scrapy 简单爬取58,百度,汽车之家
scrapy 简介:
1.创建项目(项目名字不能包含中文,开头不能是数字)
创建一个项目文件夹,cmd 进入该文件夹下 输入:
scrapy startproject scrapy_58 创建好了的项目目录结构
2.创建爬虫文件
在 spiders 文件夹中创建爬虫文件进入 spiders 文件目录创建爬虫文件scrapy genspider 爬虫文件的名字 域名例如: scrapy genspider baidu www.baidu.com3.运行爬虫
scrapy crawl 爬虫的名字例如:scrapy crawl baidu百度会有一个 robots 协议,不让爬,修改 settings.py 中 :ROBOTSTXT_OBEY = False4. scrapy 项目结构
项目名字spiders 文件夹(存储的是爬虫文件)initinititems 定义数据结构的地方,爬取数据都包含哪些middleware 中间件 代理pipelines 管道 用来处理下载的数据settings 配置文件 robots协议 UA定义5.工作原理
spiders 发送 url 给引擎,引擎 发给 调度器;调度器 发送请求给 引擎,引擎 发给 下载器;下载器 上互联网拿数据,下载器 把拿到的数据发给 引擎; (response)引擎 把数据发给 spiders, spiders 通过xpath解析数据;spiders 解析结果为数据发给 管道, 管道 获得解析成功的结果存储文件。spiders 解析结果为url发送给 引擎,引擎 发给 调度器;6. ipython
pip install ipython方便调试 scrapy xpath ,不用每次去运行 scrapy crawl baiduwin + r => cmd 输入: scrapy shell www.baidu.com例如:scrapy shell www.baidu.coma = response.xpath('//input[@id="su"]/@value)a.extract_first()爬取 58后端开发职位网页
获取请求的 url,这里的 url 在上面第二步创建爬虫的时候需要去掉 https:// 然后输入。

content 即为 网页源码,然后从里面提取需要的数据即可
获取汽车之家宝马名字和价格
按照前面的步骤创建好爬虫文件。
获取请求的 url
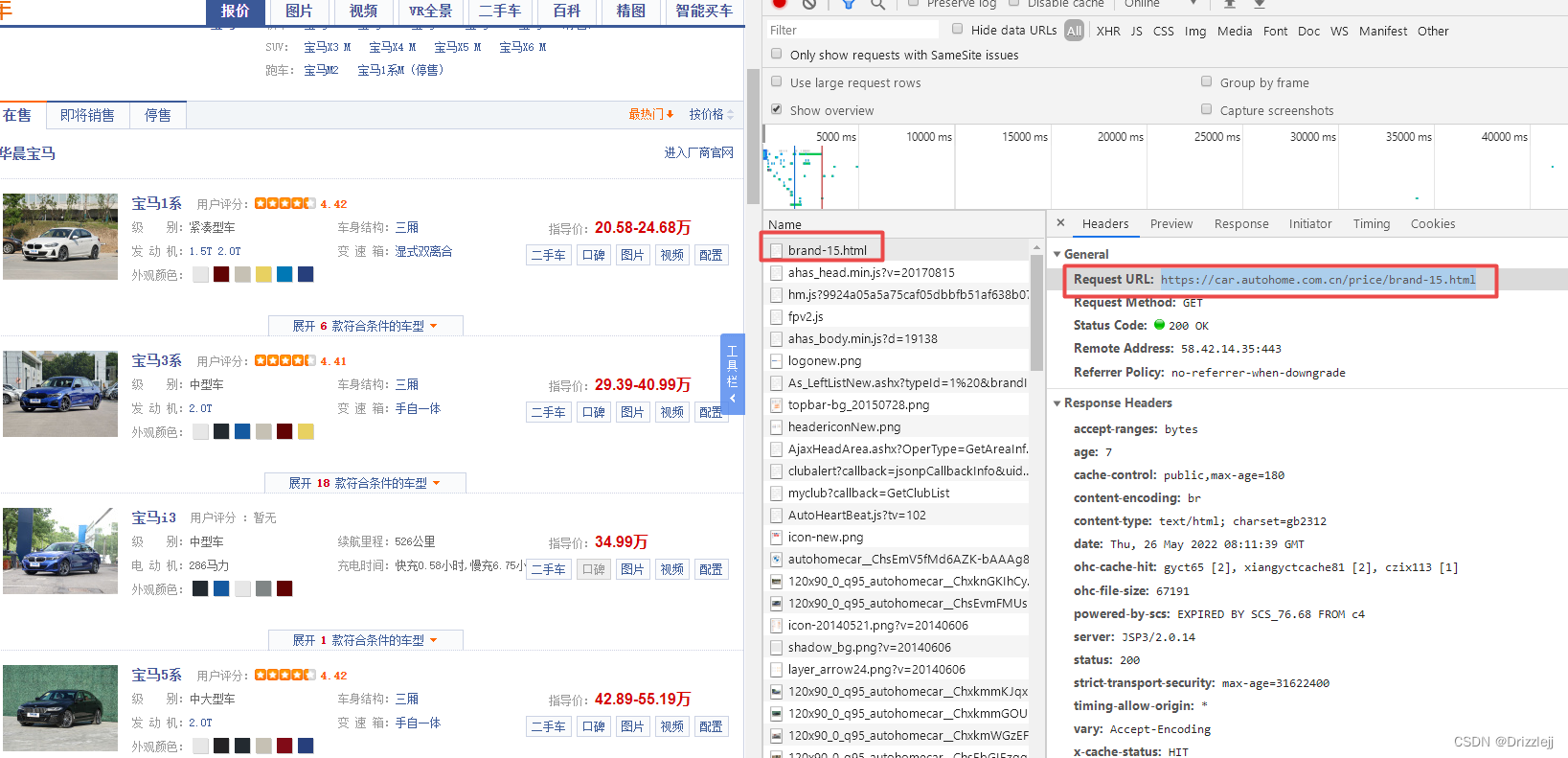

由于该项目过于简单,这里只在 carhome.py 中写入代码,其他文件未改动。
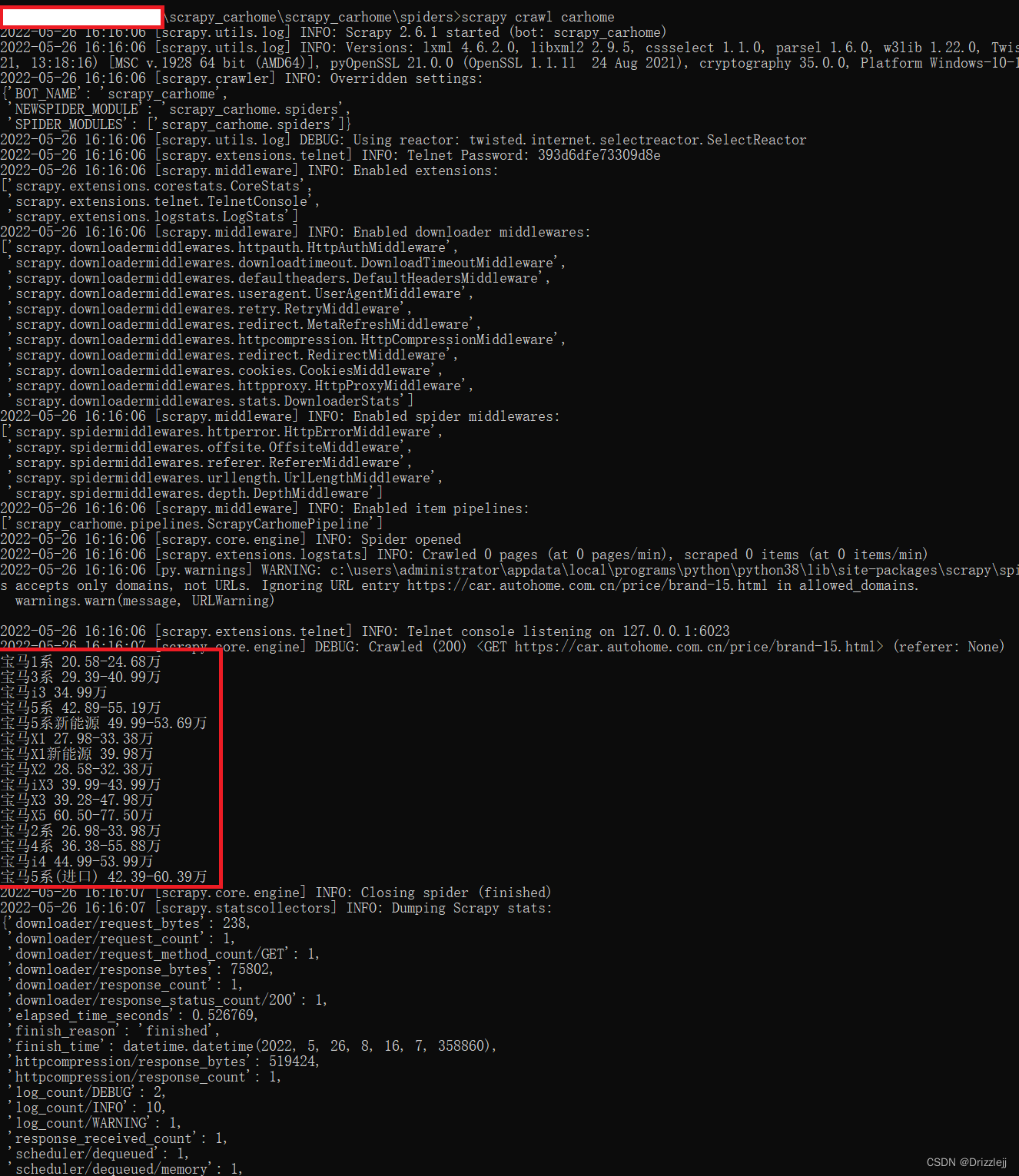
import scrapyclass CarhomeSpider(scrapy.Spider):name = 'carhome'allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html']# 请求接口 html 结尾的不需要在末尾加 /start_urls = ['https://car.autohome.com.cn/price/brand-15.html']def parse(self, response):carname_list = response.xpath('//div[@class="main-title"]/a/text()') # xpath 选择汽车名字carprice_list = response.xpath('//div[@class="main-lever"]//span/span/text()')for i in range(len(carname_list)):carname = carname_list[i].extract() #提取 seletor 对象的data属性值carprice = carprice_list[i].extract()print(carname,carprice)结果输出如下:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!