python的requests库和beautifusoup库爬取妹子图
一:python爬虫-利用requests库获取网页的信息
记录一下自己的爬虫过程吧
其实在爬之前我是想用jsonpath和json的,然后我发现打开美图吧这个网站后我只想到到了requests库和beautifulsoup库爬取的方法(狗头)
不多说,直接上代码:
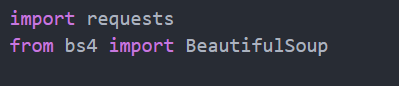
import requests
from bs4 import BeautifulSoupdef getHtml(url):cookie = {'UM_distinctid': '1727e776cfc7c6-0de60d097b0f15-c373667-144000-1727e776cfd9a6','CNZZDATA1256622196': '1626070704-1591255197-null%7C1591255197','Hm_lvt_1941ba27d34dec171a181ef89e310488': '1591259656','Hm_lpvt_1941ba27d34dec171a181ef89e310488': '1591260180',}header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}r = requests.get(url, headers=header, cookies=cookie)r.encoding = r.apparent_encodingreturn r.textdef getImage(html, result):soup = BeautifulSoup(html, 'html.parser')# 返回一个字典tergets = soup.find_all("img", {'style':"display: inline;"})for each in tergets:result.append(each['src'])return resultdef main():result = []num = 1 # 图片序号url = 'http://www.meituba.com/xinggan/list{}.html'# 要爬取几页depth = 5for i in range(81, 81+depth):u = url.format(i) html = getHtml(u)getImage(html, result)#print(result)for i in result:a = requests.get(i)with open(r'D:\pythonproject\自己的小项目或自己找的小项目\妹子图\{}.jpg'.format(num), 'wb') as f:f.write(a.content)num += 1if __name__ == '__main__':main()
使用到的第三方库:
PS:代码运行需要修改图片保存的地址,还需要自己的电脑上安装了相应的库
PS:小白第一次写文章,代码还比较垃圾,我也就想记录一下自己的爬虫,看着自己进步吧!一起加油哦,陌生人!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!