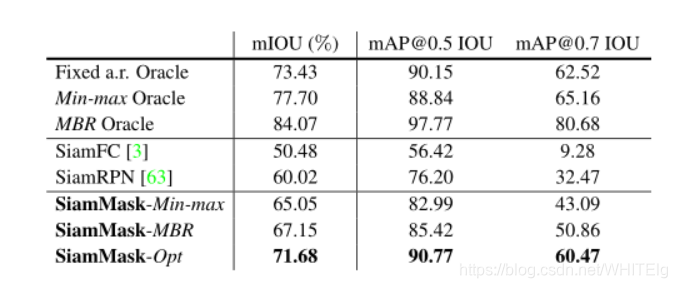
文章提出了三种由mask生成框的方法,不同方法在vot2016上的表现如下图:

论文二:VITAL: VIsual Tracking via Adversarial Learning
这篇文章将对抗学习的思想用在视觉追踪上,运用GAN在特征空间来进行正样本扩增,使得能够在长时间范围内获得大量的外观变化从而获得更加鲁棒的效果,特别是当目标被遮挡或旋转时,漂移的现象得到削弱;针对跟踪问题中负样本远远多于正样本的问题,不同于困难样本挖掘和给样本加权的方法,文章提出了一种高阶的代价敏感损失函数,即使用了focal loss的方法来解决跟踪问题中的样本不平衡问题。
GAN模型的损失函数可以表示为:
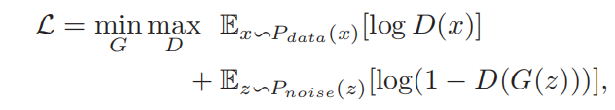
其中:
| 符号 | 含义 |
| x | 真实图片 |
| z | 随机噪声 |
| D(x) | 判别网络D判断真实图片x是否真实的概率 |
| G(z) | 生成网络G通过随机噪声z生成的伪造图片 |
| D(G(z)) | 判别网络D判断伪造图片是否真实的概率 |
对于判别网络D而言,D(x)越接近于1越好,说明判别网络D明辨是非的能力越强,所以目标是使得函数变大;对于生成网络G而言,D(G(z))越接近于1越好,说明生成网络G以假乱真的能力越强,所以目标是使得函数变小。
将GAN用到视觉追踪过程中的vital算法分成以下三个部分:
① 特征提取器:VGG-M网络提取多通道的特征
② 对抗特征生成器:产生能保留目标特征中最鲁棒部分的mask矩阵,生成靠近于M的mask矩阵
③ 判别分类器:与GAN不同,本文的目的在于获得一个对目标变化鲁棒的判别器。
文章提出的模型如下图所示,在特征提取和分类器之间增加了一个生成网络G,被用来产生加权的作用于目标特征的mask矩阵(目的是为了在特征层面丰富目标的多样性),mask矩阵为单通道的、和特征分辨率相同的矩阵,与特征通道做点乘操作:
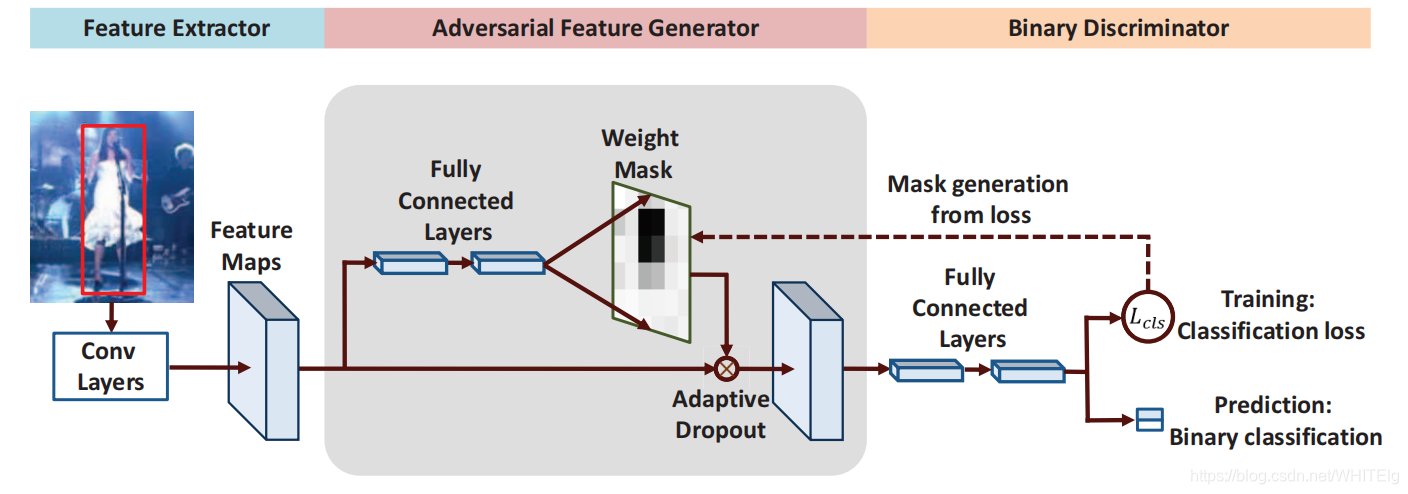
通过对抗学习,该生成式网络可以产生能保留目标特征中最鲁棒部分的mask矩阵。并且,训练得到的生成式网络生成的mask矩阵可以对判别力强的特征进行削弱,防止判别器过拟合于某个样本。
类似于GAN网络的模型损失函数,vital模型的损失函数定义如下:
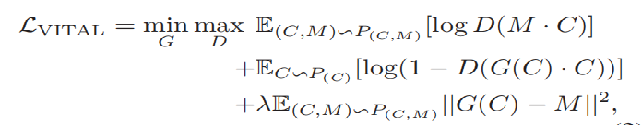
其中:
| 符号 | 含义 |
| M | 在特征C下理论上最优的mask矩阵(让判别器犯错越明显就越优) |
| C | 目标经过VGG-M网络后得到的多通道的特征 |
| G(C) | 生成网络G作用于输入特征C生成的mask矩阵 |
二分类(0 or 1)中的交叉熵损失如下:
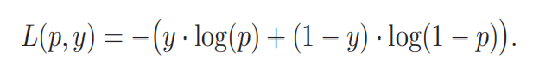
概率p表示经过sigmoid函数输出的样本属于正类的概率,这个损失存在的问题就是简单负样本,即p<<0.5且y=0。若简单负样本数量多,累加的损失值很大,简单负样本占据了交叉熵损失的绝大部分。为解决这个问题在交叉熵损失中根据概率p加了一个调整因子,因为简单正样本的log值是个小于1 的数,因此乘以一个概率p会变得也来越小,也就减小了简单负样本的损失,改进后的损失函数如下:
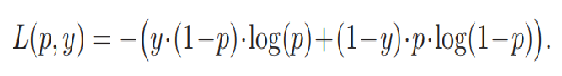
类似地,vital模型最终的损失函数定义如下:
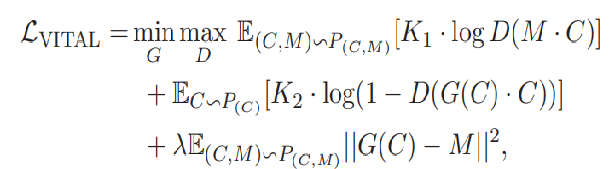
其中:
![]()
![]()
训练过程:先训练D再训练G
训练判别器D: 一次迭代中使输入特征进入G得到一个模板G(C),由于初始状态下G是随机的,因此初始时G根据特征生成随机的mask矩阵,然后作用到特征C上再传给D通过监督学习的方法训练D。训练D的目标是:网络分类时关注于时间上更鲁棒的特征而不是单帧判别力强的特征。
训练生成器G: 训练完D后,给定第一帧输入图片,随机生成多个mask矩阵对输入图片进行干扰,每一个mask对应目标的一种外观变化,希望多个mask可以覆盖目标的各种变化。然后使用D对干扰的图片特征进行判别,选择损失最大的(即判别器不容易判别代表生成器表现很好,也就是干扰性最强的特征),设置该mask为理论上最优的标准mask:M。
测试时,将G网络移除,给定一帧图,生成一些候选区域给CNN提特征再给D网络得到预测的概率值。每一帧都进行增量更新,在估计的位置周围生成一些样本并给定标签,然后用这些样本微调网络。
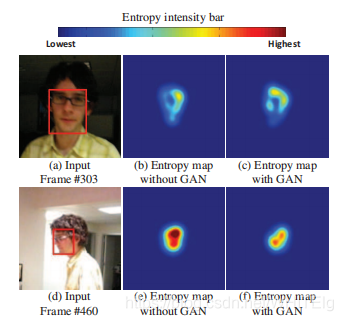
最后,可以通过D得到的分类概率来计算熵,熵越大说明预测的不确定性越高,如下图说明加了GAN能够增强结果的鲁棒性。
论文三:Learning Discriminative Model Prediction for Tracking(DIMP)
孪生的网络框架一般都只是把模板分割出来,忽略了背景信息的利用,而背景的信息对目标的检测定位也是至关重要的;由于跟踪一般都是很多没有见过的类,通过线下学习的相似性度量不是很适用;而且孪生网络的框架没有一个合适的模型更新方式。
文章的模型如下图:
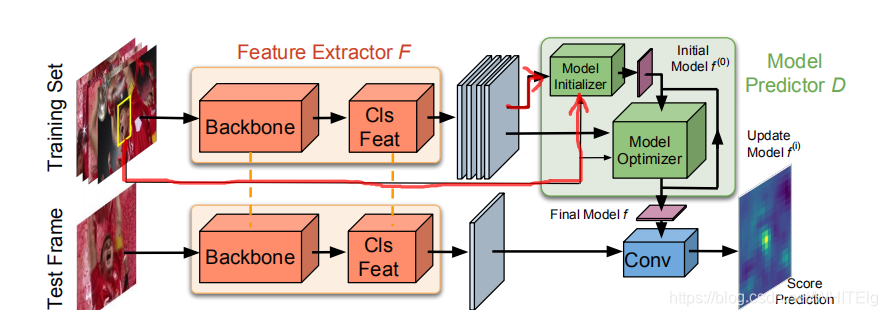
这篇文章的理论基础在于:一个判别力强的损失函数可以指导网络学到鲁棒的特征;一个powerful的优化器可以加快网络收敛。
在特征提取层后面加了一个卷积块来对特征进行分类,训练用的是一个数据集合的方式,输入的是全图以及bbox,得到多个不同的feature map,然后再通过Model Predictor D来预测最终用来分类的模型f。f作为测试图片特征的filter,卷积操作后得到最后的score map。这是目标分类的过程,bbox estimation 和ATOM一样。
文章的目标是预测一个目标模型:,
,其中
是模型优化器D的两个输入。
判别学习损失
单纯以图片对方式训练,传统的岭回归问题会让网络过分注意于优化负样本的影响,而忽略了学到的正样本的特征本身的判别能力。为了解决这个问题,他们用了SVM中使用的hinge-like 损失,就是不仅将前景背景分开,更加使得两类之间有一定的距离,使得分类结果更好。最后将背景类的loss都量化成 >=0 的,与focal loss类似,这里直接把那些简单的负样本去掉,最后的损失函数定义如下:
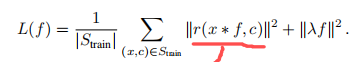
其中:r(s,c)是残差计算函数,s=x*f,c是box的中心坐标。将支撑向量机的理论用到残差计算上来,r函数内部存在hinge-like损失,函数计算公式如下:
![]()
其中:mc代表target的mask,正样本就用正样本的score,负样本的话就用大于零的,即被错分的样本。公式里的参数都是通过网络学到的,并非人工指定。
空间权重因子:当预测在目标中心时值增加,当预测在模糊的转化区域时值减小;
目标区域:当在目标区域时为1,当在背景区域时值为0。通常情况下,目标和背景的转化区域的定义都是根据误差和经验来设置,但在文章中通过数据去学习。
标签置信度得分:
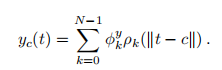
其中: 是三角基函数,定义为:
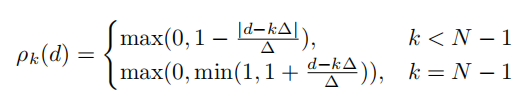
优化器
通常情况下,优化损失的方式是简单的梯度下降,梯度的负方向是下降方向,表示为:
![]()
使用步长这种迭代方式效率不高,需要多次迭代,因此希望设计一个最速梯度下降的方式,自适应的学到学习率。这里的策略就是希望梯度下降沿着最陡的方向。首先,使用loss在
处的二阶泰勒公式展开来近似表示损失函数:
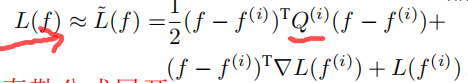
这里,用滤波器 f 作为函数的变量(f表示为向量形式),为正定方阵。通过寻找在梯度方向上使得loss函数最小化的步长
来进行最速下降迭代。熟悉梯度下降就能知道,这通过求下式可得:
![]()
那么步长为:
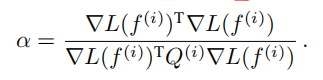
上式被用来计算f更新过程中的下降步长。
公式中的决定了loss的泰勒展开以及步长
,这里用雅可比矩阵替换Hesse矩阵到优化过程中
![]() >>>>>>>>>>>>>>>
>>>>>>>>>>>>>>> ![]()
其中:是函数在
的雅可比矩阵,使用当前模型作为初始化的
注:雅可比矩阵类似于多元函数的倒数,这里用雅可比矩阵代替Hesse矩阵可以简化计算,因为Hesse矩阵是二阶导。假设函数F将一个参数从n维空间转换到m维空间的函数,那么函数在参数处的雅可比矩阵可以表示为一个m行n列的矩阵如图:
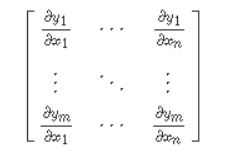
这样,在文章里loss是一个数,即m=1,因此雅可比矩阵的结果是1*n的矩阵,表示为。那么得到的
是一个n*n的方阵。
雅可比矩阵和Hesse矩阵的等价为:
D的伪代码如下;
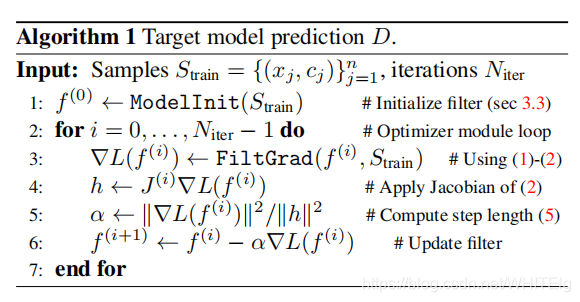
损失:
①分类损失
在成对集合上训练模型,集合
,
分别表示图像帧和目标边界框,在多帧图像中随机抽取一段
长度来构造
,从片段的第一部分和第二部分分别采样N帧作为
。送入特征提取网络获取
,目标就是获取一个模板 f 使得 f 具有对未知帧的判别能力,然后再
上评估模板 f 的好坏。对于分类损失:背景样本使用hinge思想,如下:
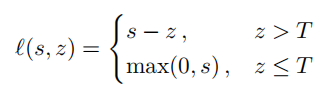
其中:阈值T=0.05表示回归误差,用来定义目标和背景区域。label置信度为z,predict置信度为s。目标区域为,背景区域为
,只对属于背景区域的正置信度s进行惩罚。
总的目标分类损失计算为所有测试样本的loss的均方误差,有一个重要的问题,我们不只是评估最后的模板 f ,而是评估每次迭代过程中产生的的损失,如下:
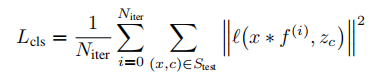
其中:为以目标c为中心的高斯函数,是使用相对于基本目标边框大小的1/4的标准偏差构建的。
②边框损失
和论文ATOM: Accurate tracking by overlap maximization中边框损失类似,边框损失通过训练IOU-Net架构,通过计算中第一帧图像和
中所有图像的预测box的调制向量来将的训练过程扩展到图像集。损失的计算方法是
中预测的IOU与实际的IOU之间的均方误差之和。
③总损失
![]()
其中:
一些细节:
①这个模型初始化的 f 就是将所有的里的bbox取平均,后面还会训练更新。
②残差函数内部的参数都是根据与目标中心距离决定的,不过不是简单的高斯,而是转化到对偶空间求
③对于给定标注的第一帧,使用数据增强策略得到15 samples,进行特征提取,送入到Model Predictor D中,得到f,最后得到预测的分数。通过增加新样本来更新模型,丢弃旧样本确保最新的50个样本。f 每20帧执行2次优化递归,或者当检测到干扰峰时进行单次递归更新。
论文四:SPM-Tracker: Series-Parallel Matching for Real-Time Visual Object Tracking
目标跟踪需要的特征既要具有鲁棒性又要具有判别性, 其中鲁棒性是为了让目标在表观变化情况下还能正确检测到(其实可以理解为语义的信息),而判别性的特征是为了让模型对相似性物体仍能分开。目前的追踪模型都是在一个网络中同时学到这两种表示,两者互相干扰会影响网络的精度。这篇文章比较巧妙地使用粗糙(CM)表示和精细(FM)表示相结合,分别执行不同的功能进行训练得到最终的效果。如下图
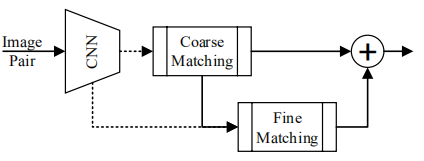
串联体现在FM的输入是CM的输出,并联体现在最后的score和bbox由两部分的结果共同决定。其中:FM stage的输入是CM stage的输出中置信度高的,这个时候可以平衡正负样本的比例;
在FM阶段用了bbox回归机制,可以使得tracker应对尺度和比例变化并且在该阶段提出了一个新的距离度量方式,因为到了这个阶段样本就比较少了,用cross-correlation无法很好去对比相似度,因此FM的判别能力通过一个用距离判别网络(a distance learning subnetwork,论文:Learning to compare: Relation network for few-shot learning)代替互相关计算的方法(CVPR2018中的少样本学习中的某个loss)
网络模型如下图:
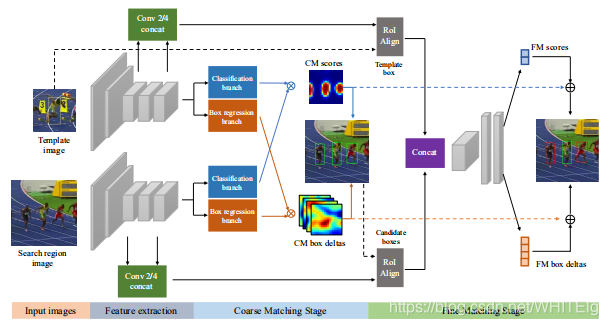
网络同样基于孪生网络,特征提取网络使用的是AlexNet,模板和搜索区域图像经过网络提取特征,然后经过分类和边框回归分支,得到的特征与前面特征做ROIAlign,进行拼接之后作为FM阶段的输入,FM阶段用两个全连接层来分类,计算相应图,最后再把两个阶段的输出用加权的方式求和,得到最终的响应度和bbox。
①CM阶段
CM阶段在搜索区域内部寻找类似于目标样本的物体,这样就不会错过要跟踪的目标,采用SiamRPN的结构,提取特征后,得到相关图然后服务于分类和回归分支。而且通过SiamRPN可以避免进行多尺度测试。提出一种generalized training(GT)的方式进行训练,目的是把要检测物体的同类物体均检测出来,先进行类别上的划分,使同一类的物体都作为正样本,使得同一类物体的类内差距小,这样就可以学习到更加一般的信息,也就是使模型更具有鲁棒性。
②FM阶段
网络的浅层特征与深层特征分别表示的是细节和深层语义特征,因此为了使目标定位更加准确,FM阶段与CM阶段共享特征,用浅层网络的特征提供更加特定的目标信息,从而将真正的目标与背景或类似的周围对象区分开来。在CM阶段获得高分的候选框被送到FM阶段,并通过ROIAlign得到固定大小的特征,使不同对象的差距变大。这个阶段采取困难负样本挖掘来平衡正负样本个数差距,以提高判别能力。这里将特征图拼接然后用过一个1×1卷积层之后是两个全连层,这两个层生成特征用于分类和bbox回归。
文章所用方法(通过CM来定位同类,FM来具体分类)和其他方法对比结果如下图:

前景目标的高c值表明了spm跟踪器的鲁棒性,而非目标的低 f 值则表明了网络的识别能力。注意:CM阶段仅使用特征图中央的6×6×256特征,FM阶段从conv2(384通道)和conv4(256通道)层中提取区域特征并进行拼接。我们使用RoI Align operation将每个size 6×6×640区域特征集合起来,其中6×6为空间尺寸,640为通道数量。
损失部分:
总体损失函数由四个部分组成:CM阶段和FM阶段的分类损失和box回归损失。对于CM阶段,当anchor box与ground-truth框的重叠(IOU)大于0.6(或小于0.3)时,将为anchor box分配一个正(或负)标签。其他IoU anchor box被忽略。对于FM阶段,正(或负)标签被分配给IoU大于(或小于)0.5的候选框。在两个阶段,正向样本都加入了边框回归损失。采用交叉熵损失进行分类,平滑L1损失进行box回归。总损失函数可表示为:
![]()
其中:,
使用表示两个不同阶段的相似度得分,
表示两个不同阶段的边框位置。最后的score和边框位置是两个模块的结果加权和,表示如下:
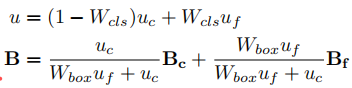
超参数
论文五:UpdateNet: Learning the Model Update for Siamese Trackers
孪生网络方法通过提取当前帧的模板特征来定位下一帧的目标位置的方法来解决目标跟踪问题。针对模板恒定不变引起的无法应对目标形变的问题提出了用学习更新模板的方式来替代固定模板、手工更新模板的方式。作者提出了一种叫UpdateNet的卷积神经网络方式,用之前积累的模板和当前帧的模板来生成一个下一帧可以用的最优模板然后融合到现有的Siamese网络中。
固定模板引起的弊端使得在线更新模板变得必要,然而一般的孪生网络模板更新方法都是采用加权平均的方法,如下:
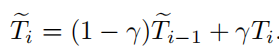
其中:i 表示帧数,是仅用当前帧求得的模板。这种方法集成了新的信息在模板上,但是,这种简单的加权方式以及恒定的模板更新率仍存在弊端。
因此,这篇文章的目的就是通过网络学习一个模板,而不人为指定,函数参数包括初始帧模板,上一帧模板和上次计算出的模板,称为自动更新策略(将当前帧的目标信息加入到匹配模板中),网络模型如下:
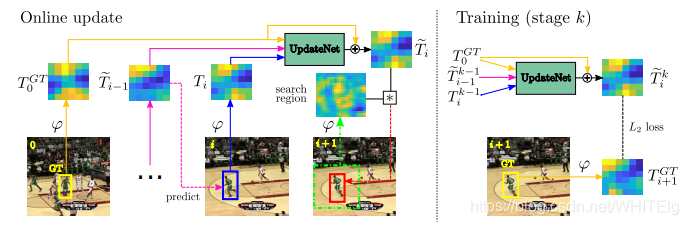
其中UpdateNet内部函数如下:
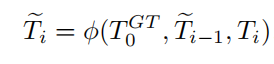
其中:表示的是一个和SiamFC相同的卷积神经网络,始帧模板
是为了保证后续帧的模板更新始终基于的是初始的目标,跟踪过程中模板不会产生大的偏移,
是将用于更新的历史模板均考虑在内。而上一帧的预测模板
是为了加入前一帧的信息以保证作用于当前帧的检测模板具有最接近于当前帧的目标信息。通过训练来得到UpdateNet的参数,将始帧模板
,上一帧模板
和上次计算出的模板
输入到这个网络中得到新的模板
,然后用新的模板进行相似性计算,得到相似图。
UpdateNet 结构中使用到的唯一一个groundtruth就是初始帧的目标,其他的输入都是基于预测的结果。上面提到初始帧模板是为了提供目标的可靠信息,因此这里UpdateNet使用的是残差学习,学习预测出来的新模板和初始帧模板的差别以适应当前帧信息,这样更好地学习网络参数
网络运行流程:
step1:设置初始值,第一帧图像,即i=0时,
step2:将第一帧图像代入得到更新模板特征,作用于第二帧,保存更新模板特征;
step3:结合初始模板特征、更新模板特征、根据更新模板对当前帧预测框特征,得到新的更新模板特征,作用于下一帧;
step4:重复step3,直到视频帧预测结束。
UpdateNet的损失函数:
均方误差的损失函数可以表示为:
![]()
用这种模板更新方式进行的追踪和其他方法的对比如下:

文章尝试的追踪器是SiamFC等基础孪生网络,除了用于计算相似度的模板求取方式不同,其他没有任何差别,因此,这里只描述了文章的创新点。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!