Hadoop 经典案例:词频统计
全文作为个人记录用。不做任何参考。
环境搭建参考:http://www.ityouknow.com/hadoop/2017/07/24/hadoop-cluster-setup.html
词频代码参考:https://blog.csdn.net/a60782885/article/details/713082561、环境搭建
总共选择了3台虚拟机作为本次的主角
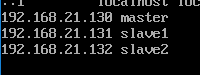
master:192.168.21.130 slave1:192.168.21.131 slave2:192.168.21.1321.1、首先是虚拟机的安装,物理主机是win10,虚拟机用的是Centos7,采用最小化方式安装,安装完后,有可能需要激活网卡,修改/etc/sysonfig/network-scripts/ifcfg-xxxx(我的是ifcfg-ens33),将ONBOOT=no修改为yes,使得能够联网。如下所示:

1.2、依次安装完3台虚拟机后,再修改主机的名字,依次为 master、slave1、slave2。修改文件/etc/sysconfig/network,在master机器中加入:HOSTNAME=master,其他机器中依次加入 HOSTNAME=slave1,HOSTNAME=slave2.
1.3、修改三台机器的hosts 加入下面这段话(具体ip视自己的机子而定):
1.4、软件的安装,首先是jdk的安装。
http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jdk-8u161-linux-x64.tar.gz wget http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jdk-8u161-linux-x64.tar.gz tar -zxvf jdk-8u161-linux-x64.tar.gz mv jdk-8u151-linux-x64 jdk180161 修改环境变量: export JAVA_HOME=/root/jdk180161export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar source /etc/profile
1.5、免密登陆
免密登陆的思想:
A机器能够免密登陆B机器。
首先在A机器上生成密钥:
ssh-keygen -t rsa
然后将密钥拷贝到B机器的authorized_keys中,就可以了。
这里以master远程免密登陆slave1为例。
①、登陆master,执行 ssh-keygen -t rsa ,可以一路回车。
②、登陆slave1,执行 scp root@master:~/.ssh/id_rsa.pub /root/
③、在slave1上,执行 cat /root/id_rsa.pub >> ~/.ssh/authorized_keys。
(如果失败,执行一下 chmod 600 .ssh/authorized_keys)
④、在master上测试 ssh slave1,能够登陆则成功。
然后依次配置三台机器之间的免密登陆和本机的免密登陆(例如在master 中执行 ssh master,可以登陆)
1.6 Hadoop配置
依次在3台机器上执行。 wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz tar -zxvf hadoop-2.7.5.tar.gz 修改环境变量: export HADOOP_HOME=/root/hadoop-2.7.5export PATH=$PATH:$HADOOP_HOME/bin
依次修改 hadoop的配置文件,在hadoop的安装目录下的/etc/hadoop中。
一共有4个文件修改: ①、 core-site.xml添加 master 在master主机(master特有) vi /root/hadoop-2.7.5/etc/hadoop/slaves
## 添加
slave1
slave2
1.7 Hadoop启动
1.7.1 格式化HDFS文件系统
bin/hadoop namenode -format(hadoop目录下执行)
1.7.2 启动hadoop
sbin/start-all.sh
1.8、可能出现的问题
JAVA_HOME is not set and could not be foundvi /root/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
## 配置项
export JAVA_HOME=你的jdk路径
1.9、词频程序
程序很简单。一步带过。 maven建立quick-start工程。 pom.xml4.0.0 cn.edu.bupt.wcy wordcount 0.0.1-SNAPSHOT jar wordcount http://maven.apache.org UTF-8 junit junit 3.8.1 test org.apache.hadoop hadoop-common 2.7.1 org.apache.hadoop hadoop-hdfs 2.7.1 org.apache.hadoop hadoop-client 2.7.1 package cn.edu.bupt.wcy.wordcount;import java.io.IOException;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class WordCountMapper extends Mapper{@Overrideprotected void map(LongWritable key, Text value, Mapper.Context context)throws IOException, InterruptedException {// TODO Auto-generated method stub//super.map(key, value, context);//String[] words = StringUtils.split(value.toString());String[] words = StringUtils.split(value.toString(), " ");for(String word:words){context.write(new Text(word), new LongWritable(1));}}}
reducer:
package cn.edu.bupt.wcy.wordcount;import java.io.IOException;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class WordCountReducer extends Reducer {@Overrideprotected void reduce(Text arg0, Iterable arg1,Reducer.Context context) throws IOException, InterruptedException {// TODO Auto-generated method stub//super.reduce(arg0, arg1, arg2);int sum=0;for(LongWritable num:arg1){sum += num.get();}context.write(arg0,new LongWritable(sum));}
}
runner:
package cn.edu.bupt.wcy.wordcount;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;public class WordCountRunner {public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration(); Job job = new Job(conf); job.setJarByClass(WordCountRunner.class); job.setJobName("wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[1])); FileOutputFormat.setOutputPath(job, new Path(args[2])); job.waitForCompletion(true); }}
打包成jar包后,放到集群上运行。 先在集群上新建一个文件夹: hdfs dfs -mkdir /input_wordcount 再放入单词文件,比如: hello world I like playing basketball hello java 。。。 运行hadoop jar WordCount.jar(jar包) WordCountRunner(主类) /input_wordcount /output_wordcount 运行完成后,查看: hdfs dfs -ls /output_wordcount。已经生成了结果,在cat一下查看内容即可。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!