Go~从基础快速入门到代码案例分析
文章目录
- GO
- 一 前言
- 1.1 为什么是Go
- 1.2 Go有缺点吗
- Go执行流程
- 二 基础类型
- 1.1 数据类型
- 1.2 特殊占位符
- 1.3 常量
- 1.3.1 使用和注意事项
- 1.4 指针
- 1.5 值类型和引用类型
- 三 Go分支结构
- 3.1 for循环
- 3.2 range遍历
- 3.3 switch
- 四 函数
- 4.1 函数内存分布
- 4.2 不定参数函数
- 4.3 多返回值函数
- 4.4 可命名返回值函数
- 4.4.1 defer函数修改命名返回值
- 4.5 函数参数为指针
- 4.6 函数类型
- 4.7 函数调用机制
- 4.8 函数作为参数
- 4.9 init函数
- 4.9 匿名函数
- 4. 10 闭包
- 4.10 .1 实践
- 4.11 defer函数
- 4.11.1 最佳实践
- 4.12 内置函数
- 五 时间相关函数
- 六 错误(error)和异常(panic)处理
- 6.1 自定义错误
- 七 集合使用
- 7.1 数组
- 7.1.1 数组注意事项
- 7.2 切片
- 7.2.1 切片注意事项
- 7.2.2 copy函数
- 7.2.3 坑
- 7.2.4 string和slice
- 7.3 Map
- 7.3.1 map的CRUD
- 7.3.2 map切片
- 八 结构体
- 8.1 结构体注意事项
- 8.2 方法
- 8.2.1 方法和函数的区别
- 8.2.2 Go的工厂模式
- 8.3 Go的继承
- 8.3.1 Go继承注意事项
- 九 接口
- 9.1 接口的应用(Sort接口实现)
- 9.2 接口注意事项
- 9.3 实现接口和继承的比较
- 9.4 类型断言
- 9.4.1 断言的实践
- 十 字符串处理
- 十一 文件操作
- 11.1 文件打开和关闭
- 11.1.1 打开文件操作和函数
- 11.2 带缓存区读文件操作
- 11.2.1 io.Reader和io.Writer接口
- 11.2.2 缓冲和无缓冲的文件输入和输出
- 11.2.3 bufio包
- 11.3 读文件示例
- 11.4 创建文件和写文件示例
- 11.4.1 新建文件写入
- 11.4.2 覆盖写入
- 11.4.3 追加写入
- 11.4.4 读出原数据再追加写入
- 11.4.5 判断文件是否存在
- 11.4.6 文件拷贝
- 11.4.7 字符统计
- 11.3 flag包用来解析命令行参数
- 十二 Json
- 12.1 使用Go演示序列化和反序列化
- 12.2 使用tag优化结构体序列化
- 十三 单测
- 13.1 细节说明
- 十四 协程
- 14.1 Go协程和Go主线程
- 14.2 MPG模式(协程的调度模型)
- 14.2.1 goroutine的调度模型
- 14.3 资源竞争问题
- 十五 管道Channel
- 15.1 channel的基本使用
- 15.1.1 channel的基本使用的注意事项
- 15.2 channel的关闭
- 15.3 channel的遍历
- 15.4 解决例题
- 15.4.1 例题2
- 15.5 只读只写channel
- 15.6 select
- 15.6.1 select注意事项
- 15.7 channel总结
- 十六 反射
- 16.1 反射基本使用
- 16.2 实际使用场景例题
- 16.2.1 运行时确定调用接口(桥接模式)
- 16.2.2 对结构体序列化
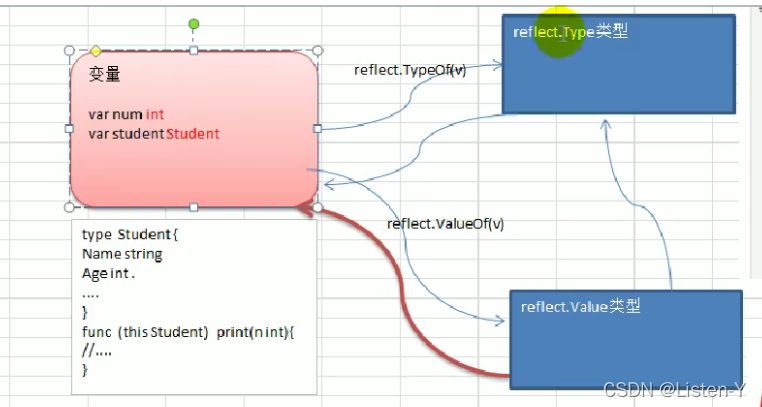
- 16.3 变量 interface{} reflect.value 相互转换
- 16.4 区分kind和type
- 16.5 代码实操
- 16.5.1 反射获得数据并计算修改
- 16.5.2 再次练习数据获取和修改
- 16.6 反射处理结构体
- 16.6.1 反射遍历结构体字段和方法、获取标签值
- 16.6.2 反射修改结构体字段
- 16.6.2 反射创建新结构体
- 十七 网络编程
- 17.1 网络基础知识了解
- 17.2 TCP服务编程
- 17.2.1 服务端代码
- 17.2.2 客户端代码
- 17.3 RPC服务编程
- 17.3.1 共享接口
- 17.3.2 客户端代码
- 17.3.3 服务端代码
GO
一 前言
无论什么知识,在官网肯定能找到:https://studygolang.com/pkgdoc
1.1 为什么是Go
- 为什么目前大厂比如字节和腾讯陆续都在选择GO语言,由收集到的资料我总结出以下几点
- 从表面的基础语法而言,GO的代码设计是务实派设计,比如他在指针和引用的处理上还有他在一些函数和方法的处理上,还有他在对面向对象的理解上,都体现出了务实,没有像java那样冗余的代码和操作,每个功能和语法都是为了让程序员能够快速上手和编写轻松, 所以他的编写难度和阅读难度都是较低的
- Go使用轻量级线程,也就是协程,并使用内存动态链接的方式和MPG的自主调度模式,使并发量能够有显著的提升,比如Java一个线程默认是1MB, 而GO的协程默认大小是2KB
- Go没有预处理器,所以编译速度很快。因此,可以作为脚本语言使用
- Go支持垃圾回收机制,所以开发者无需关心内存分配与释放的问题
- Go默认启用静态链接,二进制文件很容易在同种操作系统间移植。一旦Go代码编译后,无需关心它所依赖的其他库,就可以很方便的在其他地方执行该二进制文件
1.2 Go有缺点吗
- 没有任何语言是完美的,Go也不例外。但是有些语言在某些方面具有特定的优势。就个人而言,我喜欢Java,过去习惯于使用Java。其中的原因是,我发现Java代码阅读起来舒适,Java项目抽象起来易于上手,Java的生态也是Go锁不能比拟的。
- Go不直接支持面向对象编程,这就使得那些已经习惯于面向对象编程的开发者来说非常痛苦。然而,你可以用组合的方式去模拟面向对象的实现方式, 但是这个对于刚从Java转过来的很难接受
然而这些并不影响Go越来越火, 如果一点要对比Java和Go哪个好, 我觉得不如都会, 这样更好~
Go执行流程
我们对 .go 文件使用go build XXX.go的时候就会帮我们编译生成一个XXX.exe的二进制可执行文件 ,也可以直接使用 go run 执行一个go文件,但是慢
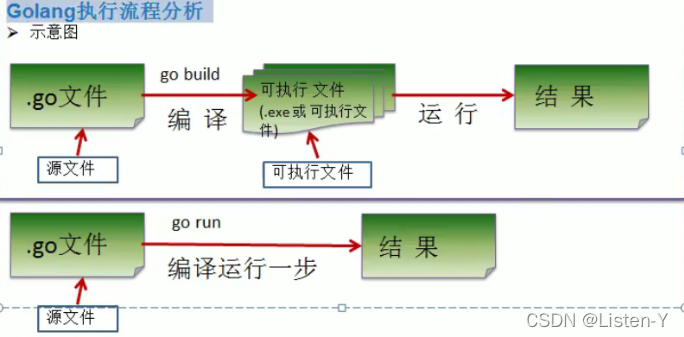
说明:两种执行流程的方式区别
1)如果我们先编译生成了可执行文件/二进制文件,那么我们可以将该可执行文件拷贝到没有go开发环境的机器上,仍然可以运行
2)如果我们是直接go run go源代码,那么如果要在另外一个机器上这么运行,也需要go开发环境,否则无法执行。
3)使用go build编译时,编译器会将程序运行依赖的库文件包含在可执行文件中,所以,可执行文件变大了很多。
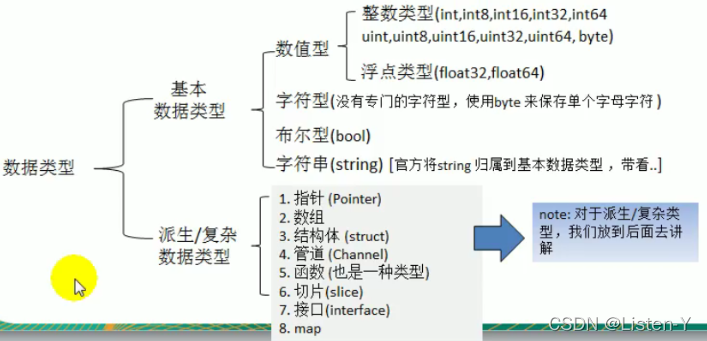
二 基础类型
1.1 数据类型
Go支持的数据类型整体分为俩大类,有接班数据类型和复杂数据类型,每一种数据类型都会分配大小不同的内存空间
- 比如int类型, Go语言同时提供了有符号和无符号的整数类型,其中包括 int8、int16、int32 和 int64 四种大小截然不同的有符号整数类型,分别对应 8、16、32、64 bit(二进制位)大小的有符号整数,与此对应的是 uint8、uint16、uint32 和 uint64 四种无符号整数类型。但是int类型在32位CPU就是4个字节,32bit,如果是64位就是8个字节,64bit,由CPU的位数决定
- 下图展示的是数据类型,占用字节数,默认值和备注
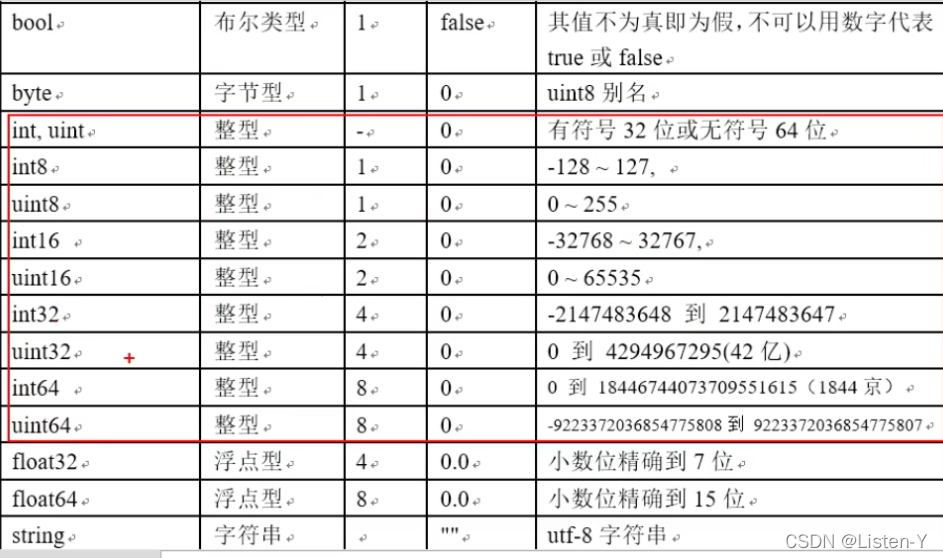
go的字符使用的是utf-8编码,所以本质是一个数字可以直接输出数字,字符可以进行运算,相当于一个整数,是因为他内部对应有Unicode码
go语言的字符串的字节使用utf-8编码标识的Unicode文本,字符串一旦赋值就不能修改,所以go字符串是不可变的
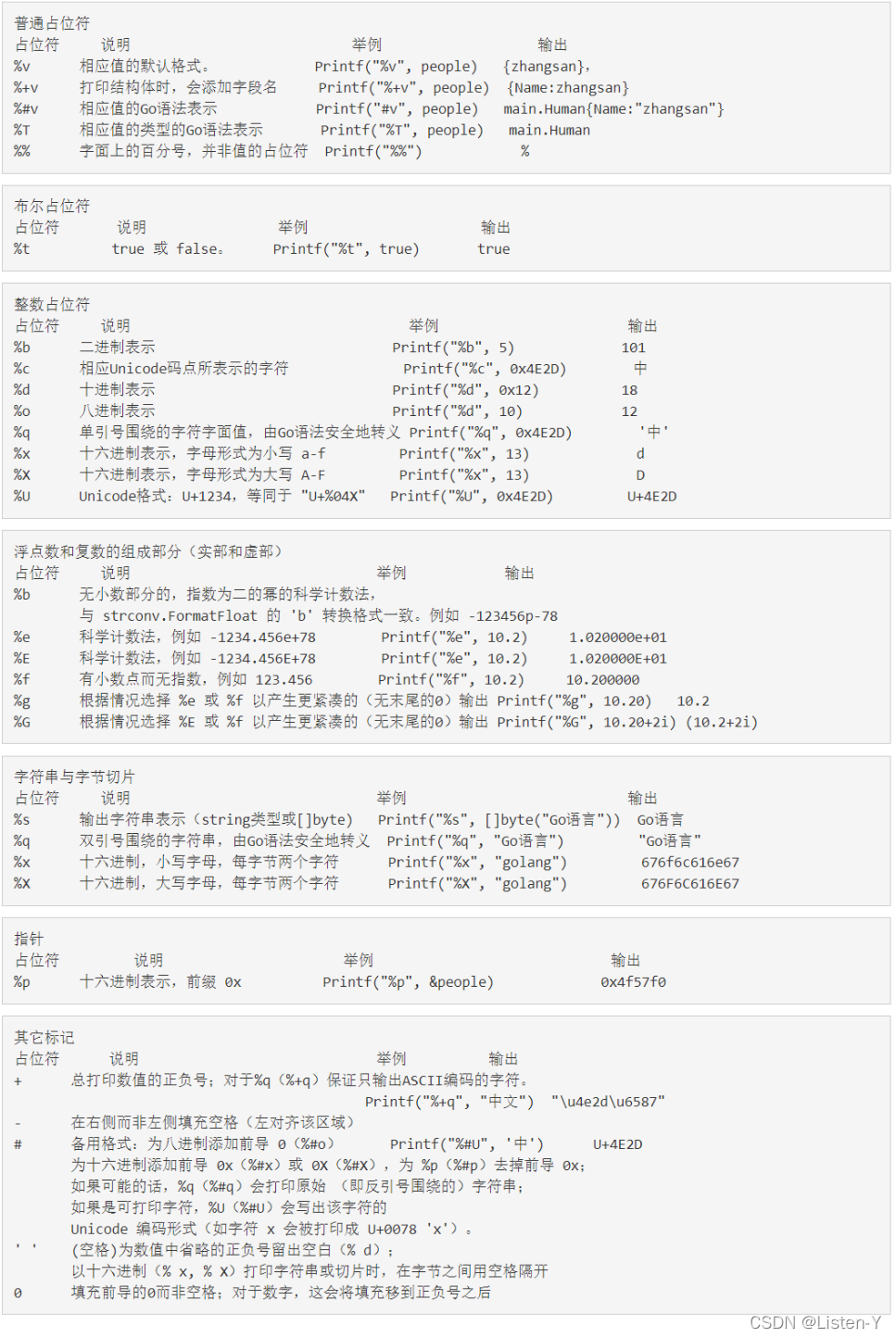
1.2 特殊占位符
- 学习Go语言,无论是在控制台输出, 还是输出日志,都会需要大量的占位符,我也做一些常见的占位符总结
1.3 常量
- 常量介绍
- 常量使用const 修改
- 常量在定义的时候,必须初始化常量不能修改
- 常量只能修饰bool、数值类型(int,float系列)、string类型
- 语法: const identifier [type] = value
1.3.1 使用和注意事项
- 简单写法
const (a = 0b = 1c = 2d = 3
)
- 专业写法
const (a = iotabcd
)
表示给a赋值为0, b在a的基础上+1, c在b的基础上+1, 这种写法就比较专业了
3. Go的常量写法一般使用驼峰形式
4. 仍然通过首字母的大小写来控制常量的访问范围
1.4 指针
这里的指针和C语言的指针是一个意思,如果学过C语言,那很好理解, 指针本身有一个它自己地址,而它自己的地址上所存储的数据也是一个地址,这个地址指向的空间中存的才是真正的数据值
func main() {var i = 10fmt.Println("num的地址", &num)var ptr *intptr = &ifmt.Println("ptr的地址", &ptr)fmt.Println("ptr的数据", ptr)fmt.Println("ptr的数据表示的真实意义", *ptr)
}
i 的地址 0xc0420e080
ptr的地址 0x04206c020
ptr的数据 0xc0420e080
ptr的数据表示的真实意义 10
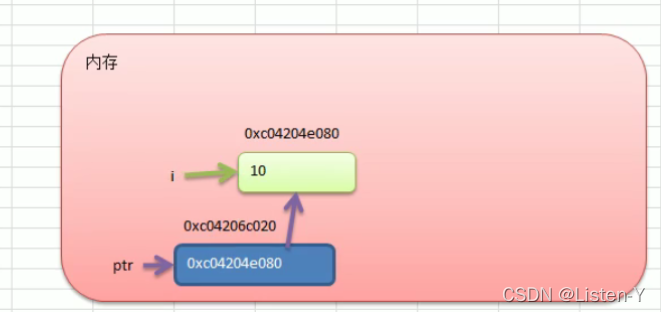
所以说指针本质上存储的是一个地址,而存储的这个地址所存储的才 是真正的数据
func main() {var ptr *float64var num = 10ptr = &num // error 还要注意指针也是有类型的
}
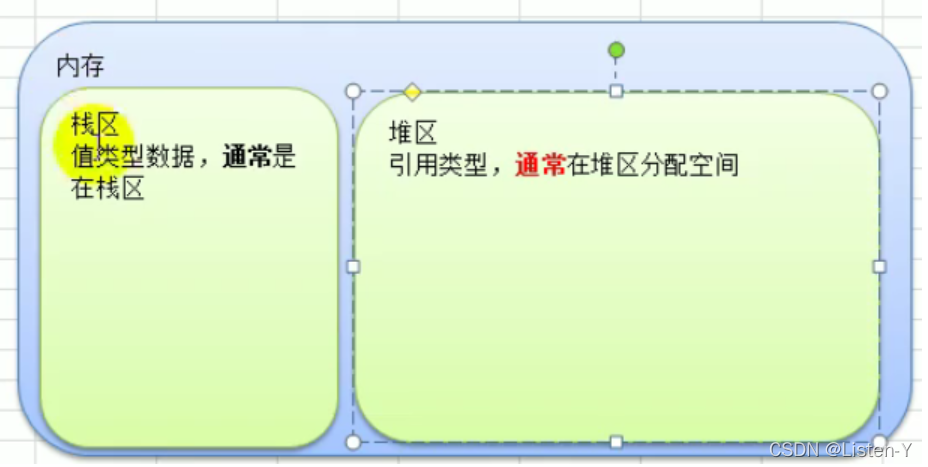
1.5 值类型和引用类型
常见的值类型和引用类型:
1)值类型:基本数据类型int系列, float系列, bool, string 、数组和结构体struct
2)引用类型:指针、slice切片、map、管道chan、interface 等都是引用类型
值类型的变量直接存储值,通常在栈中分配
引用类型, 变量存储的是一个地址,这个地址对应的空间才真正存储数据,内存通常在堆上进行分配空间,当没有任何变量引用这个地址的时候,就会对其进行GC回收
三 Go分支结构
3.1 for循环
很简单,看个例子就行
func main() {// 例一nums := [4]int{1,2,3,4}for i := 0; i < 4; i++ {fmt.Println(nums[i])}// 例二i := 0for {if nums[i] == 3 {break}i++}
}
你可以使用break关键字来退出for循环。break关键字同时也允许你创建一个没有像i <100的这样的终止条件的for循环,因为终止条件可以放在for循环内部的代码块中。在for循环中允许有多个退出循环的地方。
此外,你可以使用continue关键字在for循环中跳过一次循环。continue关键字会停止执行当前的代码块,跳回顶部的for循环,然后继续进行下一次循环。
3.2 range遍历
Go同时提供了range关键字,它能配合for循环以帮助你在遍历Go的数据类型时写出更易于理解的代码。
range关键字的主要优势在于并不需要知道一个切片或者字典的长度就可以一个接一个的对它们的元素进行操作。稍后你会看到range的示例。
对一个数组使用range关键字会返回两个值:一个是数组的索引,一个是该索引上的值。你可以两个值都使用,或者使用其中一个,甚至如果你只是想单纯的计算一下数组的元素个数的话,也可以两个值都不使用。
for index, value := range nums {fmt.Println("index: ", index, "value: ", value)}
index: 0 value: 1
index: 1 value: 2
index: 2 value: 3
index: 3 value: 4
for range方式在使用channel和map的时候也经常使用
parts := map[string]string{}parts = make(map[string]string)parts["a"] = "aa"parts["b"] = "bb"parts["c"] = "cc"for k, v := range parts {fmt.Println("k:", k, "v:", v)}
k: a v: aa
k: b v: bb
k: c v: cc
3.3 switch
和其他语言类似,但也有几点不同,比如:
- switch这个玩意可以在case中使用范围,但是这个时候switch中就不能有表达式
func main() {var score int_, _ = fmt.Scan(&score)switch {case score > 90:fmt.Println("A")case score > 80:fmt.Println("B")case score > 70:fmt.Println("C")default:fmt.Println("D")}
}
- Go语言改进了 switch 的语法设计,case 与 case 之间是独立的代码块,不需要通过 break 语句跳出当前 case 代码块以避免执行到下一行
- 可以通过switch判断一个空接口指向的是这么类型
func main() {var num = 10var name = "name"findType(num)findType(name)
}func findType(a interface{}) {switch a.(type) {case string:fmt.Println("string")case int64:fmt.Println("int64")case int:fmt.Println("int")case byte:fmt.Println("byte")case bool:fmt.Println("bool")default:}
}
- 支持一分支多值和跨越 case 的 fallthrough
func test(name string) {switch name {case "a", "x":fallthroughcase "b":fmt.Println("b")default:}
}
四 函数
和C语言类似, 所有的函数都是全局函数,可以被项目中所有文件使用, 但是区分可导出还是不可导出来控制访问权限,而且在项目中函数名也是唯一的
函数定义
func 函数名(函数参数列表){
代码体/ 程序体/ 函数体
}
变量名数据类型如果有多个参数中间用逗号分隔/先定义后调用
4.1 函数内存分布
func add(a, b int) {sum := a + bfmt.Println(sum)
}func main() {a1 := 10b1 := 20add(a1, b1)
}
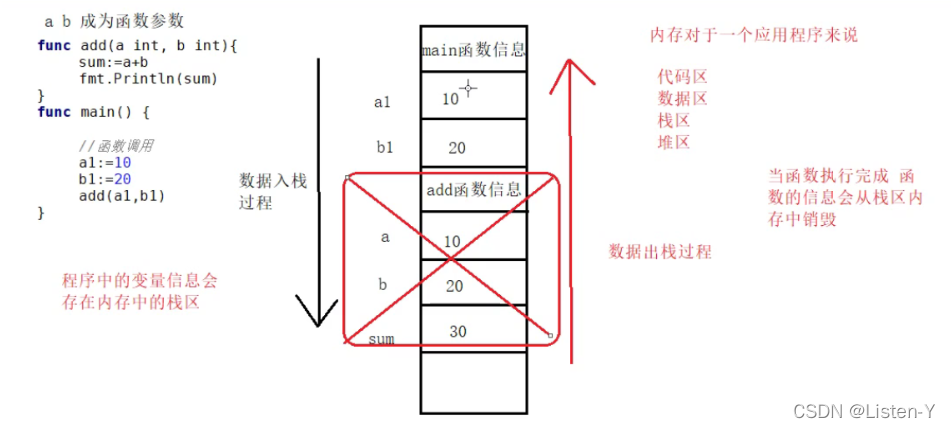
- 内存对于一个应用程序来说,分为代码区、数据区、栈区、堆区
- 每调用一个函数,就会在栈区开辟对应的空间去存储其函数的几部变量
- 比如一开始是main函数,就会有俩个变量存储起来,a1和b1, 如果调用add函数,又会在栈区开辟新的空间去存储a和b和sum的值
- add函数执行完毕,其局部变量的对应栈空间也会进行释放
PS:
所以全局变量和常数都是在数据区进行存储
4.2 不定参数函数
func sum(nums ...int) {sum := 0for i := 0; i < len(nums); i++ {sum += nums[i]}fmt.Println(sum)
}func sum1(arr ...int) {sum := 0for i, data := range arr {fmt.Println("下标:", i)sum += data}fmt.Println(sum)
}func main11() {sum(1,2,3)sum(4,5,6,7,89,0)
}
这种不定参数函数,其参数其实本质是切片, 如果使用可变参数,必须放到最后一个参数上。
func Test(nums ...int) {var s []ints = numss = append(s, 1)
}

4.3 多返回值函数
如您已经从strconv.atoi() 等函数所知,Go函数可以返回多个不同的值,这就避免了您必须创建一个专用的结构,以便能够同时从一个函数接收多个值。您可以声明一个如下返回四个值的函数,两个int值,一个float64值和一个string :
func aFunction() (int, int, float64, string){return 1, 1, 1.0, "a"
}
使用函数的时候, 自然有需要使用多个变量去接受返回值
func main() {m, _, f, s := aFunction()fmt.Println(m, f, s)
}
4.4 可命名返回值函数
和C不同,Go可以命名函数的返回值。另外,当一个函数有个没有任何参数的return语句时,函数自动返回每个命名的返回值的当前值,返回顺序与函数定义中声明的顺序相同。
func namedMinMax(x, y int) (min, max int) {if x > y {min = ymax = x} else {min = xmax = y}return
}
在这段代码中,您可以看到namedMinMax()函数的实现,它使用了命名返回值参数。然而,有一点:namedMinMax()函数没有明确的返回任何变量在 return语句。不过,由于这个函数命令了返回值,min和max被自动返回,以它们被定义的顺序。
当然在return语句也带上返回值, 这样返回值就会在return那里最后被刷新一次数据
func minMax(x, y int) (min, max int) {if x > y {min = ymax = x} else {min = xmax = y}return min, max
}
4.4.1 defer函数修改命名返回值
我们知道Go函数中有个defer函数, 他是在父函数执行结束的时候立即去执行这个defer定义的函数,那么如果在defer中修改了被命名的返回值,会不会生效呢?
- 大家仔细看代码就知道了
// 这种不会修改源数据->
func Test1() (a int , b float32) {defer func(a int, b float32) {a = 99b = 99.9}(a, b)a = 10b = 2.1return a + 1, b + 2
}// 这种会修改源数据
func Test2() (a int , b float32) {defer func() {a = 99b = 99.9}()a = 10b = 2.1return a + 1, b + 2
}func main() {fmt.Println(Test1())fmt.Println(Test2())
}
11 4.1
99 99.9
所以结论就是如果defer函数执行的时候有自己创建局部变量,那自然不会修改源数据, 如果defer函数还是使用的父函数栈区的局部变量,那定会改变源数据
变量的使用范围,如果程序中出现相同的变量名,优先使用自己内部的,如果自己内部没有才会向外面去找,使用就近原则
4.5 函数参数为指针
和C语言一样, 在被调用函数里修改值传递的数据可以改变原数据
func Swap(a, b *int) {*a, *b = *b ,*afmt.Println(*a, *b)
}func main() {a := 10b := 20fmt.Println(a, b)Swap(&a, &b)fmt.Println(a, b)
}
10 20
20 10
20 10
4.6 函数类型
通过type关键字定义的函数类型其实是规定一个变量, 这个变量只能指定该类型格式的一个函数
// type可以定义类型, 也可以给已存在的类型起别名
type fType func(a , b * int)
type fType1 func(a, b int) int
type fType2 func(a, b, c int) (int, string)
type fType3 int
- 函数类型其实本质就是一个指针
- 因为函数名本身就是一个指针数据类型,指针指向的是内存中代码区的一段代码
- 程序执行的时候会将函数先加载到代码区中,每次调用的时候会加载到栈区,并为其创建变量参数,一旦函数执行完就会销毁栈区中的变量和函数,但是代码段中的函数只有整个程序执行完毕的时候才会由操作系统帮我们进行销毁
// type可以定义类型, 也可以给已存在的类型起别名
type fType func(a , b * int)
type fType1 func(a, b int) int
type fType2 func(a, b, c int) (int, string)
type fType3 intfunc test1(a, b *int) {fmt.Println("test1")
}func test2(a, b int) int {fmt.Println("test2")return 0
}func test3(a, b, c int) (int, string) {fmt.Println("test3")return 0 , "test3"
}func test4(a, b, c int) (int, string) {fmt.Println("test4")return 0, "test4"
}func main() {a := 1b := 2c := 3var f fTypef = test1f(&a, &b)f1 := test2_ = f1(a, b)var f2 fType2f2 = test3_, _ = f2(a, b, c)f2 = test4_, _ = f2(a, b, c)
}
test1
test2
test3
test4
所以函数也可以使用 := 进行类型推导
func swap(a *int, b *int) {fmt.Println(a)c := a // 此时c也是指针类型fmt.Printf("%T, %v\n", c, c)*a = *b*b = *c
}func main() {f := swap // 函数类型推导fmt.Printf("%T, %v\n", f, f)var aa = 10var b = 20fmt.Println(aa, b)f(&aa, &b)fmt.Println(aa, b)
}
func(*int, *int), 0x6bdd60
10 20
0xc00000a098
*int, 0xc00000a098
20 20
4.7 函数调用机制
首先看一下Go程序的内存分布
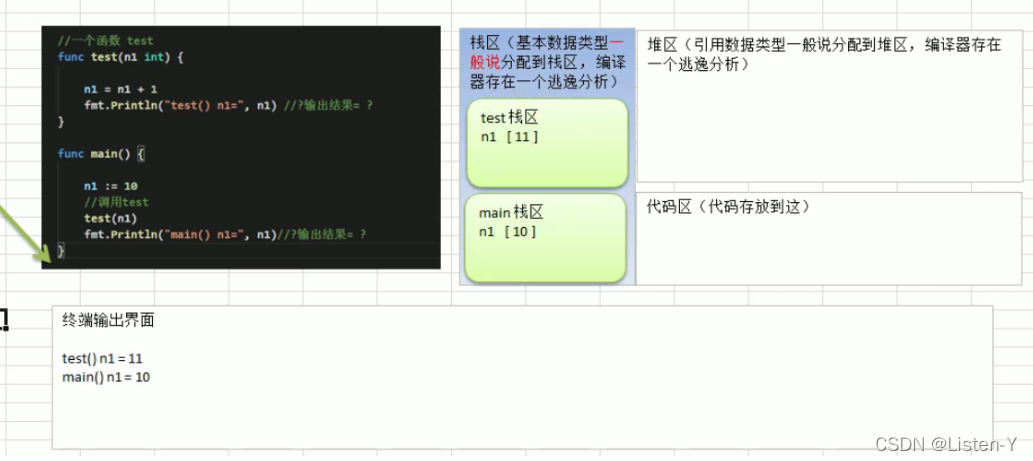
一般基本数据类型会存储在对应函数的栈区, 引用数据类型一般分配到堆区进行存储, 代码区会存储代码段
每调用一个函数,会给该函数分配一个新的空间,编译器会通过自身的处理让这个新的空间和其他栈的空间区分开来
当一个函数调用结束就会回收这栈空间
在Go中基本数据类型和数组默认都是值传递的,即进行值拷贝。在函数内修改,不会影响到原来的值。
如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量。从效果上看类似引用
Go函数不支持重载。
go中函数也是一个数据类型,所以可以将函数作为一个形参进行传递执行
4.8 函数作为参数
Go函数可以接收另一个Go函数作为参数,这个功能为您用Go函数增加了非常广泛的用途。这个功能最为常用的用途就是闭包。
func fun1(a int) int {fmt.Println("a + a")return a +a
}func fun2(a, b int) int {fmt.Println("a * b")return a * b
}func fun3(f1 func(a int) int, f2 func(a, b int) int, a, b int) int {return f1(a) + f2(a, b)
}func main() {f1 := fun1 // 这里是类型推导,并不是函数调用f2 := fun2fmt.Println(fun3(f1, f2, 1, 2))// 第二种用法fmt.Println(fun3(func(a int) int {return a + a}, func(a, b int) int {return a * b}, 1, 2))
}
尽管这个第二种方法可以运行简单的,小巧的函数参数,对于多行代码的函数还是尽量不要这样使用。
4.9 init函数
每个源文件都会有一个init函数,该函数会在main执行前执行,被go框架调用,也就是init会在所有函数之前被调用
所以会在init函数中完成初始化操作
所以如果一个源文件同时包含全局变量定义,执行流程是: 变量定义 -》init -》main函数
如果遇到import导包,导的这个包里的init比main里的优先执行
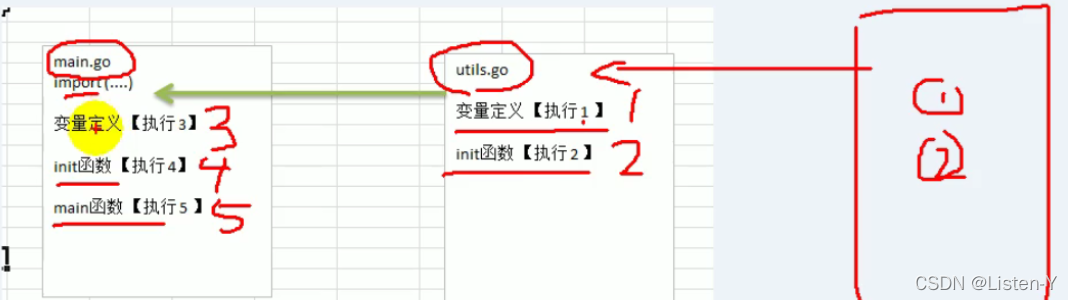
总结: 被导包的全局变量被定义-> 执行被导包的init函数-> main包全局变量被定义-> main包的init函数执行 -> 执行main函数
4.9 匿名函数
Go支持匿名函数,如果我们某个函数只是希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用。
- 使用方式1 定义的时候直接使用
func main() {res := 0func(a, b int) {fmt.Println(a + b)res = a + b}(10, 20)fmt.Println(res)res = func(a, b int) int {return a + b}(10 ,20)fmt.Println(res)}
- 使用方式2 将匿名函数赋给一个变量(函数变量),再通过该变量来调用匿名函数
f1 := func(a, b int) int {return a * b}fmt.Println(f1(1, 2))fmt.Println(f1(2, 3))
- 使用方式3 定义全局匿名函数
var (F1 = func(a, b int) int {return a / b}
)func main() {fmt.Println(F1(4, 2))
}
4. 10 闭包
基本介绍:闭包就是一个函数和与其相关的引用环境组合的一个整体(实体) 可以理解为Java的类
func addUpper() func(int) int {num := 10return func(i int) int {num = num + ireturn num}
}func main() {f := addUpper() // 注意这里先进行调用addUpper函数, 然后将返回值进行函数类型推导给了ffmt.Println(f(10))fmt.Println(f(10))fmt.Println(f(10))
}
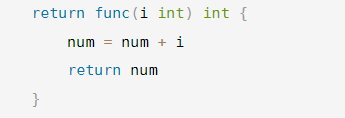
返回的是一个匿名函数,但是这个匿名函数引用到函数外的num ,因此这个匿名函数就和num形成一个整体,构成闭包。
- 大家可以这样理解:闭包是类.函数是操作,num是字段。函数和它使用到num构成闭。
- 当我们反复的调用f函数时,因为num是初始化一次,因此每调用一次就进行累计。
- 我们要搞清楚闭包的关键,就是要分析出返回的函数它使用(引用)到哪些变量,因为函数和它引用到的变量共同构成闭包。
4.10 .1 实践
1)编写一个函数makeSuffix(suffix string)可以接收一个文件后缀名(比如.jpg),并返回一个闭包
2)调用闭包,可以传入一个文件名,如果该文件名没有指定的后缀(比如.jpg) ,则返
回文件名.jpg,如果已经有.jpg后缀,则返回原文件名。
3)要求使用闭包的方式完成
4)strings.HasSuffix
func makeSuffix(suffix string) func(src string) string {return func(src string) string {if !strings.HasSuffix(src, suffix) {return src + suffix}return src}
}func main() {f := makeSuffix(".jpg")fmt.Println(f("a.jpg"))fmt.Println(f("b"))fmt.Println(f("c"))
}
a.jpg
b.jpg
c.jpg
4.11 defer函数
在函数中,程序员经常需要创建资源(比如:数据库连接、文件句柄、锁等),为了在函数执行完毕后,及时的释放资源,Go的设计者提供defer(延时机制)。
func sum(a, b int) int {defer fmt.Println("a=", a)defer fmt.Println("b=", b)ret := a + bfmt.Println("ret=", ret)return ret
}func main() {fmt.Println("sum", sum(10, 20))
}
ret= 30
b= 20
a= 10
sum 30
- 当执行到defer时,暂时不执行,会将defer后面的语句压入到独立的栈(defer栈)
- 当函数执行完毕后,再执行defer栈中的函数。按照先入后出的方式出栈,执行
注意, 将defer修饰的函数入defer栈的时候,会将使用到的数据同时以值拷贝的方式压入栈, 这里使用到的数据只是指在创建defer修饰的函数使用到的数据, 也就是如果是值拷贝类型的数据,在defer中修改后不会影响父函数return的数据
func sum(a, b int) int {defer func(a int) {a++fmt.Println("a=", a)}(a)defer func(b int) {b++fmt.Println("b=", b)}(b)ret := a + ba++b++fmt.Println("ret=", ret)return ret
}func main() {fmt.Println("sum", sum(10, 20))
}
ret= 30
b= 21
a= 11
sum 30
如果是下面这种情况, 就是创建defe修饰的函数时没有使用到外部数据,那么就会造成影响, 但是return数据自然还是不会受影响
func sum(a, b int) int {defer func() {a++fmt.Println("a=", a)}()defer func() {b++fmt.Println("b=", b)}()ret := a + ba++b++fmt.Println("ret=", ret)return ret
}func main() {fmt.Println("sum", sum(10, 20))
}
ret= 30
b= 22
a= 12
sum 30
4.11.1 最佳实践
defer最主要的价值是在,当函数执行完毕后,可以及时的释放函数创建的资源。
file, _ := os.Open("D:/a.txt")defer file.Close()
4.12 内置函数
go为了方便编程,提供了一些函数,可以直接使用,称为go的内置函数
- len:用来求长度,比如string、array、slice、map、channel
- new:用来分配内存,主要用来分配值类型,比如int、float32,struct…返回的是指
针 - make:用来分配内存,主要用来分配引用类型,比如chan、map、slice。这个我
们后面讲解。
这些内置函数在官网的buildin包下
五 时间相关函数
- 主要就是time包,我做简单和常用的介绍, 其他大量API可以去官网学习查看
我做一下简单的代码案例, 都是些常用的
func main() {// 获取当前时间now := time.Now()fmt.Printf("now=%v, now Type=%T\n", now, now)// 时间戳fmt.Println("毫秒时间戳", now.Unix())fmt.Println("纳秒时间戳", now.UnixNano())// 获取年月日时分秒fmt.Println("年=", now.Year())fmt.Println("月=", now.Month())fmt.Println("日=", now.Day())fmt.Println("时=", now.Hour())fmt.Println("分=", now.Minute())fmt.Println("秒=", now.Second())// 格式化日期fmt.Printf("当前年月日%02d-%02d-%02d %02d:%02d:%02d\n",now.Year(), now.Month(), now.Day(),now.Hour(), now.Minute(), now.Second())// 还有一种方式fmt.Println(now.Format("2006/01/02 15:04:05")) // 这个时间格式是固定的fmt.Println(now.Format("2006-01-02"))fmt.Println(now.Format("15:04:05"))
}
now=2021-12-27 11:25:30.3770708 +0800 CST m=+0.003156301, now Type=time.Time
毫秒时间戳 1640575530
1640575530377070800
年= 2021
月= December
日= 27
时= 11
分= 25
秒= 30
当前年月日2021-12-27 11:25:30
2021/12/27 11:25:30
2021-12-27
11:25:30
"2006/01/02 15:04:05”这个字符串的各个数字是固定的,必须是这样写。
"2006/01/02 15:04:05”这个字符串各个数字可以自由的组合,这样可以按程序需求来返回时间和日期
时间的常量const (
Nanosecond Duration =1//纳秒Microsecond
= 1000* Nanosecond //微秒
Millisecond
= 1000* Microsecond//毫秒
second
= 1000* Millisecond//秒
Minute
=60* Second //分钟
Hour
= 60* Minute l/小时
)
常量的作用:在程序中可用于获取指定时间单位的时间,比如想得到1oo毫秒100 * time.Millisecond
有这么多常量就是为了方便使用,比如你要0.1秒,如果使用second * 0.1就会有问题
六 错误(error)和异常(panic)处理
1)在默认情况下,当发生错误后(panic),程序就会退出(崩溃.)
2)如果我们希望,当发生错误后,可以捕获到错误,并进行处理,保证程序可以继续执行。还可以在捕获到错误后,给管理员一个提示(邮件.短信。。。
- Go语言追求简洁优雅,所以,Go语言不支持传统的try…catch…finally这种处理。
2)Go中引入的处理方式为:defer,panic, recqver
3)这几个异常的使用场景可以这么简单描述:Go中可以抛出一个panic的异常,然
后在defer中通过recover捕获这个异常,然后正常处理特别注意recover中只能捕获到上级函数的panic,如果在defer函数中再调用一个函数,此时这个函数去recover不能捕获最开始函数的panic
func main() {defer func() {err := recover()if err != nil {fmt.Println("捕获异常")fmt.Println(err)}}()num1 := 10num2 := 0fmt.Println(num1 / num2)
}
捕获异常
runtime error: integer divide by zero
进行错误处理后,程序不会轻易挂掉,如果加入预警代码,就可以让程序更加的健壮。
但是一定要注意是在defer修饰的函数里才可以, 如果在defer修饰的函数里再去执行函数中去执行recover是不会捕获到异常的
func main() {defer func() {func() {err := recover()if err != nil {fmt.Println("捕获异常")fmt.Println(err)}}()}()num1 := 10num2 := 0fmt.Println(num1 / num2)
}
上述代码就会直接让程序奔溃, 不会捕获到异常
6.1 自定义错误
Go程序中,也支持自定义错误,使用errors.New和 panic 内置函数。
- errors.New(“错误说明”),会返回一个error类型的值,表示一个错误
- panic内置函数,接收一个interface{f类型的值(也就是任何值了)作为参数。可以接收 error
或者使用fmt.errorf()也可以创建一个错误, 其实区别就是fmt.errorf可以formate内部string
func test1() error {return fmt.Errorf("error")
}
func test2() {err := test1()if err != nil {panic(err)}
}
七 集合使用
这个内容较多, 所有我有单独的博客深入讲或者部分内容,这里我做简单的介绍GO集合大全
7.1 数组
一定要注意数组的[3]int和[4]int不是同一个数据类型
func main() {var arr1 = [3]int{1, 2, 3}arr2 := [4]int{1,2,3,4}arr3 := [...]int{1,2,3,4,5}arr4 := [...]string{1: "b", 2: "c", 0: "a"} // 通过下标定位indexfmt.Println(arr1, arr2, arr3, arr4)
}
[1 2 3] [1 2 3 4] [1 2 3 4 5] [a b c]
- 遍历方式也很简单
// 方式一for i := 0; i < len(arr1); i++ {fmt.Println(arr1[i])}// 方式二for index, value := range arr1 {fmt.Println(index, value)}
7.1.1 数组注意事项
数组使用注意事项和细节
1)数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的,不能动态变化。
2)var arr []int这时arr就是一个slice切片,切片后面专门讲解,不急哈.
3)数组中的元素可以是任何数据类型,包括值类型和引用类型,但是不能混用。4)数组创建后,如果没有赋值,有默认值数值类型数组:
默认值为0
字符串数组:默认值为""
bool数组:默认值为false
5)使用数组的步骤1.声明数组并开辟空间2给数组各个元素赋值3使用数组6)
数组的下标是从o开始的。
7)数组下标必须在指定范围内使用,否则报panic:数组越界,比如var arr [5]int则有效下标为0-4
8)Go的数组属值类型,在默认情况下是值传递,因此会进行值拷贝。数组间不会相互影响
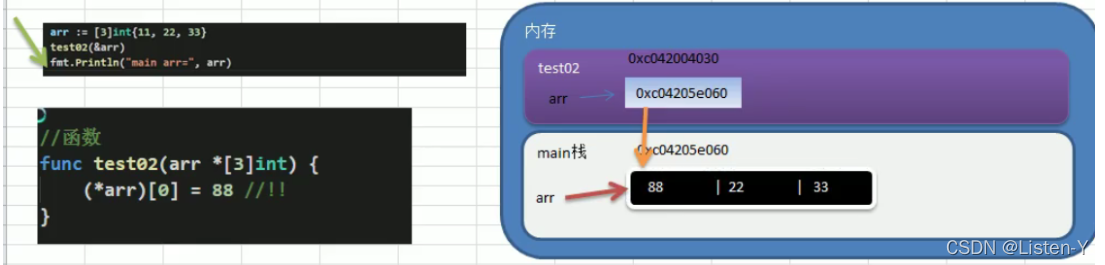
9)如想在其它函数中,去修改原来的数组,可以使用引用传递(指针方式)
记着go中数组也是值拷贝(一不留心就是大坑)
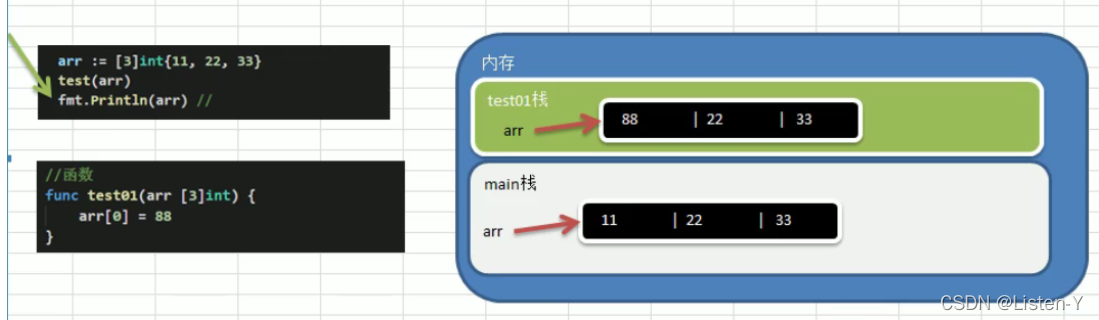
如果想用java那种把数组传递变为引用传递,那就得传递数组的指针
7.2 切片
- 切片其实就是数组,但是其多了俩个字段,一个是数量的个数,也就是长度,一个使用容量
- 切片是一个引用,因此切片是引用类型,遵守引用传递,但是要注意其内部的len和cap字段还是值传递
- 切片的长度是动态变化的
- 切片的定义就是var num []int 就是
var nums []intnums = make([]int, 0, 1) // 类型 初始长度 容量, 注意初始长度强烈建议为0
切片的内存布局,切片记着一直是引用传递的,只是在内存不够的时候才会进行开辟新空间然后把旧数据放到新的空间上
比如下面代码
func main() {arr := [5]int{0,1,2,3,4}slice1 := arr[0:4] // 这底层就是分割出来一个切片, 采用左闭右的方式进行隔离出数据fmt.Println("slice", slice1)fmt.Println("len", len(slice1))fmt.Println("cap", cap(slice1))slice1[0] = 99fmt.Println("arr", arr) // 输出 arr [99 1 2 3 4] 这里看到slice1和arr使用的同一个内存空间slice1 = append(slice1, 4)slice1 = append(slice1, 5)slice1 = append(slice1, 6)slice1 = append(slice1, 7)slice1[1] =999fmt.Println("arr", arr)// 还是输出 arr [99 1 2 3 4] 这里看到slice1和arr使用的同一个内存空间fmt.Println("slice", slice1) // 输出 slice [99 999 2 3 4 5 6 7]
}
总结:
从上面可以看到
1.slice的确是一个引用类型
2.slice从底层来说,其实就是一个数据结构(struct结构体)
type slice struct {
ptr *[2]int
len int
cap int
}
- 对比俩种初始化切片的方式的区别
func main() {// 第一种方式arr := [5]int{0, 1, 2, 3, 4}slice1 := arr[0:4] // 这底层就是分割出来一个切片, 采用左闭右的方式进行隔离出数据// 第二种方式slice2 := make([]int, 0, 4)
}
方式1是直接引用数组,这个数组是事先存在的,程序员是可见的。既然可见也是一种风险,如果切片不进行扩容,那修改原数组中的数据会对切片产生影响,这是一个坑
方式2是通过make来创建切片,make也会创建一个数组,是由切片在底层进行维护,程序员是看不见的, 但是创建的时候。make创建切片的示意图:
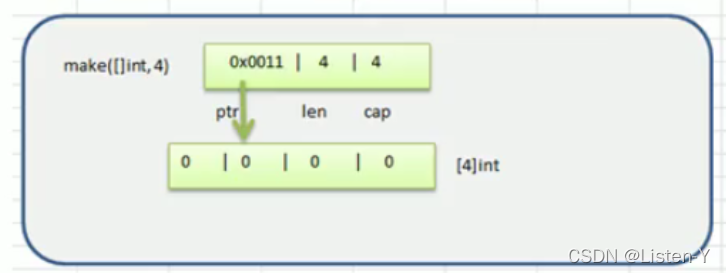
- 至于遍历方式和数组是一样的, 但是尽量推荐使用for range进行遍历, 避免踩坑
7.2.1 切片注意事项
-
切片初始化时var slice = arr[startIndex:endIndex] 说明:从arr数组下标为startlndex,取到下标为endIndex的元素(不含arr[endIndex])。
-
切片初始化时,仍然不能越界。范围在[O-len(arr)]之间,但是可以动态增长
var slice = arr[0:end]可以简写
var slice = arr[:end]
var slice = arr[start:len(arr)]可以简写:
var slice = arr[start:]
var slice = arr[0:len(arr)]
可以简写:var slice = arr[:] -
cap是一个内置函数,用于统计切片的容量,即最大可以存放多少个元素。
-
切片定义完后,还不能使用,因为本身是一个空的,需要让其引用到一个数组,或者make一个空间供切片来使用
-
切片可以继续切片, 切片无论你切几次,只要容量len
-
用append内置函数,可以对切片进行动态追加
切片append操作的底层原理分析:
1)切片append操作的本质就是对数组扩容
2)go底层会创建一下新的数组newArr(安装扩容后大小)3)将slice原来包含的元素拷贝到新的数组newArr
- slice重新引用到newArr
5)注意newArr是在底层来维护的,程序员不可见., 使用append会有可能造成len>=cap会开辟新空间,所以需要值的重新赋予
7.2.2 copy函数
说明: copy(para1, para2): para1和 para2都是切片类型。将2拷贝给1
使用copy的时候要求俩个参数都是切片,而且拷贝之后俩个切片之间的数据是独立的
注意拷贝时如果容量不够,go默认只会拷贝自己能放下的那点数据,也就是拷贝的数据是俩个切片最小len值
7.2.3 坑
看下面代码输出是什么
a := []int{1,2,3,4,5}s := make([]int, 1, 4)fmt.Println(s)copy(s, a)fmt.Println(s)
[0]
[1]
输出0是因为设置了输出容量,给了默认值所以第一个位置为0, 输出1的原因是因为进行了拷贝, 然后以l俩个切片len的最小值作为拷贝数据量
- 再看下面代码输出什么
func main() {arr := [5]int{1,2,3,4,5}var slice []intslice = arr[:]var slice2 = sliceslice2[0] = 10fmt.Println("arr", arr)fmt.Println("slice", slice)fmt.Println("slice2", slice2)
}
arr [10 2 3 4 5]
slice [10 2 3 4 5]
slice2 [10 2 3 4 5]
原因就是因为从数组中拷贝切片,只要切片没有发送扩容, 那么就和原数组使用的同一个内存空间
- 咱们再看一个例题
func main() {slice1 := make([]int, 1, 2)slice2 := make([]int, 1, 2)slice3 := make([]int, 1, 2)test5(slice1)test6(slice2)test7(slice3)fmt.Println("slice1", slice1)fmt.Println("slice2", slice2)fmt.Println("slice3", slice3)
}func test5(slice []int) {slice[0] = 10
}func test6(slice []int) {slice = append(slice, 5)slice[0] = 10
}func test7(slice []int) {slice = append(slice, 5)slice = append(slice, 5)slice = append(slice, 5)slice = append(slice, 5)slice = append(slice, 5)slice = append(slice, 5)slice[0] = 10
}
slice1 [10]
slice2 [10]
slice3 [0]
总的来说原因就是切片虽然说是引用传递,但只是底层数组的引用传递,其len和cap都是值传递, 而且引用传递本质还是引用的一个值拷贝, 所以一旦发生扩容,那么整个切片就和值传递一个样了
7.2.4 string和slice
string底层是一个byte数组,因此string也可以进行切片处理, 其原理就是因为底层使用byte数组存储了字符串的每一个字符
str := "abcdefg"slice := str[4:]fmt.Println(slice)
而这个底层的byte数组是不可见的,所以string也是不可修改的,也就说不能通过str[0]= 'z’方式来修改字符串
如果要修改,可以将字符串转为byte数组之后再进行修改,或者rune数组进行修改
str := "abcdefg"//slice := str[4:]//mt.Println(slice)strArr := []byte(str)strArr[0] = 'm'fmt.Println("str:", str, "strArr:", string(strArr)) // 注意这里输出的不一样我们转成[ ]byte后,可以处理英文和数字,但是不能处理中文
原因是[]byte字节来处理,而一个汉字,是3个字节,因此就会出现乱码
解决方法是将string转成[]rune即可,因为[]rune是按字符处理,兼容汉字
str1 := "我是Listen"sreArr1 := []rune(str1)sreArr1[0] = '你'fmt.Println("strArr1:", string(sreArr1))
7.3 Map
map是key-velue数据结构,又称为字段或者关联数组。类似其它编程语言的集合,在编程中是经常使用到。
map是引用类型,这个前面也提到过
key可以是什么类型
golang中的map的 key 可以是很多种类型,比如bool,数组,string,指针,channel ,还可以是只包含前面几个类型的接口,结构体,数组, 但是通常为int 、 string 注意: slice,map还有function不可以,因为这几个没法用==来判断, 至于value可以是任何东西
map声明的举例:
var a map[string]string
var a map[string]int
var a map[int]string
var a map[string]map[string]string
上面定义好之后, map必须进行make初始化,不然不能进行使用
注意:声明是不会分配内存的,初始化需要make ,分配内存后才能赋值和使用。
使用make的时候还有设置初始容量
7.3.1 map的CRUD
map增加和更新:
map[“key”]= value l/如果key还没有,就是增加,如果key存在就是修改。
map删除:
说明:
delete(map,“key”) ,delete是一个内置函数,如果key存在,就删除该key-value,如果key不存在,不操作,但是也不会报错
细节说明
1)如果我们要删除map的所有key ,没有一个专门的方法进行一次性除,必须逐个删除
2)或者map = make(…),make一个新的,让原来的成为垃圾,被gc回收
- map的简单遍历和复杂遍历
func main() {var kv map[string]stringkv = make(map[string]string, 4)kv["a"] = "aa"kv["b"] = "bb"val, find := kv["b"]if find { // 是否存在fmt.Println(val)}// 遍历for k, v := range kv {fmt.Println("k:", k, "v:", v)}fmt.Println("------------------------------------")// 复杂map的遍历infos := make(map[int]map[string]string, 4)_ ,ok := infos[1]if !ok { // 不存在infos[1] = make(map[string]string, 2)}values := infos[1] // 注意这里要获取make后的mapvalues["name"] = "listen"values["age"] = "22"values["id"] = "001"_ ,ok = infos[2]if !ok { // 不存在infos[2] = make(map[string]string, 2)}values = infos[2]values["name"] = "tom"values["age"] = "21"values["id"] = "002"for _, v := range infos {for kk, vv := range v {fmt.Println(kk, ":", vv)}}}
bb
k: a v: aa
k: b v: bb
name : tom age : 21 id : 002 name : listen age : 22 id : 001
7.3.2 map切片
基本介绍
切片的数据类型如果是map,则我们称为slice of map,map切片,这样使用则map个数就可以动态变化了。
func main() {// 申明一个map切片var stu []map[string]stringstu = make([]map[string]string, 2) // 此时意思是切片里有俩个map引用, 所以也只能存储俩个mapif stu[0] == nil {stu[0] = make(map[string]string, 2)stu[0]["name"] = "tom"stu[0]["age"] = "22"}if stu[1] == nil {stu[1] = make(map[string]string, 2)stu[1]["name"] = "listen"stu[1]["age"] = "21"}// 但是注意这里有个坑, 如果使用stu[2]就会出现panic, 这里要注意, 所以如果需要再次添加必须使用appends := map[string]string{"name":"lisa","age":"20",}stu = append(stu, s)fmt.Println(stu)
}
注意代码中注释说明的那个坑就好
八 结构体
- Golang也支持面向对象编程OOP,但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。所以我们说Golang支持面向对象编程特性是比较准确的。
- Golang没有类(class),Go语言的结构体(struct)和其它编程语言的类(class)有同等的地位,你可以理解Golang是基于struct来实现OOP特性的。
3)Golang面向对象编程非常简洁,去掉了传统OOP语言的继承、方法重载、构造函数和析构函数、隐藏的this指针等等 - Golang仍然有面向对象编程的继承(组合),封装(大小写)和多态(基于接口)的特性,只是实现的方式和其它OOP语言不一样,比如继承:Golang没有extends 关键字,继承是通过匿名字段来实现(组合)。
- Golang面向对象(OOP)很优雅,OOP本身就是语言类型系统(type system)的一部分,通过接口(interface)关联,耦合性低,也非常灵活。也就是说在Golang中面向接口编程是非常重要的特性。
type Person struct {Name stringage intinfos map[string]string
}func main() {p1 := Person{Name: "Listen",age: 22,infos: make(map[string]string, 2), // 必须}
}
如果结构体的字段是指针,slice, map这些初始的时候都是nil, 需要使用make之后才能分配空间才能进行正常使用
var p2 = new(Person) // 一个Person的指针(*p2).Name = "tom"p2.age = 21 // 这俩种方式都支持(*p2).infos = make(map[string]string, 2)fmt.Println(*p2)用new关键字出来的结构体是一个指向person的指针, 使用(*p2)和p2都可以直接操作数据, 这是因为go的设计者为了程序员使用方便,底层会对p2.age = 21进行处理, 变成我们第一种方式那样
8.1 结构体注意事项
- 结构体的所有字段在内存中是连续的
- 俩个结构体之间如果要相互转换,需要完全相同的字段(包括名字 类型 个数)
type A struct {Name string
}type B struct {Name string
}func main() {a := A{Name: "",}b := B{Name: "",}b = B(a)fmt.Println(b)
}
- struct的每个字段上,可以写上一个tag,该tag可以通过反射机制获取,常见的使用场景就是序列化和反序列化。
type Cat struct {Name string `json:"name"`Age int `json:"age"`
}func main() {marshal, _ := json.Marshal(Cat{Name: "bike",Age: 0,})fmt.Println(string(marshal))
}
{“name”:“bike”,“age”:0}
8.2 方法
Golang中的方法是作用在指定的数据类型上的 (即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是struct
方法也会被叫做接收器
type Cat struct {Name string `json:"name"`Age int `json:"age"`
}func (c Cat) eat() {c.Name = "listen"fmt.Println(c.Name, ": eating")
}func main() {cat := Cat{Name: "bike",Age: 0,}cat.eat()fmt.Println(cat) // {bike 0}test(cat)fmt.Println(cat) // {bike 0}
}func test(cat Cat) {cat.Name = "a"
}
上述写法会有一个问题, 因为go中结构体传参是值拷贝,所以test和eat里的修改不会影响外面,如果想要有影响,那就按照下面这样写
type Cat struct {Name string `json:"name"`Age int `json:"age"`
}func (c *Cat) eat() {c.Name = "listen"fmt.Println(c.Name, ": eating")
}func main() {cat := Cat{Name: "bike",Age: 0,}cat.eat()fmt.Println(cat)test(&cat)fmt.Println(cat)
}func test(cat *Cat) {cat.Name = "a"
}
而且我们大多数情况下都是使用指针进行函数的传参
- 有一个地方很类型java, 如果一个变量实现了string()这个方法,那么fmt.Println默认会调用这个变量的String()进行输出
8.2.1 方法和函数的区别
1)调用方式不一样
函数的调用方式:函数名(实参列表)
方法的调用方式:变量.方法名(实参列表)
2)对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
3)对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以
8.2.2 Go的工厂模式
func GetCat(name string, age int) *Cat {if ...return &Cat{Name: "",Age: 0,}
}
哈哈哈 大致就这样滴
8.3 Go的继承
Go中可以继承,只是通过嵌套匿名结构体的方式实现继承
也就是说:在Golang中,如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性。
目的就是:
代码复用性提高
扩展性和维护性提高
(复用性和扩展性,就是给基类实现一个方法,那么其子类都可以使用)
type People struct {Name stringAge intId int
}func (p *People) showInfo() {fmt.Println("info: ", p)
}type Man struct {PeopleSex string
}func (m *Man) showManInfo() {fmt.Println("man info: ", m)
}func main() {man := Man{People: People{Name: "Listen",Age: 1,Id: 1,},Sex: "男",}man.showManInfo()man.showInfo()// 或者man.People.showInfo()
}
8.3.1 Go继承注意事项
- 结构体可以使用嵌套匿名结构体所有的字段和方法,即:首字母大写或者小写的字段、方法,都可以使用
- 看下面代码
type Q struct {Name string
}type W struct {QName string
}func main() {w := W{Q: Q{Name: "Q",},Name: "W",}fmt.Println(w.Name)fmt.Println(w.Q.Name)
}
W
Q
解释:
(1)当我们直接通过w访问字段或方法时,其执行流程如下比如w.Name
(2编译器会先看w对应的类型有没有Name。如果有,则直接调用W类型的Name字段
(3)如果没有就去看W中嵌入的匿名结构体Q有没有声明Name字段,如果有就调用,如果没有继续查找…如果都找不到就报错.
访问字段和方法的时候都会有这个就近访问原则, 可以通过匿名结构体名来做区分
- 结构体嵌入两个(或多个)匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时,就必须明确指定匿名结构体名字,否则编译报错。这种多继承的方式不是很简洁明了, 不建议使用
type Q struct {Name string
}type E struct {Name string
}type W struct {QE//Name string
}func main() {w := W{Q: Q{Name: "Q",},E: E{Name: "E",},//Name: "W",}fmt.Println(w.Name)// errorfmt.Println(w.Q.Name) // right
}
-
如果一个struct 嵌套了一个有名结构体 ,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方法时,必须带上结构体的名字
-
当然也可以嵌入一个指针
type R struct {Name string
}type T struct {*R
}func main() {t := T{R: &R{Name: "",},}fmt.Println(t)
}
- 而且还可以嵌入一个基本数据类型, 但是不能相同类型的第二个,不然就无法区分
type Y struct {intstring
}func main() {y := Y{int: 0,string: "",}fmt.Println(y.string)fmt.Println(y.int)
}
九 接口
严格来说,Go的interface类型是一组需要被其他数据类型实现的函数方法的集合。对于需要满足接口的数据类型,它需要实现接口所需的所有方法。
简单地说,接口是定义了一组需要被实现的函数方法的抽象类型,实现接口的数据类型可以视为接口的实例。
如果满足以上情况,我们说数据类型实现了这个接口。因此,一个接口包含两部分:一组接口方法和一个接口类型,这样就可以定义其它数据类型的行为。
使用接口的最大优势,就是在定义函数时使用接口作为参数,那么在调用函数时,任何实现该接口类型的变量都可以作为函数的参数被传递。接口可以作为抽象类型的能力,是其最实际的价值。
接口也是为了实现多态特性和高内聚低耦合
1)接口里的所有方法都没有方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低偶合的思想。
2) Golang中的接口,不需要显式的实现。只要一个变量,含有接口类型中的所有方法,那么这个变量就实现这个接口。因此,Golang中没有implement这样的关键字
比如一个复用逻辑的具体实现, 这个函数的参数我们可以使用接口来传递,只要传递来的这个参数符合某个接口,那么我们就可以多态的形式去执行这个接口里的方法
go里面的接口实现是基于方法的,至于其他毫不关心
package mainimport ("fmt""strconv""time"
)type USB interface {// 声明方法Start(str string) stringStop(str string) string
}
type Phone struct {Id int
}func (p *Phone) Start(str string) string {// 将int转为string, 这种能避免乱码return strconv.Itoa(p.Id) + " Phone start: " + str
}
func (p *Phone) Stop(str string) string {return strconv.Itoa(p.Id) + " Phone stop: " + str
}type Computer struct {Id int
}func (c *Computer) Start(str string) string {return strconv.Itoa(c.Id) + " Computer start: " + str
}
func (c *Computer) Stop(str string) string {return strconv.Itoa(c.Id) + " Computer stop: " + str
}func Working(usb USB, desc string) {fmt.Println(usb.Start(desc))time.Sleep(time.Second)fmt.Println(usb.Stop(desc))
}func main() {phone := Phone{Id: 0,}computer := Computer{Id: 1001,}Working(&phone, "手机") // 接口的本质是指针, 所以需要取地址// 方式二var usb USBusb = &computerWorking(usb, "电脑")
}0 Phone start: 手机
0 Phone stop: 手机
1001 Computer start: 电脑
1001 Computer stop: 电脑
9.1 接口的应用(Sort接口实现)
- 比如很常见的排序,我们只需要设置一个接口,规定你要排序,你只要实现这个接口就可以调用sort方法进行排序
type Stu struct {Id int
}type Stus []Stufunc (s Stus) Len() int { // 切片是引用传递,所以给其数据类型实现sort接口return len(s) // 这里需要注意
}func (s Stus) Less(i, j int) bool {return s[i].Id > s[j].Id
}func (s Stus) Swap(i, j int) {s[i], s[j] = s[j], s[i]
}func main() {stus := Stus{}stus = append(stus, Stu{Id: 0,}, Stu{Id: 1,}, Stu{Id: 2,}, Stu{Id: 3,}, Stu{Id: 4,}, Stu{Id: 5,}, Stu{Id: 6,}, Stu{Id: 7,})sort.Sort(stus)fmt.Println(stus)
}
- 说现在有一个项目经理,管理三个程序员,开发一个软件,为了控制和管理软件,项目经理可以定义一些接口,然后由程序员具体实现。
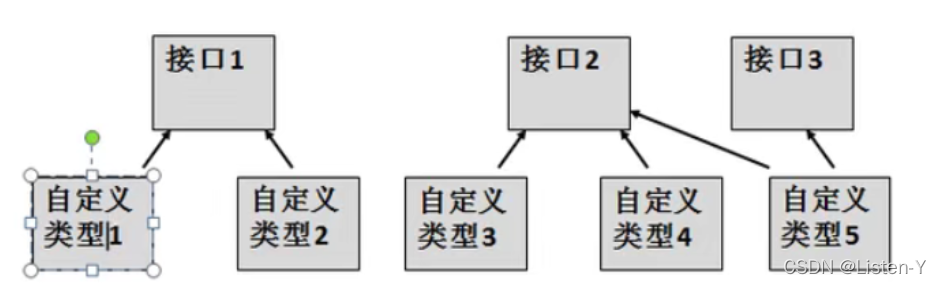
9.2 接口注意事项
- 接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)
// 方式二var usb USBusb = &computerWorking(usb, "电脑")
-
接口中所有的方法都没有方法体,即都是没有实现的方法。
-
在Golang中,一个自定义类型需要将某个接口的所有方法都实现,我们说这个自定义类型实现了该接口。
type USB interface {// 声明方法Start(str string) stringStop(str string) string
}
-
一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型。
-
只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型。
type Integer intfunc (i Integer) Start(str string) string {return fmt.Sprint(i) + " Integer start: " + str
}
func (i Integer) Stop(str string) string {return fmt.Sprint(i) + " Integer stop: " + str
}func main() {var i Integeri = 10fmt.Println(i.Stop("desc"))
}
-
一个接口可以实现多个接口
-
接口中不能有任何变量
-
一个接口(比如A接口)可以继承多个别的接口(比如B,C接口),这时如果要实现A接口,也必须将B,C接口的方法也全部实现。
-
所以本质来说接口interface是一个指针(引用类型, 所以如果没有给一个接口就行初始化就使用,会报panic, 所以使用到接口参数的时候,最好先给接口进行if判断)
-
空接口interface没有任何方法,所以所有类型都实现了空接口
type T interface {}func main() {var t Tt = Stu{Id: 0,}fmt.Println(t)t = Integer(1)fmt.Println(t)t = Computer{Id: 0,}fmt.Println(t)
}
9.3 实现接口和继承的比较
go可以通过匿名结构体字段实现继承,通过实现接口方法实现多态
所以继承是真的继承了代码, 而实现接口只是提供了一个自定义类型的规范
就比如我爸有钱,我可以直接继承他的钱,但是我爸会的技能,我还得通过实现接口才能表示我会这个技能
而多态就是基于接口实现,就和刚刚那个例子,虽然我和我弟都实现了那个接口学会了技能,但是我们俩个具体的做事风格还是不一样,企业招人就找会做的,但是做的风格又不一样,所以造成多态
-
go里面基于接口有参数的多态
在前面的Usb接口案例,Usb usb,即可以接收手机变量,又可以接收相机变量和电脑变量,就体现了Usb接口多态参数 -
go里还有数组的多态
演示一个案例:给Usb数组中,存放Phone结构体和Computer结构体变量
func main() {usbs := [3]USB{}usbs[0] = &Computer{}usbs[1] = &Phone{}usbs[2] = &Computer{}fmt.Println(usbs)
}
9.4 类型断言
我们上述演示的都是将一个变量赋予给接口, 那我们如何将一个接口赋予一个变量呢?
实现方式就是断言
看一段代码
func main() {var t interface{}point := Point{x: 0,y: 0,}t = pointfmt.Println(t)// 如何将t重新赋予给Pointvar point1 Pointpoint1 = t.(Point) // 类型断言fmt.Println(point1.x, point1.y)
}
类型断言,由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言
注意: 类型断言前后必须是完全相同的类型,否则就会失败, 比如int32转换前和转换后都必须是int32, 如果不一样断言前的类型,我们可以加上一些校验
func main() {var t interface{}var num float32num = 1.1t = numnum2, ok := t.(float64)if !ok {fmt.Println("convert error")} else {fmt.Printf("t type: %T value: %v\n", num2, num2)}
}
convert error
func main() {var t interface{}var num float64num = 1.1t = numnum2, ok := t.(float64)if !ok {fmt.Println("convert error")} else {fmt.Printf("t type: %T value: %v\n", num2, num2)}
}
t type: float64 value: 1.1
9.4.1 断言的实践
- 编写一个函数,可以判断输入的是什么类型
func typeJudge(items ...interface{}) {for index, v := range items {switch v.(type) {case int:fmt.Printf("第%v个参数 类型是%T 值是%v\n", index, v.(int), v)case float32:fmt.Printf("第%v个参数 类型是%T 值是%v\n", index, v.(float32), v)case string:fmt.Printf("第%v个参数 类型是%T 值是%v\n", index, v.(string), v)case Point:fmt.Printf("第%v个参数 类型是%T 值是%v\n", index, v.(Point), v)case *Point:fmt.Printf("第%v个参数 类型是%T 值是%v\n", index, v.(*Point), v) // 注意这个也是可以的case int64:fmt.Printf("第%v个参数 类型是%T 值是%v\n", index, v.(int64), v)default:fmt.Printf("第%v个参数 类型是%T 值是%v\n", index, v, v)}}
}func main() {itmes := make([]interface{}, 0)var num int = 1itmes = append(itmes, num)var num2 float32 = 1.1itmes = append(itmes, num2)itmes = append(itmes, "listen")itmes = append(itmes, Point{x: 0,y: 0,})itmes = append(itmes, &Point{x: 1,y: 1,})var num3 int64 = 9itmes = append(itmes, num3)typeJudge(itmes...)
}
第0个参数 类型是int 值是1
第1个参数 类型是float32 值是1.1
第2个参数 类型是string 值是listen
第3个参数 类型是main.Point 值是{0 0}
第4个参数 类型是*main.Point 值是&{1 1}
第5个参数 类型是int64 值是9
十 字符串处理
都是简单API, 大家看举例就行
func main() {// 判断两个utf-8编码字符串(将unicode大写、小写、标题三种格式字符视为相同)是否相同。fmt.Println(strings.EqualFold("ABC", "abc")) // ture// 判断s是否有前缀字符串prefix。fmt.Println(strings.HasPrefix("ABC", "AB")) // true// 判断字符串s是否包含子串substr。fmt.Println(strings.Contains("ABC", "B")) // true// 返回将所有字母都转为对应的小写版本的拷贝。fmt.Println(strings.ToLower("ABC")) // "abc"// 返回将所有字母都转为对应的大写版本的拷贝。fmt.Println(strings.ToUpper("abc")) // "ABC"// 返回count个s串联的字符串。fmt.Println(strings.Repeat("ABC", 2)) // "ABCABC"// 返回将s前后端所有cutset包含的utf-8码值都去掉的字符串。fmt.Println(strings.Trim(" ABC ", " ")) // "ABC"// 返回将s前后端所有空白(unicode.IsSpace指定)都去掉的字符串。fmt.Println(strings.TrimSpace("ABC ")) // "ABC"// 用去掉s中出现的sep的方式进行分割,会分割到结尾,并返回生成的所有片段组成的切片(每一个sep都会进行一次切割,即使两个sep相邻,也会进行两次切割)。如果sep为空字符,Split会将s切分成每一个unicode码值一个字符串。split := strings.Split("a b c d e", " ")fmt.Println(split) // [a b c d e]// 返回字符串表示的bool值。它接受1、0、t、f、T、F、true、false、True、False、TRUE、FALSE;否则返回错误。parseBool, err := strconv.ParseBool("F")fmt.Println(parseBool, err)// 返回字符串表示的整数值,接受正负号。//base指定进制(2到36),如果base为0,则会从字符串前置判断,"0x"是16进制,"0"是8进制,否则是10进制;//bitSize指定结果必须能无溢出赋值的整数类型,0、8、16、32、64 分别代表 int、int8、int16、int32、int64;返回的err是*NumErr类型的,如果语法有误,err.Error = ErrSyntax;如果结果超出类型范围err.Error = ErrRange。parseInt, err := strconv.ParseInt("1212", 10, 0)fmt.Println(parseInt, err)// 根据b的值返回"true"或"false"。fmt.Println(strconv.FormatBool(true))// 返回i的base进制的字符串表示。base 必须在2到36之间,结果中会使用小写字母'a'到'z'表示大于10的数字。fmt.Println(strconv.FormatInt(111, 10))// Atoi是ParseInt(s, 10, 0)的简写。fmt.Println(strconv.Atoi("121"))// Itoa是FormatInt(i, 10) 的简写。fmt.Println(strconv.Itoa(1212))
}
十一 文件操作
os包提供了操作系统函数的不依赖平台的接口。设计为Unix风格的,虽然错误处理是go风格的;失败的调用会返回错误值而非错误码。
通常错误值里包含更多信息。
例如,如果某个使用一个文件名的调用(如Open、Stat)失败了,打印错误时会包含该文件名,错误类型将为*PathError,其内部可以解包获得更多信息。
type PathError struct {Op stringPath stringErr error
}
11.1 文件打开和关闭
有打开就必须讲关闭, 如果没有close这个文件资源的连接就会一直有, 所以会有内存泄漏和资源浪费
其实文件的本质就是数据加一些文件特有标识符, 文件在程序中是以流的形式来操作的。

流:
数据在数据源(文件)和程序(内存)之间经历的路径
输入流:数据从数据源(文件)到程序(内存)的路径
输出流:数据从程序(内存)到数据源(文件)的路径
os.File封装所有文件相关操作,File是一个结构体
11.1.1 打开文件操作和函数
func main() {// 打开文件file, err := os.Open("D:\\test\\study.txt")if err != nil {log.Fatal("open file error")return}// 关闭defer file.Close()fmt.Println("file: ", file) // file: &{0xc0000d0780} 所以返回的file是一个指针}
11.2 带缓存区读文件操作
好处:不是一次性的把整个文件都读取进来,也不是一次性只读1个字节, 而是适配我们的内存进行读一部分, 处理一部分
11.2.1 io.Reader和io.Writer接口
如前所述,实现io.Reader接口需要实现Read()方法,io.writer()接口需要实现 write()方法。这两个接口在Go中只要涉及数据输入和输出会非常常见
type Reader interface {Read(p []byte) (n int, err error)
}
type Writer interface {Write(p []byte) (n int, err error)
}
11.2.2 缓冲和无缓冲的文件输入和输出
缓冲文件输入和输出发生在读取或写入数据之前有一个临时存储数据的缓冲区。
因此,你可以一次读取多个字节,而不是逐字节地读取一个文件。你将它放在一个缓冲区中,等待调用者以所需的方式读取它。非缓冲文件输入和输出发生在实际读取或写入数据之前没有临时存储数据的缓冲区时。
你可能会问的下一个问题是,如何决定何时使用缓冲文件输入和输出,以及何时使用非缓冲文件输入和输出。
在处理关键数据时,非缓冲文件输入和输出通常是更好的选择,因为缓冲读取可能导致过期的数据,而缓冲写入可能在计算机电源中断时导致数据丢失。然而,大多数时候,这个问题没有明确的答案。这意味着你可以使用任何使任务更容易实现的工具。
11.2.3 bufio包
顾名思义,bufio包是关于缓冲输入输出的。
所以bufio包实现了有缓冲的I/O。它包装一个io.Reader或io.Writer接口对象,创建另一个也实现了该接口,且同时还提供了缓冲和一些文本I/O的帮助函数的对象。
具体API可以去官网查看
11.3 读文件示例
func main() {// 打开文件file, err := os.Open("D:\\test\\study.txt")if err != nil {log.Fatal("open file error")return}// 关闭defer file.Close()// 创建一个带缓冲区的Readerreader := bufio.NewReader(file)// 读取内容for {// ReadString读取直到第一次遇到delim字节,返回一个包含已读取的数据和delim字节的字符串。//如果ReadString方法在读取到delim之前遇到了错误//它会返回在错误之前读取的数据以及该错误(一般是io.EOF)readString, err := reader.ReadString('\n')fmt.Println("error", err)if err == io.EOF {fmt.Println(readString)break}fmt.Print(readString)}fmt.Println("文件读取结束")
}
11.4 创建文件和写文件示例
基本介绍
func OpenFile(name string, flag int, perm FileMode) (*File, error) {
说明: os.OpenFile是一个更一般性的文件打开函数,它会使用指定的选项(如
O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/o。如果出错,错误底层类型是*PathError。
- 第一个参数文件路径和名字
- 第二个参数:文件打开模式(可以组合)
const (
O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
O_RDWR int = syscall.O_RDWR // 读写模式打开文件
O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)
- 第三个参数:权限控制(只适用于linux)
FileMode代表文件的模式和权限位。这些字位在所有的操作系统都有相同的含义,因此文件的信息可以在不同的操作系统之间安全的移植。不是所有的位都能用于所有的系统,唯一共有的是用于表示目录的ModeDir位。
const (
// 单字符是被String方法用于格式化的属性缩写。
ModeDir FileMode = 1 << (32 - 1 - iota) // d: 目录
ModeAppend // a: 只能写入,且只能写入到末尾
ModeExclusive // l: 用于执行
ModeTemporary // T: 临时文件(非备份文件)
ModeSymlink // L: 符号链接(不是快捷方式文件)
ModeDevice // D: 设备
ModeNamedPipe // p: 命名管道(FIFO)
ModeSocket // S: Unix域socket
ModeSetuid // u: 表示文件具有其创建者用户id权限
ModeSetgid // g: 表示文件具有其创建者组id的权限
ModeCharDevice // c: 字符设备,需已设置ModeDevice
ModeSticky // t: 只有root/创建者能删除/移动文件
// 覆盖所有类型位(用于通过&获取类型位),对普通文件,所有这些位都不应被设置
ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice
ModePerm FileMode = 0777 // 覆盖所有Unix权限位(用于通过&获取类型位)
)
这些被定义的位是FileMode最重要的位。另外9个不重要的位为标准Unix rwxrwxrwx权限(任何人都可读、写、运行)。这些(重要)位的值应被视为公共API的一部分,可能会用于线路协议或硬盘标识:它们不能被修改,但可以添加新的位。
r -> 4
w -> 2
x -> 1
11.4.1 新建文件写入
func main() {file, err := os.OpenFile("D:\\test\\study1.txt", os.O_WRONLY | os.O_CREATE, 0666)if err != nil {log.Fatal("open file error")}defer file.Close()writer := bufio.NewWriter(file)data := "hello"for i := 0; i < 5; i++ {_, _ = writer.WriteString(fmt.Sprintf("%v\n", data))}// 必须进行_ := writer.Flush()fmt.Println("写入成功")
}
11.4.2 覆盖写入
func main() {file, err := os.OpenFile("D:\\test\\study1.txt", os.O_WRONLY | os.O_CREATE | os.O_TRUNC, 0666)if err != nil {log.Fatal("open file error")}defer file.Close()writer := bufio.NewWriter(file)data := "byeBye"for i := 0; i < 5; i++ {_, _ = writer.WriteString(fmt.Sprintf("%v\r\n", data)) //这里使用\n是为了换行, 也支持/r/n进行换行}// 必须进行_ = writer.Flush()fmt.Println("写入成功")
}
11.4.3 追加写入
func main() {file, err := os.OpenFile("D:\\test\\study1.txt", os.O_WRONLY | os.O_CREATE | os.O_APPEND, 0666)if err != nil {log.Fatal("open file error")}defer file.Close()writer := bufio.NewWriter(file)data := "Listen"for i := 0; i < 5; i++ {_, _ = writer.WriteString(fmt.Sprintf("%v\r\n", data)) //这里使用\n是为了换行, 也支持/r/n进行换行}// 必须进行_ = writer.Flush()fmt.Println("写入成功")
}
11.4.4 读出原数据再追加写入
func main() {file, err := os.OpenFile("D:\\test\\study1.txt", os.O_RDWR | os.O_CREATE | os.O_APPEND, 0666)if err != nil {log.Fatal("open file error")}defer file.Close()// 先读出来data := make([]string, 0)reader := bufio.NewReader(file)for {readString, err := reader.ReadString('\n')if err == io.EOF {break}data = append(data, readString)}fmt.Println("读取数据成功: ", data)// 写入数据writer := bufio.NewWriter(file)for i := 0; i < len(data); i++ {_, _ = writer.WriteString(fmt.Sprintf("%v", data[i])) //这里使用\n是为了换行, 也支持/r/n进行换行}// 必须进行_ = writer.Flush()fmt.Println("写入成功")
}
11.4.5 判断文件是否存在
func FileExist(path string) (bool, error) {_, err := os.Stat(path)if err == nil { // 文件或者文件夹存在return true, err}if os.IsNotExist(err) {return false, nil}return false, err
}
golang判断文件或文件夹是否存在的方法为使用os.Stat()函数返回的错误值进行判断:
1)如果返回的错误为nil,说明文件或文件夹存在
2)如果返回的错误类型使用os.IsNotExist()判断为true,说明文件或文件夹不存在
3)如果返回的错误为其它类型,则不确定是否在存在
11.4.6 文件拷贝
// 这种方式简单不严谨
func CopyFile(srcFileName, dstFileName string) bool {data, err := ioutil.ReadFile(srcFileName)if err != nil {return false}fmt.Println(data)err = ioutil.WriteFile(dstFileName, data, 0666)return err == nil
}// 合理的方式
func CopyFile2(srcFileName, dstFileName string) bool {openFile, err := os.Open(srcFileName)if err != nil {return false}defer openFile.Close()reader := bufio.NewReader(openFile)dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY|os.O_TRUNC|os.O_CREATE, 0666)if err != nil {return false}defer dstFile.Close()writer := bufio.NewWriter(dstFile)_, err = io.Copy(writer, reader)return err == nil
}
11.4.7 字符统计
type Count struct {CharCount intNumCount intSpaceCount intOtherCount int
}func count(data []string) Count {c := Count{CharCount: 0,NumCount: 0,SpaceCount: 0,OtherCount: 0,}for _, val := range data {for _, ch := range val {switch {case ch >= 'a' && ch <= 'z':fallthroughcase ch >= 'A' && ch <= 'Z':c.CharCount++case ch >= '0' && ch <= '9':c.NumCount++case ch == ' ' || ch == '\t':c.SpaceCount++default:c.OtherCount++}}}return c
}func main() {open, err := os.Open("D:\\test\\study.txt")if err != nil {return}reader := bufio.NewReader(open)data := make([]string, 0)for true {readString, err := reader.ReadString('\n')if err == io.EOF {break}data = append(data, readString)}fmt.Println(count(data))
}
如果涉及到统计中文, 就必须先将字符串转为rune[]
11.3 flag包用来解析命令行参数
比如:
cmd>main.exe -f c:/aaa.txt -p 200 -u root
这样的形式命令行,go设计者给我们提供了flag包,可以方便的解析命令行参数,而且参数顺序可以随意
请编写一段代码,可以获取命令行各个参数.
func main() {fmt.Println("flags: ", os.Args)// 解析数据var f stringvar p intvar u stringflag.StringVar(&f, "f", "", "文件路径,默认为空")flag.IntVar(&p, "p", 0, "端口号,默认为0")flag.StringVar(&u, "f", "root", "用户,默认为root")flag.Parse() // 必须进行这步,进行数据解析
}
十二 Json
JSON易于机器解析和生成,并有效地提升网络传输效率,通常程序在网络传输时会先将数据(结构体、map等)序列化成json字符串,到接收方得到json字符串时,在反序列化恢复成原来的数据类型(结构体、map等).这种方式已然成为各个语言的标准。
https://www.json.cn
12.1 使用Go演示序列化和反序列化
func main() {// 演示将map进行序列化data := make(map[string]interface{}, 0)data["name"] = "listen"data["age"] = 22data["id"] = 329043988827384909data["score"] = 98.5marshal, err := json.Marshal(data)if err != nil {return}fmt.Println(string(marshal))
}
func main() {jsonData := "{\"age\":22,\"id\":329043988827384909,\"name\":\"listen\",\"score\":98.5}"var data map[string]interface{}// 这里的map不需要make也能使用,因为在json.Unmarshal中已经进行了makeerr := json.Unmarshal([]byte(jsonData), &data)if err != nil {return}fmt.Println(data)
}
12.2 使用tag优化结构体序列化
打tag可以方便前端理解序列化后的数据
type Stu struct {Name string `json:"name"`Id int `json:"id"`
}func main() {stu := Stu{Name: "Listen",Id: 1001,}marshal, err := json.Marshal(stu)if err != nil {return}fmt.Println(string(marshal))
}
{“name”:“Listen”,“id”:1001}
十三 单测
Go语言中自带有一个轻量级的测试框架testing和自带的go test命 令来实现单元测试和性能测试,testing框 架和其他语言中的测试框架类似,可以基于这个框架写针对
相应函数的测试用例,也可以基于该框架写相应的压力测试用例。通过单元测试,
可以解决如下问题:
1)确保每个函数是可运行,并且运行结果是正确的
2)确保写出来的代码性能是好的,
3)单元测试能及时的发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
PS:
God单测的名字是有严格的规范,文件名是必须,因为是以_test作为文件结尾, 其原因就是为了让其作为扫描条件进行扫描, 函数名不是必须,但是函数名尽量友好以便阅读性
package study_testingfunc add(a, b int) int {return a + b
}
package study_testingimport ("testing"
)func TestAdd(t *testing.T) {res := add(10, 20)if res != 30 {t.Fatal("test add 不符合预期")}t.Logf("test add 符合预期 res: %v\n", res)
}- 注意我这里使用的不是go mod项目,所以使用idea自带的go test会有问题,所以直接使用命令执行测试文件即可
D:\code\GO\20220102\study_testing> go test -v func.go func_test.go
=== RUN TestAdd
func_test.go:12: test add 符合预期 res: 30
— PASS: TestAdd (0.00s)
PASS
ok command-line-arguments 0.182s
看一下他的执行顺序

go test命令先会把XXX_test文件以文件名固定格式扫描到,对其进行编译后,在testing框架的main方法里执行TestAdd函数
13.1 细节说明
- 单元测试快速入门总结:
1)测试用例文件名必须以。test.go 结尾。比如cal test.go , cal不是固定的。
2)测试用例函数必须以Test开头,一般来 说就是Test+被测试的函数名,比如TestAddUpper.
3) TestAddUpper(t tesing.T) 的形参类型必须是testing.T
4)一个测试用例文件中,可以有多个测试用例函数,比如TestAddUpper、 TestSub
5)运行测试用例指令
(1) cmd>go test [如果运行正确,无日志,错误时,会输出日志]
(2) cmd>go test-v [运 行正确或是错误,都输出日志]
6)当出现错误时, 可以使用t.Fatalf来格式化输出错误信息,并退出程序
7) t.Logf 方法可以输出相应的日志
8)测试用例函数,并没有放在main函数中,也执行了,这就是测试用例的方便之处
9) PASS表示测试用 例运行成功,FAIL 表示测试用例运行失败
十四 协程
进程和线程的简单说明
1)进程就是程序程序在操作系统中的一次执行过程,是系统进行资源分配的最小单位
2)线程是进程的一个执行实例,是程序执行的最小单元,也就是CPU调度的最小单位,它是比进程更小的能独立运行的基本单位。
3) 一个进程可以创建核销毁多个线程,同一个进程中的多个线程可以并发执行。
4)一个程序至少有一个进程,一个进程至少有一个线程
14.1 Go协程和Go主线程
- Go主线程(有程序员直接称为线程/也可以理解成进程): 一个Go线程上,可以起
多个协程,你可以这样理解,协程是轻量级的线程。 - Go协程的特点
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
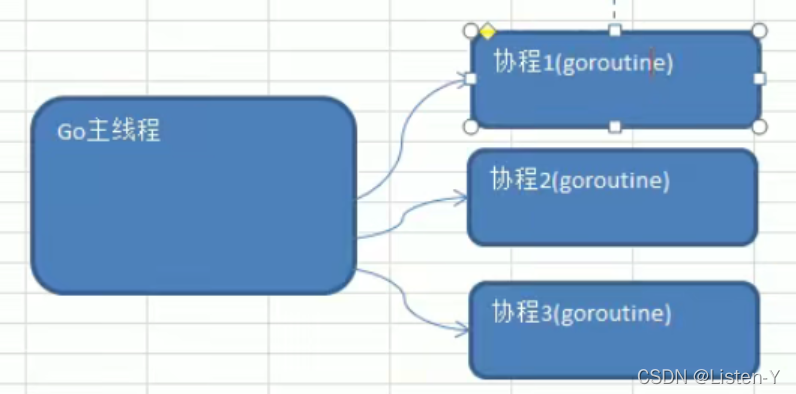
- 小结
1)主线程是一个物理线程,直接作用在cpu上的。是重量级的,非常耗费cpu资源。
2)协程从主线程开启的,是轻量级的线程,是用户态的。内存消耗和上下文切换时对资源消耗相对小。
- Golang的协程机制是重要的特点, 可以轻松的开启,上万个协程。其它编程语言
的并发机制是一般基于线程的,开启过多的线程,资源耗费大,这里就突显Golang在并发上的优势了
- 一个小例子, 让主线程和一个协程同时输出hello world
func main() {go printHello()for i := 0; i < 10; i++ {fmt.Println("主线程: ", "hello ", i)time.Sleep(time.Second)}fmt.Println("主线程: over")
}func printHello() {// 首先让协程休眠一秒time.Sleep(time.Second)for i := 0; i < 10; i++ {fmt.Println("协程: ", "hello ", i)time.Sleep(time.Second)}fmt.Println("协程: over")
}
上述代码协程的over不一定可以输出来,主要原因就是只要主线程退出,那么其开辟的协程就会退出
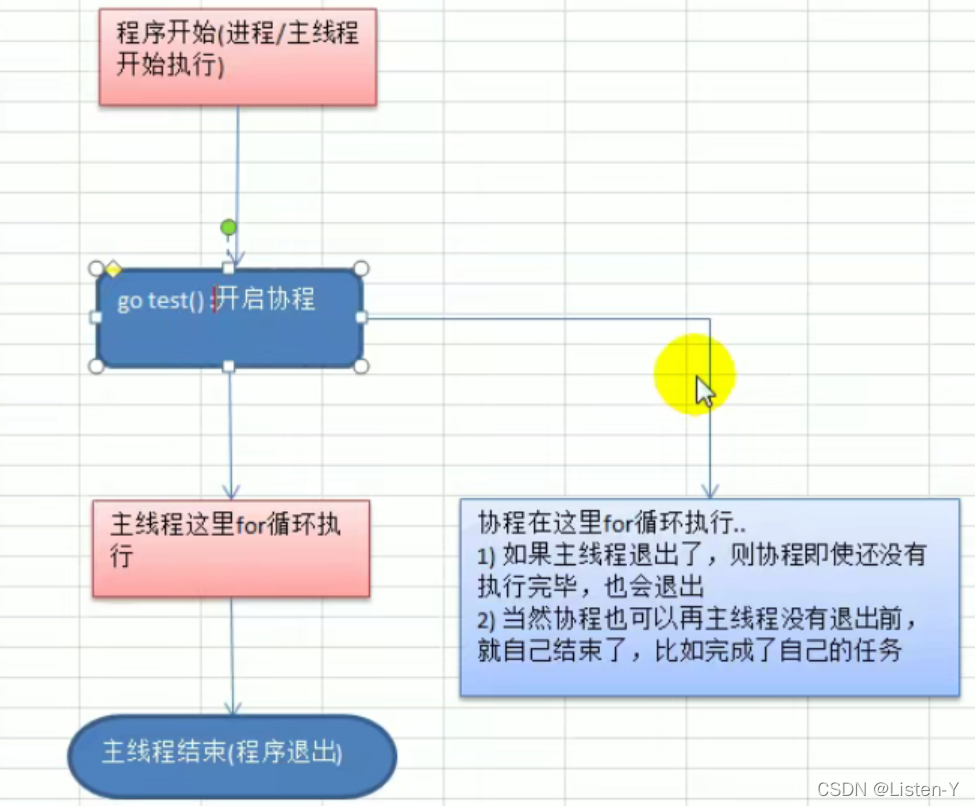
14.2 MPG模式(协程的调度模型)
MPG模式基本介绍

1)M:操作系统的主线程(是物理线程)
2) P:协程执行需要的上下文
3)G:协程
14.2.1 goroutine的调度模型
-
MPG模式运行的状态1
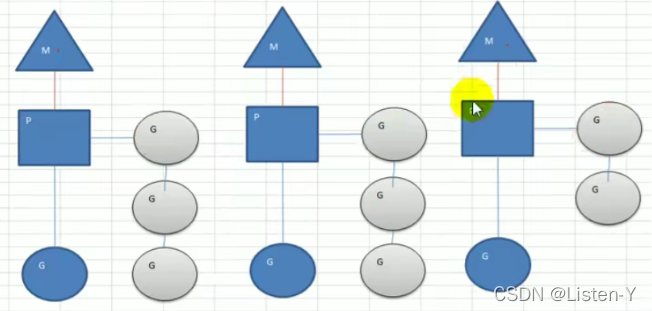
1)当前程序有三个M(主线程),如果三个M都在一个cpu运行,就是并发,如果在不同的cpu运行就是并行,并且每个主线程都会有自己的上下文空间
2)M1,M2,M3都正在执行一个蓝色的G(协程),M1的协程等待队列有三个,M2的协程等待队列有3个,M3协程等待队列有2个
3)从上图可以看到: Go的协程是轻量级的线程,是用户态的,即使进行了协程调度也不会进行到内核态的转变,Go可以容易的起上万个协程。
4)其它程序c/java的多线程,往往进行调度上下文切换会进入内核态的,比较重量级,几千个线程可能耗光cpu -
MPC运行的状态2
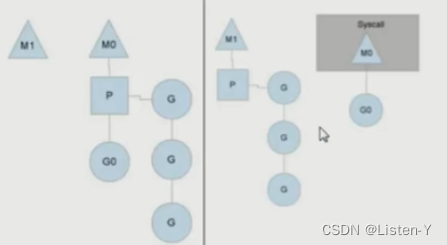
1)分成两个部分来看,先看左部分
2)原来的情况是M0主线程正在执行Go协程,另外有三个协程在队列等待
3)如果M0的Go协程阻塞,比如读取文件或者数据库等
4)这时就会创建M1主线程(也可能是从已有的线程池中取出M1),并且将等待的3个协程挂到M1下开始执行,M0的主线程下的G0仍然执行文件io的读写。
5)这样的MPG调度模式,可以既让Go执行,同时也不会让队列的其它协程一直阻塞,仍然可以并发/并行执行。
6)等到Go不阻塞了,M0会被唤醒继续执行G0。
runtime这个包可以提供go运行时与环境的互操作,比如获取当前CPU的数量和设置最大的主线程数据
14.3 资源竞争问题
多线程模式下操作数据必然会造成数据的不确定性,降低系统的安全性,本质就是我们知道的本发写问题,一旦出现这类问题,极易造成panic
我们可以使用
go build -race就可以看到程序有没有资源竞争问题
但是多线程编程自然也会大大的提高程序的执行和运算效率, 比如看下面需求
需求。现在要计算1-20 的各个数的阶乘,并且把各个数的阶乘放入到map 中。最后显示出来。要求使用goroutine完成
var (retMap = make(map[int]uint64, 200)
)func main() {for i := 1; i <= 200; i++ {go calculation(i)}time.Sleep(5 * time.Second)// 休眠5秒等待协程执行fmt.Println(retMap)
}func calculation(num int) {var ret uint64 = 1 //防止数据放不下for i := 2; i <= num; i++ {ret = ret * uint64(i)}retMap[num] = ret
}
fatal error: concurrent map writes
会有异常爆出
- 解决办法
- 加锁
var (retMap = make(map[int]uint64, 200)// 互斥锁lock sync.Mutex
)func main() {for i := 1; i <= 20; i++ {go calculation(i)}time.Sleep(5 * time.Second)// 休眠5秒等待协程执行// 这里也需要加锁,防止出现并发读写问题lock.Lock()fmt.Println(retMap)lock.Unlock()
}func calculation(num int) {var ret uint64 = 1 //防止数据放不下for i := 2; i <= num; i++ {ret = ret * uint64(i)}lock.Lock()retMap[num] = retlock.Unlock()
}
加锁可以保证互斥性,防止出现并发读和并发写问题, 但是这个做法效率很低,需要阻塞等待写和读
- 使用安全的map
var (retMap = sync.Map{}
)func main() {for i := 1; i <= 20; i++ {go calculation(i)}time.Sleep(2 * time.Second)retMap.Range(func(key, value interface{}) bool {fmt.Println("key: ", key, "value: ", value)return true})
}func calculation(num int) {var ret uint64 = 1 //防止数据放不下for i := 2; i <= num; i++ {ret = ret * uint64(i)}retMap.Store(num, ret)
}
使用这种方式,效率会有提升,但是我们不知道什么时候计算完,也就是在主线程那块,我们不知道休眠多久,以至于也会降低效率
- 使用管道,Golong高级编程里有一句话,使用管道实现并发安全才是真正的优秀代码
十五 管道Channel
为什么需要channel
前面使用全局变量加锁同步来解决goroutine的通讯,但不完美
1)主线程在等待所有goroutine全部完成的时间很难确定,我们之前代码设置10秒,仅仅是估算。
2)如果主线程休眠时间长了,会加长等待时间,如果等待时间短了,可能还有
goroutine处于工作状态,这时也会随主线程的退出而销毁
3)通过全局变量加锁同步来实现通讯,也并不利用多个协程对全局变量的读写操作。
4)上面种种分析都在呼唤一个新的通讯机制-channel
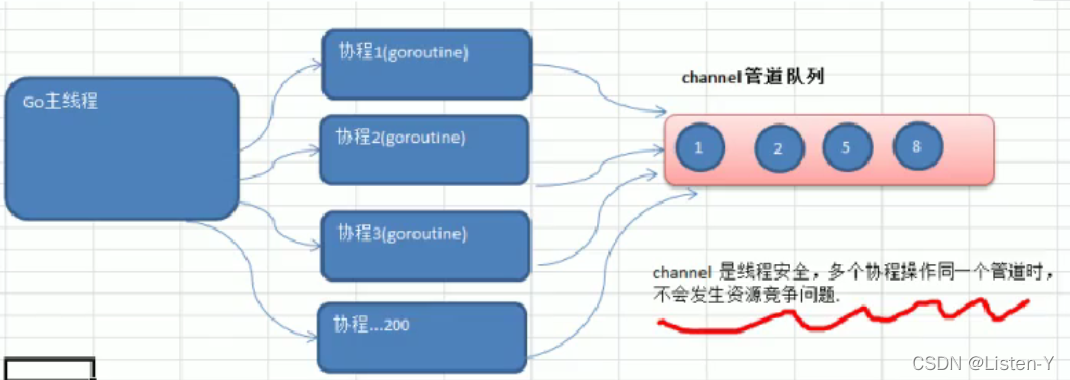
- channel的介绍
- channle本质就是一个数据结构-队列
2)数据是先进先出【FIFO : first in first out】
3)线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全
的 - channel是有类型的,一个string的channel只能存放string类型数据。
15.1 channel的基本使用
var变量名chan数据类型举例:
var intChan chan int (intChan用于存放int数据)
var mapChan chan map[int]string (mapChan用于存放map[int]string类型)
var perChan chan Person (用于存储Person类型)
var perChan2 chan Person (用于存储Person类型)
说明
1)channel是引用类型
2)channel 必须初始化才能写入数据 ,即make后才能使用
3)管道是有类型的.ntChan只能写入整数int
- 简单的读和写
func main() {// 初始化var intCh chan intintCh = make(chan int, 1) // 有缓存管道,可以缓存一个单位的数据//写入数据intCh <- 10// 读出数据ret := <- intChfmt.Println(ret)
}
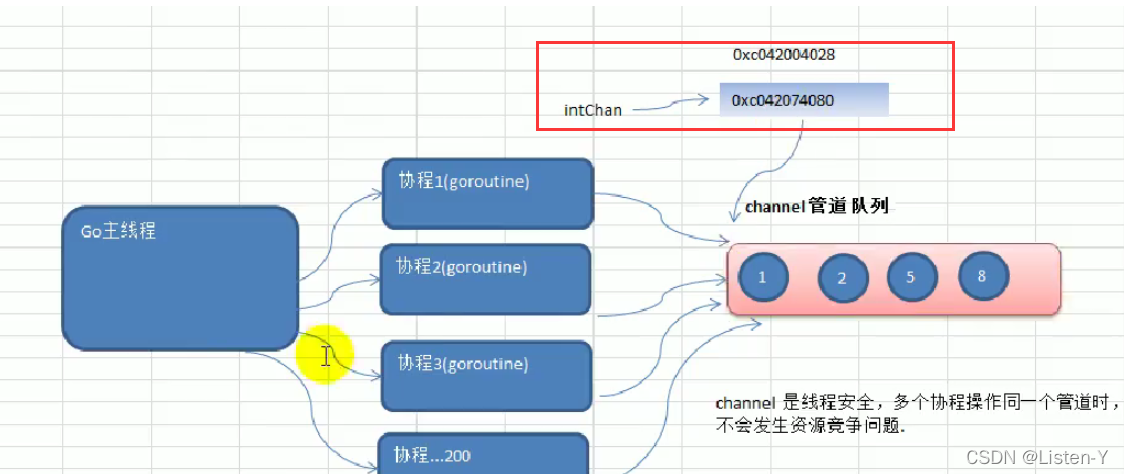
- 理解channel, 看下面代码
func main() {intCh := make(chan int, 3)fmt.Printf("intCh的值: %v, intCh的类型: %T, intCh的地址: %p\n", intCh, intCh, &intCh)// intCh的值: 0xc00007e000, intCh的类型: chan int, intCh的地址: 0xc000006028
}
由上我们可以知道,管道本身其实是存储了一个地址的指针,那个指针指向了一个另一个地址,增地址上存储了管道里的数据
15.1.1 channel的基本使用的注意事项
- channel中只能存放指定的数据类型
- channle的数据放满后,如果没有其他协程使用这个管道的入口,就不能再放入了,否则会发生deadlock
- 如果从channel取出数据后,可以继续放入
- 在没有使用协程的情况下,如果channel数据取完了,再取,就会报dead lock(死锁)
- 可以定义空接口型的管道,那样就可以放入任何数据类型的数据,但是取出的时候得进行断言
15.2 channel的关闭
使用内置函数close可以关闭channel,当channel关闭后,就不能再向channel写数据了,否则会发生panic,但是仍然可以从该channel读取数据。
func main() {intCh := make(chan int, 3)fmt.Printf("intCh的值: %v, intCh的类型: %T, intCh的地址: %p\n", intCh, intCh, &intCh)// intCh的值: 0xc00007e000, intCh的类型: chan int, intCh的地址: 0xc000006028close(intCh)
}
15.3 channel的遍历
channel支持for–range的方式进行遍历,强烈不推荐使用for循坏遍历,请注意两个细节
1)在遍历时,如果没有其他协程操作channel入口并且channel没有关闭,则回出现deadlock的错误
2)在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历。
func main() {intCh := make(chan int, 3)intCh <- 1intCh <- 2intCh <- 3close(intCh)for ch := range intCh {fmt.Println(ch)}
}
- 还可以这样写
intCh := make(chan int, 3)intCh <- 1intCh <- 2intCh <- 3close(intCh)//for ch := range intCh {// fmt.Println(ch)//}for true {v, ok := <- intChif !ok {break}fmt.Println(v)}
15.4 解决例题
需求。现在要计算1-20 的各个数的阶乘,并且把各个数的阶乘放入到map 中。最后显示出来。要求使用goroutine完成
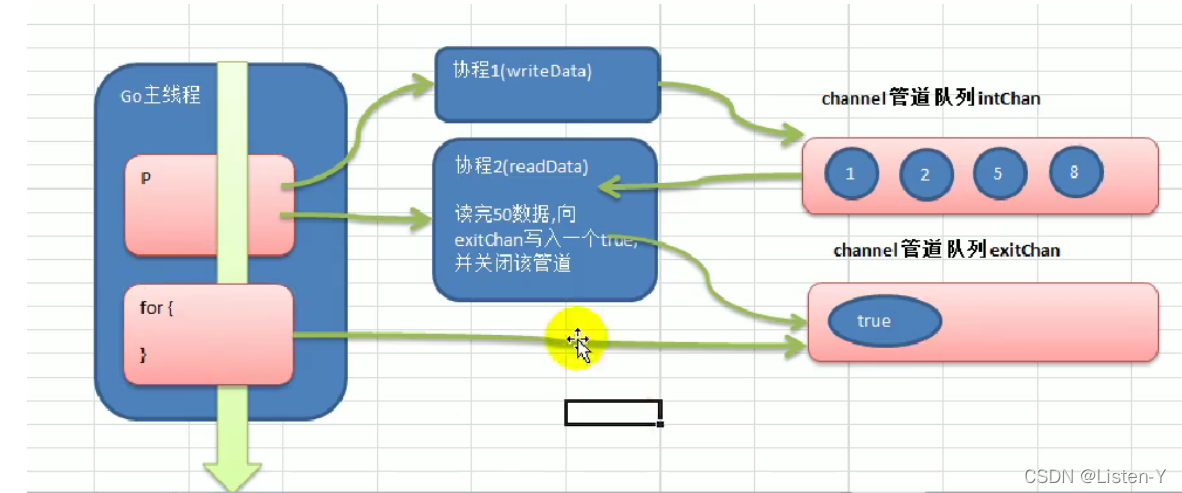
为了最大化效率,我们可以使用协程加管道的方式实现
1)开启一个writeData协程,向管道intChan中写入50个整数.
2)开启一个readData协程,从管道intChan中读取writeData写入的数据。
3)注意: writeData和readDate操作的是同一个管道
4)主线程需要等待writeData和readDate协程都完成工作才能退出
5)所以使用一个exit管道控制主线程的退出
var dataMap = make(map[int]uint64, 20)func main() {intCh := make(chan int, 20)exitCh := make(chan bool, 1)go writeData(intCh)go readData(intCh, exitCh)// 下面这俩种写法都可以,也没有什么大区别
/* for true {v, ok := <- exitChif !ok {break}fmt.Println(v)}*/for ch := range exitCh {if ch {break}}fmt.Println(dataMap)
}func writeData(intCh chan int) {for i := 1; i <= 20; i++ {intCh <- i}// 如果管道不再需要放入数据就及时关闭close(intCh)
}func readData(intCh chan int, exitCh chan bool) {for true {num, ok := <- intChif !ok {break}// 计算var ret uint64 = 1 //防止数据放不下for i := 2; i <= num; i++ {ret = ret * uint64(i)}dataMap[num] = ret}// 计算完成后退出exitCh <- trueclose(exitCh)
}
- 如果注销掉 go readData这行代码,程序会怎么样
答:如果只是向管道写入数据,而没有读取,就会出现阻塞而dead lock,原因是intChan容量是20,而代码writeData会写入20个数据,因此会阻塞在writeData的 ch c- i
一个协程不断的写数据,如果发现数据满了就会触发编译器处理,
如果编译器发现没有协程读这个管道的数据,就会立即爆出一个死锁的错误,如果编译器发现有协程去读这个管道,不管他快慢,都不会发生死锁deadlock,
读数据如果发现管道没有数据,同理,也会触发编译器的优化判断
15.4.1 例题2
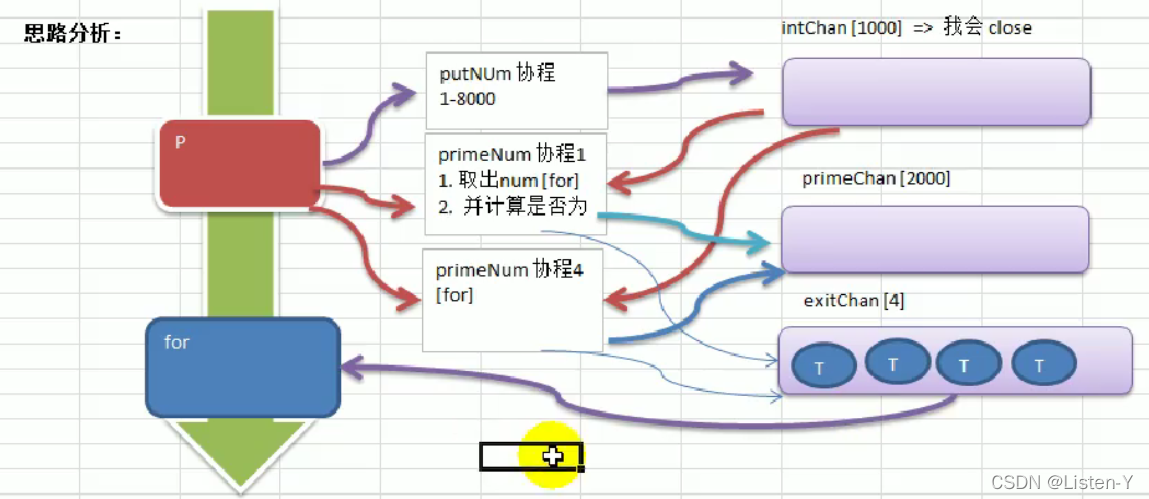
需求:要求统计1-200000的数字中,哪些是素数?这个问题在本章开篇就提出了,现在我们有goroutine和channel的知识后,就可以完成了
思路:
开启一个write协程往intchan管道写数据,开启4个read协程读数据然后计算,并且将结果写入primechan管道,最后由exitchan控制程序退出
func main() {intChan := make(chan int, 50)primeChan := make(chan int, 2000)exitChan := make(chan bool, 4)//写数据go writeData(intChan)// 读数据for i := 0; i < 4; i++ {go readData(intChan, primeChan, exitChan)}// 控制退出for i := 0; i < 4; i++ {<- exitChan}close(primeChan)close(exitChan)for num := range primeChan {fmt.Println(num)}}func writeData(intChan chan int) {for i := 0; i < 2000; i++ {intChan <- i}close(intChan)
}func readData(intChan chan int, primeChan chan int, exitChan chan bool) {for num := range intChan {flag := true//判断num是不是素数for i := 2; i < num;i++ {if num % i == 0 {//说明该num不是素数flag = falsebreak}}if flag {primeChan <- num}}//当数据取完exitChan <- true
}
15.5 只读只写channel
func main() {intChan := make(chan int, 2)testIn(intChan)testOut(intChan)
}func testOut(outChan <-chan int) {fmt.Println(<- outChan)fmt.Println(<- outChan)
}func testIn(inChan chan<- int) {inChan <- 10inChan <- 22
}
使用这种方式可以提高代码阅读性和,防止误操作,编译器也会对其进行优化,效率也会有些许提升
15.6 select
之前我们发现如果从一个管道读数据并且此时管道缓冲区为空,然后写数据的协程又很慢,就会造成读数据的协程阻塞,为了避免阻塞,select可以按顺序查看管道数据是否准备就绪,只要有一个管道有数据,就会退出select,如果都没有准备好,就会走default

func main() {one := make(chan int, 1)two := make(chan int, 1)three := make(chan int, 1)go testPut(one, 1)go testPut(two, 2)go testPut(three, 3)for {flag := falseselect {case v := <-one:fmt.Println("one: ", v)case v := <-two:fmt.Println("two: ", v)case v := <-three:fmt.Println("three: ", v)default:fmt.Println("over")close(one)close(two)close(three)flag = true}if flag {break}time.Sleep(time.Second)}
}func testPut(ch chan<- int, times int) {for i := 1; i < times * 3; i++ {num := i * timesch <- num}//close(ch) // 使用elect的时候这里不能close, 不然select的对应channel的case处一直会返回零值
}
two: 2
one: 1
one: 2
two: 4
two: 6
three: 3
three: 6
three: 9
two: 8
three: 12
two: 10
three: 15
three: 18
three: 21
three: 24
over
Process finished with exit code 0
15.6.1 select注意事项
- select可以解决管道不关闭时,读出现的deadlock问题
- 如果使用select处理管道,那对应的管道就不应该在其他地方关闭,因为一旦关闭了管道,那么case处会一直返回默认值,有概率不触发default
- 所以select还可以用在我们不确定什么时候关闭管道的时候,可以在default处对其进行关闭
15.7 channel总结
- 如果没有其他协程写数据,此时向一个空管道读数据,会造成deadlock,如有编译器检查到有其他协程写数据就不会造成deadlock
- 如果没有其他协程读数据,此时向一个满管道写数据,会造成deadlock,如有编译器检查到有其他协程读数据就不会造成deadlock
- 如果一个管道已经关闭, 如果再向这个管道写数据,就会发生panic
- 如果一个管道已经关闭,此时再读,如果缓冲区为空,会返回一个零值
- 协程出发生panic,也会导致主线程的崩溃,所以要在协程使用recove避免panic
- 为了防止读出现deallock,可以使用select避免
十六 反射
- 反射最常用的地方就是适配器,还有序列化
16.1 反射基本使用
基本介绍
1)反射可以在运行时动态获取变量的各种信息,比如变量的类型,类别
2)如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段方法)
3)通过反射,可以修改变量的值,可以调用关联的方法。
4)使用反射,需要import (“reflect”)
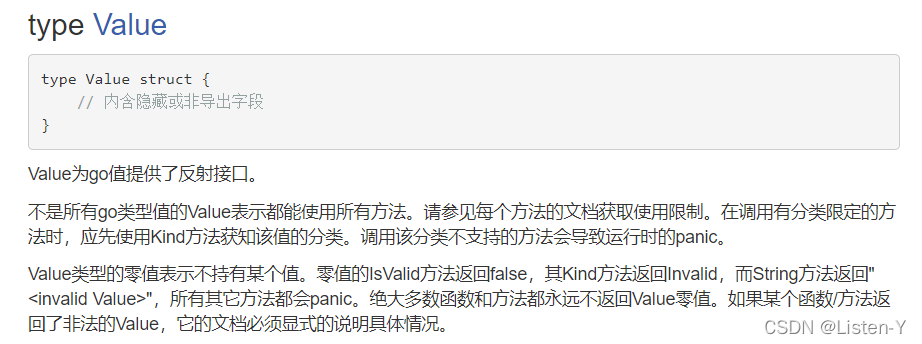
reflect包实现了运行时反射,允许程序操作任意类型的对象。典型用法是用静态类型interface{}保存一个值,通过调用TypeOf获取其动态类型信息,该函数返回一个Type类型值。调用ValueOf函数返回一个Value类型值,该值代表运行时的数据。
- 所以最常用的就是typeOf和valueOf

最好去看官网! 对应的也有很多方法

API官网解释的很清楚,对照着文档,自己调用演示演示就行,我下面主要讲一些经典的案例~
func main() {num := 10// 获得valueOfvalueOf := reflect.ValueOf(num)fmt.Println(valueOf.Kind()) // int// 通过valueOf获得typeOfi := valueOf.Interface()typeOf := reflect.TypeOf(i)fmt.Println(typeOf.Kind()) // int// 原获取到numnum2 := i.(int)fmt.Println(num2)// 直接获取typeOfof := reflect.TypeOf(num2)fmt.Println(of.Kind()) // int
}
- . 所以说valueOf其实也是一个桥接,可以通过这个再去获取Type,当然也可以直接获得typeOf
16.2 实际使用场景例题
16.2.1 运行时确定调用接口(桥接模式)
不知道接口调用哪个函数,根据传入参数在运行时确定调用的具体接口,这种需要对函数或方法反射.例如以下这种桥接模式
// 第一个参数funcPtr以接口的形式传入函数指针,
// 函数参数args以可变参数的形式传入,
// bridge函数中可以用反射来动态执行funcPtr函数
func bridge(functionPtr interface{}, args ...interface{}) {}
16.2.2 对结构体序列化
- 比如我们之前学的
tag就是通过反射获得对应字段下的tag参数, 然后生成想要的json字符串
16.3 变量 interface{} reflect.value 相互转换
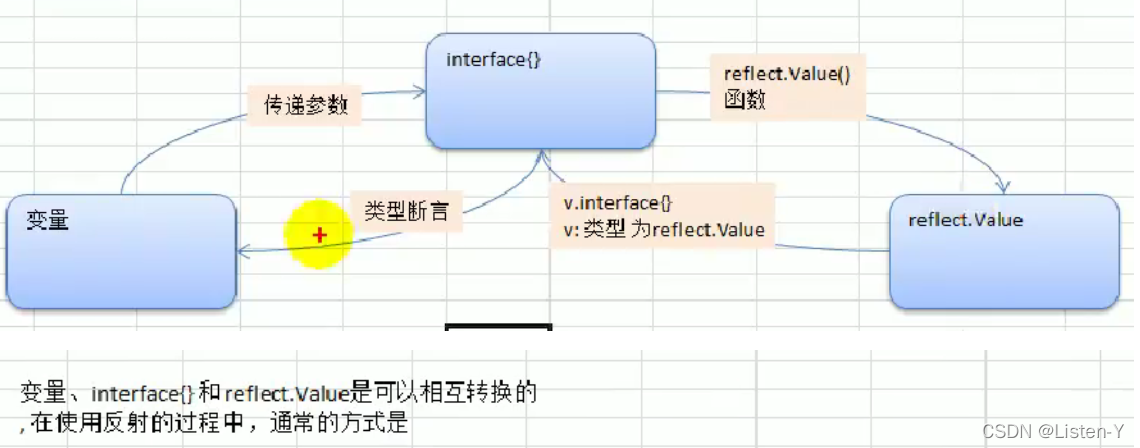
//专门用于做反射
func test(b interface{}) {//1.如何将Interface}转成reflect.valuerVal := reflect.ValueOf(b)//2.如何将reflect.Value-> interface{}ival :=rVal.Interface()//3.如何将interface{}转成原来的变量类型,使用类型断言v:= ival.(int)fmt.Println(v)
}
- 处理结构体也是这样, 不用做区分
16.4 区分kind和type
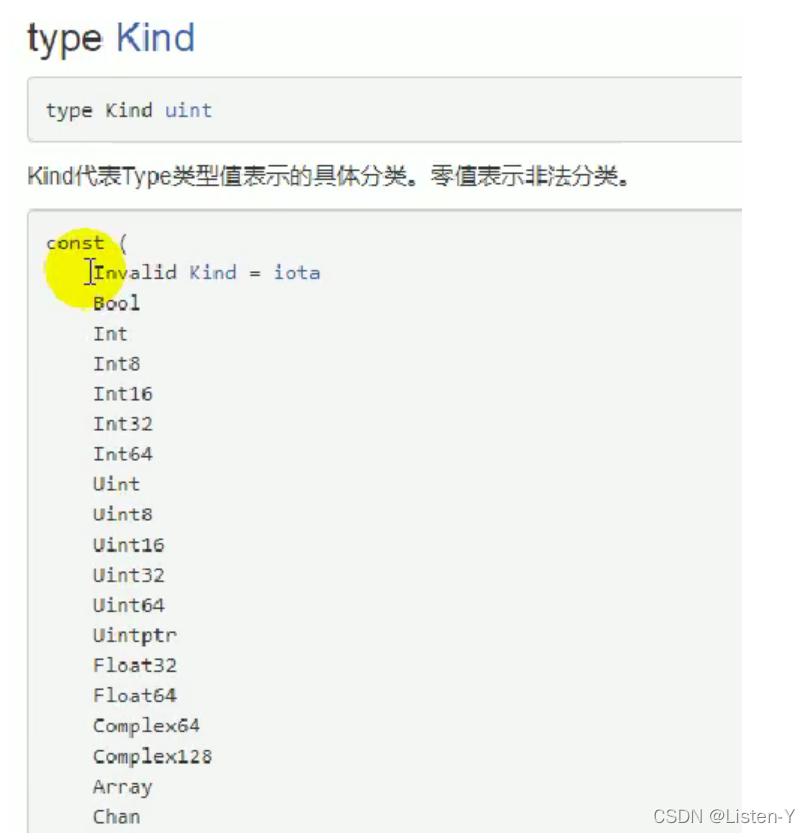
kind是类别,type是类型,type是具体的类型,kind是属于某一个类别
Type是类型,Kind是类别,Type和Kind可能是相同的,也可能是不同的.比如: var num int = 10 num的Type是int , Kind也是int
比如: var stu Student stu的Type是包名.Student , Kind是struct
kind本事是一个常量
16.5 代码实操
16.5.1 反射获得数据并计算修改
请编写一个案例,演示对(基本数据类型、interfacef}、reflect.Value)进行反射的基本操作
func main() {// 通过反射计算和修改数据num := 10valueOf := reflect.ValueOf(num)// 计算数据i := valueOf.Int()fmt.Println( i+ 10) // 20// 修改原数据, 注意这里传递的是地址valueOf = reflect.ValueOf(&num)// elem用于获取指针指向的变量valueOf.Elem().SetInt(20)fmt.Println(num) // 20
}
-
注意这里使用valueOf.Int() 要确保之前的数据也是int才可以,不然会发生panic, 最稳妥的做法就是先转换成空接口interface{} 然后断言成具体的类型
必须清楚是什么类型,不然会报panic, 如果是结构体,得进行断言 -
通过反射的来修改变量,注意当使用Setxxx方法来设置, 需要通过对应的指针类型来完成,这样才能改变传入的变量的值,同时需要使用到reflect.Value.Elem()方法
-
.elem用于获取指针指向的变量
16.5.2 再次练习数据获取和修改
给你一个变量var v float64 = 1.2,请使用反射来得到它的reflect.Value,然后获取对应的Type,Kind和值, ,并将reflect.Value转换成interface,再将interface转换成float64, 最后修改为2.4, 输出v显示2.4
func main() {var v float64 = 1.2valueOf := reflect.ValueOf(v)fmt.Println(valueOf.Kind())fmt.Println(valueOf.Type())i := valueOf.Interface()f := i.(float64)fmt.Println(f == v)of := reflect.ValueOf(&v)of.Elem().SetFloat(2.4)fmt.Println(v)
}
float64
float64
true
2.4
16.6 反射处理结构体
主要的几个方法使用 :
method, 默认按方法名排序对应i值i从0并始, 方法排序按照函数名字排序,比较函数名字的的字母的ascll码

方法执行调用, in为传入的参数,返回值和参数都是切片, 而且是value类型的切片

获得结构体字段, 和获得方法类似

反射的struct tag 的核心代码:
tag := tye.Elem().Field(0).Tag.Get(" json"")
16.6.1 反射遍历结构体字段和方法、获取标签值
type Monster struct {Name string `myJson:"monster_name"`Age int `myJson:"monster_age"`Score float32Sex string
}func (s Monster)Print() {fmt.Println(" ---start----")fmt.Println(s)fmt.Println( "---end----")
}func (s Monster)GetSum(n1,n2 int) int {return n1 + n2
}func (s Monster)Set(name string, age int,score float32, sex string) {s.Name = names.Age = ages.Score = scores.Sex = sex
}func testStruct(a interface{}) reflect.Value {valueOf := reflect.ValueOf(a)kind := valueOf.Kind()// 判断是否为结构体if kind != reflect.Struct {log.Fatal("not a struct")}return valueOf
}func main() {monster := Monster{Name: "jack",Age: 21,Score: 100,Sex: "man",}valueOf := testStruct(monster)typeOf := reflect.TypeOf(monster)// 获得结构体字段数目numField := valueOf.NumField()fmt.Println("Monster has ", numField, " fields")// 获得所有结构体字段,并遍历for i := 0; i < numField; i++ {fieldValue := valueOf.Field(i)fieldType := typeOf.Field(i)fmt.Println("Field ", i, " type is ", fieldType)fmt.Println("Field ", i, " value is ", fieldValue)// 获得tag数据get := typeOf.Field(i).Tag.Get("myJson")if get != "" {fmt.Println("Field ", i, " myJson is ", get)}}fmt.Println("====================================")// 获得方法数据, 如果方法是小写的,这里是统计不到的numMethod := valueOf.NumMethod()fmt.Println("Monster has ", numMethod, " methods")// 遍历方法for i := 0; i < numMethod; i++ {method := typeOf.Method(i)fmt.Println("Method ", i, " type is ", method)}fmt.Println("====================================")// 执行第一个方法 Print, Print方法没有参数,所以传nilvalueOf.Method(1).Call(nil)// 调用执行有参数的方法 GetSumparams := make([]reflect.Value, 0)params = append(params, reflect.ValueOf(10))params = append(params, reflect.ValueOf(20))retValues := valueOf.Method(0).Call(params) // 传入和传出的参数都是value切片fmt.Println(retValues[0].Int())
}
Monster has 4 fields
Field 0 type is {Name string myJson:"monster_name" 0 [0] false}
Field 0 value is jack
Field 0 myJson is monster_name
Field 1 type is {Age int myJson:"monster_age" 16 [1] false}
Field 1 value is 21
Field 1 myJson is monster_age
Field 2 type is {Score float32 24 [2] false}
Field 2 value is 100
Field 3 type is {Sex string 32 [3] false}
Field 3 value is man
====================================
Monster has 3 methods
Method 0 type is {GetSum func(main.Monster, int, int) int <func(main.Monster, int, int) int Value> 0}
Method 1 type is {Print func(main.Monster) <func(main.Monster) Value> 1}
Method 2 type is {Set func(main.Monster, string, int, float32, string) <func(main.Monster, string, int, float32, string) Value> 2}
====================================---start----
{jack 21 100 man}
---end----
3016.6.2 反射修改结构体字段
type User struct {Name stringAge intId int
}func main() {user := User{Name: "",Age: 0,Id: 0,}// 获取*user的valuevalueOf := reflect.ValueOf(&user)// 获取 *user的一个新的指针elem := valueOf.Elem()elem.FieldByName("Name").SetString("listen")elem.FieldByName("Age").SetInt(20)elem.FieldByName("Id").SetInt(1001)fmt.Println(user)
}
16.6.2 反射创建新结构体
type User struct {Name stringAge intId int
}func main() {user := User{Name: "",Age: 0,Id: 0,}typeOf := reflect.TypeOf(user)// 这里返回的是一个newUser 的指针newUser := reflect.New(typeOf)// 获取newUser 的一个指针elem := newUser.Elem()elem.FieldByName("Name").SetString("listen")elem.FieldByName("Age").SetInt(20)elem.FieldByName("Id").SetInt(1001)u := newUser.Interface().(*User)fmt.Println(u)
}
十七 网络编程
网络编程有三种:
1)TCP socket编程,是网络编程的主流。之所以叫Tcp socket编程,是因为底层是基于Tcp/ip协议的.比如:QQ聊天
2) b/s结构的http编程,我们使用浏览器去访问服务器时,使用的就是http协议,而http底层依旧是用tcp socket实现的。比如:京东商城【这属于go web开发范畴】
3)RPC服务编程,这种方式属于微服务区域的远程方法调用,但是在Go中有集成
17.1 网络基础知识了解
- 网线,网卡,无线网卡
计算机间要相互通讯,必须要求网线,网卡,或者是无线网卡.

- 协议(tcp/ip)
TCP/IP ( Transmission Control Protocol/Internet Protocol)的简写,中文译名为传输控制协议/因特网互联协议,又叫网络通讯协议,这个协议是Internet最基本的协议、Internet国际互联网络的基础,简单地说,就是由网络层的IP协议和传输层的TCP协议组成的。

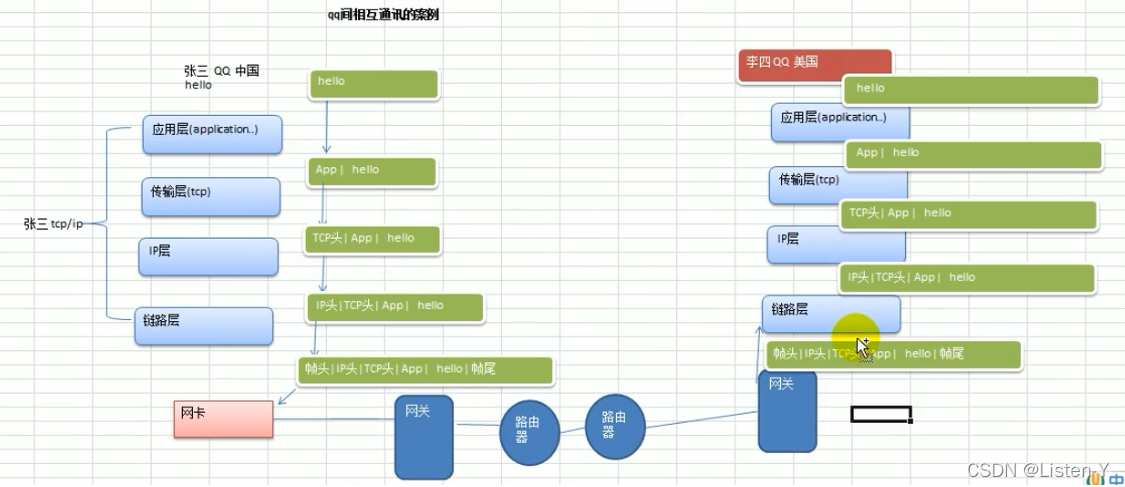
- 比如qq的交流
-
ip地址
概述:每个inter net业的主机和路由器都有一个ip地址,它包括网络号和主机号,ip地址有ipv4(32位)或者ipv6(128位).可以通过ipconfig 来查看 -
端口号
我们这里所指的端口不是指物理意义上的端口,而是特指TCP/IP协议中的端口,是逻辑意义上的端口。
如果把IP地址比作一间房子,端口就是出入这间房子的门。真正的房子只有几个门,但是一个IP地址的端口可以有65536(即:256×256)个之多!端口是通过端口号来标记的,端口号只有整数,范围是从o到65535 (256×256-1)
端口(port)-分类
0号是保留端口.
1-1024是固定端口
又叫有名端口,即被某些程序固定使用,一般程序员不使用 22:SSH远程登录协议 23: telnet使用 21:ftp使用 25: smtp服务使用 80: iis使用 7: echo服务
1025-65535是动态端口
这些端口,程序员可以使用.
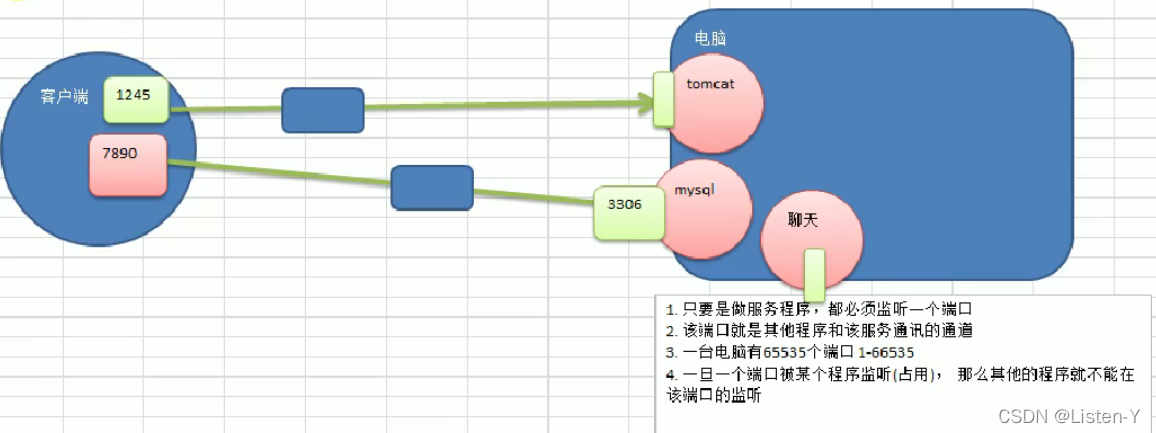
>端口(port)-使用注意
1)在计算机(尤其是做服务器)要尽可能的少开端口
2)一个端口只能被一个程序监听
3)如果使用netstat -an可以查看本机有哪些端口在监听
4)可以使用netstat -anb来查看监听端口的pid,在结合任务管理器关闭不安全的端口.
17.2 TCP服务编程
tcp socket编程会分为客户端和服务器端
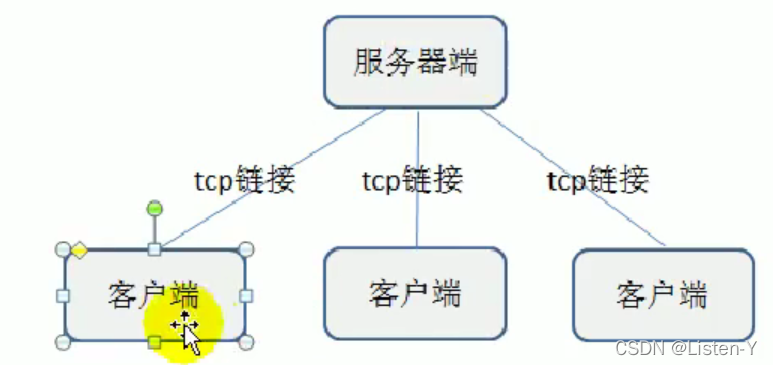
服务端的处理流程
1)监听端口
2)接收客户端的tcp链接,建立客户端和服务器端的链接.
3)创建goroutine,处理该链接的请求(通常客户端会通过链接发送请求包)
客户端的处理流程
1)建立与服务端的链接
2)发送请求数据,接收服务器端返回的结果数据
3)关闭链接
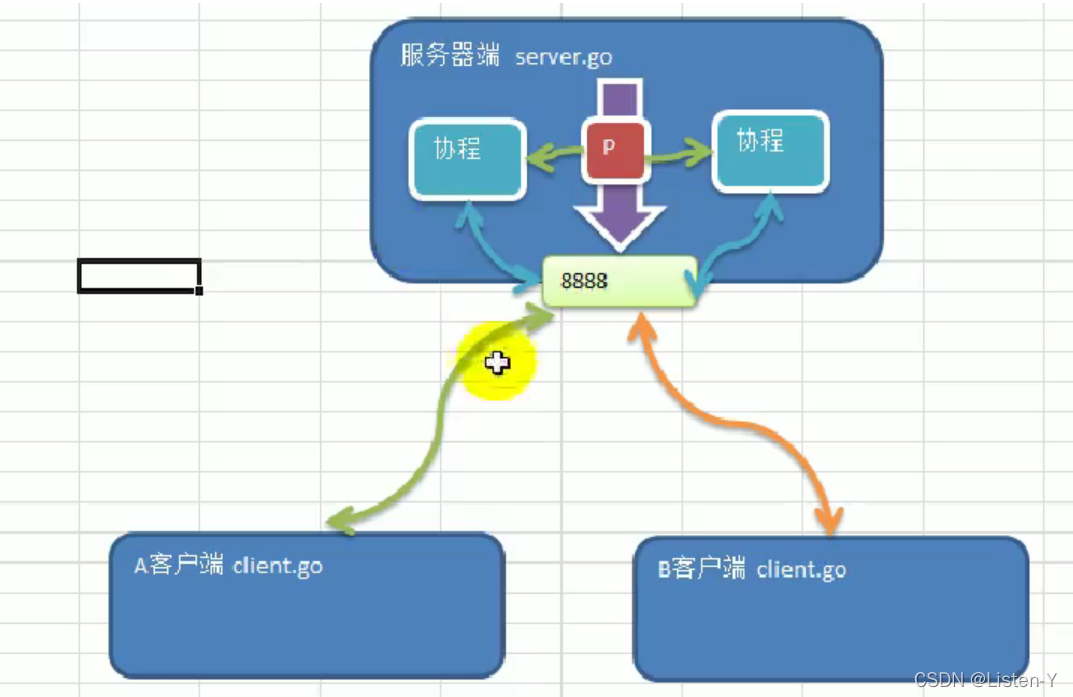
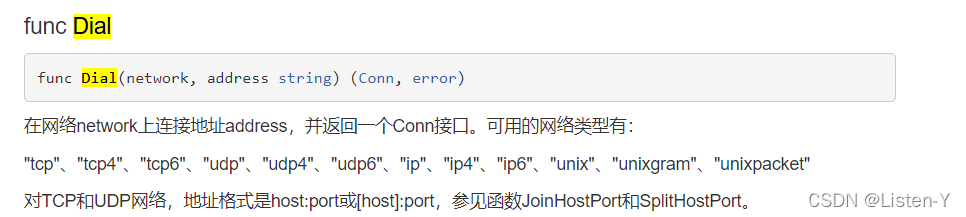
服务端主要使用API是官网里的

客户端主要使用官网API是
17.2.1 服务端代码
func main() {fmt.Println("服务器开始监听...")// net.Listen("tcp","o.0.0.0:8888")// 1. tcp表示使用网络协议是tcp// 2. 0.0.0.0.0:8888 表示在本地监听8888端口listen, err := net.Listen( "tcp", "0.0.0.0:8888")if err != nil {fmt.Println("listen error")return}defer listen.Close() // 必须关闭// 循坏等待客户端来连接for true {fmt.Println("等待客户端连接...")accept, err := listen.Accept()if err != nil {fmt.Println("accept error: ", err)} else {//获取到连接进行逻辑处理fmt.Println("accept success: ", accept)//创建一个新的切片,用户读取客户端发送来的数据buf := make([ ]byte, 1024)//1.等待客户端通过conn发送信息//2.如果客户端没有write[发送],那么就会就阻塞在这里n , err := accept.Read(buf) //从连接中读取if err != nil {fmt.Println("服务器的Read err=", err)}//3.显示客户端发送的内容到服务器的终端fmt.Println("接受到的数据为: ", string(buf[:n]))}}
}
17.2.2 客户端代码
func main() {fmt.Println("客户端建立...")dial, err := net.Dial("tcp", "0.0.0.0:8888")if err != nil {fmt.Println("客户端请求连接失败", err)return}//功能一:客户端可以发送单行数据,然后就退出, 在这里获得输入的数据reader := bufio.NewReader(os.Stdin) //os.stdin代表标准输入[终端]//从终端读取一行用户输入,并准备发送给服务器line, err := reader.ReadString('\n') // 以换行为输入的结尾if err != nil {fmt.Println( "ReadString err=", err)}//再将line发送给服务器n, err := dial.Write([]byte(line))if err != nil {fmt.Println( "conn write err=",err)}fmt.Printf("客户端发送了%d字节的数据,并退出",n)
}
17.3 RPC服务编程
远程调用(RPC)是一种使用TCP/IP的进程间通信的客户端-服务器机制。通过这种机制实现远程的方法调用,以便于程序的解耦
17.3.1 共享接口
通过远程调用方法, 实际的识别该调用哪个,是通过服务端和客户端相同的方法 参数 返回值标识的,所以一定要有一个服务端和客户端都一样的接口, 客户端只需要得到接口的方法标识即可, 服务端需要实现接口的方法
package sharedRPC// 共享结构体
type MyFloats struct {A1, A2 float64
}// 共享接口
type MyInterface interface {Multiply(arguments *MyFloats, reply *float64) errorPower(arguments *MyFloats, reply *float64) error
}/*
sharedRPC包定义了一个名为MyInterface的接口和一个名为MyFloats 的结构,
客户端和服务器都将会使用到。
只有RPC服务器需要实现这个接口。
*/- 注意项目结构,客户端和服务端都需要这个接口
17.3.2 客户端代码
package mainimport ("./sharedRPC""fmt""net/rpc"
)func main() {//注意,尽管RPC服务器使用TCP,但使用rpc.Dial()函数代替net.Dial()连接RPC服务器。c, err := rpc.Dial("tcp", "0.0.0.0:8888")if err != nil {fmt.Println(err)return}args := sharedRPC.MyFloats{A1: 16,A2: -0.5,}//RPC客户端和RPC服务器之间通过call()函数交换函数名,参数和函数返回结果,//而RPC客户端对函数的具体实现一无所知。var reply float64err = c.Call("MyInterface.Multiply", args, &reply)if err != nil {fmt.Println(err)return}fmt.Printf("Reply (Multiply): %f\n", reply)err = c.Call("MyInterface.Power", args, &reply)if err != nil {fmt.Println(err)return}fmt.Printf("Reply (Power): %f\n", reply)
}17.3.3 服务端代码
package mainimport ("./sharedRPC""fmt""math""net""net/rpc"
)// 服务端需要实现MyInterface 接口
type MyInterface struct {}func (t *MyInterface) Multiply(arguments *sharedRPC.MyFloats,reply *float64) error {*reply = arguments.A1 * arguments.A2return nil
}
func (t *MyInterface) Power(arguments *sharedRPC.MyFloats,reply *float64) error {*reply = Power(arguments.A1, arguments.A2)return nil
}func Power(x, y float64) float64 {return math.Pow(x, y)
}func main() {myInterface := new(MyInterface)/*rpc.Register()函数的调用使这个程序成为RPC服务器。但是,由于RPC服务器使用TCP协议,它仍需要调用net.ResolveTCPAddr()和net.ListenTCP()。*/err := rpc.Register(myInterface)if err != nil {fmt.Println("register error", err)return}t, err := net.ResolveTCPAddr("tcp4", "0.0.0.0:8888")if err != nil {fmt.Println(err)return}l, err := net.ListenTCP("tcp4", t)if err != nil {fmt.Println(err)return}for {c, err := l.Accept()if err != nil {continue}/*RemoteAddr()函数返回接入的RPC客户端IP地址和端口。rpc.ServerConn()函数为RPC客户端提供服务。*/fmt.Printf("%s\n", c.RemoteAddr())rpc.ServeConn(c)}
}- 先执行服务端,在执行客户端
Reply (Multiply): -8.000000
Reply (Power): 0.250000
调用成功
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!