一步搞定模型训练和商品召回:京东全新索引联合训练召回模型

©PaperWeekly 原创 · 作者 | 张菡
单位 | 京东算法工程师
研究方向 | 信息检索

简介
基于深度学习的语义检索已经广泛应用于互联网应用中。早在 2018 年,京东搜索已经实现了语义检索 [1],通过深度语义模型,学习 query 和商品的向量表示,用于京东搜索的召回阶段,通过向量相似性查找实现语义检索。
大规模的向量相似性查找需要大量的浮点运算,精确 KNN(K-Nearest Neighbor)查找会带来超长的召回时延,可行解决方案是采用 ANN(Approximate Nearest Neighbor)查找,以少量的检索精度换取超高的召回效率。
常用的 ANN 索引方法包括 PQ(Product Quantization,乘积量化)、基于树的方法、基于图的方法和哈希。而基于 PQ 的方法由于内存消耗小,可以动态增删等优点在工业界应用较为广泛。在此之前,京东搜索的语义召回采用的就是基于 PQ 的 Faiss 索引库 [2]。
基于 PQ 索引主要思想是将高维向量用低维子空间的笛卡尔积表示,而后在低维子空间中进行聚类,用聚类中心构成的码本对向量进行编码,并提前计算好编码之间的码距,在检索时,就能通过查找直接得到向量之间的距离,从而大大减少浮点运算次数。由于模型的训练和索引的建立是两个独立的过程,所以子空间的划分和聚类中心的计算势必会带来一定的相似性计算误差。
因此,我们提出一种全新的索引联合训练模型(product quantization based embedding index jointly trained with deep retrieval model,简称 Poeem),对聚类中心进行参数化学习,减少子空间划分和聚类带来的损失,进一步提高向量检索的精度。此外,在实际应用中,联合训练模型不需要额外的建索引时间以及额外的索引服务,大大降低了向量检索在实际应用中的工程复杂度。

论文标题:
Joint Learning of Deep Retrieval Model and Product Quantization based Embedding Index
论文来源:
SIGIR 2021
论文链接:
https://arxiv.org/abs/2105.03933

模型
模型结构如下图所示:
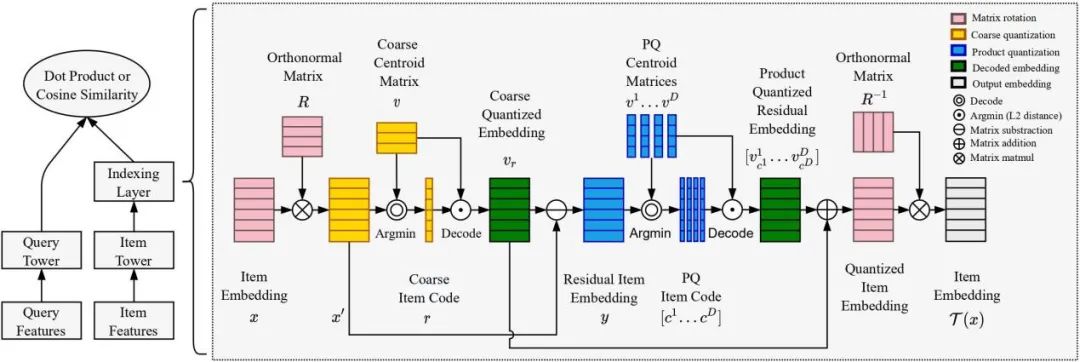
左边是一个经典的双塔召回模型,我们在 item tower 的最后嵌入一层索引层,用于实现 PQ 索引的学习,右边则是索引层向量量化的实现过程。向量量化主要分为四个步骤:
首先,我们对 item embedding 进行维度的 reordering,从而降低后续划分的子空间之间的相关性。矩阵维度的 reordering 可以通过乘上一个旋转矩阵(Rotation Matrix)来实现。(对应上图中粉色标注过程)
第二步,我们学习一个粗粒度的聚类中心矩阵 v,用 item embedding 在 v 中做相似度查找,得到 item embedding 的粗粒度量化编码 r。(对应上图中黄色标注过程)
第三步,我们首先用 item embedding 减去对应的粗粒度聚类中心,得到 residual item embedding,用于后续的向量量化。然后将 residual item embedding 均匀划分成 subvectors,同时学习每个子空间的聚类中心矩阵 ,然后用 subvector 减去对应子空间的聚类中心,得到 subvector 残差,再在聚类中心矩阵 做相似度查找,得到 item embedding 的乘积量化编码 c。
最后,我们来做向量复原。首先加上粗粒度聚类中心,将残差恢复成原向量;然后乘上旋转矩阵的逆矩阵,恢复原本向量维度的顺序。

实验
a) 对比实验
我们在三个数据集上做了对比实验,分别是京东的搜索数据集 Private Dataset,开源数据集 MovieLens [3]和 Amazon Books [4]。评测指标包括p@100(precision@100)和 r @100(recall@100)。
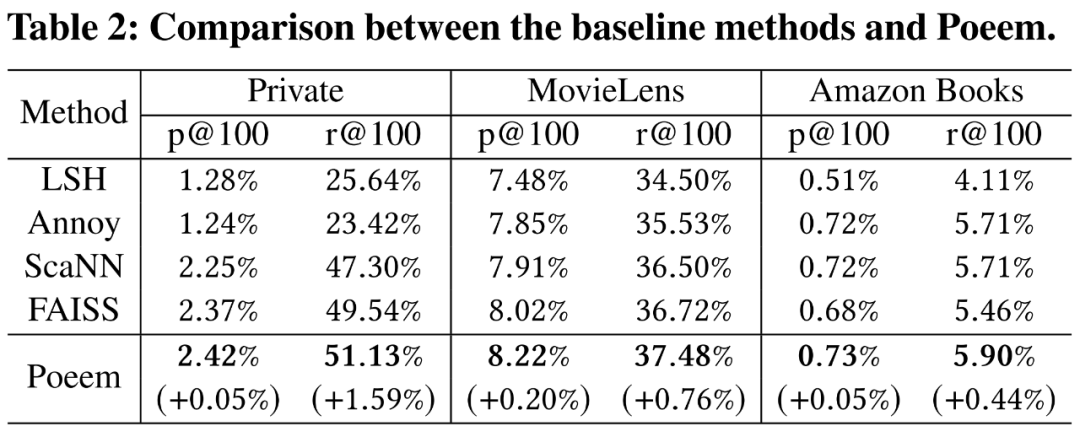
对比实验结果表明,Poeem 在召回率上有最好的表现,在三个数据集上分别有 +1.59%,+0.76%,0.44% 的提升。说明这种参数化的 PQ 学习,能够有效减少向量量化的损失。
b) 可视化表示:
此外,我们从 Private Dataset 中抽取了几个类目的商品进行 t-SNE 可视化表示:
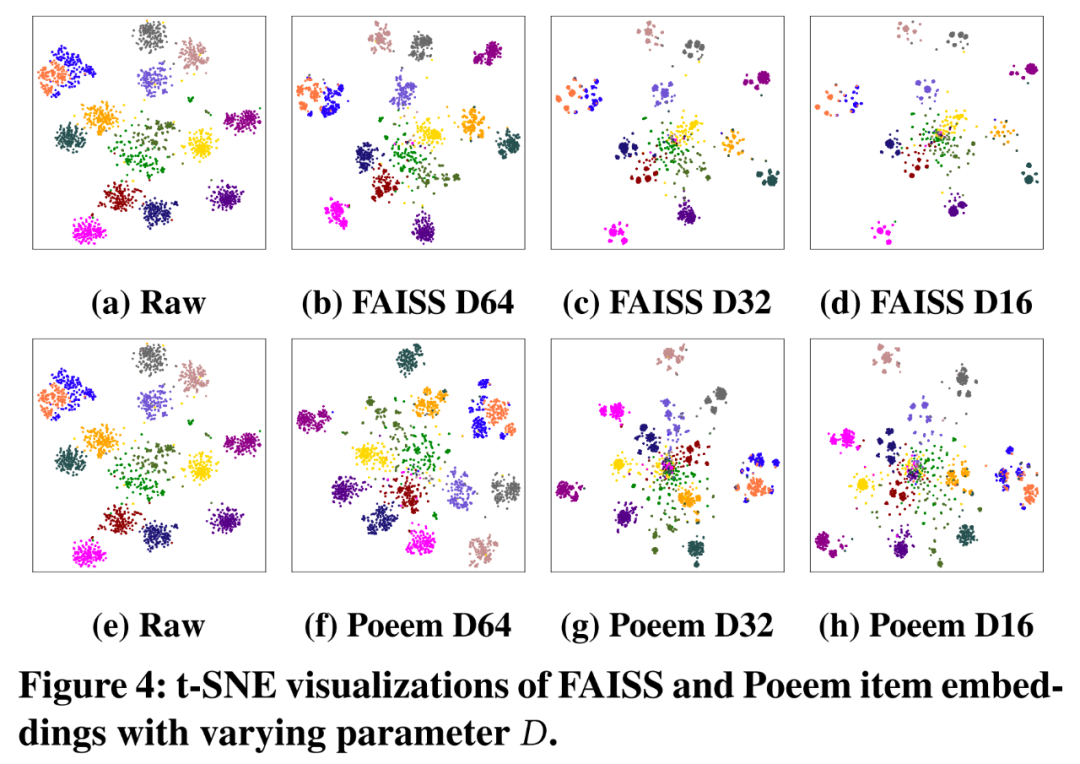
其中 (a) 和 (e) 是量化前的原始向量,(b~d)是 Faiss 量化后的向量,(f~h)是 Poeem 量化后的向量。参数 D 是划分子空间的数量。横向比较,可以看到向量量化会造成一定的向量“坍缩”,具体表现为在每个聚类的内部,向量呈现更小范围的聚集,从而背离了原始向量的分布。
这是由于子向量共享相应子空间的聚类中心导致的,这一点可以从 b~d 的变化看出,随着 D 递减,子空间越大,向量共享的维度更多,“坍缩”现象也更加严重。纵向比较,Poeem 比 Faiss 的“坍缩”程度更小,说明 Poeem 有效降低了向量量化的损失,从而提高召回精度。
c) 系统优势
下图是各个方法为一百万 512 维向量建索引的耗时:
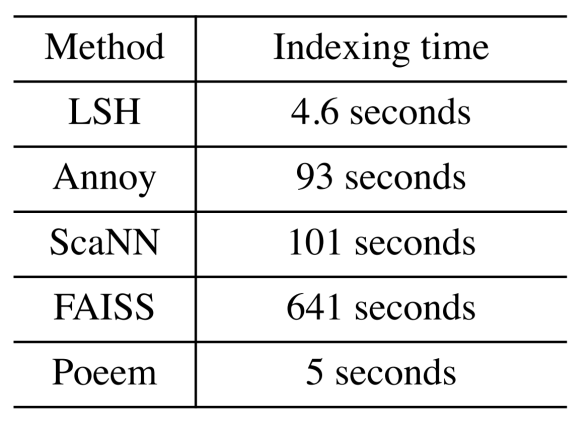
由于索引在模型训练的过程中已经学好,Poeem 几乎不需要额外的建索引时间,只需要将索引导出即可。
此外,我们实现了模型和索引的联合导出,导出的模型可以直接实现从 query 到 topk 商品的召回过程,无需额外的商品向量索引服务,只需要像其他模型一样 serve 即可,大大降低了向量召回的工程实现复杂度。

总结
Poeem 是一种基于 PQ 的索引联合训练模型,能够有效降低向量量化损失,从而提高向量查找精度。论文已被 SIGIR 2021 接收。此外,我们已将 Poeem 开源,并且已封装成 python 包,可以一键安装,快速易用:
欢迎来开源项目下体验交流。
招聘
京东搜索检索团队负责京东商城全站商品搜索召回与排序算法,成员来自百度、facebook 等业界知名公司,有着丰富的搜索算法经验,并有多篇顶会论文发表。
■ 工作内容
1、基于海量的用户和商家数据,优化商品搜索的 ctr、cvr 预估模型
2、用户和文本的向量表示学习,优化个性化向量检索模型
3、模型样本选取、结构设计、特征选择、优化算法、用户长短期行为建模等
4、与搜索架构、产品和运营同学合作,推动算法系统和产品方案落地
■ 任职要求
1. 计算机、数学、自然语言处理、机器学习及相关专业研究生、博士生
2. 熟悉 C/C++与Linux 开发,熟悉 Python/Shell 等脚本语言,对常用数据结构和算法有深刻理解
3. 熟悉常用 machine learning 尤其是 deep learning 算法,并有大规模分布式应用经验
4. 熟悉 tensorflow、torch、caffe 等深度学习框架
5. 对创新和挑战的工作有激情,具备出色的规划、执行力,强烈的责任感,以及优秀的学习能力
6. 在机器学习、数据挖掘、计算广告等领域的国际顶级会议或期刊上发表论文者优先
联系方式:王松林,wangsonglin3@jd.com
参考文献
[1] Zhang, Han, Songlin Wang, Kang Zhang, Zhiling Tang, Yunjiang Jiang, Yun Xiao, Weipeng Yan, and Wen-Yun Yang. "Towards personalized and semantic retrieval: An end-to-end solution for e-commerce search via embedding learning." In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2407-2416. 2020.
[2] Johnson, Jeff, Matthijs Douze, and Hervé Jégou. "Billion-scale similarity search with gpus." IEEE Transactions on Big Data (2019).
[3] Harper, F. Maxwell, and Joseph A. Konstan. "The movielens datasets: History and context." Acm transactions on interactive intelligent systems (tiis) 5, no. 4 (2015): 1-19.
[4] McAuley, J., Targett, C., Shi, Q., & Van Den Hengel, A. (2015, August). Image-based recommendations on styles and substitutes. In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval (pp. 43-52).
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!