NIR-to-VIS face recognition via embedding relations and coordinates of the pairwise features阅读笔记
2019 IEEE
MyeongAh Cho; Tae-young Chung; Taeoh Kim; Sangyoun Lee
一、简介
从人脸图像中提取的局部特征包含人脸各个组成部分的信息。对于两个不同的域特征,使用局部特征之间的关系比直接使用它更具有域不变性。除了这些关系,位置信息,如从嘴唇到下巴或眼睛到眼睛的距离,也提供了域不变的信息。
提出了一个关系模块,用来减少模态差异。该模块由关系层和坐标层组成,关系层隐式捕获关系,坐标层对位置信息进行建模。
提出了考虑类内分布的带条件边际的三重损失。
二、模型

特征提取(ConvNet):
输入一张人脸图像(VIS人脸图像或NIR人脸图像),使用LightCNN网络提取特征,提取出的特征图是关系模块的输入。
LightCNN网络在MS-Celebe-1M数据集上预先训练。
该网络的输出是N×N的特征图(N=8)。这些N×N个数的特征向量代表了人脸的局部斑块,如嘴唇、眼睛和鼻子,它们是人脸的重要特征。
关系层:
将N×N个特征向量进行所有成对拼接组合,一共由N×N×N个组合特征。通过该成对组合方式,获得了人脸的位置关系。
然后将这些成对的组合通过一个参数共享的全连通层,嵌入到L维的关系向量中。
该过程提取了诸如形状、大小等人脸的代表性关系。
Coordinates Layer(坐标层):
人脸各部分的位置是人脸分类时的重要信息。面部部分的相对距离,例如从嘴唇到下巴或眼睛到眼睛的距离,是身份的代表性特征。由于这一信息不依赖于领域,它可以有效地用于近红外-可见光人脸识别任务。
简单地添加两个额外的通道,表示两个空间维度。
第一个通道的第一行用0填充,第二行用1填充,以此类推。第二个通道的填充也与第一个通道相似,但列是常数值,并按比例缩放为[-1,1]。
三、损失函数
使用softmax loss和triple loss训练。
Softmax Loss:

通过L2归一化对嵌入特征进行归一化,然后对归一化特征进行s比例缩放。
Triplet Loss:

a是随机选择的输入图像的人脸图像。
p是与a同一身份且不同域下的人脸图像。
n是与a不同身份且不同域下的人脸图像。
CS是余弦相似性。
m是条件余量,取0.7。
整体损失:
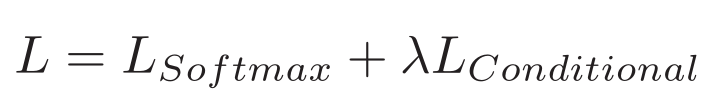
四、实验
CASIA NIR-VIS 2.0:

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!