smallRedBook销售额预测python实战
smallRedBook销售表的主要字段:
revenue:用户的下单购买金额
gender:性别。1为男,0为女,空缺为未知
age:年龄,空缺为未知
engaged_last_30:是否最近30天在app上有参与活动(eg;讨论,买家秀)
lifecycle:用户生命周期。A、B、C分别代表用户注册6个月内,1年内,2年内
days_since_last_order:最近一次下单距今的天数。小于1则代表当天有下单。
previous_order_amount:用户以往累积的总购买金额
3rd_party_stores:用户过往在app中从第三方商家购买的次数。0代表只在自营店中购买。
要分析的问题:
对于smallRedBook销售表进行数据预处理和数据描述性统计分析(数据概括,单变量分析,多变量分析),然后进行相关性分析,建立revenue的回归预测模型,进行模型评估和优化。
开始敲Python。
首先导入相关的库和数据表,对于数据进行初步了解和预处理。
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
from sklearn.linear_model import LinearRegression
#解决中文和编码不正常显示的问题
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=Falsedf=pd.read_csv(r'small_red_book.csv')
df.info()
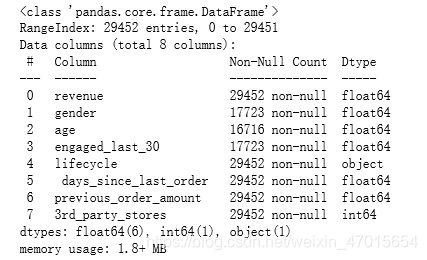
df.isnull().sum()
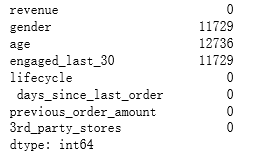
运行可知,gender,age,engaged_last_30存在缺失值
这里用unknown填充gender和engaged_last_30,用均值填充age
df['age']=df['age'].fillna(df.age.mean())
df['gender']=df['gender'].fillna('unknown')
df['engaged_last_30']=df['engaged_last_30'].fillna('unknown')df.info()

缺失值处理完成,数据预处理完成。接下来对于处理后的数据进行描述性统计分析
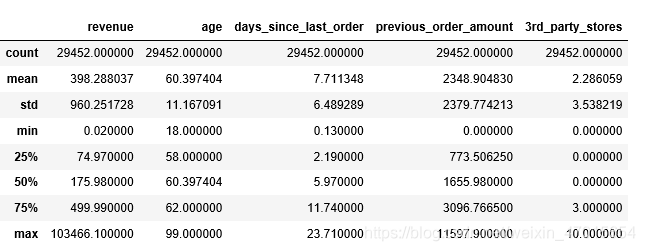
#数据描述统计
df.describe()
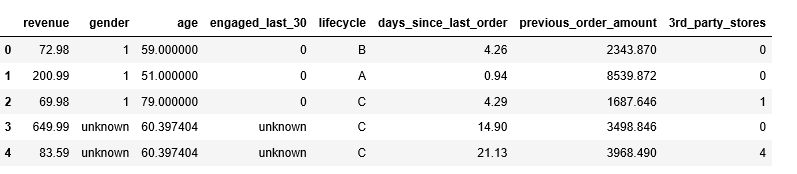
#查看前5行数据
df.head()
然后进行单变量分析,实现可视化。
#查看revenue的分布情况
plt.title('总体销售额分布')
sns.distplot(df['revenue'])
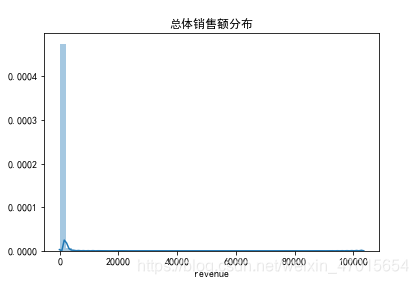
易知,大部分revenue集中在0-2000的区间
#查看0-2000区间内的revenue分布情况
plt.title('小于2000的销售额分布')
df1=df[df['revenue']<2000]
sns.distplot(df1['revenue'本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!