推翻Hinton NeurIPS论文结论!审稿人评价:该文章在标签平滑和知识蒸馏的关系上取得了重大突破!...

今天给大家介绍一篇 ICLR 2021 的文章,来自卡耐基梅隆大学,香港科技大学,北京大学和马萨诸塞大学阿默斯特分校(是 MEAL 系列作者的一篇最新力作)。

论文标题:
Is Label Smoothing Truly Incompatible with Knowledge Distillation: An Empirical Study
论文链接:
https://openreview.net/pdf?id=PObuuGVrGaZ
项目主页:
http://zhiqiangshen.com/projects/LS_and_KD/index.html
这是一篇非常特别的文章,其中一个审稿人评价这篇文章是标签平滑和知识蒸馏领域有突破性的一篇文章,并给出了 8 分的高分。为什么说它特殊呢,因为论文的核心并不是常见的刷点打榜的工作,而是在澄清和纠正过去一篇比较有名的文章中提出的一个重要发现,基于这个发现衍生出来的观点和在这个问题上的认知,进而让人们更好的理解标签平滑和知识蒸馏的工作原理,那篇被纠正的文章发表于 NeurIPS 2019 [1] ,作者之一是我们大家都非常熟悉的深度学习先驱之一的 Geoffrey Hinton。
大家应该很好奇,大佬的文章也会有不完善的观点吗?答案是肯定的。人们对于某些问题的认知本来就是在曲折中不断前进的。我们首先来介绍一下 Hinton 那篇文章在讲一个什么事情。
Hinton 这篇文章主要是在探究和解释标签平滑的机制和工作原理,下面这张图很好解释了这种机制:
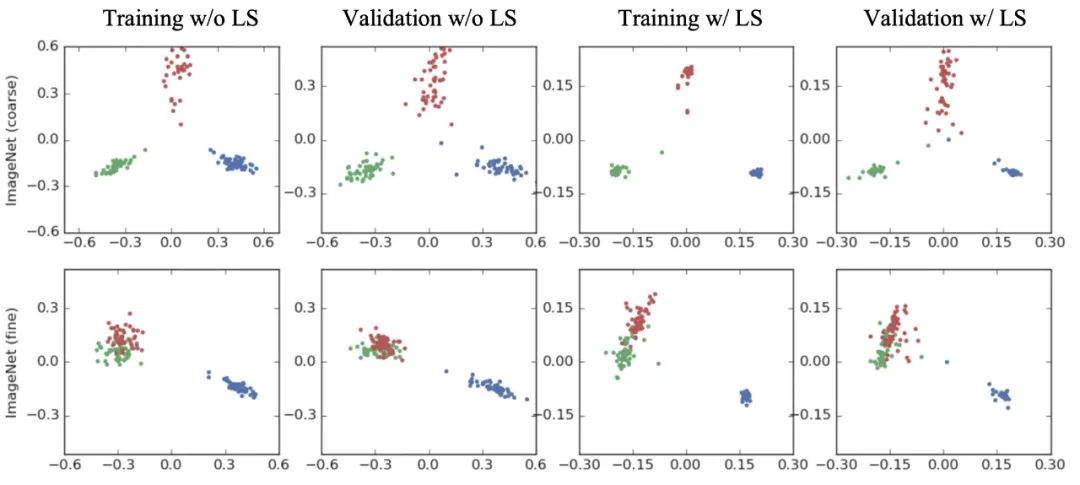
这篇文章里第一个有意思的发现是:Label smoothing encourages the activations of the penultimate layer to be close to the template of the correct class and equally distant to the templates of the incorrect classes.这是一个非常重要的发现,它的大意是在说标签平滑可以消除类内样本之间的差异,让学到的同一类别的特征表达更加紧凑。更具体来说,比如狗这个类别的图片通常会包含不同的姿态,拍照角度,曝光程度,不同背景等等,标签平滑可以很好的消除不同样本特征中这些差异的或者称为 noisy 的信息,而更多地保留它的高层语义信息,即狗这个类别信息。
基于标签平滑这个特点,作者进一步提出了一个观点,即:If a teacher network is trained with label smoothing, knowledge distillation into a student network is much less effective. 怎么解释这个结论呢?如上图最后一行所示,右侧某类样本在使用标签平滑之后会聚集在类中心点,因此不同样本到其他两种样本的距离信息会趋向于相同,即标签平滑抹去了同一类别不同样本到其他类别的距离的细微差别,作者认为这种现象对于知识蒸馏来说是有害的,因为蒸馏正是需要 teacher 能拥有这种捕捉同一类别不同样本之间细微差别的能力才会有效的,因此他们还认为: a teacher with better accuracy is not necessarily the one that distills better. 大概意思就是 teacher 性能好对于知识蒸馏来说并不重要。
上述推理听上去是不是非常合情合理,那么 ICLR 2021 这篇文章又在纠正一个什么事情呢?下面这张图很好的解释了它究竟在纠正什么:
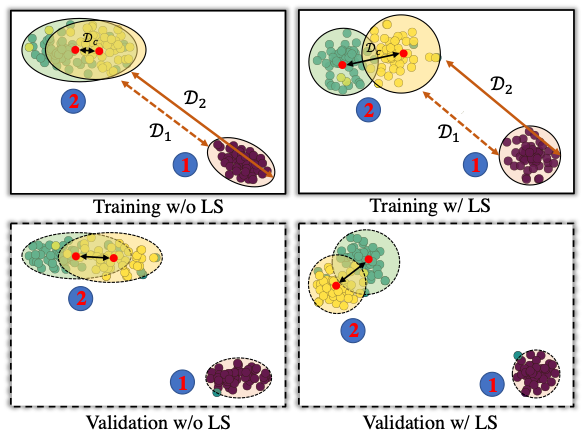
作者首先重现了 NeurIPS 2019 那篇文章中的可视化过程,并证明了上述论文中提到的现象是真实存在并可重现的,但是他们还有了一个新的惊人的发现:
如果我们重新来审视上图中两个语义相似的类别(左侧的两个靠近的类别),当使用标签平滑时,同一类别样本聚集会更加紧密,因为标签平滑会促使每个样本与该类中其他样本的类中心等距,而紧密的聚类会显著促进语义相似的不同类的表示变得更加可分离,即两个类中心距离 Dc 增大了,这进一步变现为语义相近但是不同类的样本获得更可区分的表达。
这种现象非常重要,因为这些相似类别是提高分类模型性能的关键。一般来说,我们没有必要去衡量“狗和鱼有多像或者有多不像”,因为我们有足够的线索和特征来区分它们(即右侧类样本到左侧类别的距离不重要),但对于细粒度的类别之间如不同种类的狗,如果能得到“toy poodle 与 miniature poodle 不同程度”的信息对于区分它们是非常关键的。
上述分析作者从原理上解释了为什么标签平滑和知识蒸馏并不冲突,为了更好地阐述两者关系,作者提出了一个能定量地衡量被抹去信息大小的指标,称之为 stability metric,它的数学表达如下:
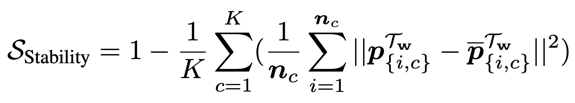
物理意义为:如果标签平滑会抹除类内的信息,类内样本的特征表达的差异也将相应减少,因此,我们可以使用这种差异来监测标签平滑抹除信息的程度,因为此指标也可以评估同一类别中不同样本特征表达波动程度,因此我们也称之为稳定性指标。
文章还有一个重要的观点是:
作者提出如果知识蒸馏不考虑使用原始数据集标签项,本质上标签平滑和知识蒸馏优化方式是一致的,唯一差别来自 soft 的监督信息来源方式不一样,知识蒸馏使用的是固定权重参数的 teacher 模型(一种动态的监督信息获取方式),标签平滑使用的是人为制定的平滑规则(固定不变的标签信息)。
总言而之,文章中作者试图去解答下面几个关键:
1. Does label smoothing in teacher networks suppress the effectiveness of knowledge distillation?
teacher 网络训练时候使用标签平滑是否会抑制知识蒸馏阶段的有效性?
2. What will actually determine the performance of a student in knowledge distillation?
哪些因素将真正决定 student 在知识蒸馏中的性能?
3. When will the label smoothing indeed lose its effectiveness for learning deep neural networks?
标签平滑在什么情况下真正失去有效性?
实验部分
作者在图像分类,二值化网络,机器翻译等任务上进行了大量的实验来验证他们的观点,并且完全抛弃了可能会带来误导的小数据集,比如 CIFAR。众所周知 CIFAR 上的实验结果和现象经常会跟 ImageNet 上的不一致,从而产生误导。
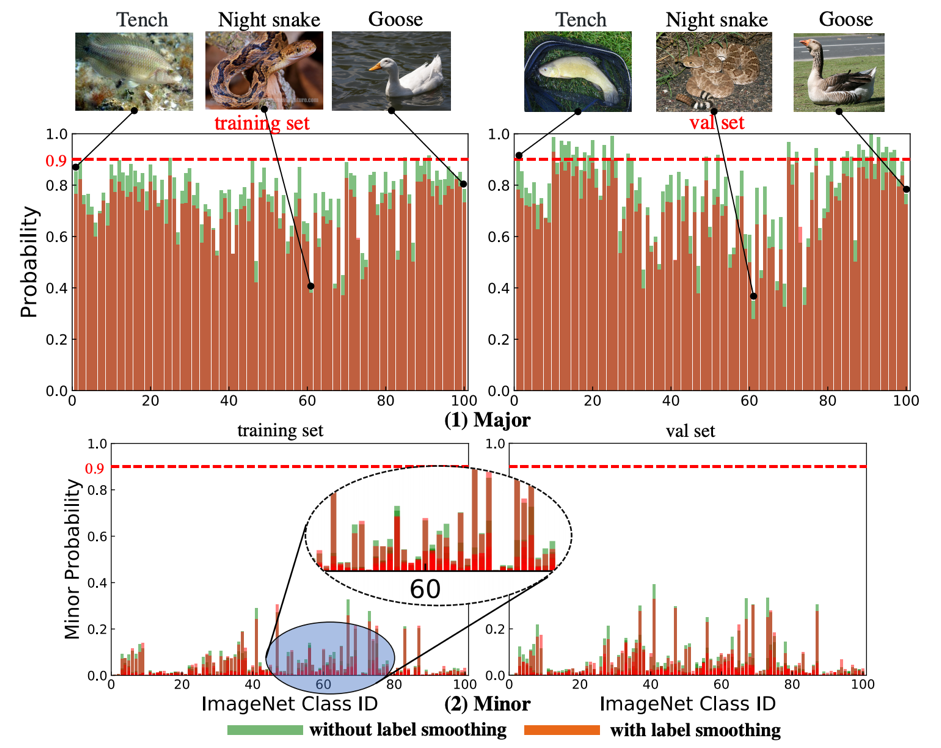
作者首先可视化了 teacher 产生的 soft 的监督信息的分布如下图所示,我们可以看到使用标签平滑训练 teacher 产生的监督信号整体上是低于不使用标签平滑,这跟标签平滑本身的工作机制是一致的。作者还展示了在一些次要类别上的信号分布(下图 2),这也是为什么 soft 标签可以提供更多细微的语义信息差别的原因。
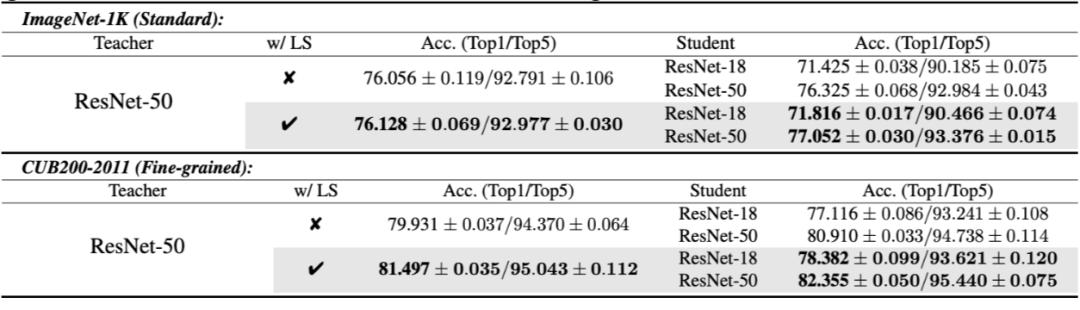
接下来是在图像分类任务上的结果,包括 ImageNet-1K 以及 CUB200-2011。我们可以看到,不管 teacher 有没有使用标签平滑训练,student 的性能基本是跟 teacher 的性能保持正相关的,即 teacher 性能越高,student 也越高。
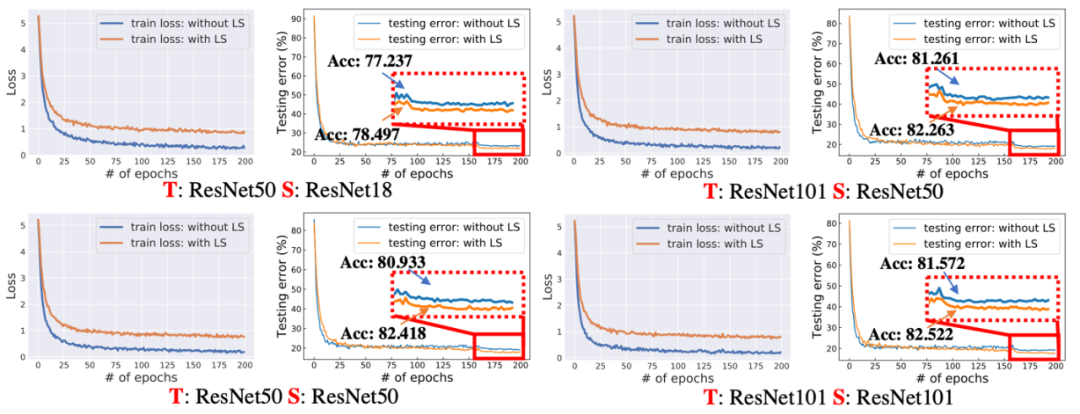
作者进一步可视化了知识蒸馏过程的 loss 曲线和测试误差曲线,如下图。作者发现如果 teacher 是使用标签平滑训练出来的,那么在知识蒸馏过程中产生的 loss 会比较大,如下图左侧,但是这个更大的 loss 值并不会影响 student 的性能,也就是说,标签平滑训练的 teacher 产生的抑制作用只会发生在训练数据集上,并不会延续到测试数据上,即 student 的泛化能力还是得到保证的。这也是一个非常有意思的发现,本质上,这种更大的 loss 是由于监督信号更加扁平(flattening)造成的,它具有一定的正则作用防止模型过拟合。
那么什么情况会真正导致标签平滑无效或者效果变弱呢?
作者发现在下列两种情况下标签平滑会失效或者没那么有效:1)数据集呈现长尾分布的时候(long-tailed);2)类别数目变多的时候。具体猜测原因可以去阅读原文。
最后回答一个大家最关心的问题:知识蒸馏到底需要怎么样的 teacher?
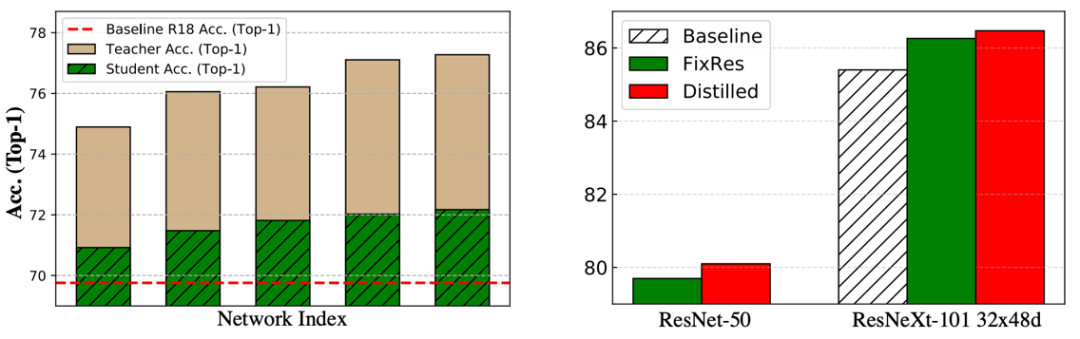
本质上,针对不同的场景和任务,需要的 teacher 类型也不尽相同,但大体上来说,精度越高的网络,通常可以蒸馏出更强的 student(如下图),当然 student 的性能也受其自身的结构容量限制,
更多细节大家可以去阅读原论文。
参考文献
[1] Müller, Rafael, Simon Kornblith, and Geoffrey Hinton. "When does label smoothing help?." In NeurIPS (2019).
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!